半监督和半弱监督 ImageNet 模型
import torch
# === SEMI-WEAKLY SUPERVISED MODELS PRETRAINED WITH 940 HASHTAGGED PUBLIC CONTENT ===
model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnet18_swsl')
# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnet50_swsl')
# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext50_32x4d_swsl')
# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x4d_swsl')
# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x8d_swsl')
# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x16d_swsl')
# ================= SEMI-SUPERVISED MODELS PRETRAINED WITH YFCC100M ==================
# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnet18_ssl')
# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnet50_ssl')
# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext50_32x4d_ssl')
# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x4d_ssl')
# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x8d_ssl')
# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x16d_ssl')
model.eval()
所有预训练模型都要求输入图像以相同的方式进行归一化,即由形状为 (3 x H x W) 的 3 通道 RGB 图像组成的小批量数据,其中 H 和 W 预计至少为 224。图像必须加载到 [0, 1] 范围内,然后使用 mean = [0.485, 0.456, 0.406] 和 std = [0.229, 0.224, 0.225] 进行归一化。
这是一个示例执行。
# Download an example image from the pytorch website
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
print(torch.nn.functional.softmax(output[0], dim=0))
模型描述
本项目包含“十亿级半监督图像分类学习”https://arxiv.org/abs/1905.00546中介绍的半监督和半弱监督 ImageNet 模型。
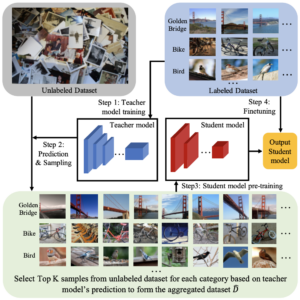
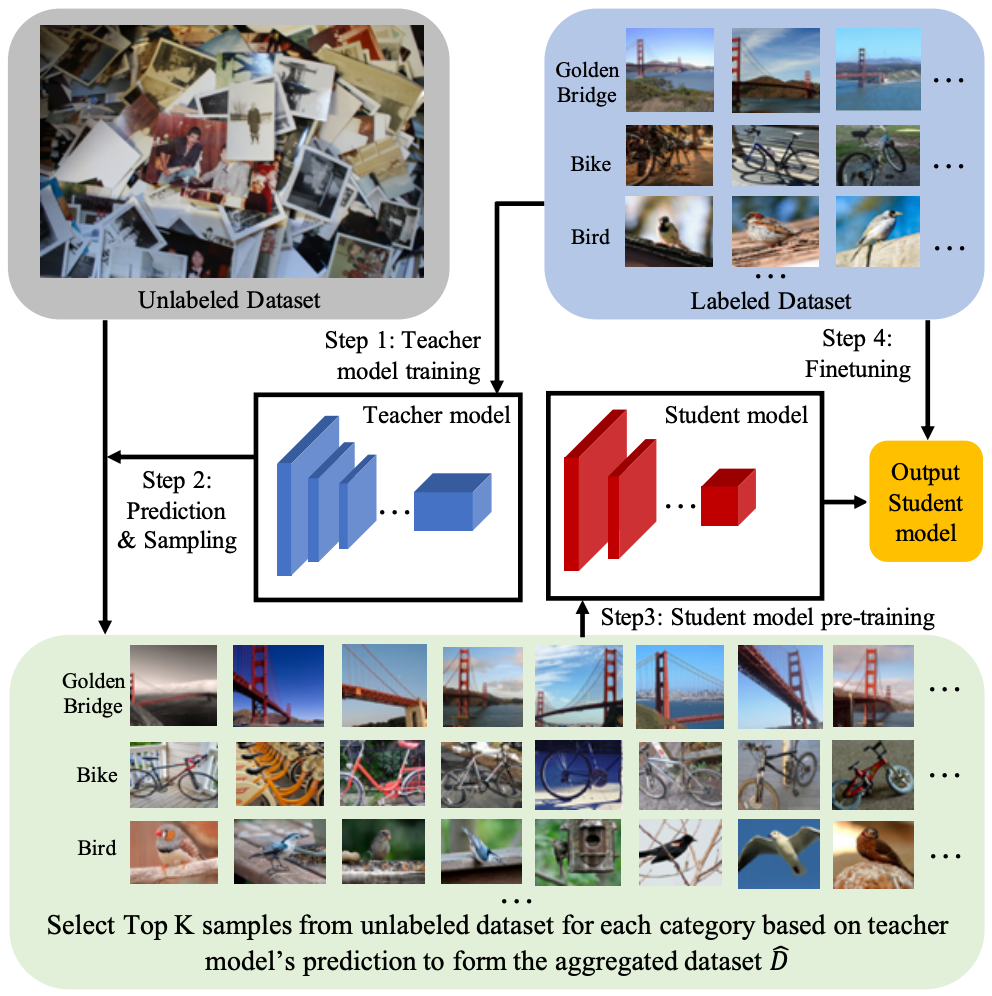
“半监督”(SSL)ImageNet 模型在无标签的 YFCC100M 公共图像数据集子集上进行预训练,并使用 ImageNet1K 训练数据集进行微调,如上述论文中的半监督训练框架所述。在这种情况下,高容量教师模型仅使用有标签的样本进行训练。
“半弱监督”(SWSL)ImageNet 模型在包含 9.4 亿公共图像的数据集上进行预训练,这些图像带有与 1000 个 ImageNet1K 同义词集匹配的 1.5K 标签,随后在 ImageNet1K 数据集上进行微调。在这种情况下,相关的标签仅用于构建一个更好的教师模型。在训练学生模型时,这些标签被忽略,学生模型使用教师模型从相同的 9.4 亿公共图像数据集中选择的 64M 图像子集进行预训练。
下表提供的半弱监督 ResNet 和 ResNext 模型与从头开始训练或截至 2019 年 9 月文献中介绍的其他训练机制相比,显著提高了 ImageNet 验证集上的 top-1 准确率。例如,我们为广泛使用/采用的 ResNet-50 模型架构在 ImageNet 上实现了 81.2% 的最先进准确率。
| 架构 | 监督方式 | #参数 | 浮点运算次数 (FLOPS) | Top-1 准确率 | Top-5 准确率 |
|---|---|---|---|---|---|
| ResNet-18 | 半监督 | 14M | 2B | 72.8 | 91.5 |
| ResNet-50 | 半监督 | 25M | 4B | 79.3 | 94.9 |
| ResNeXt-50 32x4d | 半监督 | 25M | 4B | 80.3 | 95.4 |
| ResNeXt-101 32x4d | 半监督 | 42M | 8K | 81.0 | 95.7 |
| ResNeXt-101 32x8d | 半监督 | 88M | 16B | 81.7 | 96.1 |
| ResNeXt-101 32x16d | 半监督 | 193M | 36B | 81.9 | 96.2 |
| ResNet-18 | 半弱监督 | 14M | 2B | 73.4 | 91.9 |
| ResNet-50 | 半弱监督 | 25M | 4B | 81.2 | 96.0 |
| ResNeXt-50 32x4d | 半弱监督 | 25M | 4B | 82.2 | 96.3 |
| ResNeXt-101 32x4d | 半弱监督 | 42M | 8K | 83.4 | 96.8 |
| ResNeXt-101 32x8d | 半弱监督 | 88M | 16B | 84.3 | 97.2 |
| ResNeXt-101 32x16d | 半弱监督 | 193M | 36B | 84.8 | 97.4 |
引用
如果您使用本仓库中发布的模型,请引用以下出版物 (https://arxiv.org/abs/1905.00546)。
@misc{yalniz2019billionscale,
title={Billion-scale semi-supervised learning for image classification},
author={I. Zeki Yalniz and Hervé Jégou and Kan Chen and Manohar Paluri and Dhruv Mahajan},
year={2019},
eprint={1905.00546},
archivePrefix={arXiv},
primaryClass={cs.CV}
}