1. Meta 的 AI 性能分析 (MAIProf)
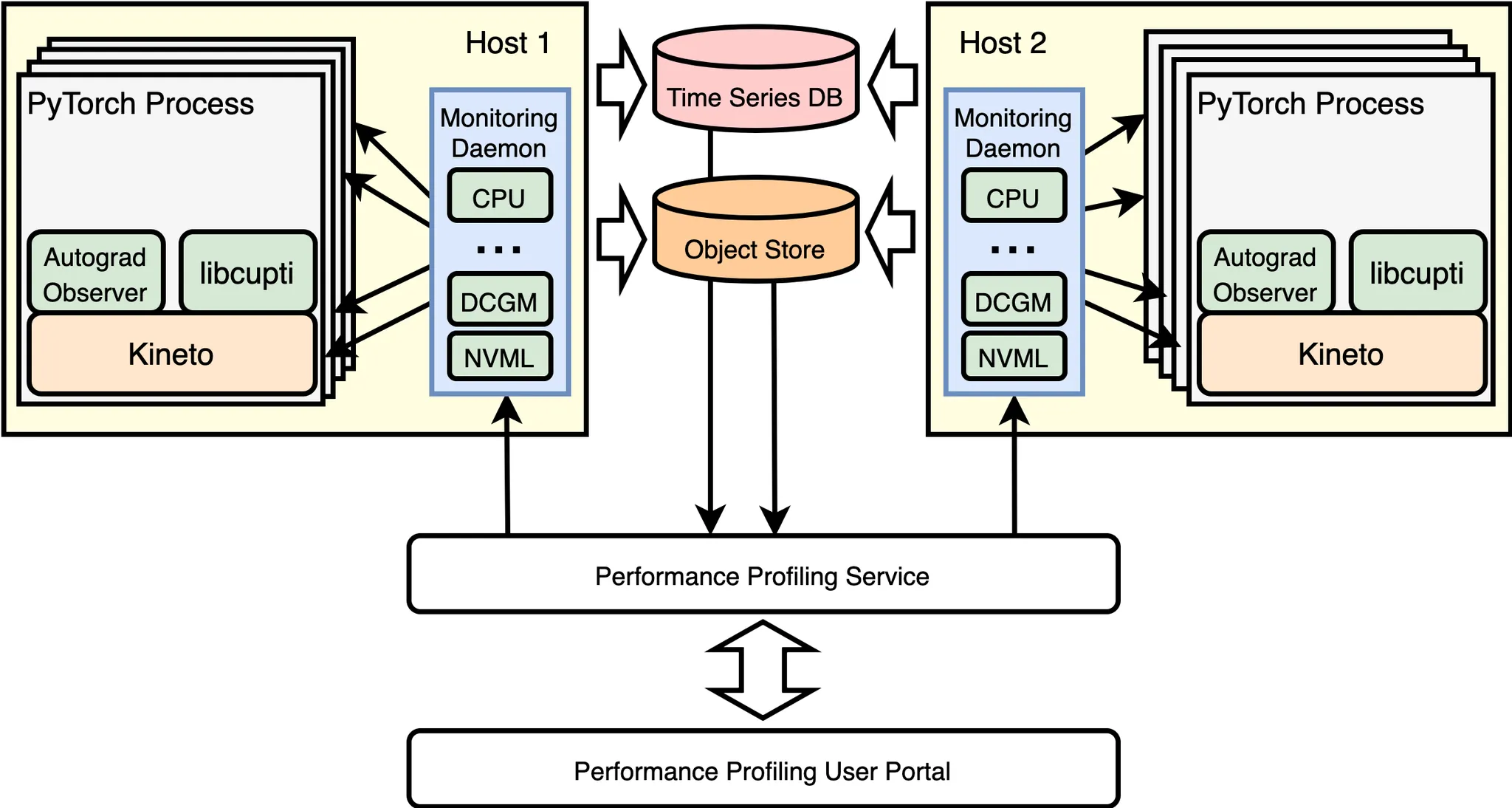
图 1:Meta 的 AI 性能分析 (MAIProf) 基础设施的简化图示。
图 1 简化地说明了 Meta 的 AI 性能分析基础设施。机器学习研究和性能工程师通过用户门户向分析服务提交训练作业的分析请求,该服务随后将请求广播给所有运行该训练作业的 GPU 主机。当 GPU 主机上的监控守护程序收到分析请求时,它会通知训练作业对应的 PyTorch 程序中的 Kineto GPU 跟踪器(基于 NVIDIA 的 libcupti)。因此,Kineto 跟踪将被收集并异步上传到对象存储(更详细地说:每个单独的 GPU 都会收集一个 Kineto 跟踪,每个跟踪都被视为并存储为一个 blob;第 2 节将给出一个示例)。同时,MAIProf 还收集各种聚合性能指标:每个 GPU 主机上的监控守护程序不断从 NVIDIA 的 DCGM/NVML 读取性能计数器并将它们记录到时间序列数据库中。
一旦跟踪和指标收集完成,分析服务将自动从对象存储下载跟踪进行跟踪分析,并从时间序列数据库下载性能指标进行指标分析。最后,一份包含详细而有见地分析的整体分析报告将交付给用户。
为了服务生产用途,我们特意为 MAIProf 做了以下设计选择:
- PyTorch 模型无需修改源代码:通过对未修改模型的执行进行用户指定时间的采样来触发分析。
- 提供全面的性能视图:MAIProf 执行覆盖 CPU 和 GPU 的全系统分析。在底层,它调用各种 CPU 工具(例如,Python 跟踪器、Autograd Observer)和 GPU 工具(例如,Kineto、DCGM)并关联它们的结果。
- 提供针对广泛 AI 分区器的多种工具:在 Meta,具有不同背景的工程师可能需要调整其 AI 工作负载性能。其中一些是 AI 专家,而另一些是普通软件工程师。因此,MAIProf 提供了各种工具,用于不同级别的性能调试,从高级自动跟踪理解到低级跟踪分析。
- 支持分布式 GPU 分析:MAIProf 可以从多个主机收集分析数据,每个主机具有多个 GPU。然后,它会显示整个系统的组合视图/分析。
- 高度可扩展:MAIProf 是作为一项服务构建在 Meta 数据中心现有基础设施之上,例如一个名为 Manifold 的可扩展存储系统。通过在服务池中增加更多机器以应对工作负载的增加,其分析能力可以轻松扩展。
2. 案例研究:优化生产中的 PyTorch 模型
具体来说,我们使用了一个生产中使用的保护 PyTorch 模型的案例研究。首先,我们讨论使用 MAIProf 识别模型中性能瓶颈的步骤。然后,我们描述了相应的优化措施及其影响。
2.1 性能瓶颈
步骤 1:
检查同一时间轴上的 CPU 和 GPU 利用率,如图 2 所示。
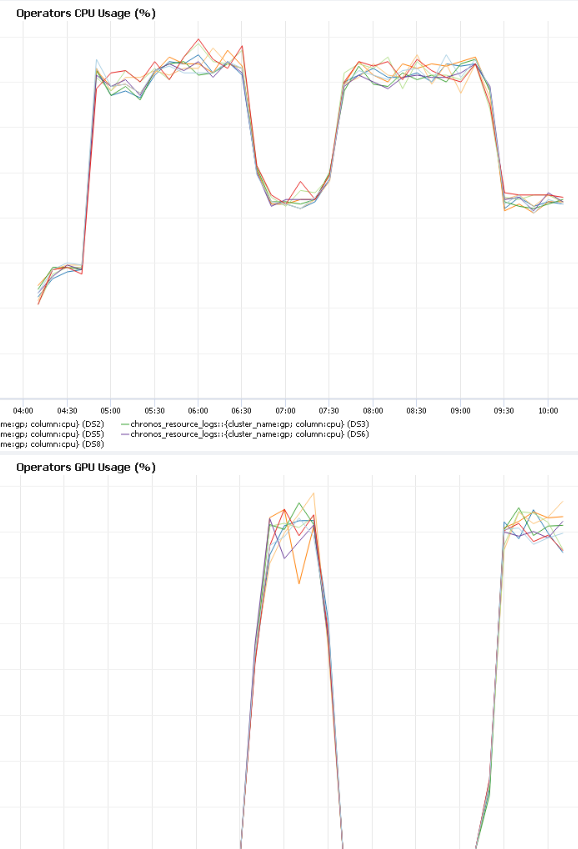
图 2:CPU 随时间的使用情况(顶部)与 GPU 随时间的使用情况(底部)。
我们在图 2 中注意到的第一个性能异常是贯穿整个训练过程的模式:“GPU 空闲,GPU 活跃,GPU 空闲,GPU 活跃……”。总体而言,GPU 在超过一半的训练时间中处于空闲状态(这对性能不利,因为 GPU 是一个高性能设备,我们希望它尽可能多地被利用)。
步骤 2:
在 GPU 空闲时使用 MAIProf 收集 CPU 上的 Python 函数调用跟踪,如图 3 所示。

图 3:Python 调用跟踪。
Python 跟踪显示,大部分 CPU 时间都花在一个 Python 函数 `sharded_iterrows()` 中。从模型的源代码中,我们了解到这个函数并行处理一个大的特征表。所使用的工作线程数由一个可配置参数 (`num_worker_threads`) 控制。此外,在调查特征表的生成方式后,我们理解了性能异常:训练数据集太大,无法一次性全部放入 CPU 内存;它需要被分成多个子数据集,每个子数据集都有足够的数据运行 10 个 epoch。因此,每 10 个 epoch 需要从磁盘读取一个新的子数据集到内存,在此期间 GPU 完全空闲。
步骤 3:
收集 GPU 性能指标,如图 4 所示。
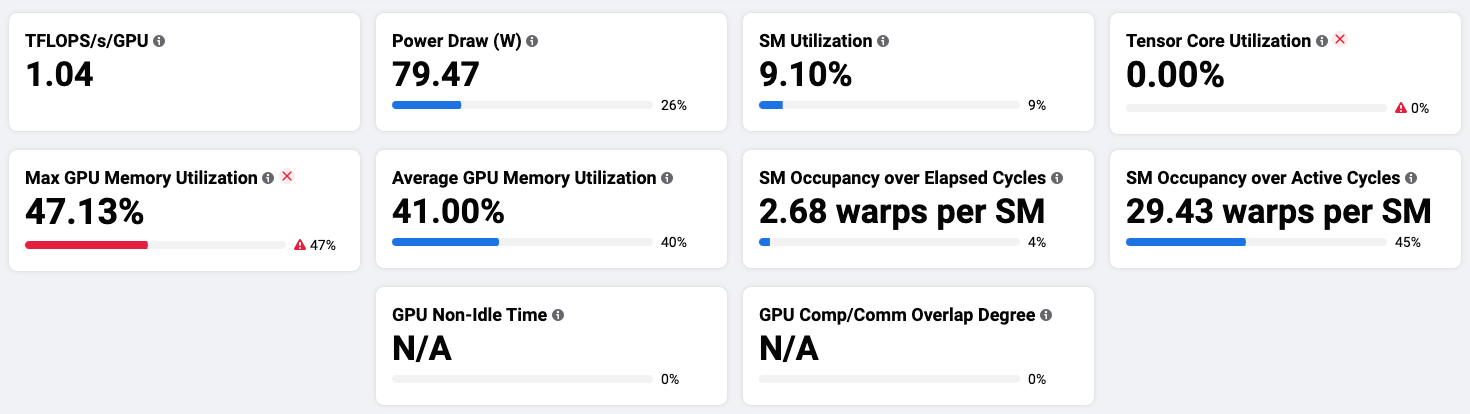
图 4:MAIProf 中的 GPU 性能指标。
我们从图 4 中得出以下观察:
- 流式多处理器 (SM) 运行模型的 CUDA 内核。其利用率 [1] 为 9.1%,表明 GPU 上的并行计算单元未得到充分利用。
- Tensor Core 利用率为 0,表示 Tensor Core(GPU 上的混合精度计算单元)[2] 完全未被使用。
- 最大 GPU 内存利用率为 47.13%,表明一半的 GPU 内存未被使用。
步骤 4:
收集训练循环的 GPU 跟踪(又称 Kineto 跟踪),如图 5 所示。

图 5:训练循环的 GPU 跟踪(又称 Kineto 跟踪)。
由于常用的 PyTorch 函数已经添加了注释,它们的名称会自动显示在跟踪中。通过它们,我们可以大致将跟踪分为训练迭代中的四个阶段:(1)数据加载,(2)前向传播,(3)反向传播,(4)梯度优化(注意:在图 5 中,“优化器”阶段来自上一个批次,而其他三个阶段来自当前批次)。
2.2 优化措施
我们针对上述瓶颈进行了四项简单的优化,每项优化只需要更改一个配置参数或最多几行源代码。它们列在图 6 中。
| 优化 | 更改量 | 解决的瓶颈 |
|---|---|---|
| 通过尝试每个主机上 CPU 核数范围内的几个可能值来调整 `num_worker_threads`。 | 1 行源代码 | GPU 完全空闲时间 |
| 将批次大小加倍 | 2 个配置参数 | GPU 内存利用率不足 |
| 在 PyTorch 中使用自动混合精度 | 13 行源代码 | Tensor Core 利用率为零 |
| 在 PyTorch 中使用多张量优化器 | 1 行源代码 | 优化器中有许多小的 GPU 内核 |
图 6:应用的四项简单优化。
3. 总结
在生产环境中对 PyTorch 进行性能调优变得越来越重要。一个强大的性能调试工具是这一过程的关键。我们通过一个生产模型的案例研究表明,MAIProf 是识别优化机会的强大基础设施。
在 Meta,MAIProf 已被数百名工程师使用,从性能新手到专家,以识别更多类型的瓶颈。这些瓶颈包括数据加载缓慢、GPU 内核小和/或慢、分布式训练问题(例如负载不平衡和过多的通信)。MAIProf 涵盖了主要的模型类别,包括推荐、视觉和自然语言处理。总而言之,它现在是调优生产 PyTorch 工作负载性能不可或缺的工具。