
理论上,“注意力”是你所需要的一切。然而在实践中,我们还需要像 FlashAttention 这样经过优化的注意力实现。
尽管这些融合的注意力实现大大提高了性能并支持了长上下文,但这种效率的提高也伴随着灵活性的损失。你不能再通过编写几个 PyTorch 操作符来尝试新的注意力变体了——你通常需要编写一个新的自定义内核!这对于机器学习研究人员来说,就像是一种“软件彩票”——如果你的注意力变体不适合现有的优化内核之一,你就注定会遭遇慢速运行时和 CUDA 内存溢出。
注意力变体的一些例子包括:因果注意力、相对位置编码、Alibi、滑动窗口注意力、PrefixLM、文档掩码/样本打包/锯齿形张量、Tanh 软限幅、分页注意力等。更糟糕的是,人们通常希望将这些变体组合起来!滑动窗口注意力 + 文档掩码 + 因果注意力 + 上下文并行?或者分页注意力 + 滑动窗口 + Tanh 软限幅又如何?
下面左图展示了当今世界的现状——掩码、偏置和设置的某些组合具有现有的内核实现。但各种选项导致了指数级的设置,因此总体而言,我们最终获得了相当零星的支持。更糟糕的是,研究人员提出的新注意力变体将获得*零*支持。
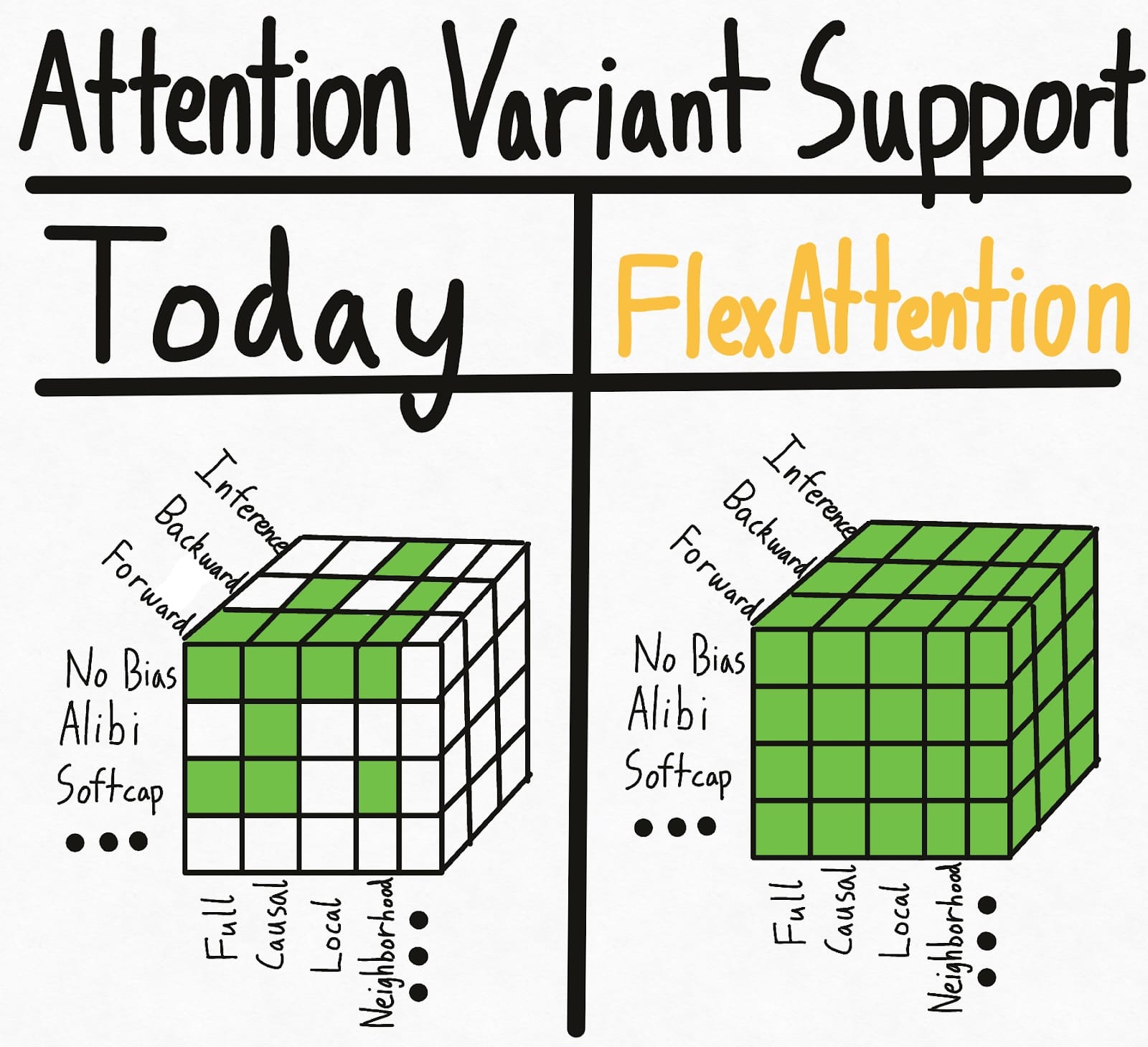
为了彻底解决这个超立方体问题,我们引入了**FlexAttention**,一个全新的 PyTorch API。
- 我们提供了一个灵活的 API,允许用几行地道的 PyTorch 代码实现许多注意力变体(包括到目前为止博客文章中提到的所有变体)。
- 我们通过 `torch.compile` 将其转换为融合的 FlashAttention 内核,生成一个不实例化任何额外内存且性能与手写内核相当的 FlashAttention 内核。
- 我们还利用 PyTorch 的自动求导机制自动生成反向传播。
- 最后,我们还可以利用注意力掩码中的稀疏性,从而相对于标准注意力实现获得显著改进。
有了 FlexAttention,我们希望尝试新的注意力变体将只受限于你的想象力。
你可以在 Attention Gym 找到许多 FlexAttention 示例:https://github.com/pytorch-labs/attention-gym。如果你有任何很酷的应用,欢迎提交示例!
附注:我们还发现这个 API 非常令人兴奋,因为它以一种有趣的方式利用了许多现有 PyTorch 基础设施——更多内容将在最后介绍。
FlexAttention
这是经典的注意力方程
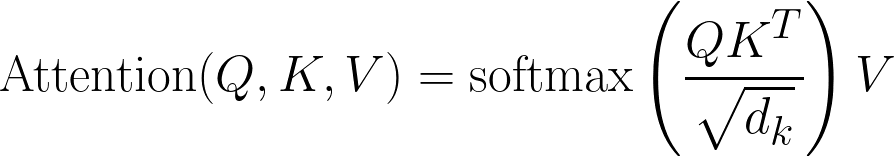
以代码形式
Q, K, V: Tensor[batch_size, num_heads, sequence_length, head_dim]
score: Tensor[batch_size, num_heads, sequence_length, sequence_length] = (Q @ K) / sqrt(head_dim)
probabilities = softmax(score, dim=-1)
output: Tensor[batch_size, num_heads, sequence_length, head_dim] = probabilities @ V
FlexAttention 允许用户定义函数 `score_mod:`

以代码形式
Q, K, V: Tensor[batch_size, num_heads, sequence_length, head_dim]
score: Tensor[batch_size, num_heads, sequence_length, sequence_length] = (Q @ K) / sqrt(head_dim)
modified_scores: Tensor[batch_size, num_heads, sequence_length, sequence_length] = score_mod(score)
probabilities = softmax(modified_scores, dim=-1)
output: Tensor[batch_size, num_heads, sequence_length, head_dim] = probabilities @ V
这个函数允许你在 softmax 之前*修改*注意力分数。令人惊讶的是,这对于绝大多数注意力变体来说已经足够了(示例如下)!
具体来说,`score_mod` 的预期签名有些独特。
def score_mod(score: f32[], b: i32[], h: i32[], q_idx: i32[], kv_idx: i32[])
return score # noop - standard attention
换句话说,`score` 是一个标量 PyTorch 张量,表示查询 token 和键 token 的点积。其余参数告诉您当前正在计算的是*哪个*点积——`b`(批次中的当前元素)、`h`(当前头)、`q_idx`(查询中的位置)、`kv_idx`(键/值张量中的位置)。
要应用此函数,我们可以将其实现为
for b in range(batch_size):
for h in range(num_heads):
for q_idx in range(sequence_length):
for kv_idx in range(sequence_length):
modified_scores[b, h, q_idx, kv_idx] = score_mod(scores[b, h, q_idx, kv_idx], b, h, q_idx, kv_idx)
当然,这不是 FlexAttention 在底层实现的。通过利用 `torch.compile`,我们自动将您的函数转换为一个*融合的* FlexAttention 内核——保证有效,否则退款!
这个 API 最终表现出惊人的表现力。让我们看一些例子。
分数修改示例
完全注意力
首先,我们来实现“完全注意力”,即标准的双向注意力。在这种情况下,`score_mod` 是一个无操作——它接收分数作为输入,然后原样返回。
def noop(score, b, h, q_idx, kv_idx):
return score
并端到端使用它(包括前向*和*后向)
from torch.nn.attention.flex_attention import flex_attention
flex_attention(query, key, value, score_mod=noop).sum().backward()
相对位置编码
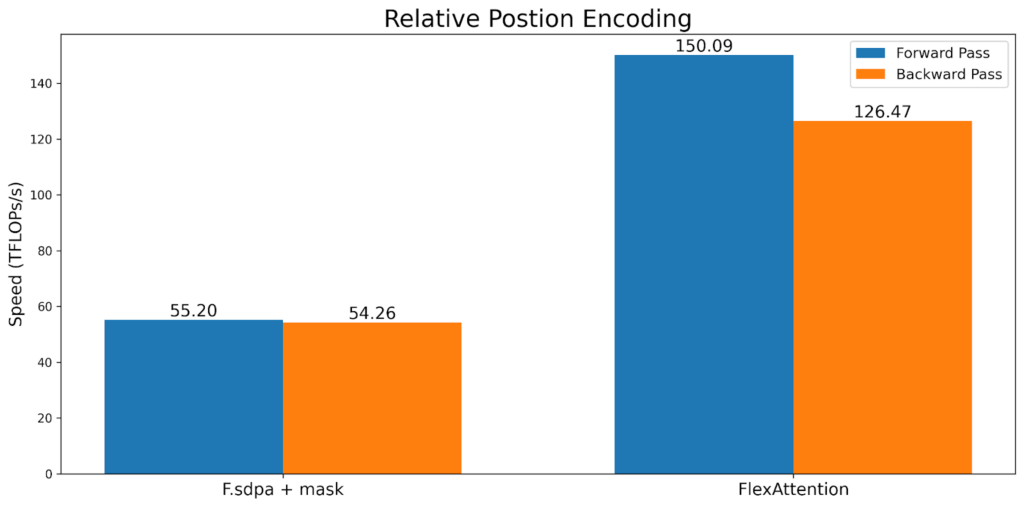
一种常见的注意力变体是“相对位置编码”。相对位置编码不是在查询和键中编码绝对距离,而是根据查询和键之间的“距离”调整分数。
def relative_positional(score, b, h, q_idx, kv_idx):
return score + (q_idx - kv_idx)
请注意,与典型的实现不同,这*不需要*实例化 SxS 张量。相反,FlexAttention 在内核内部“即时”计算偏差值,从而显著改善内存和性能。
ALiBi 偏差
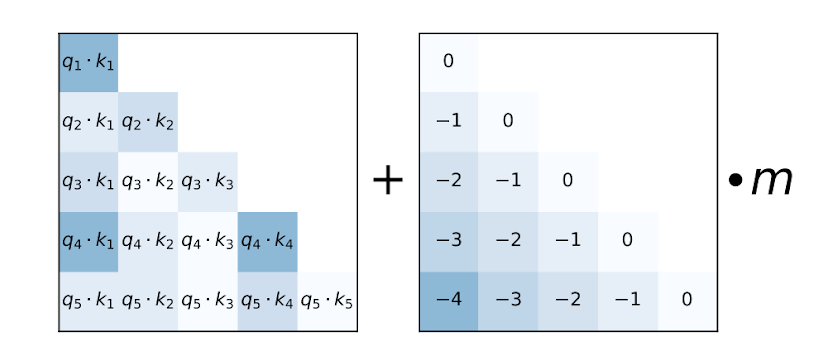
来源:Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
ALiBi 在 Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation 中被引入,并声称在推理时具有对长度外推有益的特性。值得注意的是,MosaicML 指出 “缺乏内核支持” 是他们最终从 ALiBi 转向旋转嵌入的主要原因。
Alibi 与相对位置编码相似,只有一个例外——它有一个通常预先计算的每个头因子。
alibi_bias = generate_alibi_bias() # [num_heads]
def alibi(score, b, h, q_idx, kv_idx):
bias = alibi_bias[h] * (kv_idx - q_idx)
return score + bias
这展示了 `torch.compile` 提供的一个有趣的灵活性——我们可以从 `alibi_bias` 加载,即使它*没有作为输入明确传递*!生成的 Triton 内核将计算从 `alibi_bias` 张量中进行的正确加载并进行融合。请注意,即使您重新生成 `alibi_bias`,我们也不需要重新编译。
软限幅
软限幅是 Gemma2 和 Grok-1 中使用的一种技术,可防止 logits 过度增长。在 FlexAttention 中,它看起来像这样
softcap = 20
def soft_cap(score, b, h, q_idx, kv_idx):
score = score / softcap
score = torch.tanh(score)
score = score * softcap
return score
请注意,我们还会自动从前向传播生成反向传播。此外,尽管此实现从语义上是正确的,但出于性能原因,在这种情况下我们可能希望使用 tanh 近似。有关更多详细信息,请参阅 attention-gym。
因果掩码
尽管双向注意力是最简单的,但最初的*《Attention is All You Need》*论文和绝大多数 LLM 都采用解码器专用设置中的注意力,其中每个 token 只能关注其之前的 token。人们通常将其视为下三角掩码,但使用 `score_mod` API,它可以表示为
def causal_mask(score, b, h, q_idx, kv_idx):
return torch.where(q_idx >= kv_idx, score, -float("inf"))
基本上,如果查询 token 在键 token “之后”,我们就保留分数。否则,我们通过将其设置为 -inf 来将其遮蔽掉,从而确保它不会参与 softmax 计算。
然而,掩码与其他修改相比是特殊的——如果某个东西被遮蔽掉了,我们就可以完全跳过它的计算!在这种情况下,因果掩码大约有 50% 的稀疏性,因此不利用稀疏性会导致 2 倍的减速。尽管这个 `score_mod` 足以*正确地*实现因果掩码,但要获得稀疏性带来的性能优势需要另一个概念——`mask_mod`。
掩码模组
为了利用掩码的稀疏性,我们需要做更多的工作。具体来说,通过将 `mask_mod` 传递给 `create_block_mask`,我们可以创建一个 `BlockMask`。然后 FlexAttention 可以使用 `BlockMask` 来利用稀疏性!
mask_mod 的签名与 score_mod 非常相似——只是没有 score。特别是
# returns True if this position should participate in the computation
mask_mod(b, h, q_idx, kv_idx) => bool
请注意,`score_mod` 比 `mask_mod` 严格来说*更具*表现力。然而,对于掩码,建议使用 `mask_mod` 和 `create_block_mask`,因为它性能更高。请参阅 FAQ 了解为什么 `score_mod` 和 `mask_mod` 是分开的。
现在,让我们看看如何使用 `mask_mod` 实现因果掩码。
因果掩码
from torch.nn.attention.flex_attention import create_block_mask
def causal(b, h, q_idx, kv_idx):
return q_idx >= kv_idx
# Because the sparsity pattern is independent of batch and heads, we'll set them to None (which broadcasts them)
block_mask = create_block_mask(causal, B=None, H=None, Q_LEN=1024, KV_LEN=1024)
# In this case, we don't need a score_mod, so we won't pass any in.
# However, score_mod can still be combined with block_mask if you need the additional flexibility.
flex_attention(query, key, value, block_mask=block_mask)
请注意,`create_block_mask` 是一个**相对昂贵的操作!** 尽管 FlexAttention 在它改变时不需要重新编译,但如果您不小心缓存它,它可能会导致显著的减速(请查看 FAQ 以获取最佳实践建议)。
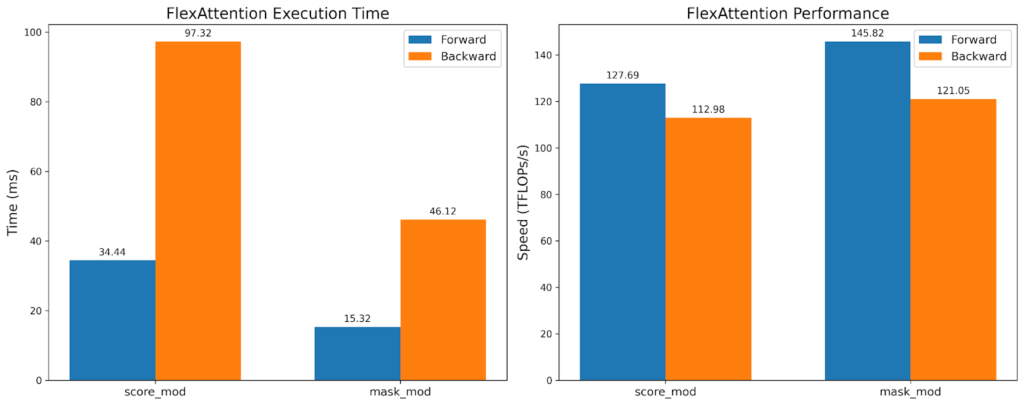
虽然 TFlops 大致相同,但 mask_mod 版本的执行时间快了 2 倍!这表明我们可以利用 BlockMask 提供的稀疏性,而*不*损失硬件效率。
滑动窗口 + 因果
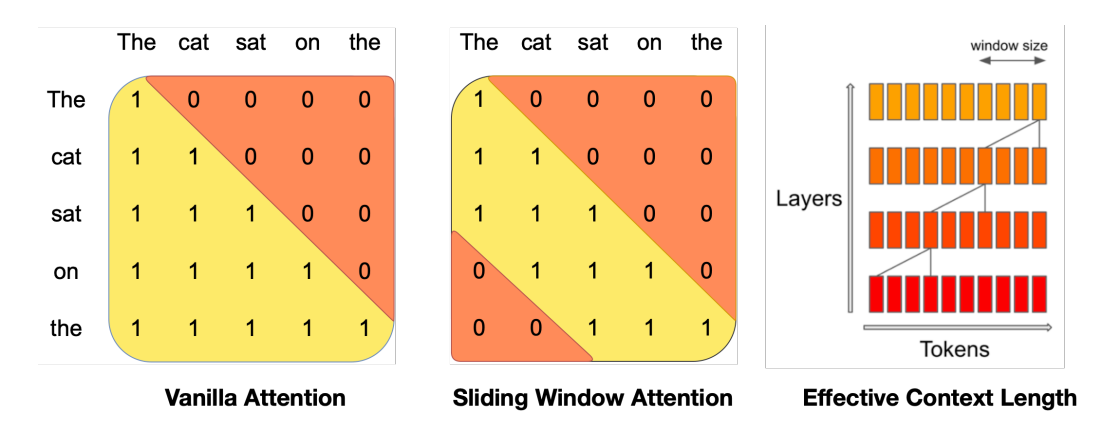
来源:Mistral 7B
由 Mistral 推广,滑动窗口注意力(也称为局部注意力)利用了最近的 token 最有用的直觉。特别是,它允许查询 token 只关注例如最近的 1024 个 token。这通常与因果注意力一起使用。
SLIDING_WINDOW = 1024
def sliding_window_causal(b, h, q_idx, kv_idx):
causal_mask = q_idx >= kv_idx
window_mask = q_idx - kv_idx <= SLIDING_WINDOW
return causal_mask & window_mask
# If you want to be cute...
from torch.nn.attention import and_masks
def sliding_window(b, h, q_idx, kv_idx)
return q_idx - kv_idx <= SLIDING_WINDOW
sliding_window_causal = and_masks(causal_mask, sliding_window)
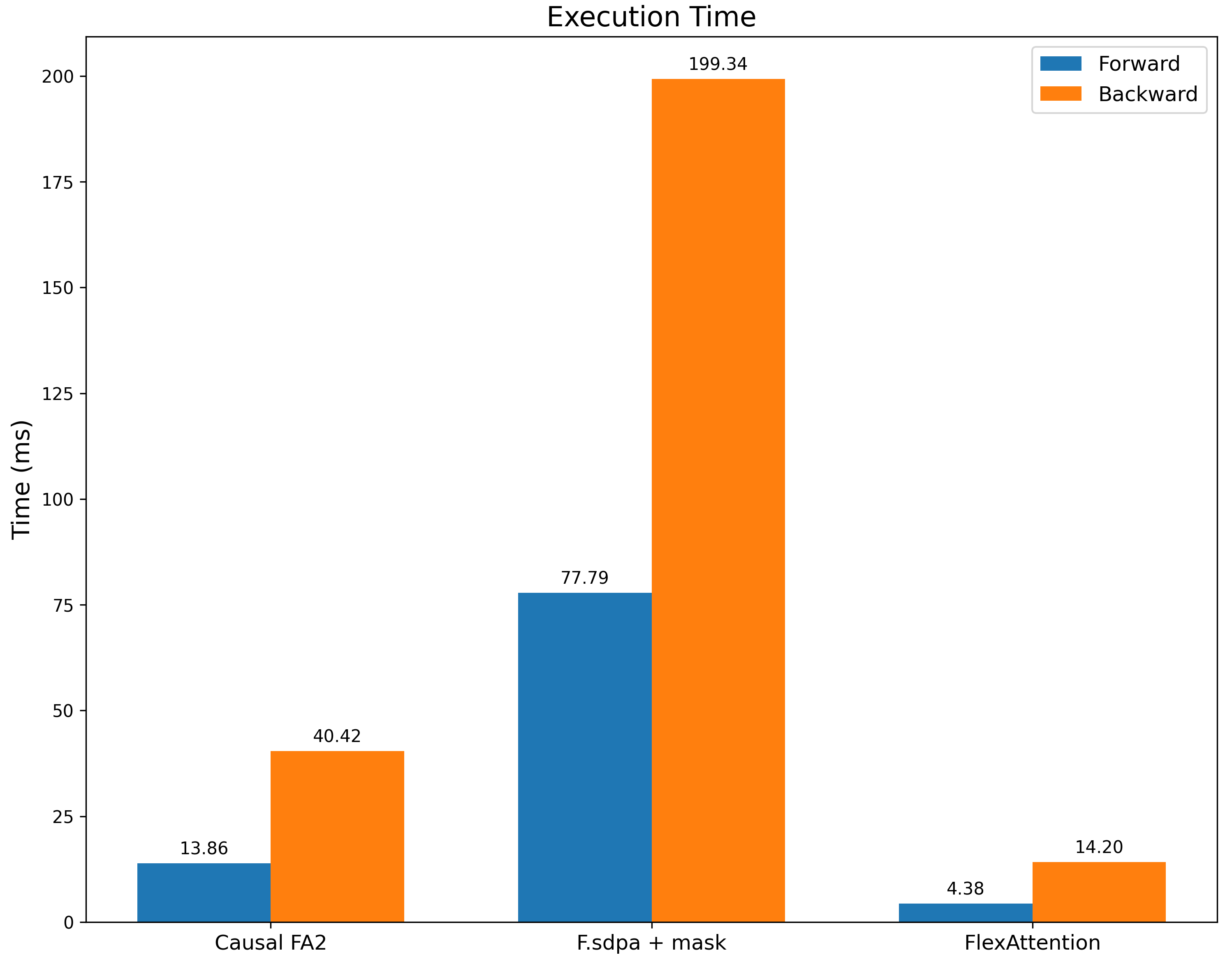
我们将其与带有滑动窗口掩码的 `F.scaled_dot_product_attention` 以及带有因果掩码的 FA2(作为性能参考点)进行基准测试。我们不仅比 `F.scaled_dot_product_attention` 快得多,我们*也*比带有因果掩码的 FA2 快得多,因为这个掩码具有显著更多的稀疏性。
PrefixLM
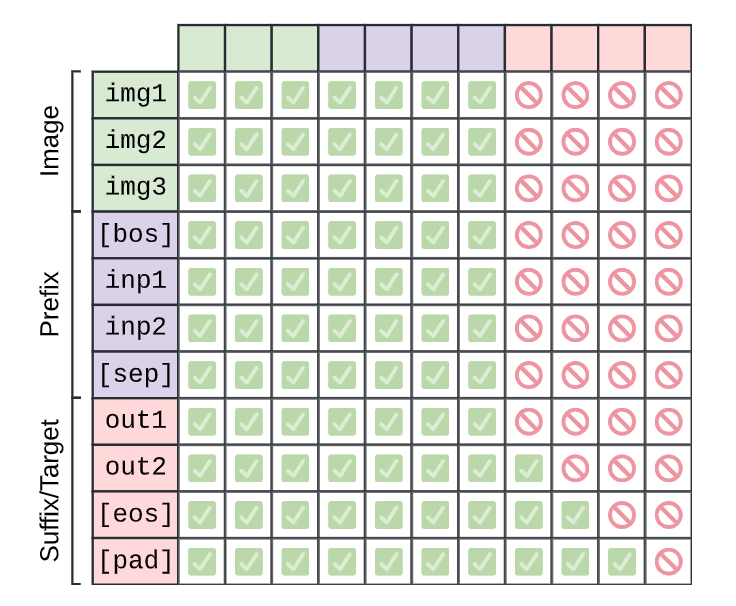
来源:PaliGemma: A versatile 3B VLM for transfer
在《探索统一文本到文本转换器的迁移学习极限》中提出的 T5 架构描述了一种注意力变体,它在“前缀”上执行完全双向注意力,在其余部分执行因果注意力。我们再次组合两个掩码函数来完成此操作,一个用于因果掩码,另一个基于前缀长度。
prefix_length: [B]
def prefix_mask(b, h, q_idx, kv_idx):
return kv_idx <= prefix_length[b]
prefix_lm_causal = or_masks(prefix_mask, causal_mask)
# In this case, our mask is different per sequence so we set B equal to our batch size
block_mask = create_block_mask(prefix_lm_causal, B=B, H=None, S, S)
就像 `score_mod` 一样,`mask_mod` 允许我们引用未明确作为函数输入的额外张量!然而,对于 prefixLM,稀疏模式是*每个输入*都会改变。这意味着对于每个新的输入批次,我们都需要重新计算 `BlockMask`。一种常见的模式是在模型开头调用 `create_block_mask` 并将该 `block_mask` 重用于模型中的所有注意力调用。请参阅*重新计算 BlockMasks 与重新编译*。
然而,作为回报,我们不仅能够为 prefixLM 提供高效的注意力内核,我们还能够利用输入中存在的任意稀疏性!FlexAttention 将根据 BlockMask 数据动态调整其性能,而*无需*重新编译内核。
文档掩码/锯齿序列
另一种常见的注意力变体是文档掩码/锯齿序列。想象一下您有许多长度不等的序列。您想将它们一起训练,但不幸的是,大多数操作符只接受矩形张量。
通过 `BlockMask`,我们也可以在 FlexAttention 中高效地支持它!
- 首先,我们将所有序列展平为单个序列,包含 sum(序列长度) 个 token。
- 然后,我们计算每个 token 所属的 document_id。
- 最后,在我们的 `mask_mod` 中,我们简单地判断查询和键值 token 是否属于同一个文档!
# The document that each token belongs to.
# e.g. [0, 0, 0, 1, 1, 2, 2, 2, 2, 2, 2] corresponds to sequence lengths 3, 2, and 6.
document_id: [SEQ_LEN]
def document_masking(b, h, q_idx, kv_idx):
return document_id[q_idx] == document_id[kv_idx]
就这样!在这种情况下,我们看到我们最终得到一个块对角掩码。
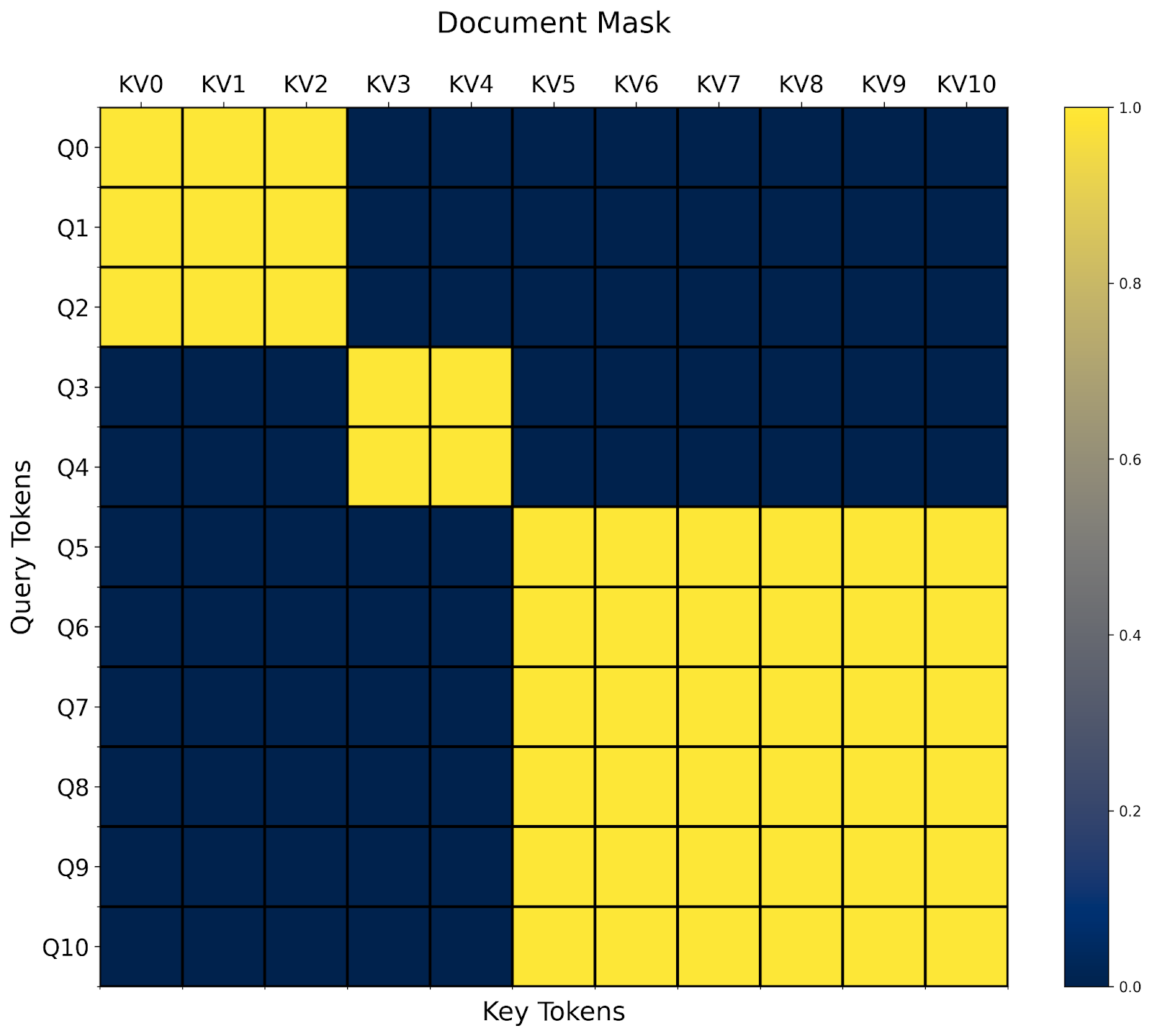
文档掩码的一个有趣之处在于,很容易看出它如何与任意其他掩码组合。例如,我们已经在上一节中定义了 `prefixlm_mask`。现在我们还需要定义一个 `prefixlm_document_mask` 函数吗?
在这些情况下,我们发现一种非常有用的模式是我们称之为“更高级别修改”的方法。在这种情况下,我们可以采用现有的 `mask_mod` 并自动将其转换为一个适用于锯齿序列的 `mask_mod`!
def generate_doc_mask_mod(mask_mod, document_id):
# Get unique document IDs and their counts
_, counts = torch.unique_consecutive(document_id, return_counts=True)
# Create cumulative counts (offsets)
offsets = torch.cat([torch.tensor([0], device=document_id.device), counts.cumsum(0)[:-1]])
def doc_mask_wrapper(b, h, q_idx, kv_idx):
same_doc = document_id[q_idx] == document_id[kv_idx]
q_logical = q_idx - offsets[document_id[q_idx]]
kv_logical = kv_idx - offsets[document_id[kv_idx]]
inner_mask = mask_mod(b, h, q_logical, kv_logical)
return same_doc & inner_mask
return doc_mask_wrapper
例如,给定上面的 `prefix_lm_causal` 掩码,我们可以将其转换为一个适用于打包文档的掩码,如下所示
prefix_length = torch.tensor(2, dtype=torch.int32, device="cuda")
def prefix_mask(b, h, q_idx, kv_idx):
return kv_idx < prefix_length
prefix_lm_causal = or_masks(prefix_mask, causal_mask)
doc_prefix_lm_causal_mask = generate_doc_mask_mod(prefix_lm_causal, document_id)
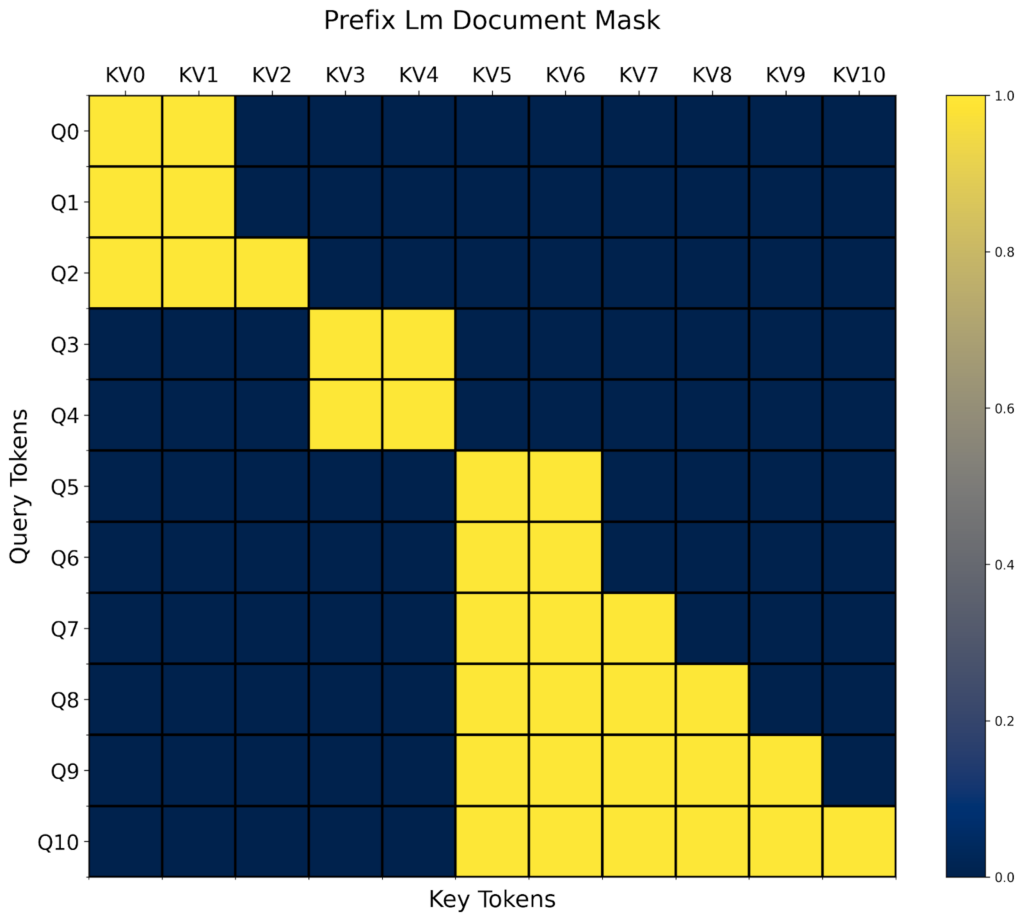
现在,这个掩码是“块-前缀LM-对角线”形状的。🙂
这就是我们所有的示例!注意力变体远不止我们能列出的,所以请查看Attention Gym以获取更多示例。我们希望社区也能贡献他们最喜欢的 FlexAttention 应用。
常见问题
问:FlexAttention 何时需要重新编译?
由于 FlexAttention 利用 `torch.compile` 进行图捕获,它实际上可以在广泛的场景中避免重新编译。值得注意的是,即使捕获的张量值发生变化,它也*不需要*重新编译!
flex_attention = torch.compile(flex_attention)
def create_bias_mod(bias)
def bias_mod(score, b, h, q_idx, kv_idx):
return score + bias
return bias_mod
bias_mod1 = create_bias_mod(torch.tensor(0))
flex_attention(..., score_mod=bias_mod1) # Compiles the kernel here
bias_mod2 = create_bias_mod(torch.tensor(2))
flex_attention(..., score_mod=bias_mod2) # Doesn't need to recompile!
即使更改块稀疏性也不需要重新编译。但是,如果块稀疏性发生变化,我们确实需要*重新计算* BlockMask。
问:我们应该何时重新计算 BlockMask?
每当块稀疏性改变时,我们都需要重新计算 BlockMask。尽管计算 BlockMask 比重新编译便宜得多(大约几百微秒而不是几秒),但您仍应注意不要过度重新计算 BlockMask。
以下是一些常见模式以及关于如何处理它们的建议。
掩码从不改变(例如因果掩码)
在这种情况下,您可以简单地预先计算块掩码并全局缓存它,将其重用于所有注意力调用。
block_mask = create_block_mask(causal_mask, 1, 1, S,S)
causal_attention = functools.partial(flex_attention, block_mask=block_mask)
掩码每批次都会变化(例如文档掩码)
在这种情况下,我们建议在模型开始时计算 BlockMask,并将其贯穿模型——将 BlockMask 重用于所有层。
def forward(self, x, doc_mask):
# Compute block mask at beginning of forwards
block_mask = create_block_mask(doc_mask, None, None, S, S)
x = self.layer1(x, block_mask)
x = self.layer2(x, block_mask)
...
# amortize block mask construction cost across all layers
x = self.layer3(x, block_mask)
return x
掩码每层变化(例如数据相关的稀疏性)
这是最困难的设置,因为我们无法在多次 FlexAttention 调用中摊销块掩码计算。尽管 FlexAttention 肯定仍然可以在这种情况下受益,但 BlockMask 的实际好处取决于您的注意力掩码的稀疏程度以及我们构建 BlockMask 的速度。这引出了…
问:我们如何更快地计算 BlockMask?
`create_block_mask` 不幸的是在内存和计算方面都相当昂贵,因为确定一个块是否完全稀疏需要评估该块中每个点的 `mask_mod`。有几种方法可以解决这个问题
- 如果您的掩码在批处理大小或头部之间相同,请确保您在这些维度上进行广播(即在 `create_block_mask` 中将它们设置为 `None`)。
- 编译 `create_block_mask`。不幸的是,目前 `torch.compile` 由于一些不幸的限制,无法直接作用于 `create_block_mask`。但是,您可以设置 `_compile=True`,这将显著降低峰值内存和运行时(在我们的测试中通常是一个数量级)。
- 为 BlockMask 编写自定义构造函数。BlockMask 的元数据非常简单(请参阅文档)。它本质上是两个张量。a. `num_blocks`:为每个查询块计算的 KV 块数。
b. `indices`:为每个查询块计算的 KV 块的位置。例如,这是 `causal_mask` 的自定义 BlockMask 构造函数。
def create_causal_mask(S):
BLOCK_SIZE = 128
# The first query block computes one block, the second query block computes 2 blocks, etc.
num_blocks = torch.arange(S // BLOCK_SIZE, device="cuda") + 1
# Since we're always computing from the left to the right,
# we can use the indices [0, 1, 2, ...] for every query block.
indices = torch.arange(S // BLOCK_SIZE, device="cuda").expand(
S // BLOCK_SIZE, S // BLOCK_SIZE
)
num_blocks = num_blocks[None, None, :]
indices = indices[None, None, :]
return BlockMask(num_blocks, indices, BLOCK_SIZE=BLOCK_SIZE, mask_mod=causal_mask)
问:为什么 `score_mod` 和 `mask_mod` 不同?难道 `mask_mod` 不仅仅是 `score_mod` 的一个特例吗?
非常敏锐的问题,假想的观众!事实上,任何 `mask_mod` 都可以很容易地转换为 `score_mod`(我们不建议在实践中使用此函数!)
def mask_mod_as_score_mod(b, h, q_idx, kv_idx):
return torch.where(mask_mod(b, h, q_idx, kv_idx), score, -float("inf"))
那么,如果 `score_mod` 可以实现 `mask_mod` 可以实现的所有功能,那么 `mask_mod` 的意义何在?
一个直接的挑战是:`score_mod` 需要实际的 `score` 值作为输入,但在预计算 BlockMask 时,我们没有实际的 `score` 值。我们或许可以通过传入全零来伪造这些值,如果 `score_mod` 返回 `-inf`,那么我们认为它被掩盖了(事实上,我们最初就是这样做的!)。
然而,存在两个问题。首先,这是不严谨的——如果用户的 `score_mod` 在输入为 0 时返回 `-inf` 怎么办?或者如果用户的 `score_mod` 用一个大的负值而不是 `-inf` 进行掩码处理怎么办?我们似乎在试图把圆钉子敲进方孔里。然而,将 `mask_mod` 与 `score_mod` 分开还有一个更重要的原因——它从根本上更高效!
事实证明,对每个计算出的元素应用掩码实际上非常昂贵——我们的基准测试显示性能下降约 15-20%!因此,尽管我们可以通过跳过一半计算来显著加速,但由于需要掩盖每个元素,我们损失了相当一部分加速!
幸运的是,如果我们可视化因果掩码,我们会注意到绝大多数块根本不需要“因果掩码”——它们是完全计算的!只有对角线上的块,部分计算和部分掩码的块,才需要应用掩码。
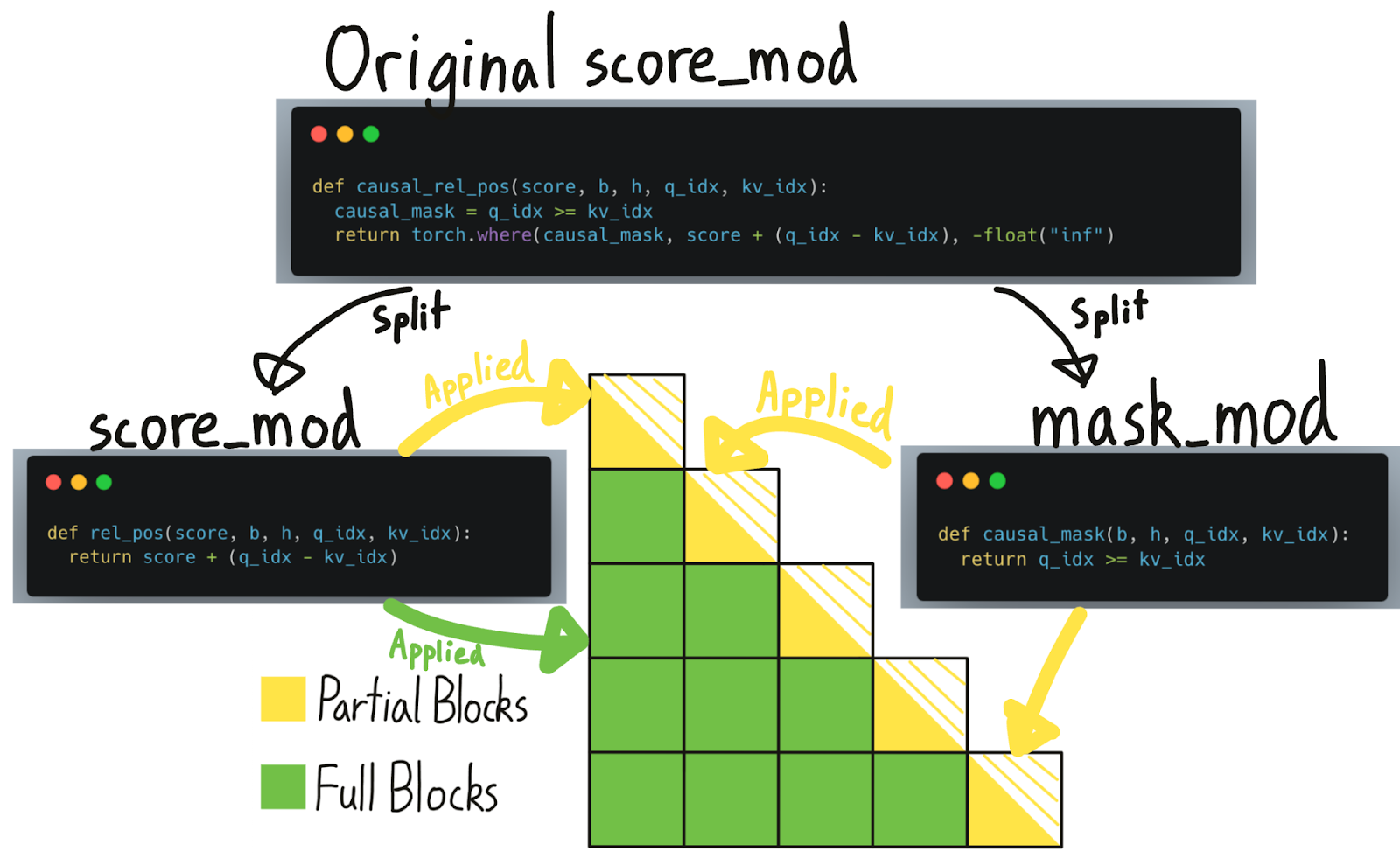
BlockMask 之前告诉我们哪些块需要计算,哪些块可以跳过。现在,我们进一步增强了这个数据结构,它还可以告诉我们哪些块是“完全计算的”(即可以跳过掩码)与“部分计算的”(即需要应用掩码)。但请注意,尽管在“完全计算的”块上可以跳过掩码,但其他 `score_mod`(如相对位置嵌入)仍然需要应用。
给定一个 `score_mod`,我们无法可靠地判断它的哪些部分是“掩码”。因此,用户必须将这些部分自己分成 `mask_mod`。
问:BlockMask 需要多少额外内存?
BlockMask 元数据的大小为 `[BATCH_SIZE, NUM_HEADS, QUERY_LEN//BLOCK_SIZE, KV_LEN//BLOCK_SIZE]`。如果掩码在批次或头维度上相同,则可以在该维度上进行广播以节省内存。
在默认的 `BLOCK_SIZE` 为 128 时,我们预计大多数用例的内存使用将可以忽略不计。例如,对于 100 万的序列长度,BlockMask 只会使用 60MB 的额外内存。如果这是一个问题,您可以增加块大小:`create_block_mask(..., BLOCK_SIZE=1024)`。例如,将 `BLOCK_SIZE` 增加到 1024 将导致此元数据下降到一兆字节以下。
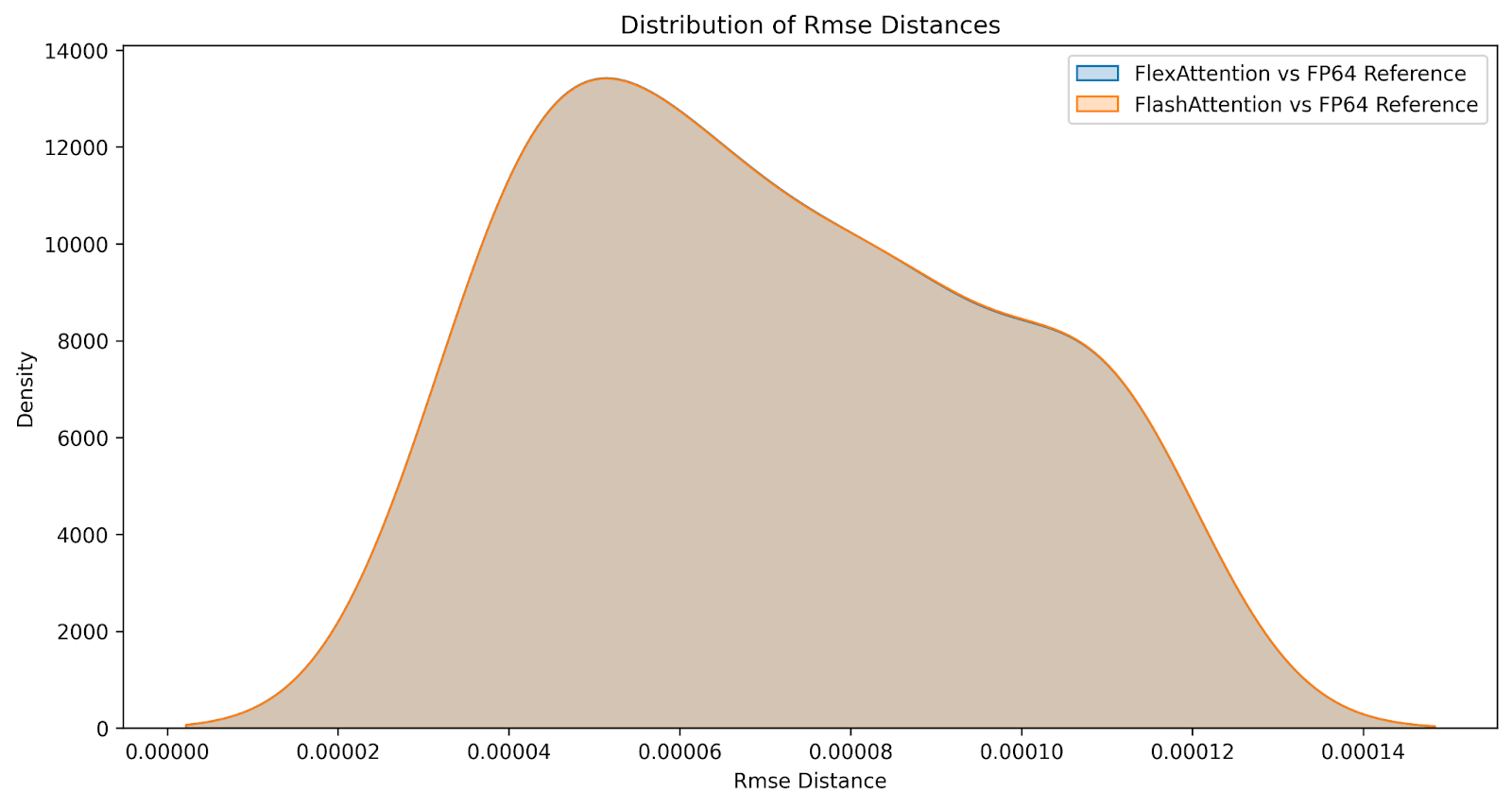
问:数值比较如何?
尽管结果并非位相同,但我们相信 FlexAttention 在数值上与 FlashAttention 一样准确。我们在一系列因果和非因果注意力变体的输入上比较了 FlashAttention 和 FlexAttention 的差异,生成了以下差异分布。误差几乎相同。
性能
通常来说,FlexAttention 的性能几乎与手写的 Triton 内核相当,这并不奇怪,因为我们大量利用了手写的 Triton 内核。然而,由于其通用性,我们确实会产生一小部分性能损失。例如,我们必须承担一些额外的延迟来确定接下来要计算哪个块。在某些情况下,我们提供了一些内核选项,它们可以在改变其行为的同时影响内核的性能。它们可以在这里找到:性能旋钮
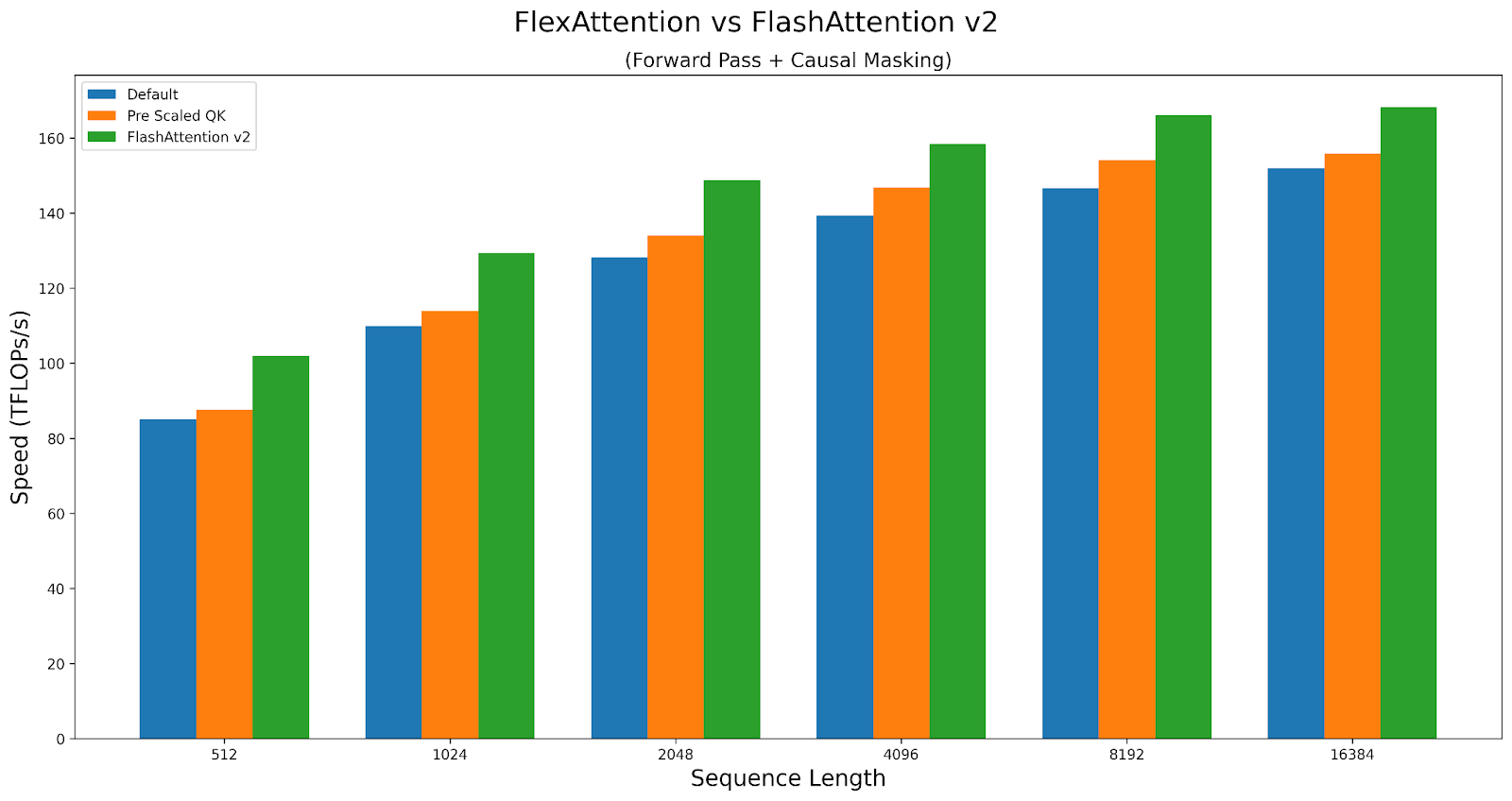
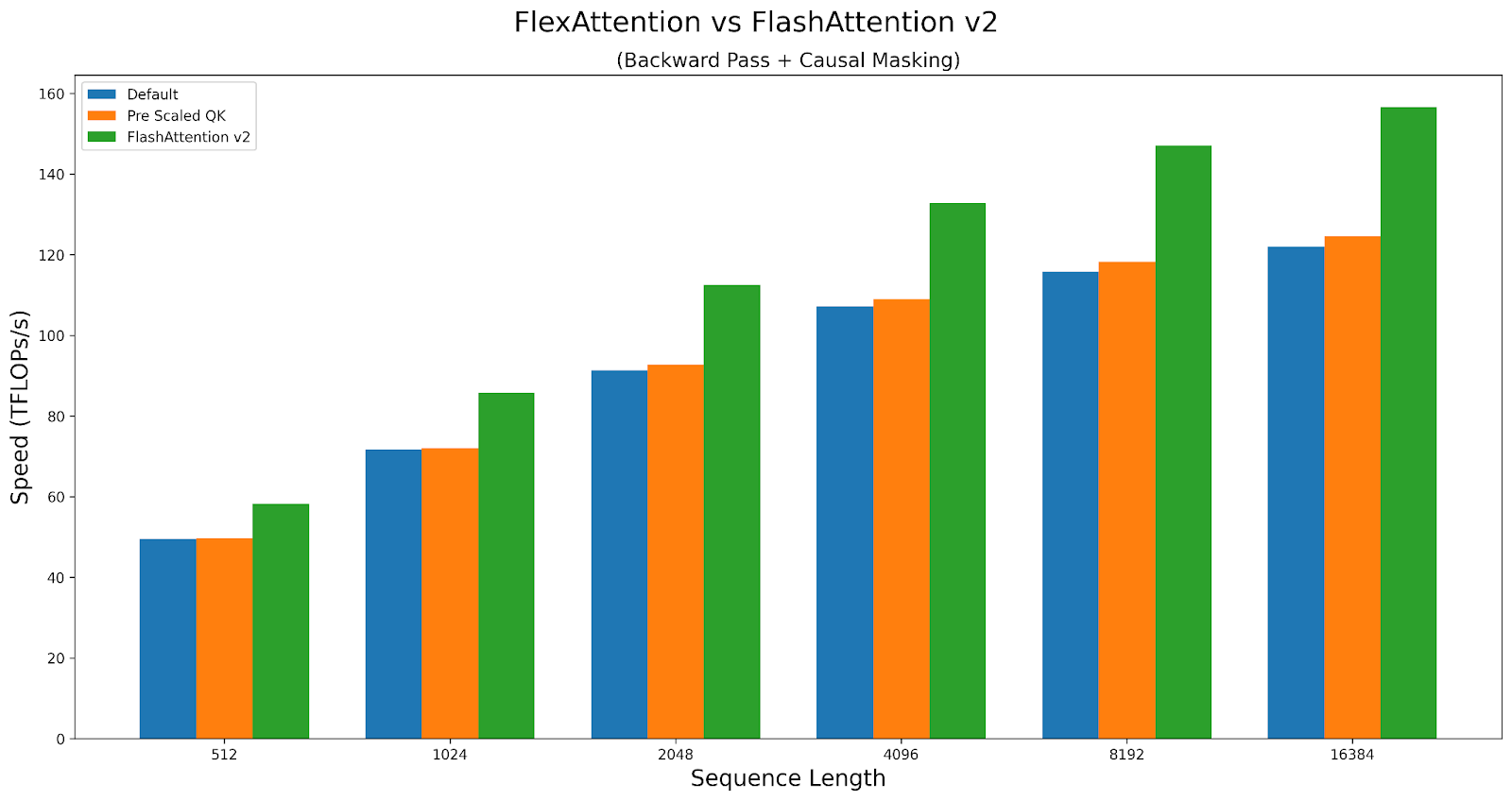
作为案例研究,让我们探讨这些旋钮如何影响因果注意力的性能。我们将比较 A100 上 Triton 内核与 FlashAttentionv2 的性能。脚本可以在此处找到。
FlexAttention 在前向传播中实现了 FlashAttention2 90% 的性能,在反向传播中实现了 85% 的性能。FlexAttention 目前正在使用一种确定性算法,它比 FAv2 重新计算更多的中间结果,但我们计划改进 FlexAttention 的反向传播算法,并希望弥合这一差距!
结论
我们希望您在使用 FlexAttention 时能像我们开发它时一样快乐!在开发过程中,我们发现了比预期更多的此 API 应用。我们已经看到它将 torchtune 的样本打包吞吐量提高了 71%,消除了研究人员需要花费一周多时间编写自己的自定义 Triton 内核的需求,并提供了与自定义手写注意力变体具有竞争力的性能。
最后,让 FlexAttention 的实现变得非常有趣的一点是,我们能够以一种有趣的方式利用许多现有的 PyTorch 基础设施。例如,TorchDynamo(torch.compile 的前端)的一个独特之处在于,它*不*要求编译函数中使用的张量作为输入显式传入。这使我们能够编译文档掩码等模块,这些模块需要访问*全局*变量,并且全局变量需要更改!
bias = torch.randn(1024, 1024)
def score_mod(score, b, h, q_idx, kv_idx):
return score + bias[q_idx][kv_idx] # The bias tensor can change!
此外,`torch.compile` 是一种通用图捕获机制,这一事实也使其能够支持更“高级”的转换,例如将任何 `mask_mod` 转换为适用于锯齿张量的高阶转换。
我们还利用 TorchInductor(torch.compile 的后端)基础设施来实现 Triton 模板。这不仅使得支持代码生成 FlexAttention 变得容易,而且还自动为我们提供了对动态形状和 epilogue 融合(即在注意力末尾融合一个操作符)的支持!将来,我们计划扩展此支持,以允许量化版本的注意力或像 RadixAttention 这样的功能。
此外,我们还利用了高阶操作、PyTorch 的自动求导来自动生成反向传播,以及 vmap 来自动应用 `score_mod` 以创建 BlockMask。
当然,没有 Triton 和 TorchInductor 生成 Triton 代码的能力,这个项目是不可能实现的。
我们期待在未来将我们在这里使用的方法应用于更多的应用程序!
局限性和未来工作
- FlexAttention 目前在 PyTorch 每夜发布版中可用,我们计划在 2.5.0 中将其作为原型功能发布
- 我们在这里没有介绍如何将 FlexAttention 用于推理(或如何实现 PagedAttention)——我们将在以后的文章中介绍。
- 我们正在努力提高 FlexAttention 的性能,使其与 H100 GPU 上的 FlashAttention3 匹配。
- FlexAttention 要求所有序列长度都是 128 的倍数——这个问题很快就会解决。
- 我们计划很快添加 GQA 支持——目前,您只需复制 kv 头即可。
致谢
我们要强调一些启发 FlexAttention 的前期工作(和人物)。
- Tri Dao 在 FlashAttention 方面的工作
- Francisco Massa 和 Xformers 团队在 Triton 中实现的 BlockSparseAttention
- Jax 团队在 SplashAttention 方面的工作
- Philippe Tillet 和 Keren Zhou 协助我们处理 Triton
- Ali Hassani 关于邻域注意力的讨论
- 所有抱怨注意力内核不支持他们最喜欢的注意力变体的人 🙂