海报
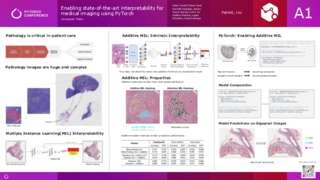
使用 PyTorch 为医学影像实现最先进的可解释性
Dinkar Juyal, Syed Asher Javed, Harshith Padigela, Limin Yu, Aaditya Prakash, Logan Kilpatrick, Anand Sampat, PathAI
PathAI 是一家总部位于波士顿的公司,专注于使用人工智能病理学改进患者护理。我们大量使用 PyTorch 构建 ML 系统,特别是对大型千兆像素病理图像进行模型训练和部署。在本案例研究中,我们重点介绍了如何使用 PyTorch 构建、实验和部署加性多实例学习 (MIL) 模型。加性 MIL 是一种基于 PyTorch Lightning 构建的新型 MIL 技术,它允许从数百万像素中进行端到端学习,同时提供空间热图的精细可解释性。这些模型能够精确计算千兆像素图像中每个较小区域对最终模型预测的贡献程度。这使得可以可视化病理图像上基于类别的兴奋性和抑制性贡献。这能让实践者了解模型失败的原因,并指导病理学家关注感兴趣的区域。这一切都得益于 PyTorch 快速的研究-原型-部署迭代周期。
计算机视觉

TorchUnmix:PyTorch 中用于组织病理学图像的自动染色分离和增强
Erik Hagendorn
TorchUnmix 是一个旨在为组织病理学全玻片图像提供自动染色分离和增强的库。组织化学染色分离(unmixing)是通过对 RGB 像素数据进行正交变换,根据预定义的光吸收系数(称为染色向量 [1])来实现的。通常使用预先计算好的公开染色向量定义,但由于组织学和/或图像采集过程导致的实验室间差异很常见,这会导致次优的分离结果。经典的染色向量估计方法依赖于染色的丰富分布,这使得它们对于免疫组织化学染色中观察到的稀疏分布不太实用。Geis 等人提出了一种基于色调-饱和度-密度颜色空间中像素值 k-means 聚类的方法来确定最佳染色向量,本工作采用了该方法 [2]。虽然染色向量可用于定量分析单个染色,但 TorchUnmix 还提供了执行染色增强的功能。染色增强是一种在深度学习模型训练过程中使用的方法,通过分离图像、随机修改单个染色,然后将这些染色合成最终的增强图像 [3],从而提高泛化能力。据我们所知,目前没有其他库在 PyTorch 中充分实现上述方法,并利用 GPU 加速。此外,TorchUnmix 已将用于执行自动染色分离和增强的所有计算扩展到对图像批次进行操作,与其他库相比,极大地加快了执行性能速度。
库

使用 Ray AIR 进行可扩展训练和推理
Kai Fricke, Balaji Veeramani
扩展机器学习很困难:像 SageMaker 这样的云平台解决方案可能会限制灵活性,但定制的分布式框架通常难以实现。实际上,ML 工程师难以将工作负载从本地原型扩展到云端。Ray AI Runtime ('Ray AIR') 是围绕分布式计算框架 Ray 构建的集成机器学习库集合。它提供了易于使用的接口,用于可扩展的数据处理、训练、调优、批处理预测和在线服务。将现有的 PyTorch 训练循环适配到 Ray AIR 的 PyTorch 集成只需修改少至 10 行代码。而从本地开发扩展到云端则无需任何代码修改。
库

AutoMAD:PyTorch 模型的混合模式自动微分
Jan Hückelheim
混合模式自动微分结合了反向传播和前向微分。这两种模式各有优缺点:反向传播对于具有许多可训练参数的标量函数效率很高。反向传播需要内存存储中间结果,需要反转数据流,对于许多输出变量的扩展性较差。前向微分易于实现、内存效率高,并且易于向量化/并行化或移植到新硬件。前向模式对于大量可训练参数的扩展性较差。AutoMAD 使得结合这两种模式成为可能。对某些层使用前向微分,同时对其他层使用反向传播。
库

xFormers:高效 Transformer 的构建块
Daniel Haziza, Francisco Massa, Jeremy Reizenstein, Patrick Labatut, Diana Liskovich
我们介绍了 xFormers,这是一个用于加速 Transformer 研究的工具箱。它包含高效的组件,例如精确且内存高效的多头注意力机制,可以在使用一小部分内存的同时将训练速度提高 2 倍。xFormers 组件也具有可定制性,可以组合起来构建 Transformer 的变体。我们希望能够推动基于 Transformer 的下一代研究。
库

linear_operator - PyTorch 中的结构化线性代数
Max Balandat
linear_operator (https://github.com/cornellius-gp/linear_operator) 是一个基于 PyTorch 构建的结构化线性代数库。它提供了一个 LinearOperator 类,表示一个永不实例化,而是通过矩阵乘法、求解、分解和索引等操作访问的张量。这些对象使用自定义的线性代数操作,可以在计算中利用特定的矩阵结构(例如对角、块对角、三角、Kronecker 等),从而在时间和内存复杂度上实现显著(多个数量级)的改进。此外,许多高效的线性代数操作(例如求解、分解、索引等)可以从 LinearOperator 的 matmul 函数中自动生成。这使得组合或实现自定义 LinearOperator 变得极其容易。使 linear_operator 易于在 PyTorch 代码中使用的关键方面是它与 `__torch_function__` 接口的集成 - 常见的线性代数操作(如矩阵乘法、求解、SVD)被映射到相应的 torch 函数(`__matmul__`、`torch.linalg.solve`、`torch.linalg.svd`),因此即使在现有代码中,LinearOperator 对象也可以作为密集张量的直接替代品。LinearOperator 操作本身可能会返回 LinearOperator 对象,并在每次计算后自动跟踪代数结构。因此,用户无需考虑使用哪些高效的线性代数例程(只要用户定义的输入元素编码了已知的输入结构)。
库

使用 Ludwig 进行声明式机器学习:使用简单灵活的数据驱动配置构建端到端机器学习管线
Justin Zhao
Ludwig 是一个声明式机器学习框架,它使用简单灵活的数据驱动配置系统,使得定义和比较机器学习管线变得容易。最少的配置声明输入和输出特征及其各自的数据类型。用户可以指定额外参数来预处理、编码和解码特征,从预训练模型加载,构建内部模型架构,设置训练参数,或运行超参数优化。Ludwig 将自动构建一个端到端机器学习管线,使用配置中明确指定的任何内容,同时对未指定的任何参数回退到智能默认值。科学家、工程师和研究人员使用 Ludwig 探索最先进的模型架构,运行超参数搜索,并在各种使用结构化和非结构化特征的问题上,扩展到大于可用内存的数据集和多节点集群。Ludwig 在 Github 上拥有 8.5K+ 星标,并构建在 PyTorch、Horovod 和 Ray 之上。
库

广义形状:块稀疏性、MaskedTensor、NestedTensor
Christian Puhrsch
本海报概述了稀疏内存格式、掩码计算以及对各种形状数据集合的支持相关的可用和正在进行的开发。特别是,它包含了一个关于块稀疏内存格式、MaskedTensor 和 NestedTensor 的案例研究。
库

Betty:一个用于广义元学习的自动微分库
Sang Keun Choe
Betty 是一个简单、可扩展且模块化的库,用于广义元学习 (GML) 和多层优化 (MLO),它构建在 PyTorch 之上,为包括少样本学习、超参数优化、神经架构搜索、数据重新加权等许多 GML/MLO 应用提供统一的编程接口。Betty 的内部自动微分机制和软件设计是通过将 GML/MLO 新颖地解释为数据流图而开发的。
库

Functorch:PyTorch 中的可组合函数变换
Samantha Andow, Richard Zhou, Horace He, Animesh Jain
受 Google JAX 启发,functorch 是 PyTorch 中的一个库,提供可组合的 vmap(向量化)和自动微分变换(grad、vjp、jvp)。自 PyTorch 1.11 发布以来,结合这些变换帮助用户开发和探索了以前在 PyTorch 中难以编写的新技术,例如神经切线核和非线性优化(参见 Theseus,也来自 PyTorch)。本文将介绍一些基本用法,并重点介绍一些利用 functorch 进行的研究。
库

偏微分方程的大规模神经求解器
Patrick Stiller, Jeyhun Rustamov, Friedrich Bethke, Maksim Zhdanov, Raj Sutarya, Mahnoor Tanveer, Karan Shah, Richard Pausch, Sunna Torge, Alexander Debus, Attila Cangi, Peter Steinbach, Michael Bussmann, Nico Hoffmann
我们的开源 Neural Solvers 框架提供基于 ML 的无数据求解器,用于自然科学现象的研究和分析,该框架构建在 PyTorch 之上。我们首次证明,由二维薛定谔方程建模的某些量子系统可以被精确求解,同时保持强大的可扩展性。我们还开发了一种新颖的神经网络架构 GatedPINN [1],将可适应域分解引入基于专家混合范式的物理信息神经网络训练中。我们的 GatedPINN 的分布式大规模训练由 Horovod 促进,从而实现了出色的 GPU 利用率,使 Neural Solvers 为即将到来的 Exascale 时代做好了准备。即将开展的项目包括更高维问题,例如 3D 激光系统和耦合模型,用于研究 Vlasov-Maxwell 系统。在新型高度可扩展计算硬件上的进一步实验为高精度 Neural Solvers 在现实世界应用中的应用铺平了道路,例如逆散射问题。
库


模型准备、联邦学习和设备端计算
Zhihan Fang
差分隐私联邦学习作为一种在保护用户隐私的同时训练机器学习模型的最有前途的方式之一,已被越来越多地采用。Meta 中围绕用户属性的现有模型主要基于传统的集中式机器学习方法。最近,由于内部和外部对用户隐私的日益关注,Meta 的机器学习团队正面临信号丢失或在模型中应用新功能以进一步提高模型性能的限制。在本文中,我们介绍了一个我们为联邦学习准备和生成模型而构建的通用框架。模型准备过程是利用传统机器学习来理解目标问题的模型结构和超参数,包括训练、推理、评估。它还需要一个模拟过程来训练目标模型结构,并理解服务器端的模拟环境,以便调整联邦学习特定的超参数。模型生成过程是生成设备兼容的模型,这些模型可以直接在用户设备上用于联邦学习。我们将联邦学习框架应用于我们的设备端模型,并与设备信号集成,以改善用户体验并保护用户隐私。
库

使用 Cooper 在 PyTorch 中进行约束优化
Jose Gallego-Posada, Juan Camilo Ramirez
Cooper (https://github.com/cooper-org/cooper) 是一个通用、深度学习优先的 PyTorch 约束优化库。Cooper (几乎!) 无缝集成到 PyTorch 中,并保留了通常的损失反向传播工作流程。如果您已经熟悉 PyTorch,使用 Cooper 将会非常轻松!这个库旨在鼓励和促进深度学习中约束优化问题的研究。Cooper 专注于非凸约束优化问题,其中损失或约束不一定“表现良好”或“理论上易处理”。此外,Cooper 被设计成可以很好地处理目标函数和约束函数的 mini-batch/随机估计。Cooper 实现了几种流行的约束优化协议,因此您可以专注于您的项目,而我们处理幕后的细节。
https://github.com/cooper-org/cooper
库

使用分布式张量进行二维并行化
Wanchao Liang, Junjie Wang
本次演讲将介绍 PyTorch 中的二维并行化(数据并行 + 张量并行),使用分布式张量,这是一个由 PyTorch Distributed 提供的基础分布式原语,它为张量并行提供了支持。我们已经证明,结合使用 FSDP + 张量并行可以使我们训练像 Transformer 这样的大型模型,并提高训练性能。我们提供端到端的训练技术,使您能够以二维并行化方式训练模型,并以分布式方式保存/加载检查点。
库

PyTorch Tabular:一个用于表格数据深度学习的框架
Manu Joseph
尽管在文本和图像等模态中表现出惊人的有效性,深度学习在表格数据方面始终落后于梯度提升,无论是在受欢迎程度还是性能上。但最近出现了一些专为表格数据创建的新模型,正在推动性能上限。然而,受欢迎程度仍然是一个挑战,因为深度学习没有像 Sci-Kit Learn 那样易于使用、即开即用的库。PyTorch Tabular 旨在改变这一状况,它是一个易于使用且灵活的框架,使得在表格数据中使用最先进的模型架构像使用 Sci-Kit Learn 一样简单。
库

Better Transformer:加速 PyTorch 中的 Transformer 推理
Michael Gschwind, Christian Puhrsch, Driss Guessous, Rui Zhu, Daniel Haziza, Francisco Massa
我们引入了 Better Transformer,这是 PyTorch 项目,通过实现 Better Transformer 的“快速路径”,开箱即用地加速 Transformer 的推理和训练。快速路径加速了 Transformer 模型中许多最常执行的函数。从 PyTorch 1.13 开始,PyTorch Core API 实现了加速操作,可以在许多 Transformer 模型(如 BERT 和 XLM-R)上提供高达 2-4 倍的加速。加速操作基于 (1) 算子和内核融合以及 (2) 利用可变序列长度 NLP 批次产生的稀疏性。除了通过快速路径改进 MultiHeadAttention 外,该模型还包括对 MultiHeadAttention 和 TransformerEncoder 模块的稀疏性支持,以便利用带有 Nested Tensors 的可变序列长度信息进行 NLP 模型训练。目前,我们通过 Better Transformer 支持 torchtext 和 Hugging Face 领域库,为文本、图像和音频模型提供了显著的加速。从下一个版本开始,PyTorch 核心将包含更快融合内核和训练支持。您今天就可以通过 PyTorch Nightlies 预览这些功能,它是即将发布的 PyTorch 版本的夜间预览版本。
库

PiPPy:PyTorch 的自动化管线并行
Ke Wen, Pavel Belevich, Anjali Sridhar
PiPPy 是一个为 PyTorch 模型提供自动化管线并行的库。利用编译器技术,PiPPy 将模型拆分为管线阶段,无需修改模型。PiPPy 还提供了一个分布式运行时,将拆分后的阶段分配到多个设备和主机上,并以重叠方式协调微批次执行。我们演示了将 PiPPy 应用于 Hugging Face 模型,在云平台上实现了 3 倍的加速。
库

使用 AWS Inferentia 进行 PyTorch 推理的实践指南
Keita Watanabe
在本次会议中,我们将逐步讲解如何使用 Inferentia 进行机器学习模型的推理过程。此外,我们还将比较其与 GPU 的推理性能,并讨论成本优势。在会议的后半部分,我们还将介绍在 Kubernetes 上进行模型部署。
优化

针对 CPU 的 PyG 性能优化
Mingfei Ma
通过更快的稀疏聚合加速 PyG 的 CPU 性能。PyG 是一个构建在 PyTorch 之上的库,用于轻松编写和训练图神经网络,它严重依赖于消息传递机制进行信息聚合。我们优化了 PyTorch 中消息传递的关键瓶颈,包括:1. Scatter Reduce:对应于 EdgeIndex 以 COO 内存格式存储时的经典 PyG 用例。2. SpMM Reduce:对应于 EdgeIndex 以 CSR 内存格式存储时的用例。
优化

PyTorch 2.0 Export 中的量化
Jerry Zhang
目前,PyTorch 架构优化 (torch.ao) 提供两种量化流程工具:eager 模式量化(beta)和 fx 图模式量化(原型)。随着 PyTorch 2.0 的到来,我们将在 PyTorch 2.0 导出路径的基础上重新设计量化。本次演讲将介绍我们在 PyTorch 2.0 导出路径中支持量化的计划、相对于先前工具的主要优势,以及模型开发者和后端开发者将如何与此流程交互。
优化

Torch-TensorRT:一个使用 TensorRT 加速 PyTorch 推理的编译器
Naren Dasan, Dheeraj Peri, Bo Wang, Apurba Bose, George Stefanakis, Nick Comly, Wei Wei, Shirong Wu, Yinghai Lu
Torch-TensorRT 是一个针对 NVIDIA GPU 的开源编译器,用于在 PyTorch 中进行高性能深度学习推理。它结合了 PyTorch 的易用性和 TensorRT 的性能,使得在 NVIDIA GPU 上优化推理工作负载变得容易。Torch-TensorRT 通过直接从 PyTorch 调用的简单 Python 和 C++ API,支持 TensorRT 中的所有优化类别,包括降低混合精度至 INT8。Torch-TensorRT 输出标准的 PyTorch 模块以及 TorchScript 格式,以允许生成一个完全自包含、可移植且带有嵌入式 TensorRT 引擎的静态模块。我们介绍了 Torch-TensorRT 的近期改进,包括新的 FX 前端,它允许开发者使用完整的 Python 工作流程来优化模型并在 Python 中扩展 Torch-TensorRT;以及统一的 Torch-TensorRT Runtime,它支持混合的 FX + TorchScript 工作流程,并讨论了该项目的未来工作。
优化

利用 oneDNN Graph 的图融合加速 PyTorch 推理
Sanchit Jain
开源的 oneDNN Graph 库通过灵活的图 API 扩展了 oneDNN,以最大化在 AI 硬件(目前是 x86-64 CPU,但 GPU 支持即将推出)上生成高效代码的优化机会。它自动识别要通过融合加速的图分区。其融合模式涉及融合计算密集型操作,如卷积、matmul 及其相邻操作,适用于推理和训练用例。自 PyTorch 1.12 以来,oneDNN Graph 已作为实验性功能得到支持,用于加速 x86-64 CPU 上的 Float32 数据类型推理。使用 BFloat16 数据类型通过 oneDNN Graph 进行推理的支持存在于 PyTorch master 分支中,因此也存在于每晚的 PyTorch 版本中。Intel Extension for PyTorch 是一个构建在 PyTorch 之上的开源库,可以视为 Intel 在 PyTorch 中进行优化的“试验场”。它利用 oneDNN Graph 进行 int8 数据类型推理。本海报展示了 PyTorch TorchBench 基准测试套件的可重现结果,以证明使用 Float32、BFloat16 和 int8 数据类型时,通过 PyTorch 和 oneDNN Graph 实现的推理加速。
优化

回归 Python:不修改 C++ 扩展 PyTorch
Alban Desmaison
本海报介绍了 PyTorch 团队设计的新扩展点,允许用户从 Python 扩展 PyTorch。我们将介绍 Tensor Subclassing、Modes 和 torch library。我们将简要描述每个扩展点,并通过内存分析、记录使用的算子、量化和自定义稀疏核等示例进行讲解,所有这些都少于 100 行代码。我们还将介绍无需直接修改 PyTorch 即可添加新设备和编写内核的新方法。
其他

PyTorch 中的函数化
Brian Hirsh
函数化是一种从发送到下游编译器的任意 PyTorch 程序中移除修改的方法。PyTorch 2.0 技术栈的核心在于捕获 PyTorch 操作图并将其发送到编译器以获得更好的性能。PyTorch 程序可以修改和别名状态,这使得它们对编译器不友好。函数化是一种技术,可以将包含可修改和别名算子的 Py满载着 PyTorch 算子的程序进行处理,在保留语义的同时移除程序中的所有修改。
其他

Walmart 搜索:在 TorchServe 上大规模提供模型服务
Pankaj Takawale, Dagshayani Kamalaharan, Zbigniew Gasiorek, Rahul Sharnagat
Walmart Search 已开始在搜索生态系统中采用深度学习,以改进各个方面的搜索相关性。作为我们的试点用例,我们希望在运行时提供计算密集型 Bert Base 模型服务,目标是实现低延迟和高吞吐量。我们有托管在 JVM 上的 Web 应用程序加载并提供多个模型服务。实验模型被加载到相同的应用程序上。这些模型体积庞大,计算成本很高。我们采用这种方法面临以下限制:用最新版本刷新模型或添加新的实验模型需要应用程序部署。单个应用程序内存压力增加。启动时加载多个 ML 模型导致启动时间变慢。由于 CPU 限制,并发并不受益(并发模型预测与顺序预测的指标)。
其他

TorchX:从本地开发到 Kubernetes 及灵活转换
Joe Doliner, Jimmy Whitaker
TorchX 对于快速开发 PyTorch 应用程序非常有益。但谈到部署,一切都不容易。随着 Docker 开发、Kubernetes 和自定义调度器,有很多东西要学。在本次演讲中,我们将讨论组织如何部署到生产环境,为什么 TorchX 是一个很棒的系统,以及我们学到的经验教训,这样你就可以避免遇到同样的问题。
生产环境

使用 PyTorch/XLA 和 Fully Sharded Data Parallel (FSDP) 进行大规模训练
Shauheen Zahirazami, Jack Cao, Blake Hechtman, Alex Wertheim, Ronghang Hu
PyTorch/XLA 使 PyTorch 用户能够在 XLA 设备(包括 Google 的 Cloud TPU)上运行其模型。PyTorch/XLA 的最新改进使得可以使用 FSDP 训练 PyTorch 模型,从而训练非常大的模型。在这项工作中,我们展示了在 Cloud TPU v4 上训练 HuggingFace GPT-2 的基准测试和硬件浮点运算利用率。
生产环境

FSDP 生产就绪性
Rohan Varma, Andrew Gu
本次演讲深入探讨了 PyTorch Fully Sharded Data Parallel (FSDP) 的最新进展,这些进展带来了更好的吞吐量、内存节省和可扩展性。这些改进消除了使用 FSDP 处理不同模态以及不同模型和数据大小模型的障碍。我们将分享将这些功能应用于特定用例(如 XLMR、FLAVA、ViT、DHEN 和 GPT3 风格模型)的最佳实践。
生产环境

使用 Kubeflow Pipelines 和 TorchX 编排 PyTorch 工作流
Erwin Huizenga, Nikita Namjoshi
TorchX 是一个通用的 PyTorch 应用程序作业启动器,可帮助 ML 实践者加快迭代时间并支持端到端生产。在本次演讲中,我们将向您展示如何使用 Kubeflow Pipeline (KFL) DSL 将 TorchX 组件构建并作为管线运行。我们将详细介绍如何使用 KFP 和 TorchX 构建组件,以及如何使用 KFP DSL 编排和运行 ML 工作流。
生产环境

一个由社区主导的 ML 编译器和基础设施项目开源生态系统
Shauheen Zahirazami, James Rubin, Mehdi Amini, Thea Lamkin, Eugene Burmako, Navid Khajouei
ML 开发常常受到框架和硬件之间不兼容性的阻碍,迫使开发者在构建 ML 解决方案时在技术上妥协。OpenXLA 是一个由社区主导的机器学习编译器和基础设施项目开源生态系统,由包括阿里巴巴、亚马逊网络服务、AMD、Arm、苹果、谷歌、英特尔、Meta、英伟达等在内的 AI/ML 领导者共同开发。它将通过允许 ML 开发者在领先的框架上构建模型,并在任何硬件后端上以高性能执行,来解决这一挑战。这种灵活性将使开发者能够为他们的项目做出正确的选择,而不是被封闭系统锁定在某个决策上。我们的社区将首先通过协作演进 XLA 编译器和 StableHLO,StableHLO 是一个可移植的 ML 计算操作集,使框架更容易跨不同硬件选项进行部署。
生产环境

在 PyTorch 中压缩 GPU 内存使用
Mao Lin, Keren Zhou, Penfei Su
有限的 GPU 内存资源常常会阻碍 GPU 加速应用的性能。虽然 PyTorch 的 Caching Allocator 旨在最大程度地减少昂贵的内存分配和释放次数,并最大限度地提高 GPU 内存资源的有效利用,但我们对常见深度学习模型的研究发现存在严重的内存碎片问题。在某些情况下,高达 50% 的 GPU 内存被浪费。为了更好地理解内存碎片的根本原因,我们开发了一个工具,它以两种方式可视化 GPU 内存使用情况:分配器视图(allocator view)和块视图(block view)。分配器视图根据每次分配或释放事件来呈现内存使用情况,而块视图显示特定内存块随时间的变化。我们的分析揭示了节省 GPU 内存的巨大潜力,这将缓解资源有限的瓶颈。通过采用交换(swapping)、激活重计算(activation recomputation)和内存碎片整理(memory defragmentation)等策略,我们成功显著减少了 GPU 内存浪费。
工具

'Brainchop':浏览器内的 MRI 体积分割与渲染
Mohamed Masoud, Farfalla Hu, Sergey Plis
在 brainchop 项目中,我们将用于结构性磁共振成像 (MRI) 体积分析的高保真预训练深度学习模型直接带入科学家和临床医生的浏览器中,无需他们具备设置 AI 解决方案的技术技能。所有这些都在一个可扩展的开源框架中实现。我们的工具是网络上第一个支持在单个浏览器中一次性完成全脑体积处理的前端 MRI 分割工具。这一特性得益于我们轻量且可靠的深度学习模型 Meshnet,它能够一次性对整个大脑进行体积处理,从而在适度的计算需求下提高准确性。高质量的客户端处理解决了隐私问题,因为数据无需离开客户端。此外,基于浏览器的实现能够利用可用的硬件加速,无论其品牌或架构如何。GitHub:https://github.com/neuroneural/brainchop
https://github.com/neuroneural/brainchop
工具

TorchBench:在开发周期中量化 PyTorch 性能
Xu Zhao, Will Constable, David Berard, Taylor Robie, Eric Han, Adnan Aziz
对于像 PyTorch 这样的机器学习框架来说,保持性能水准是一项挑战。现有的 AI 基准测试(如 MLPerf)是端到端的,因此需要大量数据集、大规模 GPU 集群和长时间的基准测试。我们开发了 TorchBench,这是一个新颖的 AI 基准测试套件,其亮点在于仅需要少量数据输入、单 GPU,并且测试延迟仅为毫秒级。TorchBench 现已作为 PyTorch 每夜构建(nightly release)流程的一部分部署,用于监控性能/正确性回归,并在最先进(SOTA)的机器学习模型上测试 PyTorch 的实验性功能。
工具

利用 OpenFold 普及生物领域的 AI
Gustaf Ahdritz, Sachin Kadyan, Will Gerecke, Luna Xia, Nazim Bouatta, Mohammed AlQuraishi
OpenFold 由哥伦比亚大学开发,是一个使用 PyTorch 实现的开源蛋白质结构预测模型。OpenFold 的目标是验证 AlphaFold 2(DeepMind 的蛋白质结构预测模型)是否可以从头复现,并在此基础上,将系统组件提供给志同道合的研究人员和学者,以便他们可以在其基础上进行构建。在这项研究中,使用了 Weights & Biases (W&B) 来加速 OpenFold 对 AlphaFold 2 的复现。W&B 的协作特性使得洞察能够从单个研究人员扩展到整个团队,并帮助解决了机器学习中的复现性挑战。
工具
