在这篇文章中,我们将讨论 Torchserve 的性能调优,以便在生产环境中部署您的模型。在机器学习项目的生命周期中,最大的挑战之一就是将模型部署到生产环境中。这需要一个可靠的服务解决方案,以及能够满足 MLOps 需求的解决方案。一个强大的服务解决方案需要支持多模型服务、模型版本控制、指标日志记录、监控和扩展以处理高峰流量。在这篇文章中,我们将概述 Torchserve,以及如何针对生产用例调整其性能。我们将讨论 Meta 的 动画绘图应用程序,它可以将您的人物素描转换为动画,以及它如何通过 Torchserve 处理高峰流量。动画绘图的工作流程如下。
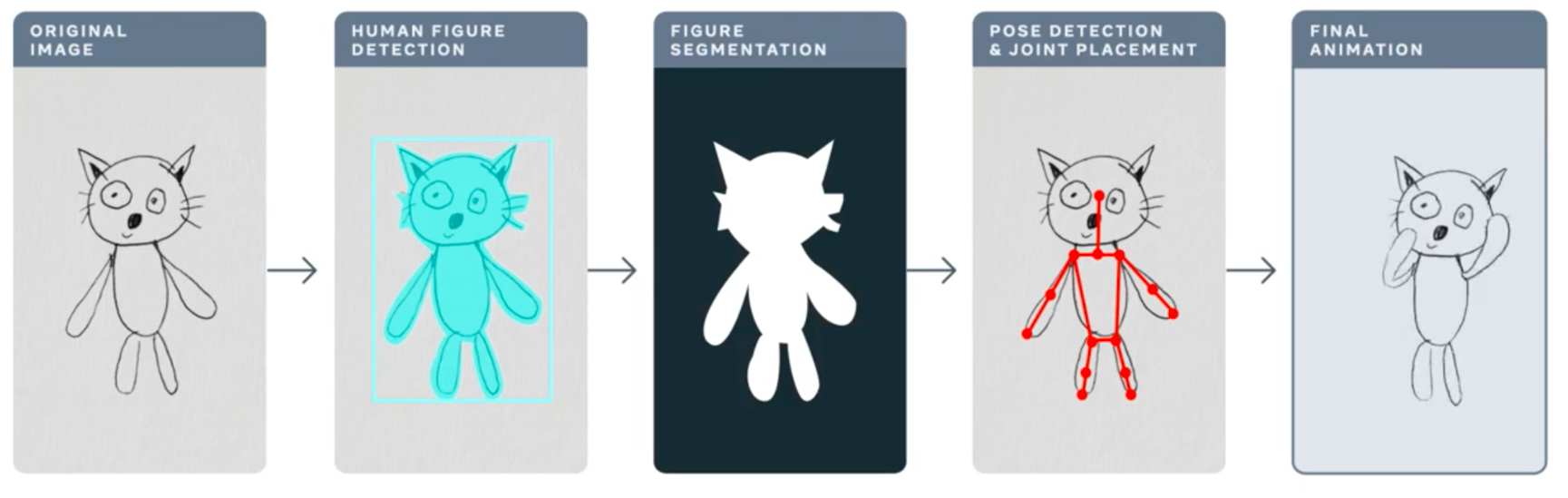
https://ai.facebook.com/blog/using-ai-to-bring-childrens-drawings-to-life
许多人工智能系统和工具都旨在处理逼真的人类图像,儿童的绘画增加了复杂性和不可预测性,因为它们通常以抽象、奇特的方式构建。这些类型的形态和风格变化甚至会混淆在识别逼真图像和绘画中的物体方面表现出色最先进的人工智能系统。Meta AI 的研究人员正在努力克服这一挑战,以便人工智能系统能够更好地识别儿童以各种各样的方式创作的人体绘画。这篇精彩的博客文章提供了有关动画绘画和所采用方法的更多详细信息。
Torchserve
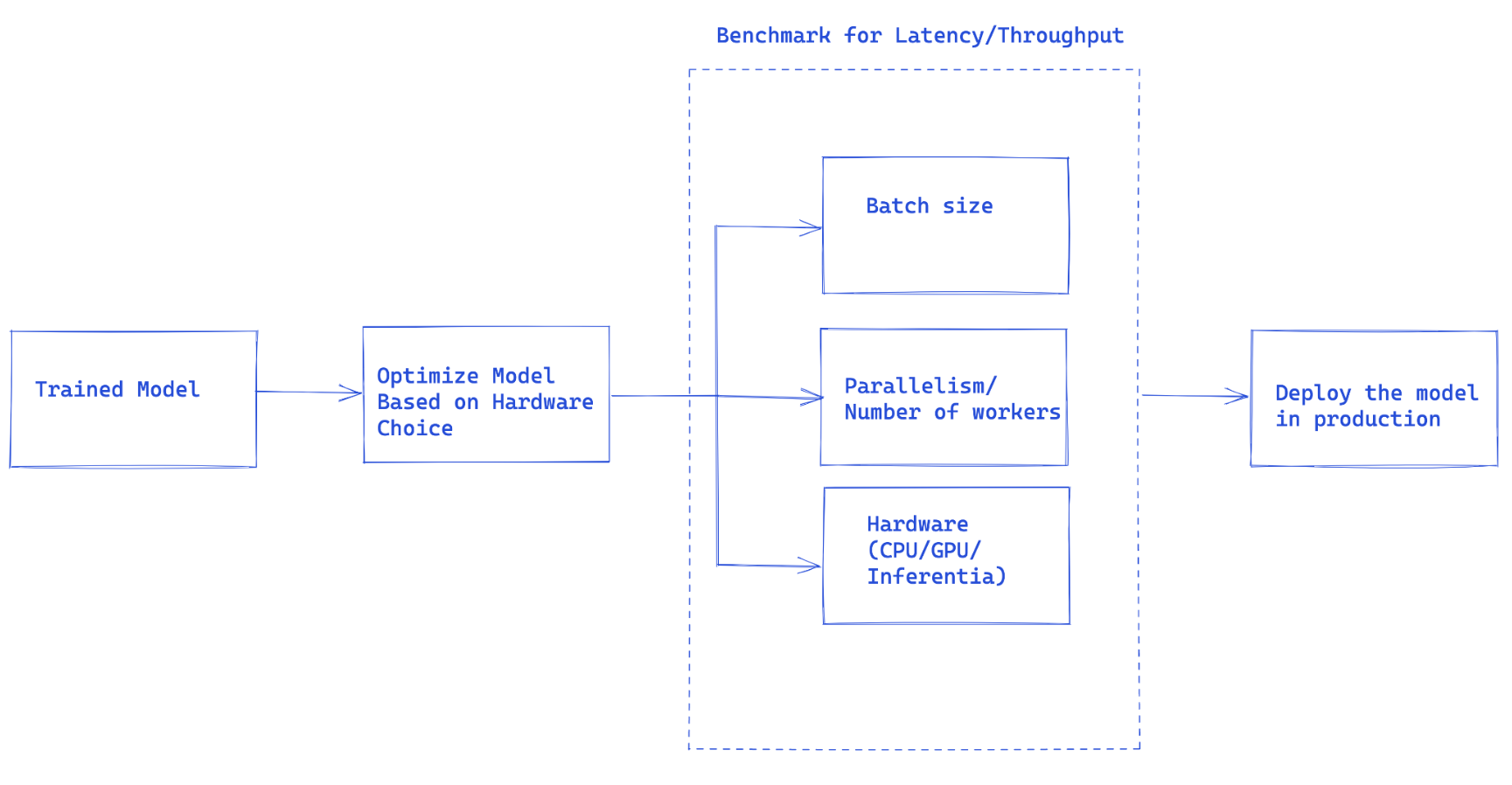
图 1. Torchserve 性能调优的整体流程
一旦您训练好模型,就需要将其集成到一个更大的系统中,以形成一个完整的应用程序。我们使用“模型服务”一词来指代这种集成。基本上,模型服务就是使您训练好的模型能够运行推理并后续使用该模型。
Torchserve 是 Pytorch 首选的生产模型服务解决方案。它是一个高性能、可扩展的工具,可将您的模型封装在 HTTP 或 HTTPS API 中。它有一个用 Java 实现的前端,负责处理从分配 worker 服务模型到处理客户端和服务器之间连接的多个任务。Torchserve 有一个 Python 后端,负责处理推理服务。
Torchserve 支持多模型服务和 A/B 测试的版本控制、动态批处理、日志记录和指标。它公开了四个 API:推理、解释、管理和指标。
推理 API 默认监听端口 8080,可通过 localhost 访问,这可以在 Torchserve 配置中配置,并启用从模型获取预测。
解释 API 在底层使用 Captum 提供正在服务的模型的解释,并且也监听端口 8080。
管理 API 允许注册或注销并描述模型。它还允许用户增加或减少服务模型的 worker 数量。
指标 API 默认监听端口 8082,使我们能够监控正在服务的模型。
Torchserve 通过支持批量推理和多个服务您模型的 worker 来让您扩展模型服务并处理高峰流量。可以通过管理 API 和通过配置文件的设置来完成扩展。此外,指标 API 通过默认和可自定义的指标帮助您监控模型服务。
其他高级设置,例如接收请求队列的长度、批量输入的ado等待时间以及许多其他属性,都可以通过在启动 Torchserve 时传递的配置文件进行配置。
使用 Torchserve 部署模型的步骤
- 安装 Torchserve、模型归档器及其依赖项。
- 选择适合您任务的默认处理程序(例如图像分类等)或编写自定义处理程序。
- 使用Torcharchive将您的模型工件(训练好的模型检查点和加载和运行模型所需的所有其他文件)和处理程序打包成“.mar”文件,并将其放置在模型存储中。
- 开始服务您的模型.
- 运行推理。我们将在这里更详细地讨论模型处理程序和指标。
模型处理程序
Torchserve 在后端使用处理程序来加载模型、预处理接收到的数据、运行推理和后处理响应。Torchserve 中的处理程序是一个**Python 脚本**,所有模型初始化、预处理、推理和后处理逻辑都包含在其中。
Torchserve 为图像分类、分割、对象检测和文本分类等多种应用程序提供了开箱即用的处理程序。如果您的用例不受默认处理程序支持,它还支持自定义处理程序。
它在自定义处理程序中提供了极大的灵活性,这可能使 Torchserve 成为**多框架**服务工具。自定义处理程序允许您定义自定义逻辑来初始化模型,该模型也可以用于从 ONNX 等其他框架加载模型。
Torchserve 的**处理程序**由四个主要**函数**组成:**初始化 (initialize)**、**预处理 (preprocess)**、**推理 (inference)** 和**后处理 (postprocess)**,每个函数都返回一个列表。下面的代码片段显示了一个自定义处理程序的示例。**自定义处理程序继承**自 Torchserve 中的 **BaseHandler**,并且可以**重写**任何**主要函数**。下面是用于加载 Detectron2 模型进行人物检测的处理程序示例,该模型已导出到 Torchscript 并使用 model.half() 进行 FP16 推理,具体细节将在本文的另一部分中解释。
class MyModelHandler(BaseHandler):
def initialize(self, context):
self.manifest = ctx.manifest
properties = ctx.system_properties
model_dir = properties.get("model_dir")
serialized_file = self.manifest["model"]["serializedFile"]
model_pt_path = os.path.join(model_dir, serialized_file)
self.device = torch.device(
"cuda:" + str(properties.get("gpu_id"))
if torch.cuda.is_available() and properties.get("gpu_id") is not None
else "cpu"
)
self.model = torch.jit.load(model_pt_path, map_location=self.device)
self.model = self.model.half()
def preprocess(self, data):
inputs = []
for request in batch:
request_body = request.get("body")
input_ = io.BytesIO(request_body)
image = cv2.imdecode(np.fromstring(input_.read(), np.uint8), 1)
input = torch.Tensor(image).permute(2, 0, 1)
input = input.to(self.device)
input = input.half()
inputs.append({"image": input})
return inputs
def inference(self,inputs):
predictions = self.model(**inputs)
return predictions
def postprocess(self, output):
responses = []
for inference_output in inference_outputs:
responses_json = {
'classes': inference_output['pred_classes'].tolist(),
'scores': inference_output['scores'].tolist(),
"boxes": inference_output['pred_boxes'].tolist()
}
responses.append(json.dumps(responses_json))
return responses
指标
在生产环境中部署模型的一个基本组件是监控模型的能力。**Torchserve 定期**收集**系统级**指标,并且还**允许**添加**自定义指标**。
系统级指标包括主机上的 CPU 利用率、可用和已用磁盘空间以及内存,以及具有不同响应代码(例如 200-300、400-500 和 500 以上)的请求数量。可以在此处添加自定义指标。TorchServe 将这两组指标记录到不同的日志文件中。指标默认收集在:
- 系统指标 – log_directory/ts_metrics.log
- 自定义指标 – log directory/model_metrics.log
如前所述,Torchserve 还公开了指标 API,该 API 默认监听端口 8082,使用户能够查询和监控收集到的指标。默认的指标端点返回 Prometheus 格式的指标。您可以使用 curl 请求查询指标,或者将Prometheus 服务器指向该端点,并使用Grafana来创建仪表板。
在部署模型时,您可以使用 curl 请求查询指标,如下所示:
curl http://127.0.0.1:8082/metrics
如果您想导出已记录的指标,请参阅此示例,该示例使用 mtail 将指标导出到 Prometheus。在仪表板中跟踪这些指标可以帮助您监控可能在离线基准测试运行中偶然发生或难以发现的性能退化。
在生产环境中优化模型性能的考量因素
图 1 中建议的工作流程是使用 Torchserve 处理模型生产部署的总体思路。
在许多情况下,生产模型服务是根据吞吐量或延迟服务水平协议 (SLA) 进行**优化**的。通常,**实时应用**更关注**延迟**,而**离线应用**可能更关注更高的**吞吐量**。
有许多主要因素会影响生产环境中服务模型的性能。特别是,我们这里关注的是使用 Torchserve 服务 Pytorch 模型,但其中大部分因素也适用于其他框架的所有模型。
- **模型优化**:这是将模型部署到生产环境的预备步骤。这是一个非常广泛的讨论,我们将在未来的一系列博客中深入探讨。这包括量化、剪枝以减小模型大小、使用中间表示(IR 图)例如 Pytorch 中的 Torchscript、融合内核等技术。目前,torchprep 提供了许多这些技术作为 CLI 工具。
- **批量推理:**它指的是将多个输入送入模型,这在训练过程中至关重要,在推理时管理成本也非常有帮助。硬件加速器针对并行性进行了优化,批量处理有助于使计算能力饱和,并通常导致更高的吞吐量。推理中的主要区别在于您不能等待太长时间才能从客户端填充批次,这称为动态批量处理。
- **Worker 数量:** Torchserve 使用 worker 来服务模型。Torchserve worker 是 Python 进程,它们保存模型权重的副本以运行推理。worker 过少意味着您没有充分利用并行性,但 worker 过多会导致 worker 争用并降低端到端性能。
- **硬件:**根据模型、应用以及延迟、吞吐量预算选择合适的硬件。这可能是 Torchserve 支持的硬件之一,**CPU、GPU、AWS Inferentia**。有些硬件配置旨在实现最佳性能,而另一些则更适合经济高效的推理。根据我们的实验,我们发现 GPU 在较大的批次大小下表现最佳,而合适的 CPU 和 AWS Inferentia 对于较小的批次大小和低延迟则更具成本效益。
Torchserve 性能调优的最佳实践
为了在使用 Torchserve 部署模型时获得最佳性能,我们在这里分享一些最佳实践。Torchserve 提供了一个基准测试套件,可以提供有用的见解,以便对如下所述的不同选择做出明智的决定。
- **优化您的模型**是第一步,Pytorch 模型优化教程。**模型优化**选择也与**硬件**选择密切**相关**。我们将在另一篇博客文章中更详细地讨论它。
- **决定**模型部署的**硬件**可能与延迟、吞吐量预算以及每次推理的成本密切相关。根据模型和应用程序的大小,它可能会有所不同。对于某些模型,如计算机视觉模型,在 CPU 上生产运行历史上一直是不划算的。然而,通过在 Torchserve 中添加诸如 IPEX 等优化,这变得更加经济和具有成本效益,您可以在此项调查性的案例研究中了解更多信息。
- Torchserve 中的**worker**是提供并行性的 Python 进程,应仔细设置 worker 数量。默认情况下,Torchserve 启动的 worker 数量等于主机上的 VCPU 或可用 GPU 数量,这可能会大大增加 Torchserve 的启动时间。Torchserve 公开了一个配置属性来设置 worker 数量。为了通过**多个 worker**提供**高效的并行性**并避免它们争用资源,我们**建议**在 CPU 和 GPU 上遵循以下设置作为基准:**CPU**:在处理程序中,设置 `torch.set_num_threads(1)`,然后将 worker 数量设置为 `num physical cores / 2`。但最佳的线程配置可以通过利用 Intel CPU 启动脚本来实现。**GPU**:可用 GPU 的数量可以通过 config.properties 中的number_gpus来设置。Torchserve 使用轮询方式将 worker 分配给 GPU。我们建议按如下方式设置 worker 数量:`worker 数量 = (可用 GPU 数量) / (独特模型数量)`。请注意,Ampere 之前的 GPU 不提供任何多实例 GPU 的资源隔离。
- **批处理大小**可以直接影响延迟和吞吐量。为了更好地利用计算资源,需要增加批处理大小。然而,延迟和吞吐量之间存在权衡。**较大的批处理大小**可以**提高吞吐量,但也会导致更高的延迟**。批处理大小可以通过两种方式在 Torchserve 中设置,要么通过 config.properties 中的模型配置,要么在注册模型时使用管理 API。
在下一节中,我们将使用 Torchserve 基准测试套件来决定模型优化、硬件、worker 和批处理大小的最佳组合。
动画绘图性能调优
要使用 Torchserve 基准测试套件,首先我们需要一个归档文件,即如上所述的“.mar”文件,其中包含模型、处理程序以及所有其他用于加载和运行推理的工件。动画绘图使用 Detectron2 的 Mask-RCNN 实现作为对象检测模型。
如何运行基准测试套件
Torchserve 中的自动化基准测试套件允许您使用不同的设置(包括批处理大小和 worker 数量)对多个模型进行基准测试,并最终为您生成报告。要开始:
git clone https://github.com/pytorch/serve.git
cd serve/benchmarks
pip install -r requirements-ab.txt
apt-get install apache2-utils
模型级设置可以在类似如下的 yaml 文件中配置
Model_name:
eager_mode:
benchmark_engine: "ab"
url: "Path to .mar file"
workers:
- 1
- 4
batch_delay: 100
batch_size:
- 1
- 2
- 4
- 8
requests: 10000
concurrency: 10
input: "Path to model input"
backend_profiling: False
exec_env: "local"
processors:
- "cpu"
- "gpus": "all"
此 yaml 文件将在 `benchmark_config_template.yaml` 文件中引用,该文件包含用于生成报告的其他设置,它还可以选择与 AWS CloudWatch 配合使用以获取日志。
python benchmarks/auto_benchmark.py --input benchmark_config_template.yaml
**运行基准测试**后,结果将写入“csv”文件,可在“_ /tmp/benchmark/ab_report.csv_”中找到,完整报告在“/tmp/ts_benchmark/report.md”中。它将包括 Torchserve 平均延迟、模型 P99 延迟、吞吐量、并发数、请求数、处理程序时间以及其他一些指标。这里我们重点关注我们跟踪的一些重要指标,这些指标用于调整性能,它们是**并发性**、**模型 P99 延迟**、**吞吐量**。我们特别关注这些数字与**批处理大小**、使用的**设备**、**worker 数量**以及是否进行了任何**模型优化**的**组合**。
该模型的**延迟 SLA** 已设置为**100 毫秒**,这是一个实时应用程序,正如我们之前讨论的,延迟更受关注,而**吞吐量**理想情况下应该尽可能高,同时**不违反延迟 SLA。**
通过搜索空间,在不同的批处理大小(1-32)、worker 数量(1-16)和设备(CPU、GPU)上,我们运行了一系列实验,下表总结了其中最好的结果。
| 设备 | 并发性 | 请求数 | Worker 数量 | 批次大小 | Payload/图像 | 优化 | 吞吐量 | P99 延迟 |
| CPU | 10 | 1000 | 1 | 1 | 小 | 不适用 | 3.45 | 305.3 毫秒 |
| CPU | 1 | 1000 | 1 | 1 | 小 | 不适用 | 3.45 | 291.8 毫秒 |
| GPU | 10 | 1000 | 1 | 1 | 小 | 不适用 | 41.05 | 25.48 毫秒 |
| GPU | 1 | 1000 | 1 | 1 | 小 | 不适用 | 42.21 | 23.6 毫秒 |
| GPU | 10 | 1000 | 1 | 4 | 小 | 不适用 | 54.78 | 73.62 毫秒 |
| GPU | 10 | 1000 | 1 | 4 | 小 | model.half() | 78.62 | 50.69 毫秒 |
| GPU | 10 | 1000 | 1 | 8 | 小 | model.half() | 85.29 | 94.4 毫秒 |
该模型在 CPU 上,在所有尝试过的批处理大小、并发性和 worker 数量设置下,延迟均未达到 SLA,实际上高出了约 13 倍。
**将模型服务****转移到 GPU**,可以立即将**延迟**从 305 毫秒**提高**约 **13 倍**,降至 23.6 毫秒。
我们可以对模型进行的最**简单**的**优化**之一是将其精度降低到 **fp16**,这只需一行代码(**model.half()**),可以将**模型 P99 延迟**减少 **32%**,并以几乎相同的幅度提高吞吐量。
还可以通过对模型进行 Torchscript 优化并使用optimize_for_inference或其他技巧(包括 onnx 或 tensorrt 运行时优化,它们利用激进融合)进行其他优化,这些超出了本文的范围。我们将在单独的帖子中讨论模型优化。
我们发现在 CPU 和 GPU 上,将**worker 数量设置为 1** 在本例中效果最佳。
- 将模型迁移到 GPU,使用**worker 数量 = 1**,**批处理大小 = 1**,与 **CPU 相比,吞吐量增加了约 12 倍**,**延迟减少了约 13 倍**。
- 将模型迁移到 GPU,使用 **model.half()**,**worker 数量 = 1**,**批处理大小 = 8**,在**吞吐量**方面取得了**最佳**结果,并且延迟仍在可容忍范围内。(**与 CPU 相比,吞吐量增加了约 25 倍**,**延迟仍满足 SLA(94.4 毫秒)**)。
注意:如果您正在运行基准测试套件,请确保设置了适当的 `batch_delay`,并将请求的并发数设置为与您的批处理大小成比例的数字。这里的并发性指的是发送到服务器的并发请求数量。
结论
在这篇文章中,我们讨论了 Torchserve 在生产环境中调整性能时需要考虑的因素和可用的配置。我们探讨了 Torchserve 基准测试套件作为一种工具,可以帮助我们调整性能并深入了解模型优化、硬件选择和总体成本的可能选项。我们以 Animated Drawings 应用程序(使用 Detectron2 的 Mask-RCNN 模型)作为案例研究,展示了使用基准测试套件进行性能调优的过程。
有关 Torchserve 性能调优的更多详细信息,请参阅我们的文档此处。此外,如有任何疑问和反馈,请随时在Torchserve 存储库上提交工单。
致谢
我们要感谢 Somya Jain (Meta)、Christopher Gustave (Meta) 在本博客的许多步骤中提供的巨大支持和指导,并为 Sketch Animator 工作流程提供了见解。此外,特别感谢来自 AWS 的李宁,为 Torchserve 的自动化基准测试套件,使性能调优变得更加容易所做的巨大努力。