ExecuTorch 的高级架构和组件¶
本页介绍了 ExecuTorch 的技术架构及其各个组件。本文档面向将 PyTorch 模型部署到边缘设备的工程师。
上下文
为了针对具有不同硬件、关键功耗要求和实时处理需求的设备上 AI,单一的整体解决方案并不实用。相反,需要一个模块化、分层且可扩展的架构。ExecuTorch 定义了一个简化的工作流程来准备(导出、转换和编译)和执行 PyTorch 程序,具有默认的开箱即用组件和明确定义的自定义入口点。这种架构极大地提高了可移植性,使工程师能够使用高性能的轻量级跨平台运行时,该运行时可以轻松集成到不同的设备和平台中。
概述¶
将 PyTorch 模型部署到设备上包含三个阶段:程序准备、运行时准备和程序执行,如下图所示,包含多个用户入口点。我们将在本文档中分别讨论每个步骤。
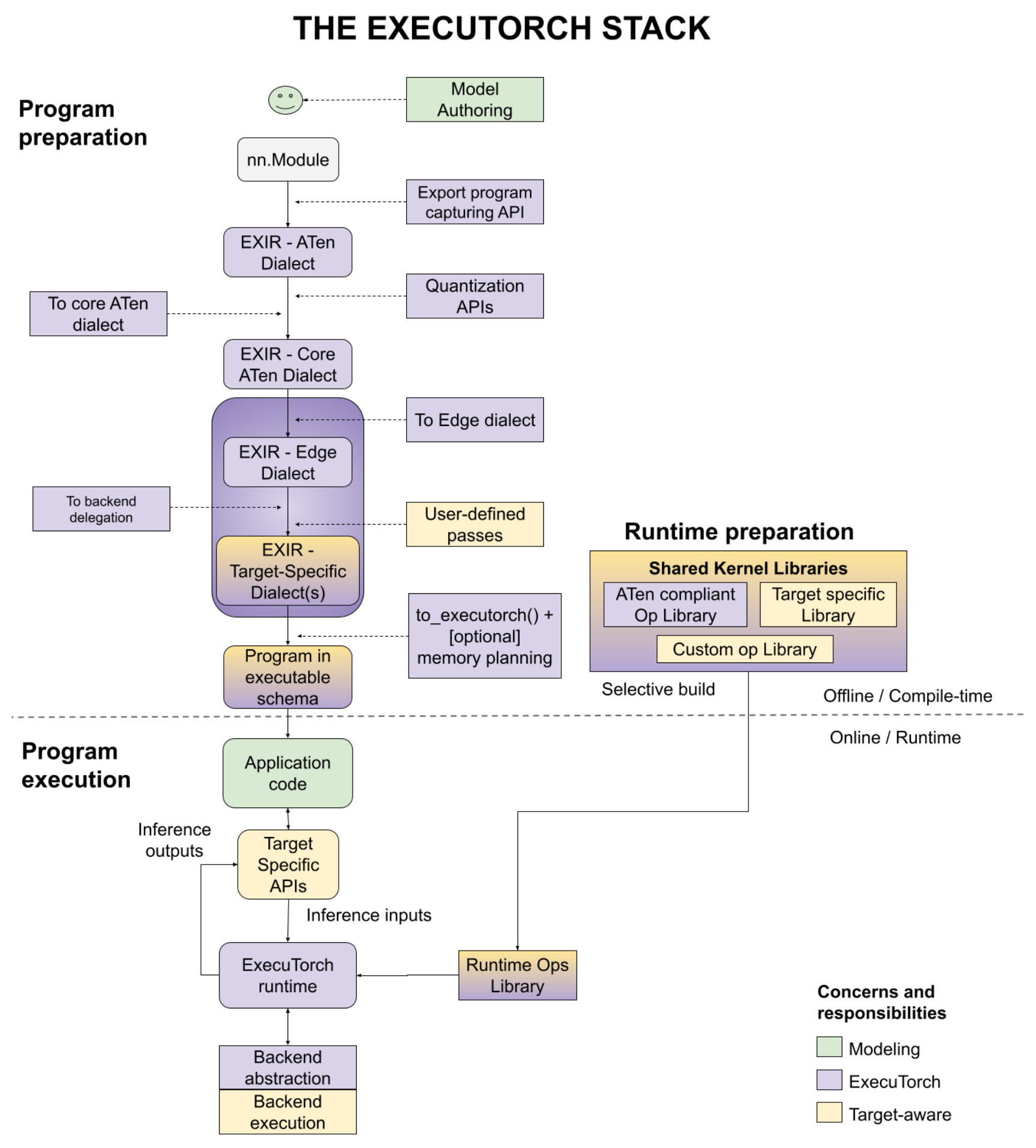
图 1. 该图说明了三个阶段 - 程序准备、运行时准备和程序执行。
程序准备¶
ExecuTorch 将 PyTorch 的灵活性和可用性扩展到边缘设备。它利用 PyTorch 2 编译器和导出功能(TorchDynamo、AOTAutograd、量化、动态形状、控制流 等)来准备在设备上执行的 PyTorch 程序。
程序准备通常简称为 AOT(提前),因为导出、转换和编译到程序是在最终使用用 C++ 编写的 ExecuTorch 运行时运行之前执行的。为了拥有轻量级的运行时和执行中的少量开销,我们尽可能地将工作推送到 AOT。
从程序源代码开始,以下是完成程序准备的步骤。
程序源代码¶
导出¶
为了将程序部署到设备上,工程师需要一个图表示,用于将模型编译成可以在各种后端运行的模型。使用 torch.export(),会生成一个 EXIR(导出中间表示),其中包含 ATen 方言。所有 AOT 编译都基于此 EXIR,但在降低路径中可能包含多个方言,如下所述。
ATen 方言。PyTorch Edge 基于 PyTorch 的张量库 ATen,该库具有明确的契约,可实现高效执行。ATen 方言是一个由 ATen 节点表示的图,这些节点完全符合 ATen 规范。允许使用自定义运算符,但必须在调度程序中注册。它被扁平化,没有模块层次结构(较大模块中的子模块),但源代码和模块层次结构保存在元数据中。此表示也支持自动微分。
可选地,可以在转换为 Core ATen 之前,将量化(无论是 QAT(量化感知训练)还是 PTQ(训练后量化))应用于整个 ATen 图。量化有助于减小模型大小,这对边缘设备很重要。
Core ATen 方言。ATen 有数千个运算符。对于某些基本转换和内核库实现来说,它并不理想。来自 ATen 方言图的运算符被分解成基本运算符,以便运算符集(op 集)更小,并且可以应用更多基本转换。Core ATen 方言也是可序列化的,并且可以转换为 Edge 方言,如下所述。
边缘编译¶
上面讨论的导出过程基于一个图,该图与最终执行代码的边缘设备无关。在边缘编译步骤中,我们处理的是特定于边缘的表示。
边缘方言。所有运算符要么符合具有数据类型和内存布局信息的 ATen 运算符(表示为
dim_order),要么是注册的自定义运算符。标量被转换为张量。这些规范允许后续步骤专注于更小的边缘领域。此外,它还支持基于特定数据类型和内存布局的选择性构建。
使用边缘方言,有两种目标感知的方式可以将图进一步降低到后端方言。在这一点上,特定硬件的委托可以执行许多操作。例如,iOS 上的 Core ML、高通上的 QNN 或 Arm 上的 TOSA 可以重写图。此级别的选项是
后端委托。将图(全部或部分)编译到特定后端的入口点。在转换过程中,已编译的图将被语义上等效的图替换。已编译的图将在运行时(也称为
delegated)卸载到后端,以提高性能。用户定义的传递。用户也可以执行特定于目标的转换。这方面的好例子包括内核融合、异步行为、内存布局转换等等。
编译为 ExecuTorch 程序¶
上面的边缘程序适合编译,但不适合运行时环境。设备部署工程师可以降低图,使其能够被运行时高效地加载和执行。
在大多数边缘环境中,动态内存分配/释放会带来显著的性能和功耗开销。可以使用 AOT 内存规划和静态执行图来避免这种情况。
ExecuTorch 运行时是静态的(从图表示的角度来看,但仍然支持控制流和动态形状)。为了避免输出创建和返回,所有函数运算符表示都转换为 out 变体(输出作为参数传递)。
用户可以选择应用自己的内存规划算法。例如,嵌入式系统可以有特定的内存层次结构。用户可以根据该内存层次结构定制自己的内存规划。
程序被发射到 ExecuTorch 运行时可以识别的格式。
最后,发射的程序可以序列化为 flatbuffer 格式。
运行时准备¶
有了序列化程序和提供的内核库(用于运算符调用)或后端库(用于委托调用),模型部署工程师现在可以为运行时准备程序。
ExecuTorch 具有 选择性构建 API,用于构建仅链接到程序使用的内核的运行时,这可以在最终应用程序中提供显著的二进制大小节省。
程序执行¶
ExecuTorch 运行时是用 C++ 编写的,依赖关系最少,以实现可移植性和执行效率。由于程序已做好 AOT 准备,因此核心运行时组件很少,包括
平台抽象层
日志记录和可选的分析
执行数据类型
内核和后端注册表
内存管理
执行器 是加载程序并执行程序的入口点。执行会从这个非常小的运行时触发相应的运算符内核或后端执行。
SDK¶
用户应该能够高效地使用上述流程从研究到生产。生产力至关重要,以便用户能够编写、优化和部署他们的模型。我们提供 ExecuTorch SDK 来提高生产力。SDK 不在图中。相反,它是一个涵盖所有三个阶段的开发人员工作流程的工具集。
在程序准备和执行过程中,用户可以使用 ExecuTorch SDK 对程序进行分析、调试或可视化。由于端到端流程都在 PyTorch 生态系统中,用户可以将性能数据与图形可视化相关联并显示,以及直接引用程序源代码和模型层次结构。我们认为这是快速迭代和将 PyTorch 程序降低到边缘设备和环境的关键组成部分。
