WaveGlow
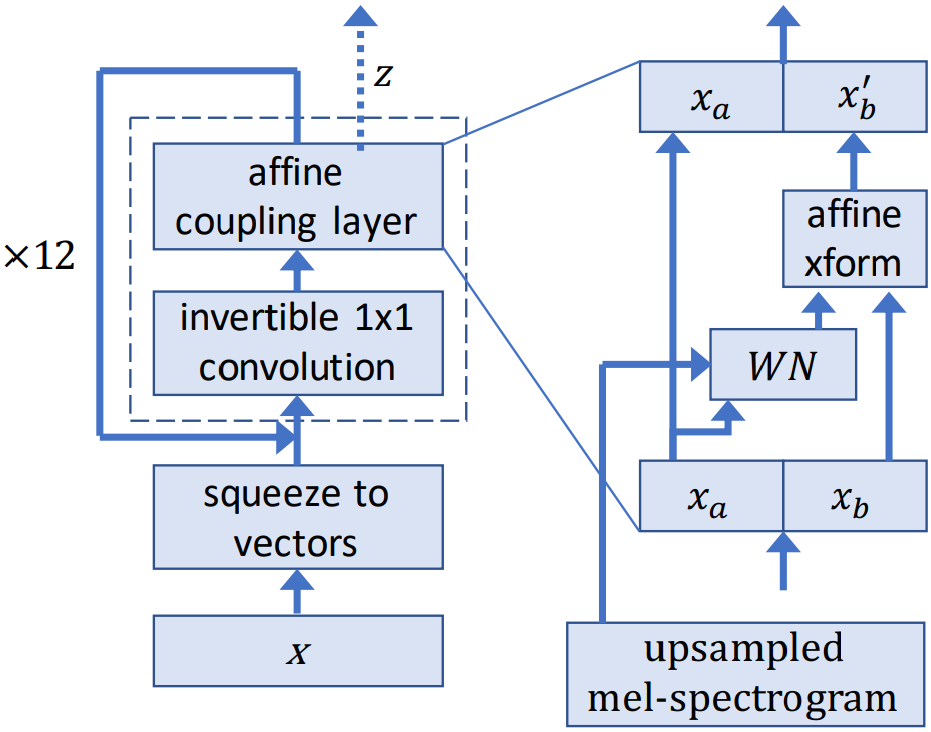
模型描述
Tacotron 2 和 WaveGlow 模型构成了一个文本转语音系统,使用户能够从原始文本中合成自然的声音,而无需任何额外的韵律信息。Tacotron 2 模型(也可通过 torch.hub 获得)使用编码器-解码器架构从输入文本生成梅尔谱图。WaveGlow 是一种基于流的模型,它使用梅尔谱图生成语音。
示例
在下面的示例中
- 从 torch.hub 加载预训练的 Tacotron2 和 Waveglow 模型
- 给定输入文本(“Hello world, I missed you so much”)的张量表示,Tacotron2 生成一个梅尔谱图,如插图所示
- Waveglow 根据梅尔谱图生成声音
- 输出声音保存为“audio.wav”文件
要运行此示例,您需要安装一些额外的 Python 包。这些包用于文本和音频的预处理,以及显示和输入/输出。
pip install numpy scipy librosa unidecode inflect librosa
apt-get update
apt-get install -y libsndfile1
加载在 LJ Speech 数据集上预训练的 WaveGlow 模型
import torch
waveglow = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_waveglow', model_math='fp32')
准备用于推理的 WaveGlow 模型
waveglow = waveglow.remove_weightnorm(waveglow)
waveglow = waveglow.to('cuda')
waveglow.eval()
加载预训练的 Tacotron2 模型
tacotron2 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tacotron2', model_math='fp32')
tacotron2 = tacotron2.to('cuda')
tacotron2.eval()
现在,让我们让模型说
text = "hello world, I missed you so much"
使用实用方法格式化输入
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tts_utils')
sequences, lengths = utils.prepare_input_sequence([text])
运行链式模型
with torch.no_grad():
mel, _, _ = tacotron2.infer(sequences, lengths)
audio = waveglow.infer(mel)
audio_numpy = audio[0].data.cpu().numpy()
rate = 22050
您可以将其写入文件并收听
from scipy.io.wavfile import write
write("audio.wav", rate, audio_numpy)
或者,在 Jupyter Notebook 中使用 IPython 小部件立即播放
from IPython.display import Audio
Audio(audio_numpy, rate=rate)
详情
有关模型输入和输出、训练方法、推理和性能的详细信息,请访问: github 和/或 NGC