ExecuTorch XNNPACK 委托¶
这是 ExecuTorch XNNPACK 后端委托的高级概述。此高性能委托旨在减少 ExecuTorch 模型的 CPU 推理延迟。我们将简要介绍 XNNPACK 库,并探讨委托的整体架构和预期用例。
注意
XNNPACK 委托目前处于积极开发中,将来可能会更改
什么是 XNNPACK?¶
XNNPACK 是一个高度优化的神经网络运算符库,适用于 Android、iOS、Windows、Linux 和 macOS 环境中的 ARM、x86 和 WebAssembly 架构。它是一个开源项目,您可以在 github 上找到更多相关信息。
什么是 ExecuTorch 代理?¶
代理是后端处理和执行 ExecuTorch 程序部分的入口点。委托的 ExecuTorch 模型部分将执行委托给后端。XNNPACK 后端代理是 ExecuTorch 中众多可用代理之一。它利用 XNNPACK 第三方库,在各种 CPU 上高效地加速 ExecuTorch 程序。有关代理和开发您自己的代理的更多详细信息,请参见 此处。建议您在继续学习架构部分之前熟悉该内容。
架构¶
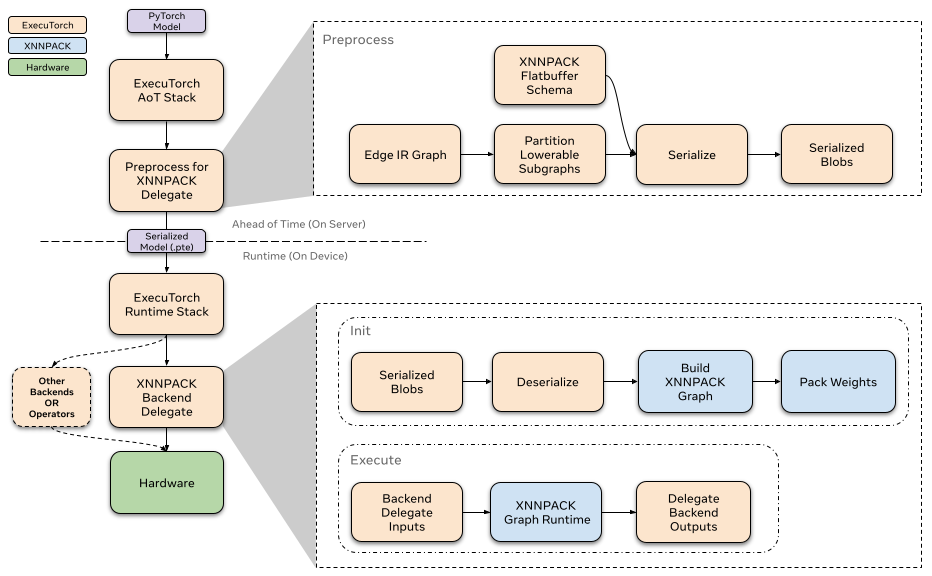
提前¶
在 ExecuTorch 导出流程中,降低到 XNNPACK 代理发生在 to_backend() 阶段。在此阶段,模型由 XnnpackPartitioner 进行分区。图的已分区部分被转换为 XNNPACK 特定的图表示,然后通过 flatbuffer 进行序列化。序列化后的 flatbuffer 然后就可以在运行时由 XNNPACK 后端反序列化和执行。

分区器¶
分区器由后端代理实现,以标记适合降低的节点。 XnnpackPartitioner 使用节点目标和模块元数据进行降低。有关分区器的更多参考,请参见 此处
基于模块的分区¶
source_fn 嵌入在节点的元数据中,并提供有关这些节点来源的信息。例如,像 torch.nn.Linear 这样的模块在被捕获并导出到 to_edge 时,会为其计算生成一组节点。与计算线性模块相关的节点组将具有 source_fn 为 torch.nn.Linear. Partitioning based on source_fn` 允许我们识别可以通过 XNNPACK 降低的节点组。
例如,在捕获 torch.nn.Linear 后,您将在与线性相关的 addmm 节点的元数据中找到以下键
>>> print(linear_node.meta["source_fn"])
'source_fn': ('fn', <class 'torch.nn.modules.linear.Linear'>)
运行时¶
XNNPACK 后端的运行时通过自定义的 init 和 execute 函数与 ExecuTorch 运行时交互。每个委托的子图都包含在一个单独序列化的 XNNPACK blob 中。当模型初始化时,ExecuTorch 会对所有 XNNPACK Blob 调用 init 以从序列化的 flatbuffer 加载子图。之后,当模型执行时,每个子图都会通过后端通过自定义的 execute 函数执行。要详细了解代理运行时如何与 ExecuTorch 交互,请参阅此 资源。
初始化¶
在调用 XNNPACK 代理的 init 时,我们通过 flatbuffer 反序列化预处理的 blob。我们使用预先序列化信息来定义节点(运算符)和边(中间张量)以构建 XNNPACK 执行图。正如我们之前提到的,大部分处理是在预先完成的,因此在运行时,我们只需连续调用 XNNPACK API 并使用序列化参数。当我们将静态数据定义到执行图中时,XNNPACK 会在运行时执行权重打包,以准备静态数据(如权重和偏差)以进行高效执行。在创建执行图后,我们创建运行时对象并将其传递给 execute。
由于权重打包会在 XNNPACK 内部创建权重的额外副本,因此我们释放了预处理的 XNNPACK Blob 内权重的原始副本,这使我们能够消除一些内存开销。
执行¶
在执行 XNNPACK 子图时,我们会准备张量输入和输出,并将它们馈送到 XNNPACK 运行时图。执行运行时图后,输出指针将填充计算出的张量。
性能分析¶
我们已为 XNNPACK 代理启用基本性能分析,可以使用以下编译器标志 -DENABLE_XNNPACK_PROFILING 启用。借助 ExecuTorch 的 SDK 集成,您现在还可以使用 SDK 工具对模型进行性能分析。您可以按照 使用 ExecuTorch SDK 对模型进行性能分析 中的步骤,了解如何对 ExecuTorch 模型进行性能分析,以及如何使用 SDK 的 Inspector API 查看 XNNPACK 的内部性能分析信息。
量化¶
XNNPACK 代理也可以用作后端来执行对称量化模型。对于量化模型委托,我们使用 XNNPACKQuantizer 对模型进行量化。 Quantizers 是特定于后端的,这意味着 XNNPACKQuantizer 被配置为对模型进行量化,以利用 XNNPACK 库提供的量化运算符。我们不会详细介绍如何实现自定义量化器,您可以按照 此处 的文档进行操作。但是,我们将简要概述如何对模型进行量化,以利用 XNNPACK 代理的量化执行。
配置 XNNPACKQuantizer¶
from torch.ao.quantization.quantizer.xnnpack_quantizer import (
XNNPACKQuantizer,
get_symmetric_quantization_config,
)
quantizer = XNNPACKQuantizer()
quantizer.set_global(get_symmetric_quantization_config())
这里我们初始化 XNNPACKQuantizer 并将量化配置设置为对称量化。对称量化是指权重以对称方式量化,其中 qmin = -127 和 qmax = 127,这将强制量化零点为零。 get_symmetric_quantization_config() 可以使用以下参数进行配置
is_per_channel权重跨通道量化
is_qat量化感知训练
is_dynamic动态量化
然后,我们可以根据需要配置 XNNPACKQuantizer。以下配置示例
quantizer.set_global(quantization_config)
.set_object_type(torch.nn.Conv2d, quantization_config) # can configure by module type
.set_object_type(torch.nn.functional.linear, quantization_config) # or torch functional op typea
.set_module_name("foo.bar", quantization_config) # or by module fully qualified name
使用 XNNPACKQuantizer 量化您的模型¶
配置完量化器后,我们就可以开始量化模型了
from torch._export import capture_pre_autograd_graph
exported_model = capture_pre_autograd_graph(model_to_quantize, example_inputs)
prepared_model = prepare_pt2e(exported_model, quantizer)
print(prepared_model.graph)
Prepare 会执行一些 Conv2d-BN 融合,并在适当的位置插入量化观察器。对于训练后量化,我们通常在此步骤之后校准模型。我们通过 prepared_model 运行示例,以观察张量的统计信息,从而计算量化参数。
最后,我们在这里转换模型
quantized_model = convert_pt2e(prepared_model)
print(quantized_model)
您现在将看到模型的 Q/DQ 表示,这意味着在量化运算符输入处插入了 torch.ops.quantized_decomposed.dequantize_per_tensor,在运算符输出处插入了 torch.ops.quantized_decomposed.quantize_per_tensor。示例
def _qdq_quantized_linear(
x_i8, x_scale, x_zero_point, x_quant_min, x_quant_max,
weight_i8, weight_scale, weight_zero_point, weight_quant_min, weight_quant_max,
bias_fp32,
out_scale, out_zero_point, out_quant_min, out_quant_max
):
x_fp32 = torch.ops.quantized_decomposed.dequantize_per_tensor(
x_i8, x_scale, x_zero_point, x_quant_min, x_quant_max, torch.int8)
weight_fp32 = torch.ops.quantized_decomposed.dequantize_per_tensor(
weight_i8, weight_scale, weight_zero_point, weight_quant_min, weight_quant_max, torch.int8)
out_fp32 = torch.ops.aten.linear.default(x_fp32, weight_fp32, bias_fp32)
out_i8 = torch.ops.quantized_decomposed.quantize_per_tensor(
out_fp32, out_scale, out_zero_point, out_quant_min, out_quant_max, torch.int8)
return out_i8
您可以在此处阅读有关 PyTorch 2 量化的更深入解释 here.
