审阅人: Yunsang Ju(Naver GplaceAI 负责人), Min Jean Cho(Intel), Jing Xu(Intel), Mark Saroufim(Meta)
引言
在此,我们将分享我们如何在不降低性能或质量的情况下,将 AI 工作负载从 GPU 服务器迁移到 Intel CPU 服务器的经验,并在此过程中每年节省约 34 万美元(请参阅结论)。
我们的目标是通过提供各种 AI 模型来增强线上到线下 (O2O) 体验,从而为消费者创造价值。随着新模型需求的持续增长以及高成本 GPU 资源的有限性,我们需要将相对轻量级的 AI 模型从 GPU 服务器迁移到 Intel CPU 服务器,以减少资源消耗。然而,在相同的设置下,CPU 服务器存在 RPS、推理时间等性能下降数十倍的问题。我们应用了各种工程技术并对模型进行了轻量化,以解决此问题,并成功过渡到 Intel CPU 服务器,仅通过三倍的横向扩展就实现了与 GPU 服务器相同或更好的性能。
有关我们团队的更详细介绍,请参阅 NAVER Place AI 开发团队介绍。
我稍后还会再次提及,但在整个工作中,我从 Intel 和 PyTorch 撰写的 从第一性原理理解 PyTorch Intel CPU 性能中获得了大量帮助。
问题定义
1:服务架构
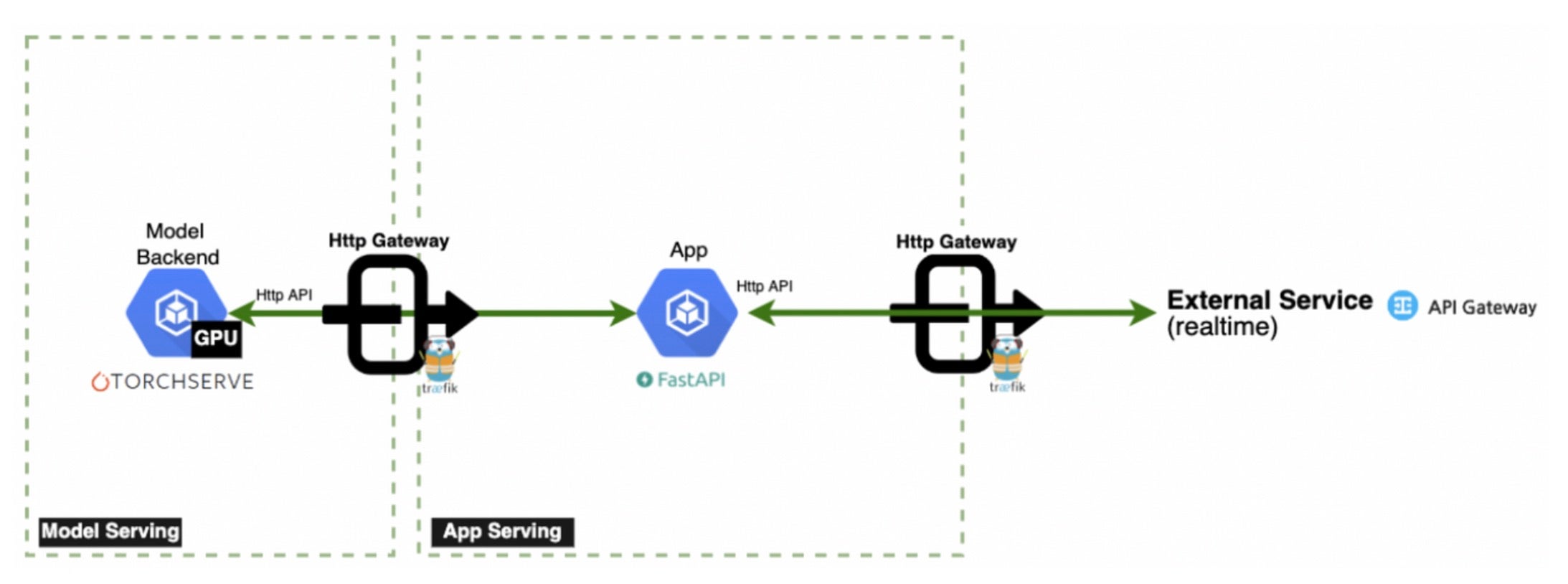
简化服务架构(图片来源: NAVER GplaceAI)
为了便于理解,将简要介绍我们的服务架构。CPU 密集型任务,例如将输入预处理为张量格式(然后转发到模型)以及将推理结果后处理为人类可读的输出(例如自然语言和图像格式)在应用服务器 (FastAPI) 上执行。模型服务器 (TorchServe) 专门处理推理操作。为了服务的稳定运行,需要以足够的吞吐量和低延迟执行以下操作。
具体的处理顺序如下
- 客户端通过 Traefik 网关向应用服务器提交请求。
- 应用服务器通过执行调整大小、转换等操作对输入进行预处理,并将其转换为 Torch 张量,然后请求模型服务器。
- 模型服务器执行推理并将特征返回给应用服务器
- 应用服务器通过后处理将特征转换为人类可理解的格式,并将其返回给客户端
2: 吞吐量和延迟测量
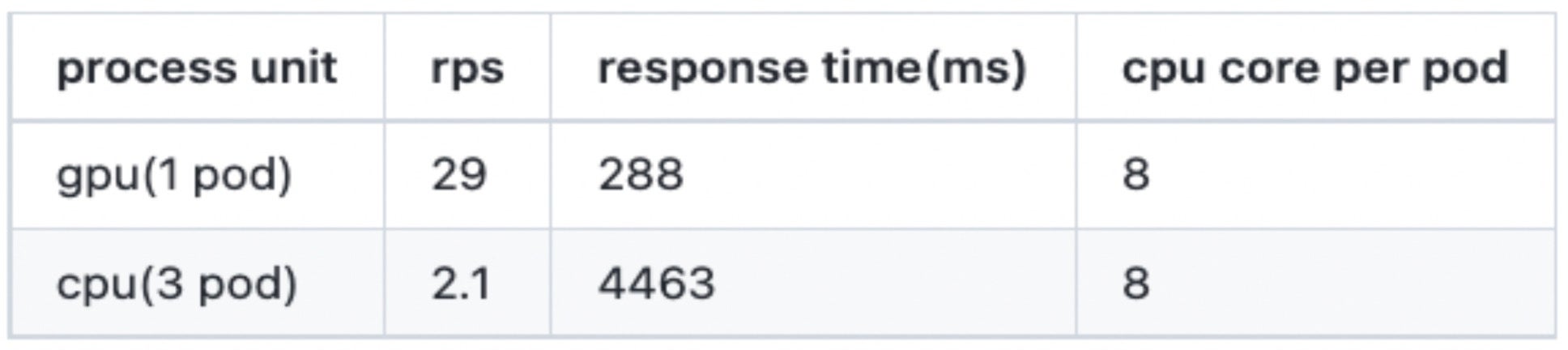
图像评分模型比较
在所有其他条件不变的情况下,部署在三倍数量的 CPU 服务器 pod 上,但 RPS(每秒请求数)和响应时间却显著下降了十倍以上。虽然 CPU 推理性能不如 GPU 并不令人意外,但严峻的形势显而易见。考虑到在有限资源内保持性能的目标,在不进行额外扩展的情况下,需要实现大约 10 到 20 倍的性能提升。
3: 吞吐量方面的挑战
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /predictions/image-scoring 37 0(0.00%) | 9031 4043 28985 8200 | 1.00 0.00
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 37 0(0.00%) | 9031 4043 28985 8200 | 1.00 0.00
TorchServe 框架用户提高吞吐量的首要步骤之一可能是增加 TorchServe 中的 worker 数量。这种方法在 GPU 服务器上是有效的,因为并行工作负载处理,除了 worker 扩展时内存使用量线性增加。然而,我们发现在增加 worker 数量时性能反而下降了。识别 CPU 服务器上性能下降的原因需要进一步调查。
4: 延迟方面的挑战
我们主要关注的是延迟。通常,当系统实现忠实于横向扩展原则时,吞吐量提升是可实现的,除了极少数最坏情况。然而,在图像评分模型的例子中,即使执行一次推理也需要超过 1 秒,并且随着请求量的增加,延迟会增加到 4 秒。这是一种即使进行一次推理也无法满足客户端超时标准的情况。
提出的解决方案
需要从机器学习和工程角度进行改进。根本上缩短 CPU 上的推理时间至关重要,并且需要找出在应用通常能提高性能的配置时导致性能下降的原因,以找到最佳配置值。为此,我们与 MLE 专业人员合作,同时执行“在不损害性能的情况下对模型进行轻量化”和“确定实现最佳性能的最佳配置”等任务。通过上述方法,我们能够有效地将工作负载处理转移到我们的 CPU 服务器。
1:从工程角度解决低 RPS 问题
首先,即使增加 worker 数量后性能仍然下降的原因是 GEMM 操作中逻辑线程导致的前端瓶颈。通常,当增加 worker 数量时,预期的改进效果是并行度的增加。相反,如果性能下降,则可以推断出相应的权衡效应。
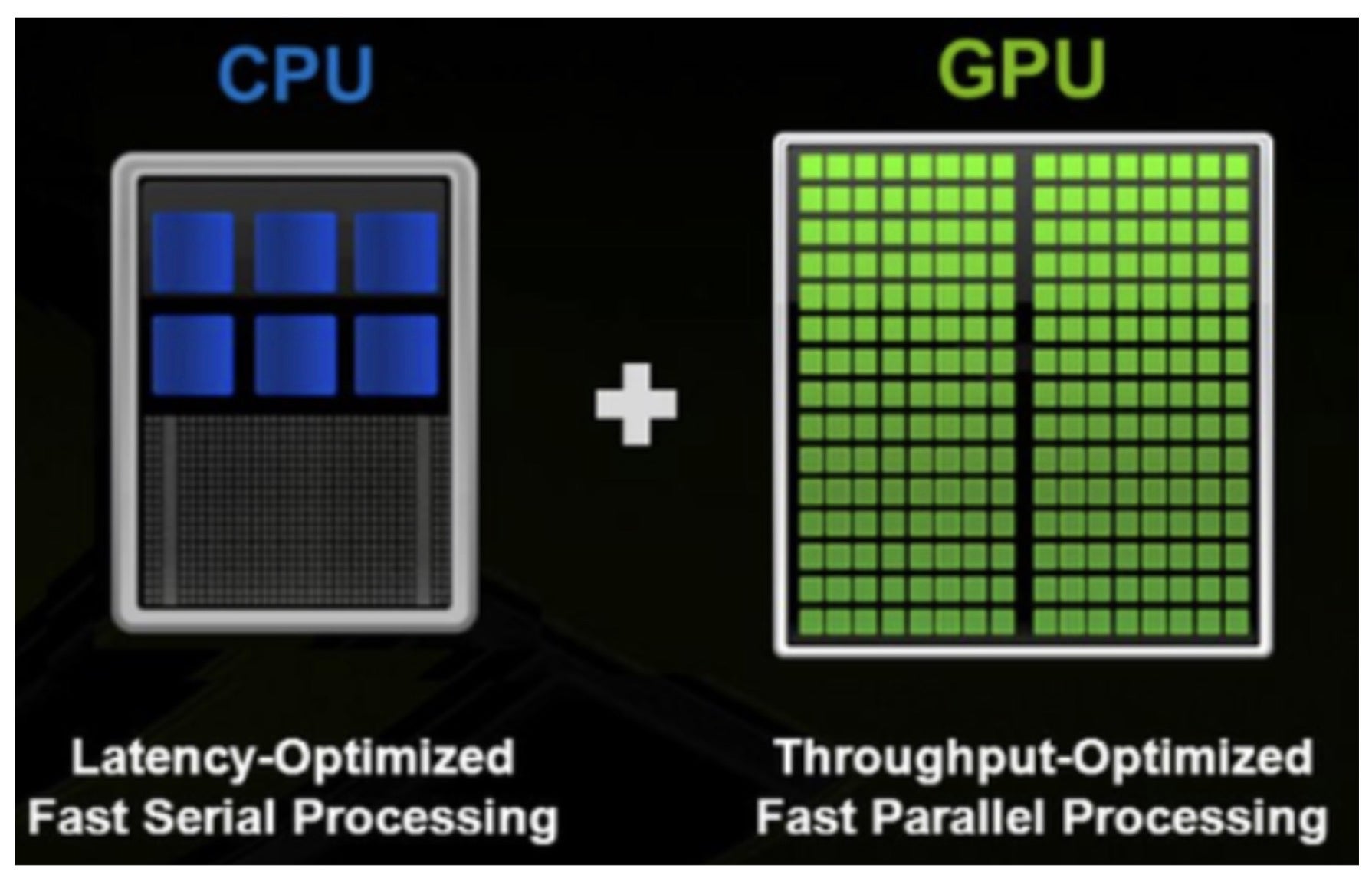
图片来源: Nvidia
众所周知,CPU 上模型推理性能不如 GPU 的原因在于硬件设计的差异,尤其是在多线程能力方面。深入来看,模型推理本质上是 GEMM(通用矩阵乘法)操作的重复,这些 GEMM 操作在 “融合乘加”(FMA)或 “点积”(DP)执行单元中独立执行。如果 GEMM 操作成为 CPU 上的瓶颈,增加并行度实际上可能会导致性能下降。在研究问题时,我们在 PyTorch 文档中找到了相关信息。
当两个逻辑线程同时运行 GEMM 时,它们将共享相同的核心资源,导致前端瓶颈
此信息强调了逻辑线程可能导致 CPU GEMM 操作中的瓶颈,这有助于我们直观地理解为什么增加 worker 数量时性能会下降。这是因为 torch 线程的默认值对应于 CPU 的物理核心值。
root@test-pod:/# lscpu
…
Thread(s) per core: 2
Core(s) per socket: 12
…
root@test-pod:/# python
>>> import torch
>>> print(torch.get_num_threads())
24
当 worker_num 增加时,总线程数增加,增加量为物理核心数 * worker 数量的乘积。因此,逻辑线程被利用。为了提高性能,每个 worker 的总线程数被调整为与物理核心数对齐。下面可以看到,当 worker_num 增加到 4 并且总线程数与物理核心数对齐时,RPS 指标大约增加了三倍,达到 6.3(从之前的 2.1)。
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /predictions/image-scoring 265 0(0.00%) | 3154 1885 4008 3200 | 6.30 0.00
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 265 0(0.00%) | 3154 1885 4008 3200 | 6.30 0.00
注意事项 1:我们的团队使用 Kubernetes 来维护我们的部署。因此,我们正在根据 pod 的 CPU 资源限制进行调整,而不是使用 lscpu 命令检查到的节点的物理核心数。(将每个 worker 的 torch 线程设置为 8/4 = 2 或 24/4 = 6 会导致性能下降。)
注意事项 2:由于每个 worker 的 torch 线程设置只能配置为整数,因此建议将 CPU 限制设置为可被 worker_num 整除,以便充分利用 CPU 使用率。

例如)核心数=8,worker_num=3 的情况下:int(8/worker_num) = 2,2*worker_num/8 = 75%

例如)核心数=8,worker_num=4 的情况下:int(8/worker_num) = 2,2*worker_num/8 = 100%
我们还分析了模型容器,以了解为什么在 worker 数量增加四倍的情况下,性能仅提高了三倍。我们监控了各种资源,其中核心利用率被认为是根本原因。
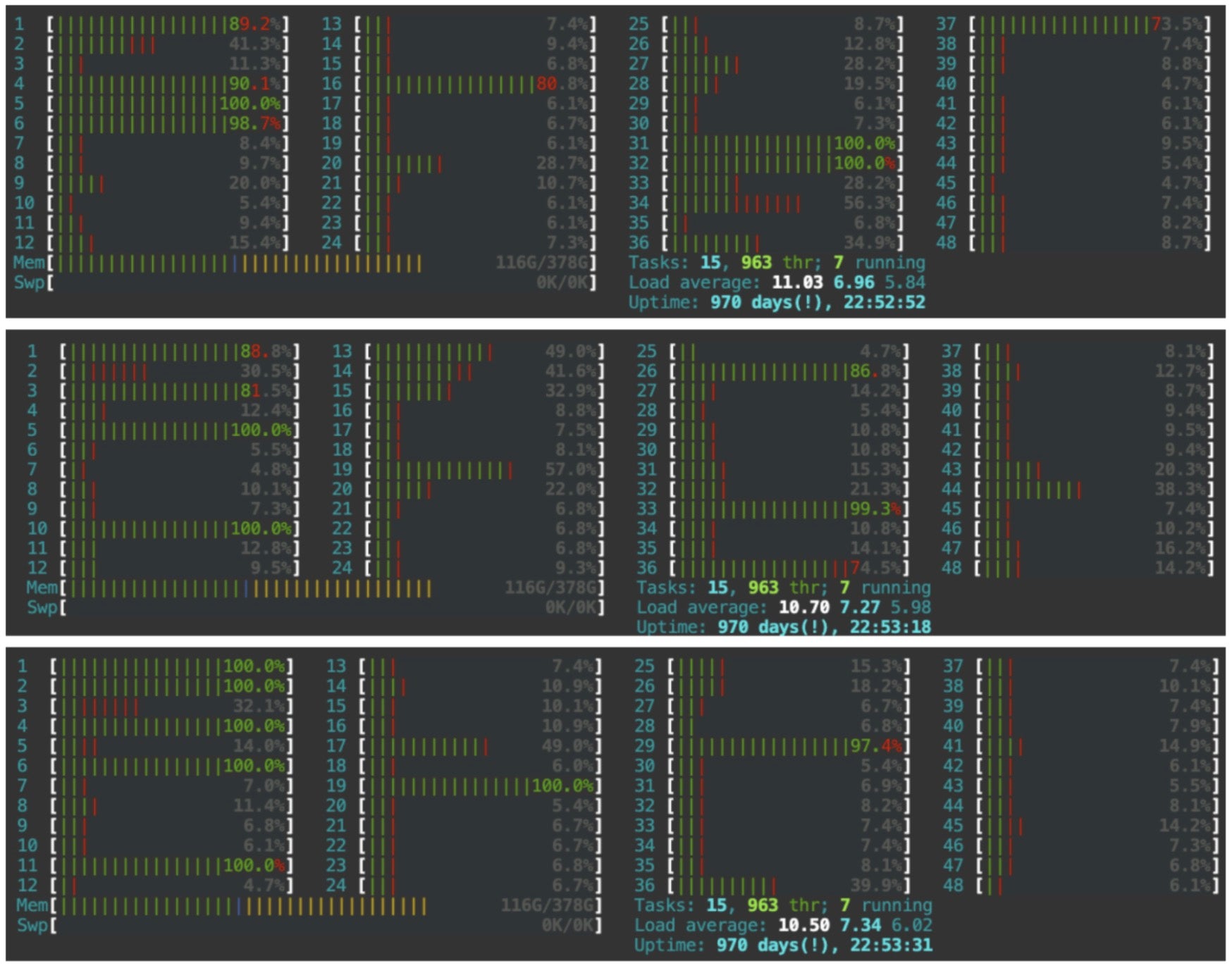
即使将总线程数调整为与 CPU(第二代 Intel(R) Xeon(R) Silver 4214)限制(8 核)匹配,也存在计算从逻辑线程到逻辑核心执行的情况。由于存在 24 个物理核心,编号 25 到 48 的核心被归类为逻辑核心。将线程执行仅限于物理核心的可能性似乎提供了进一步提高性能的潜力。此解决方案的参考可以在 PyTorch-geometric 文章中提到的源文档中找到,该文章警告了 CPU GEMM 瓶颈。
根据文档中的说明,Intel 提供了 Intel® Extension for PyTorch,我们可以简单地将核心固定到特定的插槽。应用方法也变得非常简单,只需将以下设置添加到 torchserve config.properties 文件中即可。(使用了 intel_extension_for_pytorch==1.13.0)
ipex_enable=true
CPU_launcher_enable=true
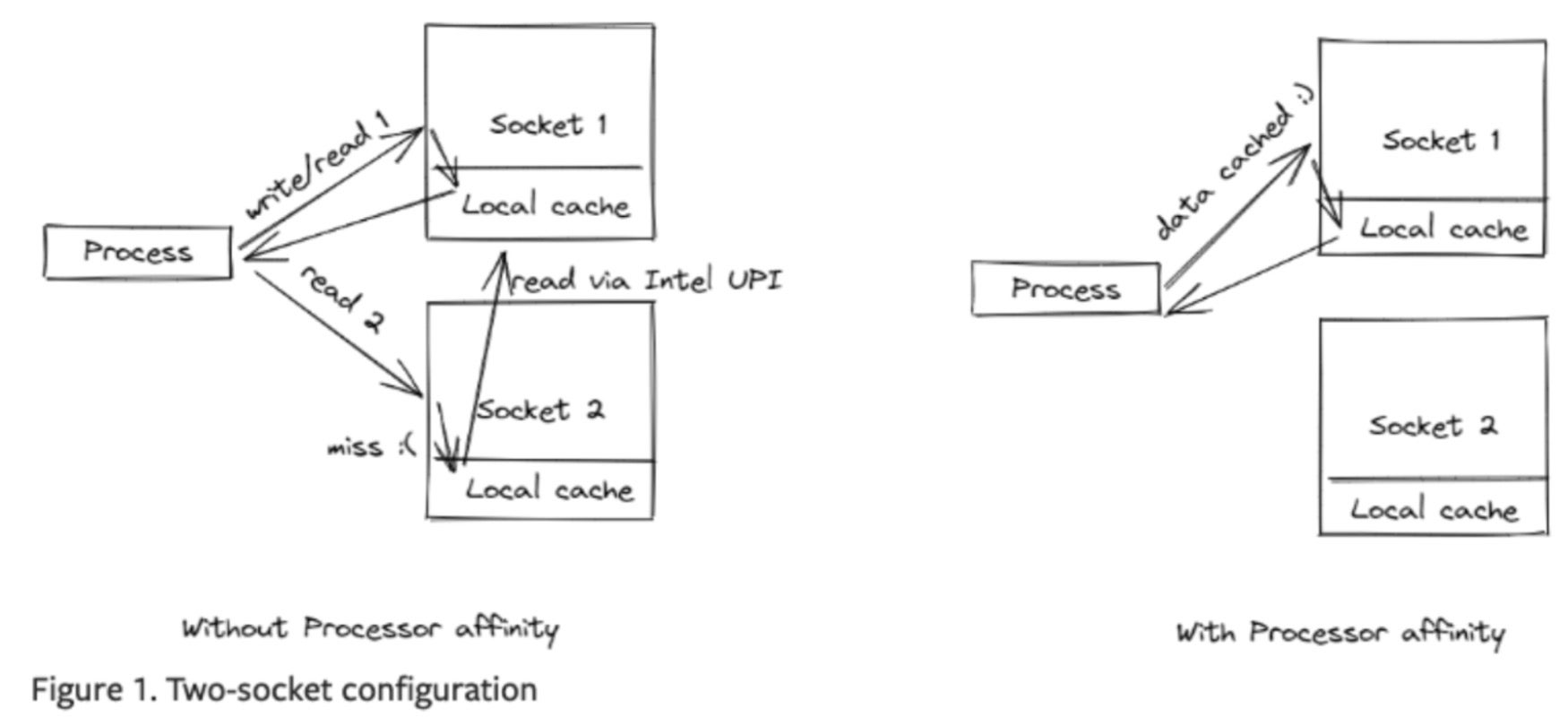
图片来源: PyTorch
除了通过插槽绑定消除逻辑线程外,还有额外的好处是消除了 UPI 缓存命中开销。由于 CPU 包含多个插槽,当调度在插槽 1 上的线程重新调度到插槽 2 时,在通过 Intel Ultra Path Interconnect (UPI) 访问插槽 1 的缓存时会发生缓存命中。此时,UPI 访问本地缓存的速度比本地缓存访问慢两倍以上,从而导致更多的瓶颈。通过 oneAPI 驱动的 Intel® Extension for PyTorch 将线程绑定到插槽单元,我们观察到 RPS 处理量比存在瓶颈时提高了四倍。
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /predictions/image-scoring 131 0(0.00%) | 3456 1412 6813 3100 | 7.90 0.00
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 131 0(0.00%) | 3456 1412 6813 3100 | 7.90 0.00
注意事项 1:Intel® Extension for PyTorch 专注于神经网络(以下简称“nn”)推理优化,因此 nn 以外的其他技术的性能提升可能微乎其微。事实上,在作为示例的图像评分系统中,推理后应用了 svr(支持向量回归),性能提升仅限于 4 倍。然而,对于纯粹的 nn 推理模型,例如食物识别模型,检测到性能提升了 7 倍(2.5rps -> 17.5rps)。
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /predictions/food-classification 446 0(0.00%) | 1113 249 1804 1200 | 17.50 0.00
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 446 0(0.00%) | 1113 249 1804 1200 | 17.50 0.00
注意事项 2:应用 Intel® Extension for PyTorch 需要 torchserve 版本 0.6.1 或更高版本。由于我们团队使用的是 0.6.0 版本,因此存在插槽绑定无法正常工作的问题。目前,我们已修改了指导文档,指定了所需版本。
在 WorkerLifeCycle.java中,0.6.0 及以下版本不支持多 worker 绑定(ninstance 硬编码为 1)
// 0.6.0 version
public ArrayList<String> launcherArgsToList() {
ArrayList<String> arrlist = new ArrayList<String>();
arrlist.add("-m");
arrlist.add("intel_extension_for_pytorch.cpu.launch");
arrlist.add(" — ninstance");
arrlist.add("1");
if (launcherArgs != null && launcherArgs.length() > 1) {
String[] argarray = launcherArgs.split(" ");
for (int i = 0; i < argarray.length; i++) {
arrlist.add(argarray[i]);
}
}
return arrlist;
}
// master version
if (this.numWorker > 1) {
argl.add(" — ninstances");
argl.add(String.valueOf(this.numWorker));
argl.add(" — instance_idx");
argl.add(String.valueOf(this.currNumRunningWorkers));
}
2:通过模型轻量化解决慢延迟问题
我们还使用 知识蒸馏(通常缩写为 KD)简化了我们的模型,以进一步减少延迟。众所周知,知识蒸馏是一种技术,将来自较大网络(教师网络)的知识传递给较小、轻量级网络(学生网络),该网络资源密集度较低,可以更容易地部署。有关更多详细信息,请参阅最初引入此概念的论文,题为 “Distilling the Knowledge in a Neural Network”。
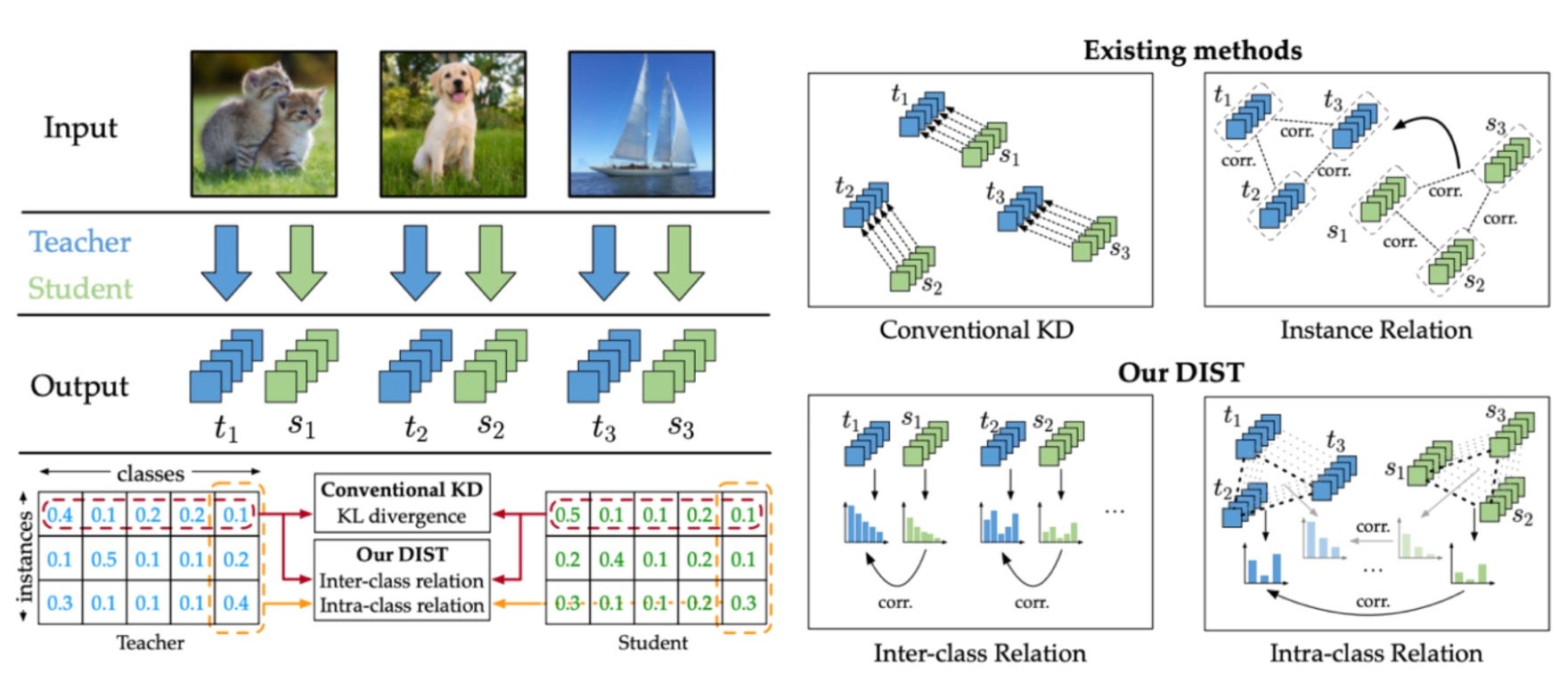
有多种知识蒸馏技术可用,由于我们主要关注准确性损失最小化,因此我们采用了 2022 年发表的论文“来自更强教师的知识蒸馏”中的方法。概念很简单。与仅利用模型属性值的传统蒸馏方法不同,所选择的方法涉及让学生网络学习教师网络中类之间的相关性。在实际应用中,我们观察到模型权重有效减少,同时保持高准确性。以下是我们使用上述知识蒸馏技术对几个候选学生模型进行实验的结果,其中根据保持的准确性水平进行了选择。
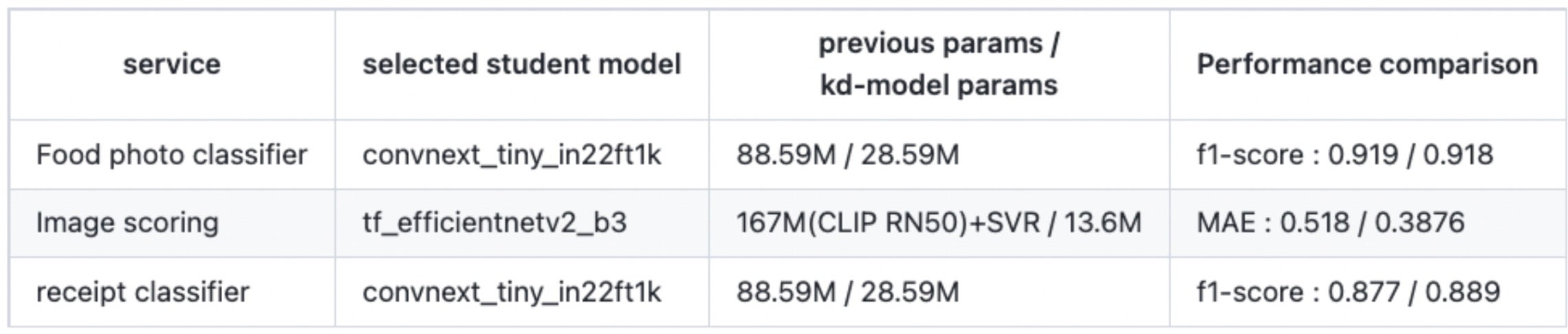
对于图像评分系统,我们采取了额外的措施来减小输入大小。考虑到之前使用了基于 CPU 的机器学习技术 SVR(支持向量回归)(2 阶段:CNN + SVR),即使将其简化为 1 阶段模型,在 CPU 推理中也没有观察到显著的速度优势。为了使简化具有意义,学生模型在推理时的输入大小需要进一步减小。因此,我们进行了实验,将大小从 384*384 减小到 224*224。
为了进一步简化转换,我们将两阶段(CNN + SVR)方法统一为一个包含更大 ConvNext 的一阶段模型,然后使用轻量级 EfficientNet 应用 kd 以解决准确性权衡问题。在实验过程中,我们遇到了一个问题,即将 Img_resize 更改为 224 导致 MAE 从 0.4007 下降到 0.4296。由于输入大小的减小,应用于原始训练图像的各种预处理技术(例如 Affine、RandomRotate90、Blur、OneOf [GridDistortion、OpticalDistortion、ElasticTransform]、VerticalFlip)产生了反作用。通过采取这些措施,学生模型实现了有效的训练,并且MAE 值比之前提高了 25%(从 0.518 提高到 0.3876)。
验证
1:最终性能测量
下表显示了使用 CPU 服务器对本文中提到的三个模型进行的最终性能改进。
# Food photo classifier (pod 3): 2.5rps -> 84 rps
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|------|------------|-------|------|-------|-------|--------|---------
POST /predictions/food-classification 2341 0(0.00%) | 208 130 508 200 | 84.50 0.00
--------|----------------------------------------------------------------------------|--------|-------------|------|-------|--------|------|--------|----------
Aggregated 2341 0(0.00%) | 208 130 508 200 | 84.50 0.00
# Image scoring (pod 3): 2.1rps -> 62rps
Type Name #reqs #fails | Avg Min Max Median | req/s failures/s
--------|---------------------------------------------------------------------------------|--------|-------------|--------|-------|--------|---------|--------|---------
POST /predictions/image-scoring 1298 0 (0.00%) | 323 99 607 370 | 61.90 0.00
--------|---------------------------------------------------------------------------------|--------|-------------|--------|------|--------|---------|--------|----------
Aggregated 1298 0(0.00%) | 323 99 607 370 | 61.90 0.00
# receipt classifier(pod 3) : 20rps -> 111.8rps
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /predictions/receipt-classification 4024 0(0.00%) | 266 133 2211 200 | 111.8 0.00
--------|----------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 4020 0(0.00%) | 266 133 2211 200 | 111.8 0.00
2: 流量镜像
如前所述,我们团队的服务架构在应用服务器前面使用“traefik”工具作为网关,正如文章开头简要介绍的那样。为了最终验证,我们利用了 traefik 网关的镜像功能,将生产流量镜像到 staging 环境进行了一个月的验证,然后才将其应用于生产环境,目前已投入运行。
关于镜像的详细信息超出了本主题的范围,因此此处省略。感兴趣的读者请参阅文档: https://doc.traefik.io/traefik/routing/services/#mirroring-service。
结论
至此,关于在保持服务质量的同时从 GPU 模型服务器过渡到 CPU 服务器的讨论结束。通过这项努力,我们团队在韩国和日本各节省了 15 个 GPU,从而每年节省了约 34 万美元。尽管我们在 NAVER 内部直接购买和使用 GPU,但我们基于稳定支持 T4 GPU 的 AWS EC2 实例计算了大致的成本降低。
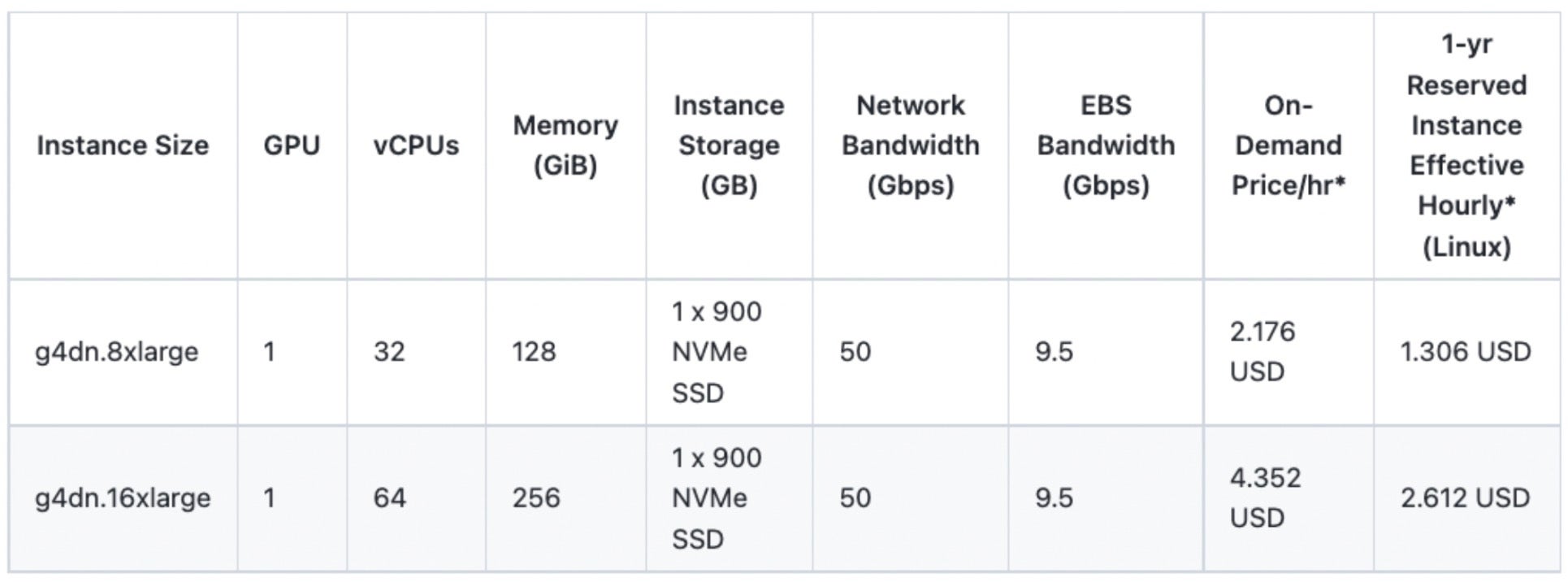
计算:1.306(1 年期预留实例有效每小时成本)* 24(小时)* 365(天)* 15(GPU 数量)* 2(韩国 + 日本)
这些获得的 GPU 将用于进一步推进和增强我们团队的 AI 服务,提供卓越的服务体验。我们真诚地感谢您的鼓励和期待:)
了解更多
- https://www.intel.com/content/www/us/en/developer/ecosystem/pytorch-foundation.html
- https://pytorch-geometric.readthedocs.io/en/latest/advanced/CPU_affinity.html#binding-processes-to-physical-cores
- https://arxiv.org/pdf/2205.10536.pdf