今天,我们很高兴地宣布 PyTorch 引入了一项新的高级 CUDA 功能——CUDA 图。现代深度学习框架具有复杂的软件堆栈,每次向 GPU 提交操作都会产生显著的开销。当深度学习工作负载为提高性能而强力扩展到多个 GPU 时,每个 GPU 操作所需的时间会减少到几微秒,在这种情况下,框架高昂的工作提交延迟通常会导致 GPU 利用率低下。随着 GPU 速度的加快以及工作负载扩展到更多设备,工作负载因这些启动引起的停顿而受损的可能性会增加。为了克服这些性能开销,NVIDIA 工程师与 PyTorch 开发人员合作,在 PyTorch 中原生启用 CUDA 图执行。此设计对于扩展 NVIDIA 的 MLPerf 工作负载(在 PyTorch 中实现)至关重要,使其能够扩展到 4000 多个 GPU,从而实现破纪录的性能。

PyTorch 中对 CUDA 图的支持只是 NVIDIA 和 Facebook 工程师长期合作的又一个例子。torch.cuda.amp,例如,使用半精度进行训练,同时保持单精度实现的网络精度,并尽可能自动利用 Tensor Core。AMP 仅需几行代码更改即可提供比 FP32 高达 3 倍的性能。同样,NVIDIA 的Megatron-LM使用 PyTorch 在多达 3072 个 GPU 上进行了训练。在 PyTorch 中,扩展 GPU 训练的最有效方法之一是使用torch.nn.parallel.DistributedDataParallel与 NVIDIA Collective Communications Library (NCCL) 后端结合使用。
CUDA 图
CUDA 图于 CUDA 10 首次亮相,它允许将一系列 CUDA 内核定义和封装为一个单元,即一个操作图,而不是一系列单独启动的操作。它提供了一种通过单个 CPU 操作启动多个 GPU 操作的机制,从而减少了启动开销。
CUDA 图的优势可以通过图 1 中的简单示例进行演示。在顶部,CPU 逐个启动一系列短内核。CPU 启动开销在内核之间造成了显著的间隔。如果我们将这一系列内核替换为 CUDA 图,最初我们需要花费一些额外的时间来构建图并在第一次一次性启动整个图,但后续执行将非常快,因为内核之间几乎没有间隔。当相同的操作序列重复多次时,例如在许多训练步骤中,这种差异会更加明显。在这种情况下,构建和启动图的初始成本将在整个训练迭代次数中摊销。有关该主题的更全面的介绍,请参阅我们的博客CUDA 图入门和 GTC 演讲轻松实现 CUDA 图。
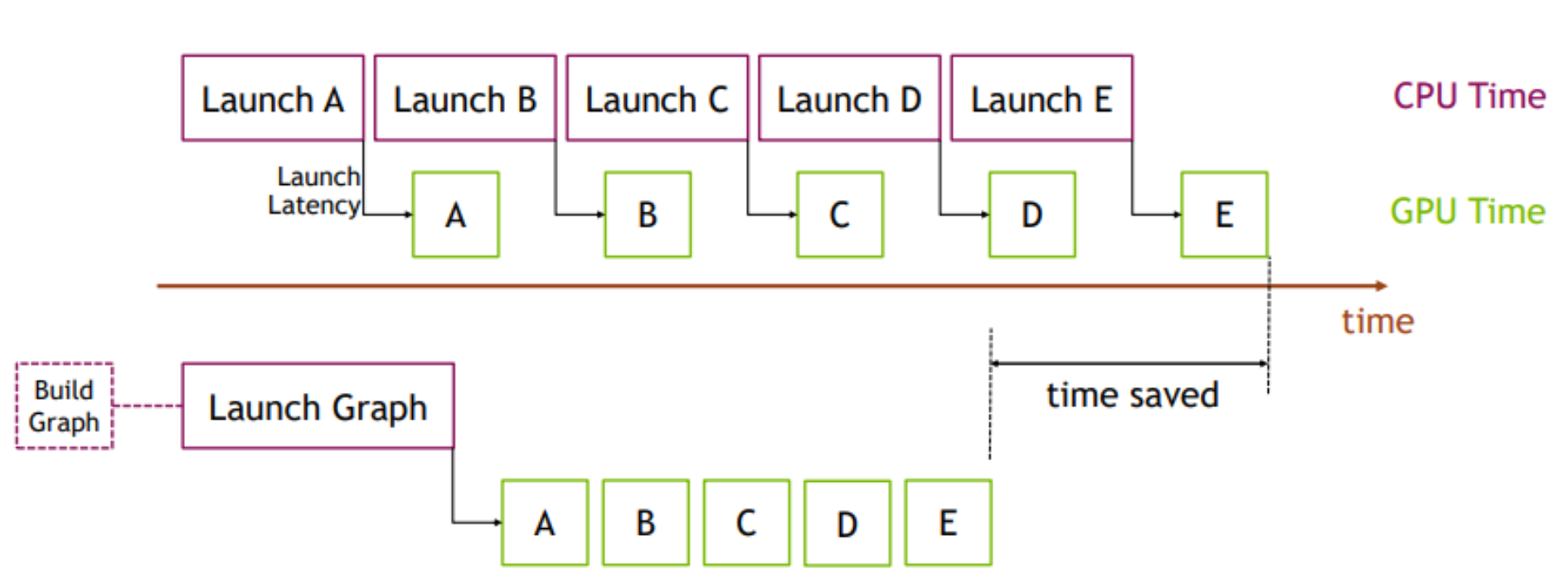
图 1. 使用 CUDA 图的优势
NCCL 对 CUDA 图的支持
前面提到的减少启动开销的优势也延伸到 NCCL 内核启动。NCCL 支持基于 GPU 的集体通信和 P2P 通信。借助NCCL 对 CUDA 图的支持,我们可以消除 NCCL 内核启动开销。
此外,由于各种 CPU 负载和操作系统因素,内核启动时间可能不可预测。这种时间偏差可能对 NCCL 集体操作的性能有害。借助 CUDA 图,内核被捆绑在一起,从而使分布式工作负载中各等级的性能保持一致。这在大型集群中特别有用,因为即使单个缓慢的节点也可能降低整个集群级别的性能。
对于分布式多 GPU 工作负载,NCCL 用于集体通信。如果我们查看利用数据并行性训练神经网络,如果没有 NCCL 对 CUDA 图的支持,我们将需要为前向/后向传播和 NCCL AllReduce 分别启动。相比之下,借助 NCCL 对 CUDA 图的支持,我们可以通过将前向/后向传播和 NCCL AllReduce 全部捆绑到单个图启动中来减少启动开销。

图 2. 观察典型的神经网络,所有 NCCL AllReduce 的内核启动都可以打包成一个图以减少开销启动时间。
PyTorch CUDA 图
从 PyTorch v1.10 开始,CUDA 图功能作为一组 Beta API 提供。
API 概述
PyTorch 支持使用流捕获构建 CUDA 图,它将 CUDA 流置于捕获模式。发给捕获流的 CUDA 工作实际上不会在 GPU 上运行。相反,工作会被记录在一个图中。捕获后,可以启动该图以根据需要运行 GPU 工作任意多次。每次重放都以相同的参数运行相同的内核。对于指针参数,这意味着使用相同的内存地址。通过在每次重放之前用新数据(例如,来自新批次)填充输入内存,您可以对新数据重新运行相同的工作。
重放图牺牲了典型即时执行的动态灵活性,以换取大大降低的 CPU 开销。图的参数和内核是固定的,因此图重放跳过了所有参数设置和内核调度层,包括 Python、C++ 和 CUDA 驱动程序开销。在底层,重放通过单个调用cudaGraphLaunch将整个图的工作提交给 GPU。重放中的内核在 GPU 上执行速度也略快,但消除 CPU 开销是主要优势。
如果您的网络全部或部分是图安全的(通常这意味着静态形状和静态控制流,但请参阅其他限制),并且您怀疑其运行时至少在某种程度上受到 CPU 限制,那么您应该尝试使用 CUDA 图。
API 示例
PyTorch 通过原始的torch.cuda.CUDAGraph类和两个便利包装器torch.cuda.graph和torch.cuda.make_graphed_callables暴露图。
torch.cuda.graph是一个简单、多功能的上下文管理器,可在其上下文中捕获 CUDA 工作。在捕获之前,通过运行几次即时迭代来预热要捕获的工作负载。预热必须在侧流上进行。由于图在每次重放中都从相同的内存地址读取和写入,因此您必须在捕获期间维护对保存输入和输出数据的张量的长期引用。要在新输入数据上运行图,请将新数据复制到捕获的输入张量中,重放图,然后从捕获的输出张量中读取新输出。
如果整个网络捕获安全,则可以捕获并重放整个网络,如以下示例所示。
N, D_in, H, D_out = 640, 4096, 2048, 1024
model = torch.nn.Sequential(torch.nn.Linear(D_in, H),
torch.nn.Dropout(p=0.2),
torch.nn.Linear(H, D_out),
torch.nn.Dropout(p=0.1)).cuda()
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# Placeholders used for capture
static_input = torch.randn(N, D_in, device='cuda')
static_target = torch.randn(N, D_out, device='cuda')
# warmup
# Uses static_input and static_target here for convenience,
# but in a real setting, because the warmup includes optimizer.step()
# you must use a few batches of real data.
s = torch.cuda.Stream()
s.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(s):
for i in range(3):
optimizer.zero_grad(set_to_none=True)
y_pred = model(static_input)
loss = loss_fn(y_pred, static_target)
loss.backward()
optimizer.step()
torch.cuda.current_stream().wait_stream(s)
# capture
g = torch.cuda.CUDAGraph()
# Sets grads to None before capture, so backward() will create
# .grad attributes with allocations from the graph's private pool
optimizer.zero_grad(set_to_none=True)
with torch.cuda.graph(g):
static_y_pred = model(static_input)
static_loss = loss_fn(static_y_pred, static_target)
static_loss.backward()
optimizer.step()
real_inputs = [torch.rand_like(static_input) for _ in range(10)]
real_targets = [torch.rand_like(static_target) for _ in range(10)]
for data, target in zip(real_inputs, real_targets):
# Fills the graph's input memory with new data to compute on
static_input.copy_(data)
static_target.copy_(target)
# replay() includes forward, backward, and step.
# You don't even need to call optimizer.zero_grad() between iterations
# because the captured backward refills static .grad tensors in place.
g.replay()
# Params have been updated. static_y_pred, static_loss, and .grad
# attributes hold values from computing on this iteration's data.
如果您的网络中的某些部分不安全无法捕获(例如,由于动态控制流、动态形状、CPU 同步或必要的 CPU 端逻辑),您可以即时运行不安全的部分,并使用torch.cuda.make_graphed_callables仅对捕获安全的部分进行图化。接下来将演示这一点。
make_graphed_callables接受可调用对象(函数或nn.Module)并返回图化版本。默认情况下,由make_graphed_callables返回的可调用对象是自动求导感知的,可以在训练循环中直接替代您传入的函数或nn.Module。make_graphed_callables内部创建CUDAGraph对象,运行预热迭代,并根据需要维护静态输入和输出。因此(与torch.cuda.graph不同),您不需要手动处理这些。
在以下示例中,依赖数据的动态控制流意味着网络无法端到端捕获,但make_graphed_callables() 让我们无论如何都可以捕获并运行图安全的部分作为图
N, D_in, H, D_out = 640, 4096, 2048, 1024
module1 = torch.nn.Linear(D_in, H).cuda()
module2 = torch.nn.Linear(H, D_out).cuda()
module3 = torch.nn.Linear(H, D_out).cuda()
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.SGD(chain(module1.parameters(),
module2.parameters(),
module3.parameters()),
lr=0.1)
# Sample inputs used for capture
# requires_grad state of sample inputs must match
# requires_grad state of real inputs each callable will see.
x = torch.randn(N, D_in, device='cuda')
h = torch.randn(N, H, device='cuda', requires_grad=True)
module1 = torch.cuda.make_graphed_callables(module1, (x,))
module2 = torch.cuda.make_graphed_callables(module2, (h,))
module3 = torch.cuda.make_graphed_callables(module3, (h,))
real_inputs = [torch.rand_like(x) for _ in range(10)]
real_targets = [torch.randn(N, D_out, device="cuda") for _ in range(10)]
for data, target in zip(real_inputs, real_targets):
optimizer.zero_grad(set_to_none=True)
tmp = module1(data) # forward ops run as a graph
if tmp.sum().item() > 0:
tmp = module2(tmp) # forward ops run as a graph
else:
tmp = module3(tmp) # forward ops run as a graph
loss = loss_fn(tmp, target)
# module2's or module3's (whichever was chosen) backward ops,
# as well as module1's backward ops, run as graphs
loss.backward()
optimizer.step()
示例用例
MLPerf v1.0 训练工作负载
PyTorch CUDA 图功能在将 NVIDIA 的 MLPerf 训练 v1.0 工作负载(在 PyTorch 中实现)扩展到 4000 多个 GPU 方面发挥了重要作用,在所有方面都创造了新纪录。我们将在下面展示两个 MLPerf 工作负载,其中使用 CUDA 图获得了最显著的增益,速度提升高达约 1.7 倍。
| GPU 数量 | CUDA 图带来的加速比 | |
|---|---|---|
| Mask R-CNN | 272 | 1.70倍 |
| BERT | 4096 | 1.12倍 |
表 1. PyTorch CUDA 图对 MLPerf 训练 v1.0 性能的提升。
Mask R-CNN
深度学习框架使用 GPU 加速计算,但仍有大量代码在 CPU 核心上运行。CPU 核心处理张量形状等元数据,以准备启动 GPU 内核所需的参数。处理元数据是固定成本,而 GPU 完成的计算工作的成本与批处理大小正相关。对于大批处理大小,CPU 开销占总运行时间成本的百分比可以忽略不计,但对于小批处理大小,CPU 开销可能大于 GPU 运行时间。发生这种情况时,GPU 在内核调用之间处于空闲状态。这个问题可以在图 3 的 NSight 时间轴图中识别。下图显示了 Mask R-CNN 的“骨干”部分,每个 GPU 的批处理大小为 1,在图化之前。绿色部分显示 CPU 负载,蓝色部分显示 GPU 负载。在此配置文件中,我们看到 CPU 负载达到 100%,而 GPU 大部分时间处于空闲状态,GPU 内核之间存在大量空白区域。

图 3:Mask R-CNN 的 NSight 时间线图
当张量形状是静态的时,CUDA 图可以自动消除 CPU 开销。在第一步中捕获所有内核调用的完整图,在后续步骤中,整个图通过单个操作启动,从而消除所有 CPU 开销,如图 4 所示。

图 4:CUDA 图优化
通过图化,我们看到 GPU 内核紧密打包,GPU 利用率保持较高。图化部分现在在 6 毫秒内运行,而不是 31 毫秒,速度提升了 5 倍。我们没有对整个模型进行图化,主要只是 resnet 骨干网络,这导致整体速度提升了约 1.7 倍。为了扩大图的范围,我们对软件堆栈进行了一些更改,以消除一些 CPU-GPU 同步点。在 MLPerf v1.0 中,这项工作包括将 torch.randperm 函数的实现更改为使用 CUB 而不是 Thrust,因为后者是一个同步的 C++ 模板库。这些改进可在最新的 NGC 容器中获得。
BERT
同样,通过图形捕获模型,我们消除了 CPU 开销以及伴随的同步开销。CUDA 图实现使我们最大规模的 BERT 配置性能提升了 1.12 倍。为了最大化 CUDA 图的优势,重要的是要尽可能扩大图的范围。为此,我们修改了模型脚本以在执行过程中移除 CPU-GPU 同步,以便可以完整捕获模型图。此外,我们还确保执行期间图范围内的张量大小是静态的。例如,在 BERT 中,只有总标记的特定子集对损失函数有贡献,这由预生成的掩码张量决定。从该掩码中提取有效标记的索引,并使用这些索引收集对损失有贡献的标记,会生成一个具有动态形状的张量,即在迭代之间形状不恒定。为了确保张量大小是静态的,我们没有在损失计算中使用动态形状张量,而是使用了静态形状张量,其中使用掩码来指示哪些元素有效。因此,所有张量形状都是静态的。动态形状还需要 CPU-GPU 同步,因为它必须涉及框架在 CPU 端的内存管理。对于仅静态形状,不需要 CPU-GPU 同步。这在图 5 中显示。

图 5. 通过使用固定大小的张量和布尔掩码,如文中所述,我们能够消除动态大小张量所需的 CPU 同步
NVIDIA 深度学习示例集合中的 CUDA 图
单 GPU 用例也可以从使用 CUDA 图中受益。对于启动许多具有小批次的短内核的工作负载尤其如此。一个很好的例子是推荐系统的训练和推理。下面我们展示了 NVIDIA 深度学习示例集合中深度学习推荐模型 (DLRM) 实现的初步基准测试结果。为此工作负载使用 CUDA 图为训练和推理都提供了显著的加速。当使用非常小的批次大小时,效果尤其明显,因为 CPU 开销更加突出。
CUDA 图正在积极集成到其他 PyTorch NGC 模型脚本和 NVIDIA Github 深度学习示例中。敬请关注更多关于如何使用它的示例。
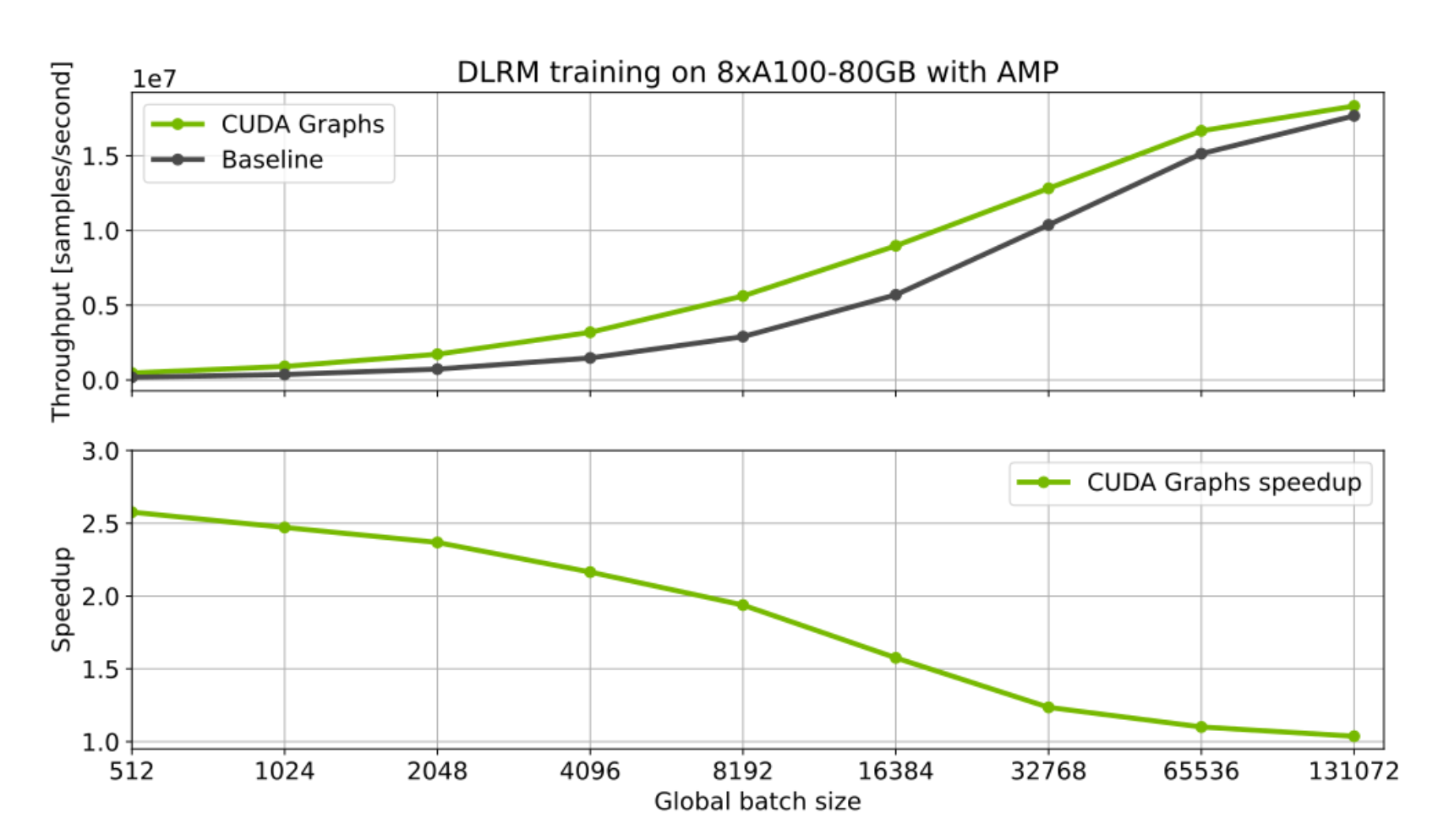

图 6:DLRM 模型的 CUDA 图优化。
行动号召:PyTorch v1.10 中的 CUDA 图
CUDA 图可以为包含许多小型 GPU 内核并因此受 CPU 启动开销拖累的工作负载提供巨大的好处。这已在我们的 MLPerf 工作中得到证明,优化了 PyTorch 模型。许多这些优化,包括 CUDA 图,已经或最终将集成到我们的 PyTorch NGC 模型脚本集合和 NVIDIA Github 深度学习示例中。目前,请查看我们的开源 MLPerf 训练 v1.0 实现,它可以作为了解 CUDA 图实际运作的良好起点。或者,在您自己的工作负载上尝试 PyTorch CUDA 图 API。
我们感谢许多 NVIDIA 和 Facebook 工程师的讨论和建议:Karthik Mandakolathur US、Tomasz Grel、PLJoey Conway、Arslan Zulfiqar US
作者简介
Vinh Nguyen 深度学习工程师,NVIDIA
Vinh 是一位深度学习工程师和数据科学家,已发表 50 多篇科学文章,引用次数超过 2500 次。在 NVIDIA,他的工作涵盖广泛的深度学习和人工智能应用,包括语音、语言和视觉处理以及推荐系统。
Michael Carilli 高级开发者技术工程师,NVIDIA
Michael 曾在空军研究实验室工作,为现代并行架构优化 CFD 代码。他拥有加州大学圣巴巴拉分校计算物理学博士学位。作为 PyTorch 团队的一员,他致力于使内部团队、外部客户和 PyTorch 社区用户能够更快、数值更稳定、更轻松地进行 GPU 训练。
Sukru Burc Eryilmaz 开发架构高级架构师,NVIDIA
Sukru 获得斯坦福大学博士学位和 Bilkent 大学学士学位。他目前致力于改进单节点规模和超级计算机规模的神经网络训练的端到端性能。
Vartika Singh 深度学习框架和库技术合作伙伴主管,NVIDIA
Vartika 曾领导团队在云和分布式计算、扩展和人工智能的交汇点工作,影响了主要公司的设计和战略。她目前与主要框架和编译器组织以及 NVIDIA 内外的开发人员合作,帮助设计在 NVIDIA 硬件上高效、优化地工作。
Michelle Lin 产品实习生,NVIDIA
Michelle 目前在加州大学伯克利分校攻读计算机科学与工商管理本科学位。她目前负责管理项目执行,例如进行市场调研和为 Magnum IO 创建营销资产。
Natalia Gimelshein 应用研究科学家,Facebook
Natalia Gimelshein 曾在 NVIDIA 和 Facebook 致力于深度学习工作负载的 GPU 性能优化。她目前是 PyTorch 核心团队成员,与合作伙伴合作无缝支持新的软件和硬件功能。
Alban Desmaison 研究工程师,Facebook
Alban 学习工程学并获得了机器学习和优化博士学位,在此期间他曾是 PyTorch 的 OSS 贡献者,之后加入了 Facebook。他的主要职责是维护一些核心库和功能(autograd、optim、nn),并致力于全面改进 PyTorch。
Edward Yang 研究工程师,Facebook
Edward 在麻省理工学院和斯坦福大学学习计算机科学,之后加入 Facebook。他是 PyTorch 核心团队的一员,也是 PyTorch 的主要贡献者之一。