在TorchVision v0.9中,我们发布了一系列新的移动友好型模型,可用于分类、目标检测和语义分割。在本文中,我们将深入探讨模型的代码,分享重要的实现细节,解释我们如何配置和训练它们,并强调在调整过程中做出的重要权衡。我们的目标是披露通常在原始论文和模型仓库中未记录的技术细节。
网络架构
MobileNetV3架构的实现与原始论文紧密契合。它是可定制的,并提供不同的配置来构建分类、目标检测和语义分割骨干网络。它的设计遵循与MobileNetV2类似的结构,两者共享通用构建块。
我们开箱即用地提供了论文中描述的两种变体:大(Large)和小(Small)。两者都使用相同的代码构建,唯一的区别在于它们的配置,它描述了块的数量、大小、激活函数等。
配置参数
尽管可以直接编写自定义的倒置残差(InvertedResidual)设置并将其传递给MobileNetV3类,但对于大多数应用程序,我们可以通过向模型构建方法传递参数来调整现有配置。一些关键的配置参数如下:
width_mult参数是一个乘数,它影响模型的通道数量。默认值为1,通过增加或减少它,可以改变所有卷积(包括第一层和最后一层)的滤波器数量。该实现确保滤波器数量始终是8的倍数。这是一种硬件优化技巧,可以加速操作的向量化。reduced_tail参数将网络最后几个块的通道数量减半。此版本被一些目标检测和语义分割模型使用。这是一种速度优化,在MobileNetV3论文中有所描述,据报道可以在不显著影响准确性的情况下将延迟降低15%。dilated参数影响模型的最后3个倒置残差块,并将其普通深度可分离卷积转换为空洞卷积。这用于控制这些块的输出步幅,对语义分割模型的准确性具有显著的积极影响。
实现细节
下面我们提供关于该架构一些值得注意的实现细节的额外信息。MobileNetV3类负责根据提供的配置构建网络。以下是该类的一些实现细节:
- 最后一个卷积块将最后一个倒置残差块的输出扩展6倍。该实现与论文中描述的大(Large)和小(Small)配置对齐,并且可以适应乘数参数的不同值。
- 与MobileNetV2等其他模型类似,一个dropout层被放置在分类器最终的线性层之前。
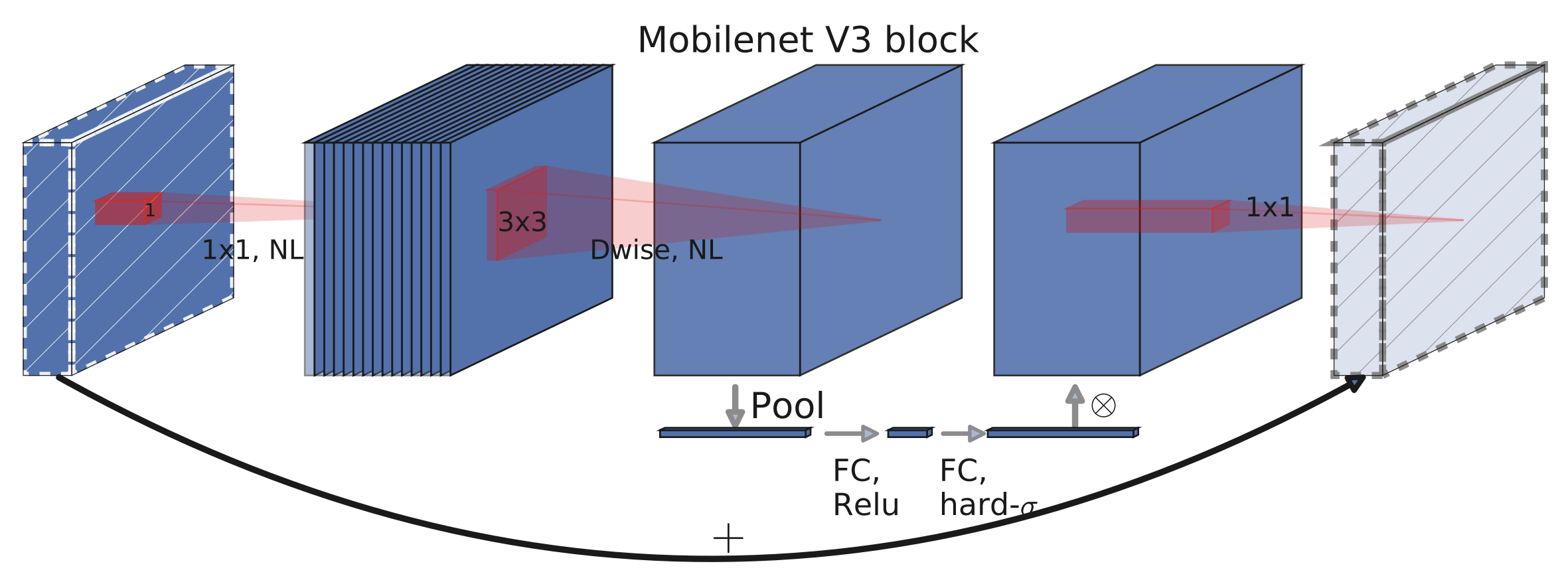
倒置残差(InvertedResidual)类是网络的主要构建块。以下是该块的一些值得注意的实现细节以及其可视化图(来自论文图4):
- 如果输入通道和扩展通道相同,则没有扩展步骤。这发生在网络的第一个卷积块中。
- 即使扩展通道与输出通道相同,也始终存在投影步骤。
- 深度可分离块的激活方法被放置在Squeeze-and-Excite层之前,因为这略微提高了准确性。
分类
在本节中,我们将提供预训练模型的基准,并详细说明它们的配置、训练和量化方式。
基准测试
以下是初始化预训练模型的方法:
large = torchvision.models.mobilenet_v3_large(pretrained=True, width_mult=1.0, reduced_tail=False, dilated=False)
small = torchvision.models.mobilenet_v3_small(pretrained=True)
quantized = torchvision.models.quantization.mobilenet_v3_large(pretrained=True)
下面是新模型与选定旧模型之间的详细基准。正如我们所看到的,MobileNetV3-Large是ResNet50的可行替代品,适用于那些愿意牺牲一点准确性以换取大约6倍速度提升的用户。
| 模型 | Acc@1 | Acc@5 | CPU推理时间(秒) | 参数数量(百万) |
|---|---|---|---|---|
| MobileNetV3-Large | 74.042 | 91.340 | 0.0411 | 5.48 |
| MobileNetV3-Small | 67.668 | 87.402 | 0.0165 | 2.54 |
| 量化MobileNetV3-Large | 73.004 | 90.858 | 0.0162 | 2.96 |
| MobileNetV2 | 71.880 | 90.290 | 0.0608 | 3.50 |
| ResNet50 | 76.150 | 92.870 | 0.2545 | 25.56 |
| ResNet18 | 69.760 | 89.080 | 0.1032 | 11.69 |
请注意,推理时间是在CPU上测量的。它们并非绝对基准,但可以用于模型之间的相对比较。
训练过程
所有预训练模型都配置为宽度乘数为1,具有完整尾部,未进行空洞卷积,并在ImageNet上进行拟合。大(Large)和小(Small)变体都使用相同的超参数和脚本进行训练,这些可以在我们的references文件夹中找到。下面我们提供关于训练过程最值得注意的方面的详细信息。
实现快速稳定的训练
正确配置RMSProp对于实现数值稳定的快速训练至关重要。论文的作者在他们的实验中使用了TensorFlow,并在他们的运行中报告使用了与默认值相比相当高的rmsprop_epsilon。通常这个超参数取小值,因为它用于避免零分母,但在这种特定模型中,选择正确的值对于避免损失中的数值不稳定性似乎很重要。
另一个重要的细节是,尽管PyTorch和TensorFlow的RMSProp实现通常表现相似,但在我们的设置中,处理epsilon超参数的方式存在一些差异。更具体地说,PyTorch将epsilon添加在平方根计算之外,而TensorFlow将其添加在内部。这个实现细节导致在移植论文的超参数时需要调整epsilon值。一个合理的近似值可以用公式PyTorch_eps = sqrt(TF_eps)来表示。
通过调整超参数和改进训练配方来提高准确性
在配置优化器以实现快速稳定的训练后,我们转而优化模型的准确性。有几种技术帮助我们实现了这一点。首先,为了避免过拟合,我们使用AutoAugment算法对数据进行了增强,然后是RandomErasing。此外,我们通过交叉验证调整了诸如权重衰减等参数。我们还发现,在训练结束后,对不同时期检查点进行权重平均是有益的。最后,虽然未在我们的发布训练配方中使用,但我们发现使用标签平滑(Label Smoothing)、随机深度(Stochastic Depth)和学习率噪声注入(LR noise injection)可以将整体准确性提高超过1.5个百分点。
图表和表格描绘了MobileNetV3 Large变体准确性改进过程中最重要迭代的简化摘要。请注意,训练模型时实际进行的迭代次数要多得多,并且准确性进步并非总是单调递增的。另请注意,图表的Y轴从70%而不是0%开始,以使迭代之间的差异更明显。
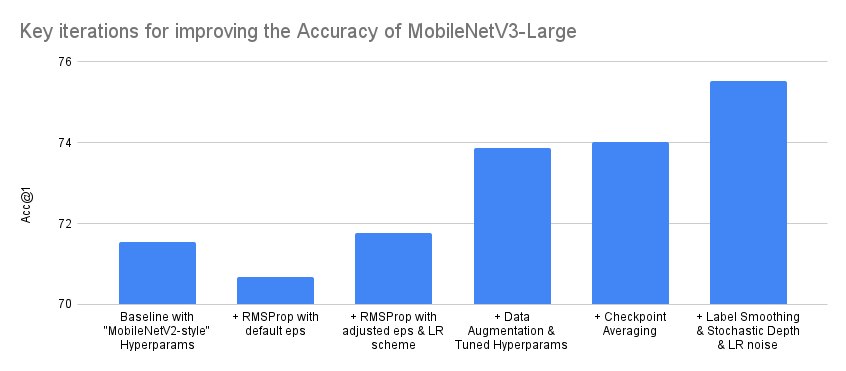
| 迭代 | Acc@1 | Acc@5 |
|---|---|---|
| 基线与“MobileNetV2风格”超参数 | 71.542 | 90.068 |
| + RMSProp,默认eps | 70.684 | 89.38 |
| + RMSProp,调整后的eps和学习率方案 | 71.764 | 90.178 |
| + 数据增强和调整后的超参数 | 73.86 | 91.292 |
| + 检查点平均 | 74.028 | 91.382 |
| + 标签平滑 & 随机深度 & 学习率噪声 | 75.536 | 92.368 |
请注意,一旦我们达到可接受的准确性,我们就会在之前未用于训练或超参数调整的保留测试数据集上验证模型性能。此过程有助于我们检测过拟合,并且在所有预训练模型发布之前都会执行。
量化
我们目前为MobileNetV3-Large变体的QNNPACK后端提供量化权重,可实现2.5倍的加速。为了量化模型,使用了量化感知训练(QAT)。用于训练模型的超参数和脚本可以在我们的references文件夹中找到。
值得注意的是,QAT允许我们模拟量化的影响并调整权重,从而提高模型精度。这使得与简单的训练后量化相比,精度提高了1.8个点。
| 量化状态 | Acc@1 | Acc@5 |
|---|---|---|
| 非量化 | 74.042 | 91.340 |
| 量化感知训练 | 73.004 | 90.858 |
| 训练后量化 | 71.160 | 89.834 |
目标检测
在本节中,我们将首先提供已发布模型的基准,然后讨论如何在特征金字塔网络中结合MobileNetV3-Large骨干网与FasterRCNN检测器来执行目标检测。我们还将解释网络的训练和调整方式以及我们必须做出的权衡。我们将不涉及它与SSDlite的使用细节,因为这将在未来的文章中讨论。
基准测试
以下是模型的初始化方式:
high_res = torchvision.models.detection.fasterrcnn_mobilenet_v3_large_fpn(pretrained=True)
low_res = torchvision.models.detection.fasterrcnn_mobilenet_v3_large_320_fpn(pretrained=True)
下面是一些新模型和选定旧模型之间的基准测试。正如我们所看到的,对于那些愿意牺牲一些精度以换取5倍速度提升的用户来说,带有MobileNetV3-Large FPN骨干网的高分辨率Faster R-CNN似乎是等效ResNet50模型的可行替代品。
| 模型 | mAP | CPU推理时间(秒) | 参数数量(百万) |
|---|---|---|---|
| Faster R-CNN MobileNetV3-Large FPN (高分辨率) | 32.8 | 0.8409 | 19.39 |
| Faster R-CNN MobileNetV3-Large 320 FPN (低分辨率) | 22.8 | 0.1679 | 19.39 |
| Faster R-CNN ResNet-50 FPN | 37.0 | 4.1514 | 41.76 |
| RetinaNet ResNet-50 FPN | 36.4 | 4.8825 | 34.01 |
实现细节
检测器使用FPN风格的骨干网络,该网络从MobileNetV3模型的不同卷积中提取特征。默认情况下,预训练模型使用第13个倒置残差块的输出和池化层之前的卷积输出,但该实现支持使用更多阶段的输出。
从网络中提取的所有特征图都通过FPN块将其输出投影到256个通道,因为这大大提高了网络的速度。FPN骨干网提供的这些特征图被FasterRCNN检测器用于在不同尺度上提供边界框和类别预测。
训练与调优过程
我们目前提供两个预训练模型,能够在不同分辨率下进行目标检测。这两个模型均在COCO数据集上使用相同的超参数和脚本进行训练,这些可以在我们的references文件夹中找到。
高分辨率检测器使用800-1333像素的图像进行训练,而移动友好的低分辨率检测器使用320-640像素的图像进行训练。我们提供两组独立的预训练权重的原因是,直接在较小的图像上训练检测器比将小图像传递给预训练的高分辨率模型可以提高5 mAP的精度。两个骨干网都使用在ImageNet上拟合的权重进行初始化,并且其权重的最后三个阶段在训练过程中进行了微调。
通过调整RPN NMS阈值,可以对移动友好模型进行额外的速度优化。通过仅牺牲0.2 mAP的精度,我们能够将模型的CPU速度提高约45%。优化的详细信息如下所示:
| 调优状态 | mAP | CPU推理时间(秒) |
|---|---|---|
| 之前 | 23.0 | 0.2904 |
| 之后 | 22.8 | 0.1679 |
下面我们提供了一些可视化Faster R-CNN MobileNetV3-Large FPN模型预测的示例。

语义分割
在本节中,我们将首先提供已发布的预训练模型的基准。然后,我们将讨论MobileNetV3-Large骨干网络如何与LR-ASPP、DeepLabV3和FCN等分割头结合进行语义分割。我们还将解释网络的训练方式,并提出一些针对速度关键应用的可选优化技术。
基准测试
以下是初始化预训练模型的方法:
lraspp = torchvision.models.segmentation.lraspp_mobilenet_v3_large(pretrained=True)
deeplabv3 = torchvision.models.segmentation.deeplabv3_mobilenet_v3_large(pretrained=True)
下面是新模型与选定现有模型之间的详细基准。正如我们所看到的,带有MobileNetV3-Large骨干网的DeepLabV3对于大多数应用来说是FCN与ResNet50的可行替代品,因为它以8.5倍的速度提升实现了相似的准确性。我们还观察到LR-ASPP网络在所有指标上都超越了等效的FCN。
| 模型 | 平均交并比 (mIoU) | 全局像素精度 | CPU推理时间(秒) | 参数数量(百万) |
|---|---|---|---|---|
| LR-ASPP MobileNetV3-Large | 57.9 | 91.2 | 0.3278 | 3.22 |
| DeepLabV3 MobileNetV3-Large | 60.3 | 91.2 | 0.5869 | 11.03 |
| FCN MobileNetV3-Large (未发布) | 57.8 | 90.9 | 0.3702 | 5.05 |
| DeepLabV3 ResNet50 | 66.4 | 92.4 | 6.3531 | 39.64 |
| FCN ResNet50 | 60.5 | 91.4 | 5.0146 | 32.96 |
实现细节
在本节中,我们将讨论已测试分割头的重要实现细节。请注意,本节中描述的所有模型都使用空洞MobileNetV3-Large骨干网。
LR-ASPP
LR-ASPP是MobileNetV3论文作者提出的Reduced Atrous Spatial Pyramid Pooling模型的精简变体。与TorchVision中的其他分割模型不同,它不使用辅助损失。相反,它使用低级和高级特征,输出步幅分别为8和16。
与论文中使用带有可变步长的49×49 AveragePooling层不同,我们的实现使用`AdaptiveAvgPool2d`层来处理全局特征。这是因为论文作者根据Cityscapes数据集定制了头部,而我们的重点是提供一个适用于多个数据集的通用实现。最后,我们的实现始终在返回输出之前进行双线性插值,以确保输入和输出图像的大小完全匹配。
DeepLabV3 & FCN
MobileNetV3与DeepLabV3和FCN的结合与其它模型紧密相似,这些方法的阶段估计与LR-ASPP相同。唯一值得注意的区别是,我们没有使用高级和低级特征,而是将正常损失附加到输出步幅为16的特征图上,并将辅助损失附加到输出步幅为8的特征图上。
最后,我们应该指出,FCN版本的模型没有发布,因为它在速度和准确性方面完全被LR-ASPP取代。预训练权重仍然可用,只需对代码进行少量更改即可使用。
训练和调优过程
我们目前提供两个能够进行语义分割的MobileNetV3预训练模型:LR-ASPP和DeepLabV3。这些模型的骨干网络使用ImageNet权重进行初始化,并进行端到端训练。两种架构都使用相同的脚本和相似的超参数在COCO数据集上进行训练。它们的详细信息可以在我们的references文件夹中找到。
通常,在推理过程中,图像会调整大小到520像素。一个可选的速度优化是通过使用高分辨率预训练权重并将其推理调整大小减少到320像素来构建模型的低分辨率配置。这将使CPU执行时间提高约60%,同时牺牲几个mIoU点。此优化的详细数字可在下表中找到。
| 低分辨率配置 | mIoU差异 | 速度提升 | 平均交并比 (mIoU) | 全局像素精度 | CPU推理时间(秒) |
|---|---|---|---|---|---|
| LR-ASPP MobileNetV3-Large | -2.1 | 65.26% | 55.8 | 90.3 | 0.1139 |
| DeepLabV3 MobileNetV3-Large | -3.8 | 63.86% | 56.5 | 90.3 | 0.2121 |
| FCN MobileNetV3-Large (未发布) | -3.0 | 57.57% | 54.8 | 90.1 | 0.1571 |
以下是一些可视化LR-ASPP MobileNetV3-Large模型预测的示例。

我们希望您觉得这篇文章有趣。我们期待您的反馈,以了解您希望我们更频繁地发布哪些类型的内容。如果社区认为此类帖子有用,我们很乐意发布更多涵盖新引入机器学习模型实现细节的文章。