


注意
转到末尾下载完整示例代码
导出到 ExecuTorch 教程¶
作者: Angela Yi
ExecuTorch 是一个统一的 ML 堆栈,用于将 PyTorch 模型降级到边缘设备。它引入了改进的入口点来执行模型、设备和/或特定于用例的优化,例如后端委托、用户定义的编译器转换、默认或用户定义的内存规划等。
从高层次来看,工作流如下所示
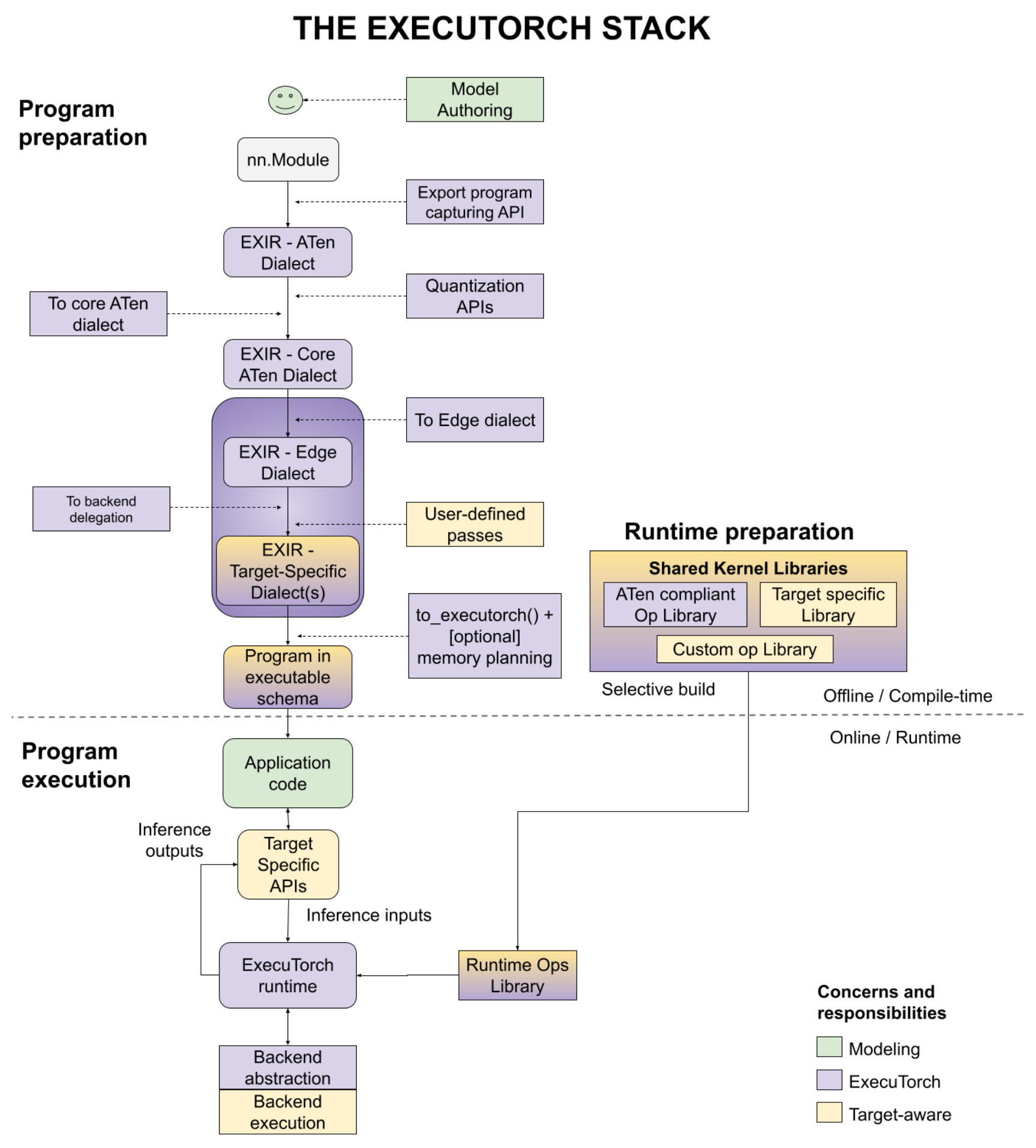
在本教程中,我们将介绍“程序准备”步骤中的 API,以将 PyTorch 模型降级到可以加载到设备并在 ExecuTorch 运行时上运行的格式。
先决条件¶
要运行本教程,首先需要设置 ExecuTorch 环境。
导出模型¶
注意:导出 API 仍在进行更改,以更好地与导出的长期状态保持一致。有关更多详细信息,请参阅此问题。
降级到 ExecuTorch 的第一步是将给定的模型(任何可调用对象或torch.nn.Module)导出到图表示。这是通过两阶段 API torch._export.capture_pre_autograd_graph 和 torch.export 完成的。
这两个 API 都接受一个模型(任何可调用对象或torch.nn.Module)、一个位置参数元组、一个关键字参数字典(示例中未显示)和一个动态形状列表(稍后介绍)。
import torch
from torch._export import capture_pre_autograd_graph
from torch.export import export, ExportedProgram
class SimpleConv(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv = torch.nn.Conv2d(
in_channels=3, out_channels=16, kernel_size=3, padding=1
)
self.relu = torch.nn.ReLU()
def forward(self, x: torch.Tensor) -> torch.Tensor:
a = self.conv(x)
return self.relu(a)
example_args = (torch.randn(1, 3, 256, 256),)
pre_autograd_aten_dialect = capture_pre_autograd_graph(SimpleConv(), example_args)
print("Pre-Autograd ATen Dialect Graph")
print(pre_autograd_aten_dialect)
aten_dialect: ExportedProgram = export(pre_autograd_aten_dialect, example_args)
print("ATen Dialect Graph")
print(aten_dialect)
Pre-Autograd ATen Dialect Graph
GraphModule()
def forward(self, x):
arg0, = fx_pytree.tree_flatten_spec(([x], {}), self._in_spec)
arg0_1 = arg0
_param_constant0 = self.conv_weight
_param_constant1 = self.conv_bias
conv2d = torch.ops.aten.conv2d.default(arg0_1, _param_constant0, _param_constant1, [1, 1], [1, 1]); arg0_1 = _param_constant0 = _param_constant1 = None
relu = torch.ops.aten.relu.default(conv2d); conv2d = None
return pytree.tree_unflatten([relu], self._out_spec)
# To see more debug info, please use `graph_module.print_readable()`
ATen Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[16, 3, 3, 3]", arg1_1: "f32[16]", arg2_1: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:68 in forward, code: a = self.conv(x)
convolution: "f32[1, 16, 256, 256]" = torch.ops.aten.convolution.default(arg2_1, arg0_1, arg1_1, [1, 1], [1, 1], [1, 1], False, [0, 0], 1); arg2_1 = arg0_1 = arg1_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:69 in forward, code: return self.relu(a)
relu: "f32[1, 16, 256, 256]" = torch.ops.aten.relu.default(convolution); convolution = None
return (relu,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg0_1'), target='conv_weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg1_1'), target='conv_bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg2_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='relu'), target=None)])
Range constraints: {}
torch._export.capture_pre_autograd_graph 的输出是一个完全扁平化的图(这意味着该图不包含任何模块层次结构,除了控制流运算符的情况除外)。此外,捕获的图仅包含 Autograd 安全的 ATen 运算符(约 3000 个运算符),例如,安全用于急切模式训练。
torch.export 的输出进一步将图编译为更低级和更简洁的表示。具体来说,它具有以下
该图是纯函数式的,这意味着它不包含具有副作用的操作,例如突变或别名。
该图仅包含一个小的已定义 核心 ATen IR 运算符集(~180 个运算符),以及已注册的自定义运算符。
图中的节点包含在跟踪期间捕获的元数据,例如来自用户代码的堆栈跟踪。
关于 torch.export 结果的更多规范可以在 此处 找到。
由于 torch.export 的结果是一个包含核心 ATen 运算符的图,因此我们将称其为 ATen 方言,并且由于 torch._export.capture_pre_autograd_graph 返回一个包含一组对 Autograd 安全的 ATen 运算符的图,因此我们将称其为 Pre-Autograd ATen 方言。
表达动态性¶
默认情况下,导出流程将跟踪程序,假设所有输入形状都是静态的,因此如果我们使用与跟踪时所用形状不同的输入形状运行程序,我们将遇到错误
import traceback as tb
class Basic(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
return x + y
f = Basic()
example_args = (torch.randn(3, 3), torch.randn(3, 3))
pre_autograd_aten_dialect = capture_pre_autograd_graph(f, example_args)
aten_dialect: ExportedProgram = export(f, example_args)
# Works correctly
print(aten_dialect.module()(torch.ones(3, 3), torch.ones(3, 3)))
# Errors
try:
print(aten_dialect.module()(torch.ones(3, 2), torch.ones(3, 2)))
except Exception:
tb.print_exc()
tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])
Traceback (most recent call last):
File "/pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py", line 137, in <module>
print(aten_dialect.module()(torch.ones(3, 2), torch.ones(3, 2)))
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 737, in call_wrapped
return self._wrapped_call(self, *args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 317, in __call__
raise e
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 304, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1561, in _call_impl
args_kwargs_result = hook(self, args, kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 451, in _fn
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/external_utils.py", line 36, in inner
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/export/_unlift.py", line 32, in _check_input_constraints_pre_hook
return _check_input_constraints_for_graph(
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_export/utils.py", line 129, in _check_input_constraints_for_graph
raise RuntimeError(
RuntimeError: Expected input at *args[0].shape[1] to be equal to 3, but got 2
- 要表示某些输入形状是动态的,我们可以插入动态
导出流程中的形状。这是通过
DimAPI 完成的
from torch.export import Dim
class Basic(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
return x + y
f = Basic()
example_args = (torch.randn(3, 3), torch.randn(3, 3))
dim1_x = Dim("dim1_x", min=1, max=10)
dynamic_shapes = {"x": {1: dim1_x}, "y": {1: dim1_x}}
pre_autograd_aten_dialect = capture_pre_autograd_graph(
f, example_args, dynamic_shapes=dynamic_shapes
)
aten_dialect: ExportedProgram = export(f, example_args, dynamic_shapes=dynamic_shapes)
print("ATen Dialect Graph")
print(aten_dialect)
ATen Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[3, s0]", arg1_1: "f32[3, s0]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:153 in forward, code: return x + y
add: "f32[3, s0]" = torch.ops.aten.add.Tensor(arg0_1, arg1_1); arg0_1 = arg1_1 = None
return (add,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg0_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg1_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='add'), target=None)])
Range constraints: {s0: ValueRanges(lower=2, upper=10, is_bool=False)}
请注意,输入 arg0_1 和 arg1_1 现在具有形状 (3, s0),其中 s0 是表示此维度可以是值范围的符号。
此外,我们可以在范围约束中看到 s0 的值范围是 [1, 10],这是由我们的动态形状指定的。
现在让我们尝试使用不同的形状运行模型
# Works correctly
print(aten_dialect.module()(torch.ones(3, 3), torch.ones(3, 3)))
print(aten_dialect.module()(torch.ones(3, 2), torch.ones(3, 2)))
# Errors because it violates our constraint that input 0, dim 1 <= 10
try:
print(aten_dialect.module()(torch.ones(3, 15), torch.ones(3, 15)))
except Exception:
tb.print_exc()
# Errors because it violates our constraint that input 0, dim 1 == input 1, dim 1
try:
print(aten_dialect.module()(torch.ones(3, 3), torch.ones(3, 2)))
except Exception:
tb.print_exc()
tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])
tensor([[2., 2.],
[2., 2.],
[2., 2.]])
Traceback (most recent call last):
File "/pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py", line 183, in <module>
print(aten_dialect.module()(torch.ones(3, 15), torch.ones(3, 15)))
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 737, in call_wrapped
return self._wrapped_call(self, *args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 317, in __call__
raise e
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 304, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1561, in _call_impl
args_kwargs_result = hook(self, args, kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 451, in _fn
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/external_utils.py", line 36, in inner
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/export/_unlift.py", line 32, in _check_input_constraints_pre_hook
return _check_input_constraints_for_graph(
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_export/utils.py", line 123, in _check_input_constraints_for_graph
raise RuntimeError(
RuntimeError: Expected input at *args[0].shape[1] to be <= 10, but got 15
Traceback (most recent call last):
File "/pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py", line 189, in <module>
print(aten_dialect.module()(torch.ones(3, 3), torch.ones(3, 2)))
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 737, in call_wrapped
return self._wrapped_call(self, *args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 317, in __call__
raise e
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 304, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1561, in _call_impl
args_kwargs_result = hook(self, args, kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 451, in _fn
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/external_utils.py", line 36, in inner
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/export/_unlift.py", line 32, in _check_input_constraints_pre_hook
return _check_input_constraints_for_graph(
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_export/utils.py", line 85, in _check_input_constraints_for_graph
raise RuntimeError(
RuntimeError: Expected input at *args[1].shape[1] to be equal to 3, but got 2
解决无法跟踪的代码¶
由于我们的目标是从 PyTorch 程序中捕获整个计算图,因此我们最终可能会遇到无法跟踪的程序部分。要解决这些问题,torch.export 文档 或 torch.export 教程 将是最好的参考。
执行量化¶
要对模型进行量化,我们可以在 Pre-Autograd ATen 方言 中的 torch._export.capture_pre_autograd_graph 和 torch.export 之间的调用之间进行。这是因为量化必须在对急切模式训练安全级别进行操作。
与 FX 图模式量化 相比,我们需要调用两个新的 API:prepare_pt2e 和 convert_pt2e,而不是 prepare_fx 和 convert_fx。它们的不同之处在于 prepare_pt2e 将后端特定的 Quantizer 作为参数,该参数将使用特定后端正确量化模型所需的信息对图中的节点进行注释。
example_args = (torch.randn(1, 3, 256, 256),)
pre_autograd_aten_dialect = capture_pre_autograd_graph(SimpleConv(), example_args)
print("Pre-Autograd ATen Dialect Graph")
print(pre_autograd_aten_dialect)
from torch.ao.quantization.quantize_pt2e import convert_pt2e, prepare_pt2e
from torch.ao.quantization.quantizer.xnnpack_quantizer import (
get_symmetric_quantization_config,
XNNPACKQuantizer,
)
quantizer = XNNPACKQuantizer().set_global(get_symmetric_quantization_config())
prepared_graph = prepare_pt2e(pre_autograd_aten_dialect, quantizer)
# calibrate with a sample dataset
converted_graph = convert_pt2e(prepared_graph)
print("Quantized Graph")
print(converted_graph)
aten_dialect: ExportedProgram = export(converted_graph, example_args)
print("ATen Dialect Graph")
print(aten_dialect)
Pre-Autograd ATen Dialect Graph
GraphModule()
def forward(self, x):
arg0, = fx_pytree.tree_flatten_spec(([x], {}), self._in_spec)
arg0_1 = arg0
_param_constant0 = self.conv_weight
_param_constant1 = self.conv_bias
conv2d = torch.ops.aten.conv2d.default(arg0_1, _param_constant0, _param_constant1, [1, 1], [1, 1]); arg0_1 = _param_constant0 = _param_constant1 = None
relu = torch.ops.aten.relu.default(conv2d); conv2d = None
return pytree.tree_unflatten([relu], self._out_spec)
# To see more debug info, please use `graph_module.print_readable()`
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/ao/quantization/observer.py:1272: UserWarning: must run observer before calling calculate_qparams. Returning default scale and zero point
warnings.warn(
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/ao/quantization/utils.py:339: UserWarning: must run observer before calling calculate_qparams. Returning default values.
warnings.warn(
Quantized Graph
GraphModule()
def forward(self, x):
arg0, = fx_pytree.tree_flatten_spec(([x], {}), self._in_spec)
arg0_1 = arg0
quantize_per_tensor_default = torch.ops.quantized_decomposed.quantize_per_tensor.default(arg0_1, 1.0, 0, -128, 127, torch.int8); arg0_1 = None
dequantize_per_tensor_default = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor_default, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor_default = None
_frozen_param0 = self._frozen_param0
dequantize_per_tensor_default_1 = torch.ops.quantized_decomposed.dequantize_per_tensor.default(_frozen_param0, 1.0, 0, -127, 127, torch.int8); _frozen_param0 = None
_param_constant1 = self.conv_bias
conv2d = torch.ops.aten.conv2d.default(dequantize_per_tensor_default, dequantize_per_tensor_default_1, _param_constant1, [1, 1], [1, 1]); dequantize_per_tensor_default = dequantize_per_tensor_default_1 = _param_constant1 = None
relu = torch.ops.aten.relu.default(conv2d); conv2d = None
quantize_per_tensor_default_2 = torch.ops.quantized_decomposed.quantize_per_tensor.default(relu, 1.0, 0, -128, 127, torch.int8); relu = None
dequantize_per_tensor_default_2 = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor_default_2, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor_default_2 = None
return pytree.tree_unflatten([dequantize_per_tensor_default_2], self._out_spec)
# To see more debug info, please use `graph_module.print_readable()`
ATen Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[16]", arg1_1: "i8[16, 3, 3, 3]", arg2_1: "f32[1, 3, 256, 256]"):
# File: <eval_with_key>.162:7 in forward, code: quantize_per_tensor_default = torch.ops.quantized_decomposed.quantize_per_tensor.default(arg0_1, 1.0, 0, -128, 127, torch.int8); arg0_1 = None
quantize_per_tensor: "i8[1, 3, 256, 256]" = torch.ops.quantized_decomposed.quantize_per_tensor.default(arg2_1, 1.0, 0, -128, 127, torch.int8); arg2_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:68 in forward, code: a = self.conv(x)
dequantize_per_tensor: "f32[1, 3, 256, 256]" = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor = None
dequantize_per_tensor_1: "f32[16, 3, 3, 3]" = torch.ops.quantized_decomposed.dequantize_per_tensor.default(arg1_1, 1.0, 0, -127, 127, torch.int8); arg1_1 = None
convolution: "f32[1, 16, 256, 256]" = torch.ops.aten.convolution.default(dequantize_per_tensor, dequantize_per_tensor_1, arg0_1, [1, 1], [1, 1], [1, 1], False, [0, 0], 1); dequantize_per_tensor = dequantize_per_tensor_1 = arg0_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:69 in forward, code: return self.relu(a)
relu: "f32[1, 16, 256, 256]" = torch.ops.aten.relu.default(convolution); convolution = None
quantize_per_tensor_1: "i8[1, 16, 256, 256]" = torch.ops.quantized_decomposed.quantize_per_tensor.default(relu, 1.0, 0, -128, 127, torch.int8); relu = None
# File: <eval_with_key>.162:15 in forward, code: dequantize_per_tensor_default_2 = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor_default_2, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor_default_2 = None
dequantize_per_tensor_2: "f32[1, 16, 256, 256]" = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor_1, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor_1 = None
return (dequantize_per_tensor_2,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg0_1'), target='conv_bias', persistent=None), InputSpec(kind=<InputKind.BUFFER: 3>, arg=TensorArgument(name='arg1_1'), target='_frozen_param0', persistent=True), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg2_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='dequantize_per_tensor_2'), target=None)])
Range constraints: {}
有关如何量化模型以及后端如何实现 Quantizer 的更多信息,请参阅 此处。
降低到 Edge 方言¶
将图导出并降低到 ATen Dialect 之后,下一步是降低到 Edge Dialect,其中将应用对边缘设备有用的但对于通用(服务器)环境来说不是必需的专业化。其中一些专业化包括
数据类型专业化
标量到张量的转换
将所有操作转换为
executorch.exir.dialects.edge命名空间。
请注意,此方言仍然与后端(或目标)无关。
降低是通过 to_edge API 完成的。
from executorch.exir import EdgeProgramManager, to_edge
example_args = (torch.randn(1, 3, 256, 256),)
pre_autograd_aten_dialect = capture_pre_autograd_graph(SimpleConv(), example_args)
print("Pre-Autograd ATen Dialect Graph")
print(pre_autograd_aten_dialect)
aten_dialect: ExportedProgram = export(pre_autograd_aten_dialect, example_args)
print("ATen Dialect Graph")
print(aten_dialect)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
print("Edge Dialect Graph")
print(edge_program.exported_program())
Pre-Autograd ATen Dialect Graph
GraphModule()
def forward(self, x):
arg0, = fx_pytree.tree_flatten_spec(([x], {}), self._in_spec)
arg0_1 = arg0
_param_constant0 = self.conv_weight
_param_constant1 = self.conv_bias
conv2d = torch.ops.aten.conv2d.default(arg0_1, _param_constant0, _param_constant1, [1, 1], [1, 1]); arg0_1 = _param_constant0 = _param_constant1 = None
relu = torch.ops.aten.relu.default(conv2d); conv2d = None
return pytree.tree_unflatten([relu], self._out_spec)
# To see more debug info, please use `graph_module.print_readable()`
ATen Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[16, 3, 3, 3]", arg1_1: "f32[16]", arg2_1: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:68 in forward, code: a = self.conv(x)
convolution: "f32[1, 16, 256, 256]" = torch.ops.aten.convolution.default(arg2_1, arg0_1, arg1_1, [1, 1], [1, 1], [1, 1], False, [0, 0], 1); arg2_1 = arg0_1 = arg1_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:69 in forward, code: return self.relu(a)
relu: "f32[1, 16, 256, 256]" = torch.ops.aten.relu.default(convolution); convolution = None
return (relu,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg0_1'), target='conv_weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg1_1'), target='conv_bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg2_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='relu'), target=None)])
Range constraints: {}
Edge Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[16, 3, 3, 3]", arg1_1: "f32[16]", arg2_1: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:68 in forward, code: a = self.conv(x)
aten_convolution_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_convolution_default(arg2_1, arg0_1, arg1_1, [1, 1], [1, 1], [1, 1], False, [0, 0], 1); arg2_1 = arg0_1 = arg1_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:69 in forward, code: return self.relu(a)
aten_relu_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_relu_default(aten_convolution_default); aten_convolution_default = None
return (aten_relu_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg0_1'), target='conv_weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg1_1'), target='conv_bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg2_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_relu_default'), target=None)])
Range constraints: {}
to_edge() 返回一个 EdgeProgramManager 对象,其中包含将放置在此设备上的已导出程序。此数据结构允许用户导出多个程序并将它们组合到一个二进制文件中。如果只有一个程序,则默认情况下它将被保存为名称“forward”。
class Encode(torch.nn.Module):
def forward(self, x):
return torch.nn.functional.linear(x, torch.randn(5, 10))
class Decode(torch.nn.Module):
def forward(self, x):
return torch.nn.functional.linear(x, torch.randn(10, 5))
encode_args = (torch.randn(1, 10),)
aten_encode: ExportedProgram = export(
capture_pre_autograd_graph(Encode(), encode_args),
encode_args,
)
decode_args = (torch.randn(1, 5),)
aten_decode: ExportedProgram = export(
capture_pre_autograd_graph(Decode(), decode_args),
decode_args,
)
edge_program: EdgeProgramManager = to_edge(
{"encode": aten_encode, "decode": aten_decode}
)
for method in edge_program.methods:
print(f"Edge Dialect graph of {method}")
print(edge_program.exported_program(method))
Edge Dialect graph of decode
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[1, 5]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:297 in forward, code: return torch.nn.functional.linear(x, torch.randn(10, 5))
aten_randn_default: "f32[10, 5]" = executorch_exir_dialects_edge__ops_aten_randn_default([10, 5], device = device(type='cpu'), pin_memory = False)
aten_permute_copy_default: "f32[5, 10]" = executorch_exir_dialects_edge__ops_aten_permute_copy_default(aten_randn_default, [1, 0]); aten_randn_default = None
aten_mm_default: "f32[1, 10]" = executorch_exir_dialects_edge__ops_aten_mm_default(arg0_1, aten_permute_copy_default); arg0_1 = aten_permute_copy_default = None
return (aten_mm_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg0_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_mm_default'), target=None)])
Range constraints: {}
Edge Dialect graph of encode
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[1, 10]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:292 in forward, code: return torch.nn.functional.linear(x, torch.randn(5, 10))
aten_randn_default: "f32[5, 10]" = executorch_exir_dialects_edge__ops_aten_randn_default([5, 10], device = device(type='cpu'), pin_memory = False)
aten_permute_copy_default: "f32[10, 5]" = executorch_exir_dialects_edge__ops_aten_permute_copy_default(aten_randn_default, [1, 0]); aten_randn_default = None
aten_mm_default: "f32[1, 5]" = executorch_exir_dialects_edge__ops_aten_mm_default(arg0_1, aten_permute_copy_default); arg0_1 = aten_permute_copy_default = None
return (aten_mm_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg0_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_mm_default'), target=None)])
Range constraints: {}
我们还可以通过 transform API 对导出的程序运行其他传递。有关如何编写转换的深入文档,请参阅 此处。
请注意,由于图现在位于 Edge 方言中,因此所有传递也必须生成有效的 Edge 方言图(具体来说,需要指出的一件事是,运算符现在位于 executorch.exir.dialects.edge 命名空间中,而不是 torch.ops.aten 命名空间中。
example_args = (torch.randn(1, 3, 256, 256),)
pre_autograd_aten_dialect = capture_pre_autograd_graph(SimpleConv(), example_args)
aten_dialect: ExportedProgram = export(pre_autograd_aten_dialect, example_args)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
print("Edge Dialect Graph")
print(edge_program.exported_program())
from executorch.exir.dialects._ops import ops as exir_ops
from executorch.exir.pass_base import ExportPass
class ConvertReluToSigmoid(ExportPass):
def call_operator(self, op, args, kwargs, meta):
if op == exir_ops.edge.aten.relu.default:
return super().call_operator(
exir_ops.edge.aten.sigmoid.default, args, kwargs, meta
)
else:
return super().call_operator(op, args, kwargs, meta)
transformed_edge_program = edge_program.transform((ConvertReluToSigmoid(),))
print("Transformed Edge Dialect Graph")
print(transformed_edge_program.exported_program())
Edge Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[16, 3, 3, 3]", arg1_1: "f32[16]", arg2_1: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:68 in forward, code: a = self.conv(x)
aten_convolution_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_convolution_default(arg2_1, arg0_1, arg1_1, [1, 1], [1, 1], [1, 1], False, [0, 0], 1); arg2_1 = arg0_1 = arg1_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:69 in forward, code: return self.relu(a)
aten_relu_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_relu_default(aten_convolution_default); aten_convolution_default = None
return (aten_relu_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg0_1'), target='conv_weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg1_1'), target='conv_bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg2_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_relu_default'), target=None)])
Range constraints: {}
Transformed Edge Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[16, 3, 3, 3]", arg1_1: "f32[16]", arg2_1: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:68 in forward, code: a = self.conv(x)
aten_convolution_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_convolution_default(arg2_1, arg0_1, arg1_1, [1, 1], [1, 1], [1, 1], False, [0, 0], 1); arg2_1 = arg0_1 = arg1_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:69 in forward, code: return self.relu(a)
aten_sigmoid_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_sigmoid_default(aten_convolution_default); aten_convolution_default = None
return (aten_sigmoid_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg0_1'), target='conv_weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg1_1'), target='conv_bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg2_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_sigmoid_default'), target=None)])
Range constraints: {}
注意:如果您看到类似 torch._export.verifier.SpecViolationError: Operator torch._ops.aten._native_batch_norm_legit_functional.default is not Aten Canonical 的错误,请在 https://github.com/pytorch/executorch/issues 中提交问题,我们会很乐意提供帮助!
委托给后端¶
我们现在可以通过 to_backend API 将图的某些部分或整个图委托给第三方后端。有关后端委托的具体信息(包括如何委托给后端以及如何实现后端)的深入文档,请参阅此处
使用此 API 的方法有三种
我们可以降低整个模块。
我们可以获取降低的模块,并将其插入到另一个更大的模块中。
我们可以将模块划分为可降低的子图,然后将这些子图降低到后端。
降低整个模块¶
要降低整个模块,我们可以将后端名称、要降低的模块以及编译规范列表传递给 to_backend,以帮助后端完成降低过程。
class LowerableModule(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return torch.sin(x)
# Export and lower the module to Edge Dialect
example_args = (torch.ones(1),)
pre_autograd_aten_dialect = capture_pre_autograd_graph(LowerableModule(), example_args)
aten_dialect: ExportedProgram = export(pre_autograd_aten_dialect, example_args)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
to_be_lowered_module = edge_program.exported_program()
from executorch.exir.backend.backend_api import LoweredBackendModule, to_backend
# Import the backend
from executorch.exir.backend.test.backend_with_compiler_demo import ( # noqa
BackendWithCompilerDemo,
)
# Lower the module
lowered_module: LoweredBackendModule = to_backend(
"BackendWithCompilerDemo", to_be_lowered_module, []
)
print(lowered_module)
print(lowered_module.backend_id)
print(lowered_module.processed_bytes)
print(lowered_module.original_module)
# Serialize and save it to a file
save_path = "delegate.pte"
with open(save_path, "wb") as f:
f.write(lowered_module.buffer())
LoweredBackendModule()
BackendWithCompilerDemo
b'1#op:demo::aten.sin.default, numel:1, dtype:torch.float32<debug_handle>1#'
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[1]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:391 in forward, code: return torch.sin(x)
aten_sin_default: "f32[1]" = executorch_exir_dialects_edge__ops_aten_sin_default(arg0_1); arg0_1 = None
return (aten_sin_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg0_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_sin_default'), target=None)])
Range constraints: {}
在此调用中,to_backend 将返回 LoweredBackendModule。LoweredBackendModule 的一些重要属性是
backend_id:此降低的模块将在运行时在其上运行的后端名称processed_bytes:一个二进制 blob,它将告诉后端如何在运行时运行此程序original_module:原始导出的模块
将降低的模块组合到另一个模块中¶
在希望在多个程序中重复使用此降低的模块的情况下,我们可以将此降低的模块与另一个模块组合。
class NotLowerableModule(torch.nn.Module):
def __init__(self, bias):
super().__init__()
self.bias = bias
def forward(self, a, b):
return torch.add(torch.add(a, b), self.bias)
class ComposedModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.non_lowerable = NotLowerableModule(torch.ones(1) * 0.3)
self.lowerable = lowered_module
def forward(self, x):
a = self.lowerable(x)
b = self.lowerable(a)
ret = self.non_lowerable(a, b)
return a, b, ret
example_args = (torch.ones(1),)
pre_autograd_aten_dialect = capture_pre_autograd_graph(ComposedModule(), example_args)
aten_dialect: ExportedProgram = export(pre_autograd_aten_dialect, example_args)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
exported_program = edge_program.exported_program()
print("Edge Dialect graph")
print(exported_program)
print("Lowered Module within the graph")
print(exported_program.graph_module.lowered_module_0.backend_id)
print(exported_program.graph_module.lowered_module_0.processed_bytes)
print(exported_program.graph_module.lowered_module_0.original_module)
Edge Dialect graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[1]", arg1_1: "f32[1]"):
# File: /opt/conda/envs/py_3.10/lib/python3.10/site-packages/executorch/exir/lowered_backend_module.py:336 in forward, code: return executorch_call_delegate(self, *args)
lowered_module_0 = self.lowered_module_0
executorch_call_delegate: "f32[1]" = torch.ops.higher_order.executorch_call_delegate(lowered_module_0, arg1_1); lowered_module_0 = arg1_1 = None
# File: /opt/conda/envs/py_3.10/lib/python3.10/site-packages/executorch/exir/lowered_backend_module.py:336 in forward, code: return executorch_call_delegate(self, *args)
lowered_module_1 = self.lowered_module_0
executorch_call_delegate_1: "f32[1]" = torch.ops.higher_order.executorch_call_delegate(lowered_module_1, executorch_call_delegate); lowered_module_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:446 in forward, code: return torch.add(torch.add(a, b), self.bias)
aten_add_tensor: "f32[1]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(executorch_call_delegate, executorch_call_delegate_1)
aten_add_tensor_1: "f32[1]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_add_tensor, arg0_1); aten_add_tensor = arg0_1 = None
return (executorch_call_delegate, executorch_call_delegate_1, aten_add_tensor_1)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.BUFFER: 3>, arg=TensorArgument(name='arg0_1'), target='_tensor_constant0', persistent=True), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg1_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='executorch_call_delegate'), target=None), OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='executorch_call_delegate_1'), target=None), OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor_1'), target=None)])
Range constraints: {}
Lowered Module within the graph
BackendWithCompilerDemo
b'1#op:demo::aten.sin.default, numel:1, dtype:torch.float32<debug_handle>1#'
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[1]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:391 in forward, code: return torch.sin(x)
aten_sin_default: "f32[1]" = executorch_exir_dialects_edge__ops_aten_sin_default(arg0_1); arg0_1 = None
return (aten_sin_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg0_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_sin_default'), target=None)])
Range constraints: {}
请注意,现在图中有一个 torch.ops.higher_order.executorch_call_delegate 节点,它正在调用 lowered_module_0。此外,lowered_module_0 的内容与我们之前创建的 lowered_module 相同。
模块的部分划分和降低¶
一个单独的降低流程是将 to_backend 我们要降低的模块和特定于后端的划分器传递给 to_backend。 to_backend 将使用特定于后端的划分器标记模块中可降低的节点,将这些节点划分为子图,然后为每个子图创建一个 LoweredBackendModule。
class Foo(torch.nn.Module):
def forward(self, a, x, b):
y = torch.mm(a, x)
z = y + b
a = z - a
y = torch.mm(a, x)
z = y + b
return z
example_args = (torch.randn(2, 2), torch.randn(2, 2), torch.randn(2, 2))
pre_autograd_aten_dialect = capture_pre_autograd_graph(Foo(), example_args)
aten_dialect: ExportedProgram = export(pre_autograd_aten_dialect, example_args)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
exported_program = edge_program.exported_program()
print("Edge Dialect graph")
print(exported_program)
from executorch.exir.backend.test.op_partitioner_demo import AddMulPartitionerDemo
delegated_program = to_backend(exported_program, AddMulPartitionerDemo())
print("Delegated program")
print(delegated_program)
print(delegated_program.graph_module.lowered_module_0.original_module)
print(delegated_program.graph_module.lowered_module_1.original_module)
Edge Dialect graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[2, 2]", arg1_1: "f32[2, 2]", arg2_1: "f32[2, 2]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:493 in forward, code: y = torch.mm(a, x)
aten_mm_default: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_mm_default(arg0_1, arg1_1)
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:494 in forward, code: z = y + b
aten_add_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_mm_default, arg2_1); aten_mm_default = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:495 in forward, code: a = z - a
aten_sub_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_sub_Tensor(aten_add_tensor, arg0_1); aten_add_tensor = arg0_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:496 in forward, code: y = torch.mm(a, x)
aten_mm_default_1: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_mm_default(aten_sub_tensor, arg1_1); aten_sub_tensor = arg1_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:497 in forward, code: z = y + b
aten_add_tensor_1: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_mm_default_1, arg2_1); aten_mm_default_1 = arg2_1 = None
return (aten_add_tensor_1,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg0_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg1_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg2_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor_1'), target=None)])
Range constraints: {}
Delegated program
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[2, 2]", arg1_1: "f32[2, 2]", arg2_1: "f32[2, 2]"):
# No stacktrace found for following nodes
lowered_module_0 = self.lowered_module_0
executorch_call_delegate = torch.ops.higher_order.executorch_call_delegate(lowered_module_0, arg0_1, arg1_1, arg2_1); lowered_module_0 = None
getitem: "f32[2, 2]" = executorch_call_delegate[0]; executorch_call_delegate = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:495 in forward, code: a = z - a
aten_sub_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_sub_Tensor(getitem, arg0_1); getitem = arg0_1 = None
# No stacktrace found for following nodes
lowered_module_1 = self.lowered_module_1
executorch_call_delegate_1 = torch.ops.higher_order.executorch_call_delegate(lowered_module_1, aten_sub_tensor, arg1_1, arg2_1); lowered_module_1 = aten_sub_tensor = arg1_1 = arg2_1 = None
getitem_1: "f32[2, 2]" = executorch_call_delegate_1[0]; executorch_call_delegate_1 = None
return (getitem_1,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg0_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg1_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg2_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='getitem_1'), target=None)])
Range constraints: {}
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[2, 2]", arg1_1: "f32[2, 2]", arg2_1: "f32[2, 2]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:493 in forward, code: y = torch.mm(a, x)
aten_mm_default: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_mm_default(arg0_1, arg1_1); arg0_1 = arg1_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:494 in forward, code: z = y + b
aten_add_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_mm_default, arg2_1); aten_mm_default = arg2_1 = None
return (aten_add_tensor,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg0_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg1_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg2_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor'), target=None)])
Range constraints: {}
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, aten_sub_tensor: "f32[2, 2]", arg1_1: "f32[2, 2]", arg2_1: "f32[2, 2]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:496 in forward, code: y = torch.mm(a, x)
aten_mm_default_1: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_mm_default(aten_sub_tensor, arg1_1); aten_sub_tensor = arg1_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:497 in forward, code: z = y + b
aten_add_tensor_1: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_mm_default_1, arg2_1); aten_mm_default_1 = arg2_1 = None
return (aten_add_tensor_1,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='aten_sub_tensor'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg1_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg2_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor_1'), target=None)])
Range constraints: {}
请注意,现在图中包含 2 个 torch.ops.higher_order.executorch_call_delegate 节点,一个包含操作 add, mul,另一个包含操作 mul, add。
或者,一个更紧密的 API 来降低模块的某些部分是直接调用 to_backend
class Foo(torch.nn.Module):
def forward(self, a, x, b):
y = torch.mm(a, x)
z = y + b
a = z - a
y = torch.mm(a, x)
z = y + b
return z
example_args = (torch.randn(2, 2), torch.randn(2, 2), torch.randn(2, 2))
pre_autograd_aten_dialect = capture_pre_autograd_graph(Foo(), example_args)
aten_dialect: ExportedProgram = export(pre_autograd_aten_dialect, example_args)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
exported_program = edge_program.exported_program()
delegated_program = edge_program.to_backend(AddMulPartitionerDemo())
print("Delegated program")
print(delegated_program.exported_program())
Delegated program
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[2, 2]", arg1_1: "f32[2, 2]", arg2_1: "f32[2, 2]"):
# No stacktrace found for following nodes
lowered_module_0 = self.lowered_module_0
executorch_call_delegate = torch.ops.higher_order.executorch_call_delegate(lowered_module_0, arg0_1, arg1_1, arg2_1); lowered_module_0 = None
getitem: "f32[2, 2]" = executorch_call_delegate[0]; executorch_call_delegate = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:530 in forward, code: a = z - a
aten_sub_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_sub_Tensor(getitem, arg0_1); getitem = arg0_1 = None
# No stacktrace found for following nodes
lowered_module_1 = self.lowered_module_1
executorch_call_delegate_1 = torch.ops.higher_order.executorch_call_delegate(lowered_module_1, aten_sub_tensor, arg1_1, arg2_1); lowered_module_1 = aten_sub_tensor = arg1_1 = arg2_1 = None
getitem_1: "f32[2, 2]" = executorch_call_delegate_1[0]; executorch_call_delegate_1 = None
return (getitem_1,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg0_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg1_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg2_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='getitem_1'), target=None)])
Range constraints: {}
运行用户自定义传递和内存规划¶
作为降低的最后一步,我们可以使用 to_executorch() API 传入后端特定传递,例如用自定义后端操作替换一组操作,以及内存规划传递,以提前告知运行时如何在运行程序时分配内存。
提供了默认内存规划传递,但如果存在,我们还可以选择后端特定的内存规划传递。可以在 此处 找到有关编写自定义内存规划传递的更多信息
from executorch.exir import ExecutorchBackendConfig, ExecutorchProgramManager
from executorch.exir.passes import MemoryPlanningPass
executorch_program: ExecutorchProgramManager = edge_program.to_executorch(
ExecutorchBackendConfig(
passes=[], # User-defined passes
memory_planning_pass=MemoryPlanningPass(
"greedy"
), # Default memory planning pass
)
)
print("ExecuTorch Dialect")
print(executorch_program.exported_program())
import executorch.exir as exir
ExecuTorch Dialect
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, arg0_1: "f32[2, 2]", arg1_1: "f32[2, 2]", arg2_1: "f32[2, 2]"):
# No stacktrace found for following nodes
alloc: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:528 in forward, code: y = torch.mm(a, x)
aten_mm_default: "f32[2, 2]" = torch.ops.aten.mm.out(arg0_1, arg1_1, out = alloc); alloc = None
# No stacktrace found for following nodes
alloc_1: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:529 in forward, code: z = y + b
aten_add_tensor: "f32[2, 2]" = torch.ops.aten.add.out(aten_mm_default, arg2_1, out = alloc_1); aten_mm_default = alloc_1 = None
# No stacktrace found for following nodes
alloc_2: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:530 in forward, code: a = z - a
aten_sub_tensor: "f32[2, 2]" = torch.ops.aten.sub.out(aten_add_tensor, arg0_1, out = alloc_2); aten_add_tensor = arg0_1 = alloc_2 = None
# No stacktrace found for following nodes
alloc_3: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:531 in forward, code: y = torch.mm(a, x)
aten_mm_default_1: "f32[2, 2]" = torch.ops.aten.mm.out(aten_sub_tensor, arg1_1, out = alloc_3); aten_sub_tensor = arg1_1 = alloc_3 = None
# No stacktrace found for following nodes
alloc_4: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:532 in forward, code: z = y + b
aten_add_tensor_1: "f32[2, 2]" = torch.ops.aten.add.out(aten_mm_default_1, arg2_1, out = alloc_4); aten_mm_default_1 = arg2_1 = alloc_4 = None
return (aten_add_tensor_1,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg0_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg1_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg2_1'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor_1'), target=None)])
Range constraints: {}
请注意,在图中,我们现在看到 torch.ops.aten.sub.out 和 torch.ops.aten.div.out 等操作,而不是 torch.ops.aten.sub.Tensor 和 torch.ops.aten.div.Tensor。
这是因为在运行后端传递和内存规划传递之间,为了准备内存规划的图,在图上运行 out 变体传递,将所有操作转换为其 out 变体。操作的 out 变体不会在内核实现中分配返回的张量,而是将预先分配的张量作为其 out kwarg,并将结果存储在那里,从而使内存规划器更容易进行张量生命周期分析。
我们还将 alloc 节点插入到图中,其中包含对特殊 executorch.exir.memory.alloc 操作的调用。这告诉我们 out 变体操作需要分配多少内存给每个张量输出。
保存到文件¶
最后,我们可以将 ExecuTorch 程序保存到文件,并将其加载到设备中运行。
以下是整个端到端工作流的示例
import torch
from torch._export import capture_pre_autograd_graph
from torch.export import export, ExportedProgram
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.param = torch.nn.Parameter(torch.rand(3, 4))
self.linear = torch.nn.Linear(4, 5)
def forward(self, x):
return self.linear(x + self.param).clamp(min=0.0, max=1.0)
example_args = (torch.randn(3, 4),)
pre_autograd_aten_dialect = capture_pre_autograd_graph(M(), example_args)
# Optionally do quantization:
# pre_autograd_aten_dialect = convert_pt2e(prepare_pt2e(pre_autograd_aten_dialect, CustomBackendQuantizer))
aten_dialect: ExportedProgram = export(pre_autograd_aten_dialect, example_args)
edge_program: exir.EdgeProgramManager = exir.to_edge(aten_dialect)
# Optionally do delegation:
# edge_program = edge_program.to_backend(CustomBackendPartitioner)
executorch_program: exir.ExecutorchProgramManager = edge_program.to_executorch(
ExecutorchBackendConfig(
passes=[], # User-defined passes
)
)
with open("model.pte", "wb") as file:
file.write(executorch_program.buffer)
