TL;DR. 我们将以 Andrej Karpathy 的 GPT 模型紧凑型开源实现 nanoGPT 为例,展示如何使用加速 PyTorch 2.0 Transformer 和新引入的 torch.compile() 方法来加速大型语言模型。使用加速 PT2 Transformer 引入的新 缩放点积注意力运算符,我们选择 flash_attention 自定义内核,并实现了更快的每批次训练时间(使用 Nvidia A100 GPU 测量),从基准的约 143 毫秒/批次降至约 113 毫秒/批次。此外,使用 SDPA 运算符的增强实现提供了更好的数值稳定性。最后,使用填充输入进一步实现了优化,与 flash attention 结合后可将每批次训练时间缩短至约 87 毫秒。
近期,大型语言模型 (LLM) 和生成式 AI 在日常生活中得到了爆炸式普及。与这些不断增长的模型紧密相关的是不断增长的训练成本——无论是时间还是硬件利用率。PyTorch 团队通过 加速 PyTorch 2 Transformer(以前称为“Better Transformer”)和 PyTorch 2.0 中的 JIT 编译,直接应对了这些挑战。
在这篇博客文章中,我们探讨了通过利用 SDPA(也称为缩放点积注意力)的自定义内核实现所获得的训练优化,SDPA 是 Transformer 模型中的一个关键层。SDPA 的自定义内核将几个离散的顺序操作替换为一个全局优化的内核,从而避免分配大量中间 CUDA 内存。这种方法具有许多优点,包括但不限于:通过减少内存带宽瓶颈来提高 SDPA 的计算性能、减少内存占用以支持更大的批次大小,以及最后通过预缩放输入张量来增加数值稳定性。这些优化将在 Andrej Karpathy 的 GPT 开源实现 nanoGPT 上进行演示。
背景
缩放点积注意力是多头注意力的基本组成部分,正如 “Attention is All You Need” 中所介绍的,它在 LLM 和生成式 AI 模型中具有广泛的应用。
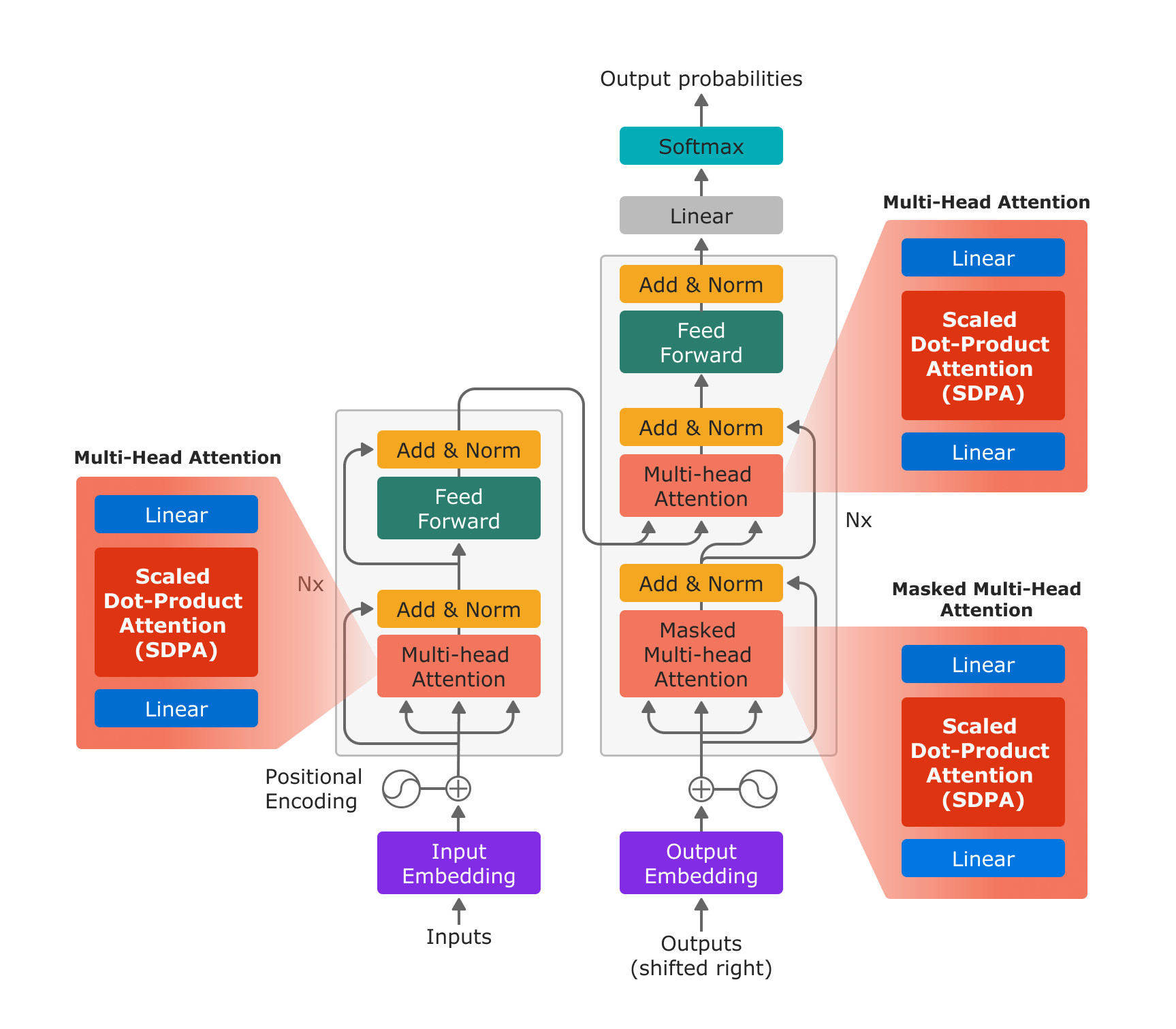
图 1:基于 “Attention is All You Need” 的 Transformer 模型架构。借助新的 PyTorch SDPA 运算符,多头注意力通过用于输入投影的线性层、SDPA 运算符和用于输出投影的线性层高效实现。
有了新的 scaled_dot_product_attention 运算符,多头注意力只需 3 个步骤即可实现:使用线性层进行内投影、SDPA 以及使用线性层进行外投影。
# In Projection
# variable descriptions:
# q,k,v = Query, Key, Value tensors
# bsz = batch size
# num_heads = Numner of heads for Multihead Attention
# tgt_len = Target length
# src_len = Source Length
# head_dim: Head Dimension
q, k, v = _in_projection(query, key, value, q_proj_weight, k_proj_weight, v_proj_weight, b_q, b_k, b_v)
q = q.view(bsz, num_heads, tgt_len, head_dim)
k = k.view(bsz, num_heads, src_len, head_dim)
v = v.view(bsz, num_heads, src_len, head_dim)
# Scaled Dot Product Attention
attn_output = scaled_dot_product_attention(q, k, v, attn_mask, dropout_p, is_causal)
# Out Projection
attn_output = attn_output.permute(2, 0, 1, 3).contiguous().view(bsz * tgt_len, embed_dim)
attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
PyTorch 2. 支持多种针对特定用例和特定要求进行优化的不同内核。内核选择器会为特定输入参数组合选择最佳内核。如果无法识别出针对特定输入参数组合的优化“自定义内核”,则内核选择器会选择一个可以处理所有输入组合的通用内核。
尽管未来的版本可能会扩展这组运算符,但 PyTorch 2.0 推出了 SDPA 运算符的 3 种实现
- 实现 SDPA 数学方程的通用内核
sdpa_math() - 基于“Flash Attention”论文的优化内核,支持在计算架构 SM80 (A100) 上使用 16 位浮点数据类型评估 SDPA。
- 基于“Self-Attention Does Not Need O(n^2) Memory”论文并在 xFormer 中实现的优化内核,支持在更广泛的架构(SM40 及更高版本)上使用 32 位和 16 位浮点数据类型。这篇博客文章将此内核称为
mem_efficient内核。
请注意,这两个优化内核(上面列出的第二和第三个)都支持键填充掩码,并将支持的注意力掩码限制为因果注意力。加速 PyTorch 2.0 Transformer 目前仅在通过 is_causal 布尔值指定因果掩码时才支持。当指定掩码时,将选择通用内核,因为分析提供的掩码内容以确定它是否是因果掩码的成本太高。有关每个内核限制的更多解释,请参阅 加速 PT2 Transformer 博客。
使用 nanoGPT 启用加速 Transformer
SDPA 运算符作为 GPT 模型的一个关键组件,我们将开源 nanoGPT 模型视为一个极佳的候选模型,可以轻松演示 PyTorch 2.0 加速 Transformer 的实现和优势。下面展示了在 nanoGPT 上启用加速 Transformer 的确切过程。
此过程主要围绕用 functional.py 中新增的 F.scaled_dot_product_attention 运算符替换现有的 SDPA 实现。此过程可以轻松调整,以便在许多其他 LLM 中启用该运算符。或者,用户也可以选择调用 F.multi_head_attention_forward() 或直接利用 nn.MultiHeadAttention 模块(如果适用)。以下代码片段改编自 Karpathy 的 nanoGPT 存储库。
第 1 步:识别现有 SDPA 实现
就 nanoGPT 而言,SDPA 在模型的 CausalSelfAttention 类中实现。撰写本文时,原始实现已在此处进行改编。
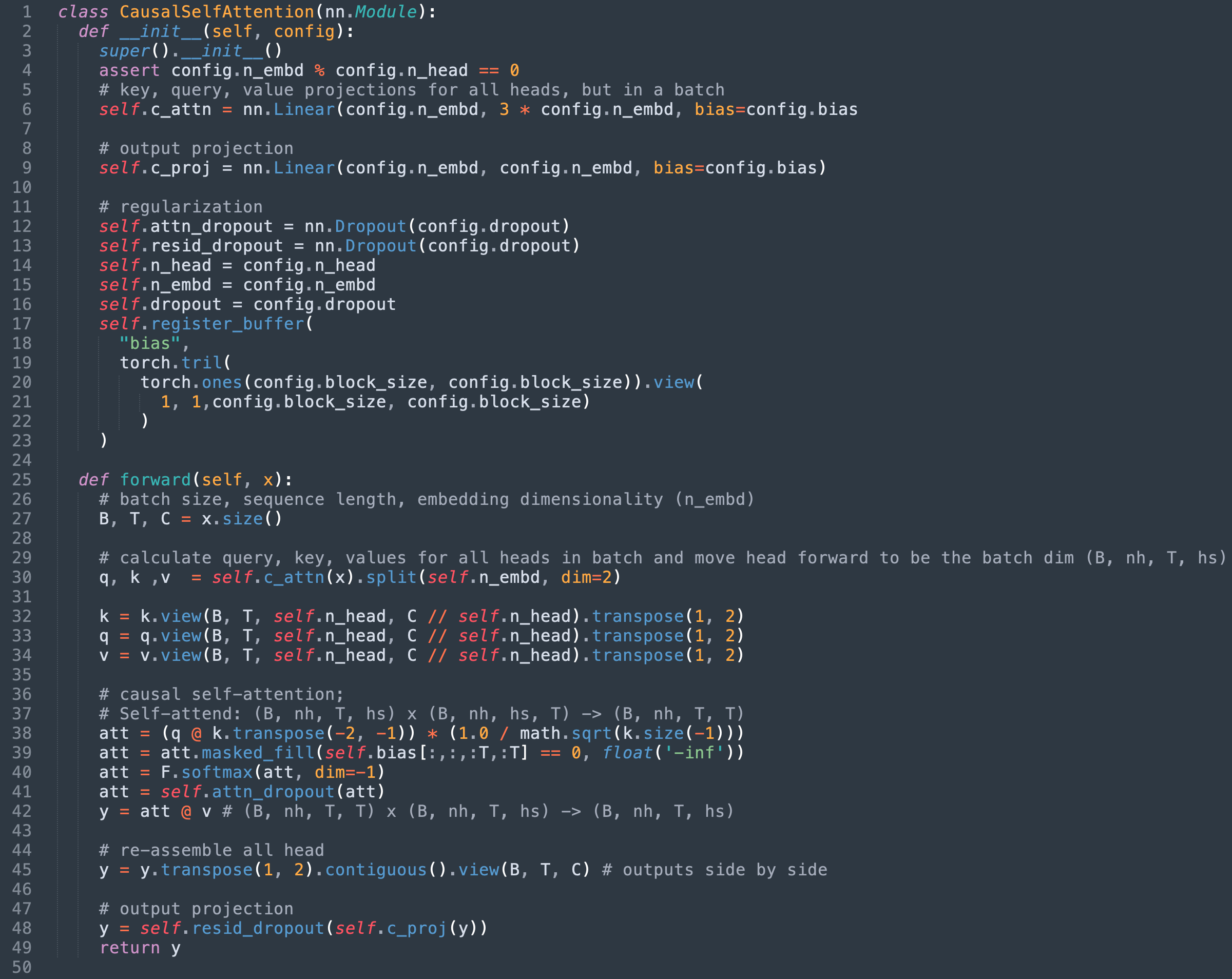
第 2 步:替换为 Torch 的 scaled_dot_product_attention
此时我们可以注意到以下几点
- 第 36 – 42 行定义了我们正在替换的 SDPA 的数学实现
- 第 39 行应用的掩码不再相关,因为我们使用的是 scaled_dot_product_attention 的
is_causal标志。 - 第 41 行使用的 dropout 层也变得不必要。
将 SDPA 实现替换为 torch 的 scaled_dot_product_attention 并删除现在冗余的代码,将得到以下实现。
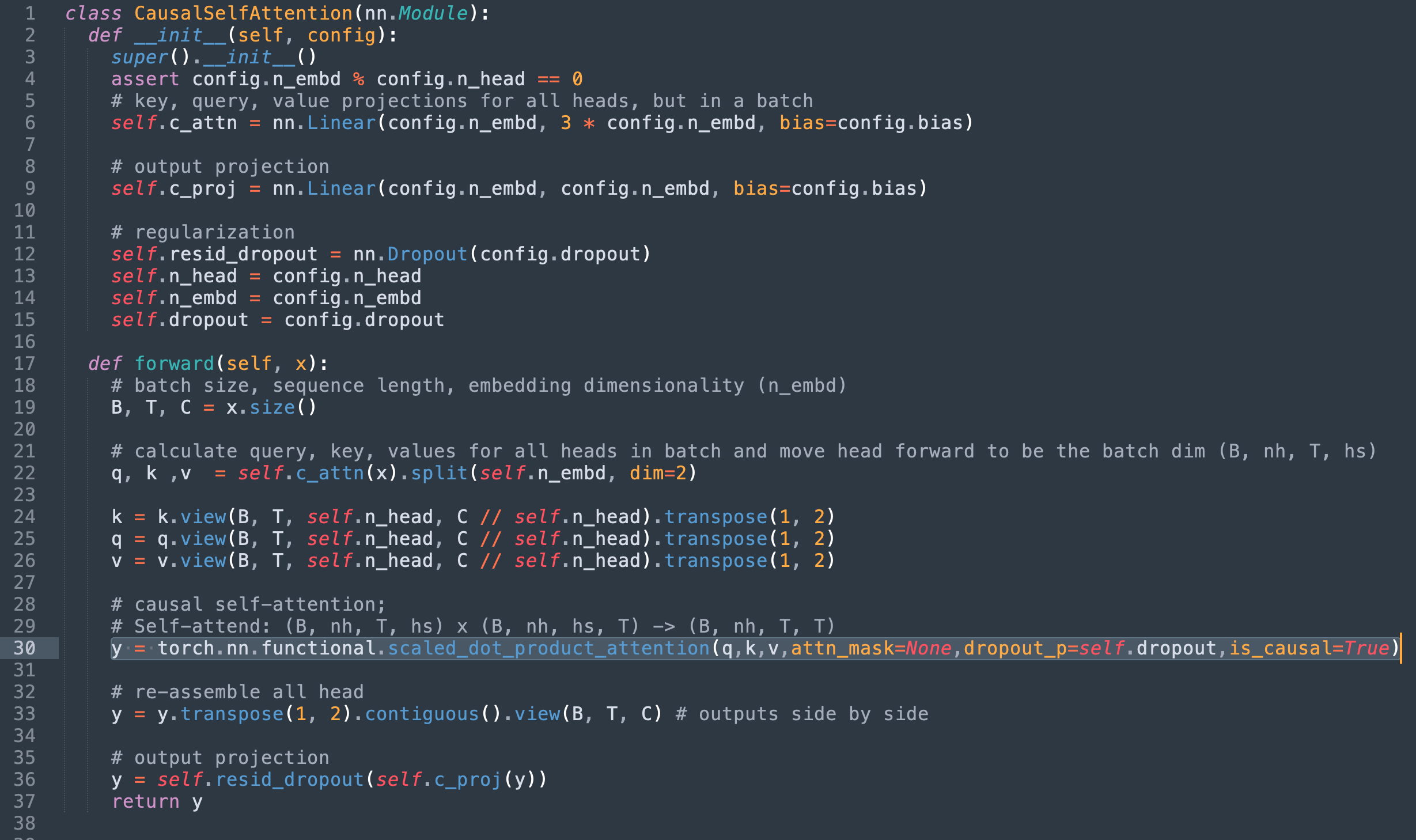
或者,原始掩码可以传递给 attn_mask 字段,但由于上述内核限制,这将限制实现仅支持通用 sdpa_math 内核。
第 3 步(奖励):通过填充实现更快的矩阵乘法
除了 SDPA 带来的性能改进之外,我们的分析还带来了一个不错的附带收获。用 Andrej 的话来说,“到目前为止,nanoGPT 最显著的优化(约 25% 的速度提升)仅仅是将词汇量从 50257 增加到 50304(最近的 64 倍数)。”

词汇量决定了 GPT 输出层中矩阵乘法的维度,这些维度是如此之大,以至于它们占据了整个训练循环的 大部分 时间!我们发现它们的性能显著低于 A100 GPU 上可达到的峰值吞吐量,并从 NVIDIA 的矩阵乘法文档 中猜测 64 元素对齐会产生更好的结果。实际上,填充这些矩阵乘法实现了近 3 倍的加速!根本原因是未对齐的内存访问显著降低了效率。更深入的分析可以在 此 Twitter 帖子 中找到。
通过这项优化,我们能够将训练时间从每批次约 113 毫秒(使用 Flash Attention)进一步缩短至约 87 毫秒。
结果
下图展示了使用 PyTorch 自定义内核获得的性能。以下是具体数据:
- 基线 (nanoGPT 实现): 约 143 毫秒
- sdpa_math (通用): 约 134 毫秒 (快 6.71%)
mem_efficient内核: 约 119 毫秒 (快 20.16%)flash_attention内核: 约 113 毫秒 (快 26.54%)- flash_attention + 填充词汇: 约 87 毫秒 (快 64.37%)
所有代码均在配备 8 个 NVIDIA Corporation A100 服务器(80 GB HBM [A100 SXM4 80GB])上运行,为本次实验,dropout 设置为 0。
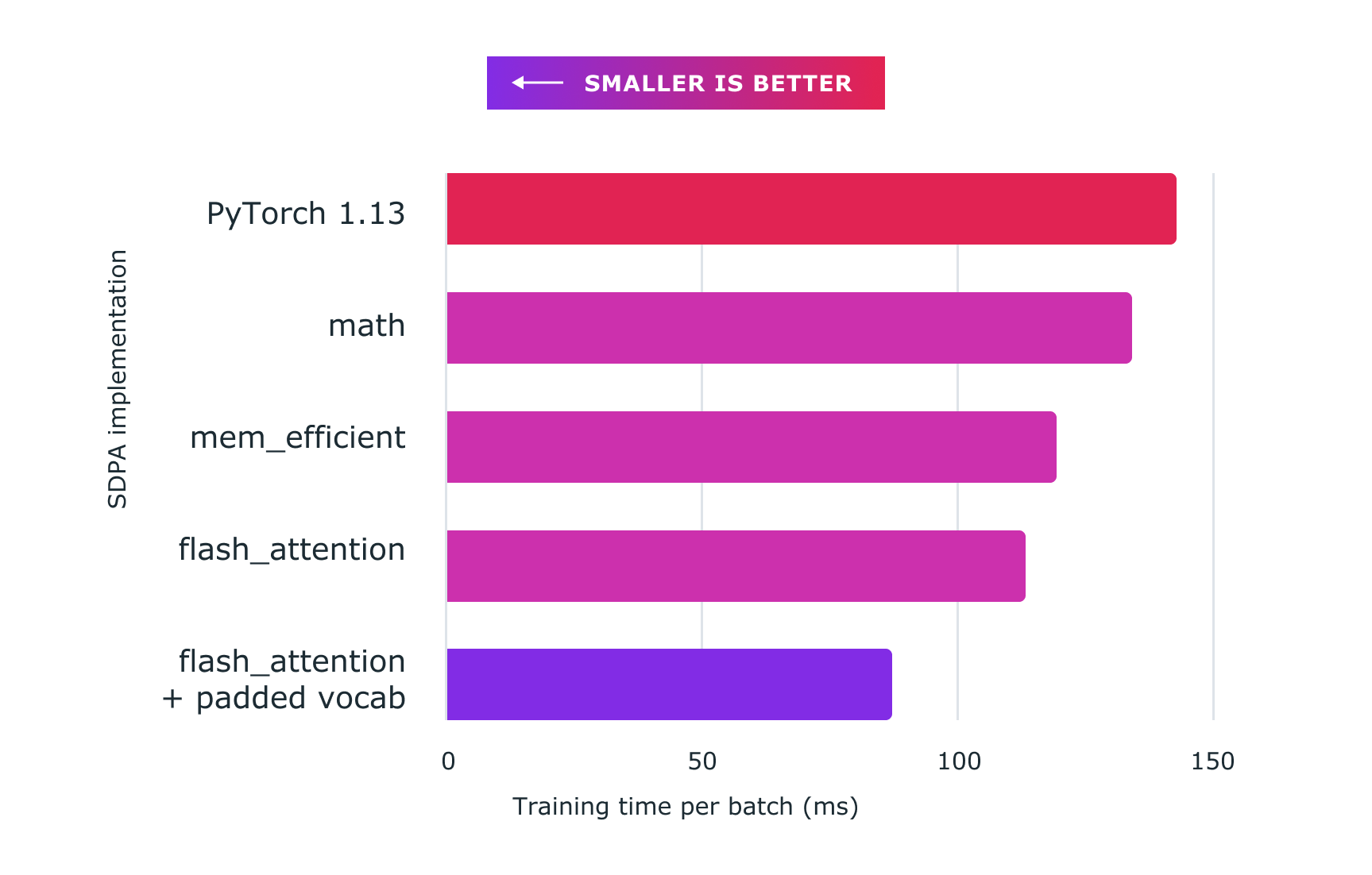
图 2:使用带自定义内核的缩放点积注意力和 torch.compile 可显著加速大型语言模型(如此处所示的 nanoGPT)的训练。
增强数值模型稳定性
除了速度更快之外,PyTorch 的实现还通过避免在许多执行场景中丢失精度,从而提高了数值稳定性。这里有一个很好的解释 here,但本质上,PyTorch 的实现在乘法 之前 对 Query 和 Key 矩阵进行缩放,这被认为更稳定并避免了精度损失。由于 SDPA 融合的自定义内核架构,这种缩放不会在注意力结果的计算中引入额外的开销。相比之下,由单独计算组件实现的方案将需要额外的预缩放成本。有关更多解释,请参见附录 A。
改进的内存消耗
使用 torch SDPA 内核的另一个巨大优势是减少了内存占用,这允许使用更大的批次大小。下表比较了 Flash Attention 和因果注意力基线实现在一小时训练后的最佳验证损失。可以看出,使用基线因果注意力实现(在 8 个 NVIDIA Corporation A100 服务器上,配备 80 GB HBM)可达到的最大批次大小为 24,显著小于使用 Flash Attention 达到的最大批次大小 39。
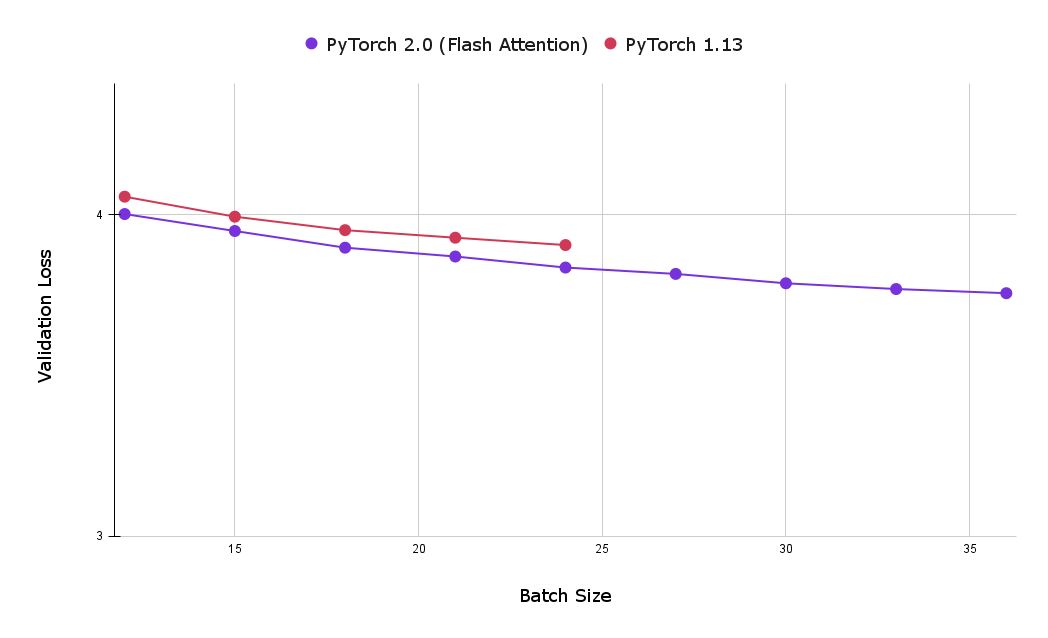
图 3:使用 Flash Attention 可以使用更大的批次大小,让用户在训练一小时后获得更低的验证损失(越小越好)。
结论
加速 PyTorch 2 Transformer 旨在使最先进的 Transformer 模型的训练和生产部署更具成本效益,并与 PyTorch 2.0 模型 JIT 编译集成。新引入的 PyTorch SDPA 运算符为训练 Transformer 模型提供了改进的性能,对于昂贵的大型语言模型训练尤其有价值。在这篇文章中,我们展示了在示例 nanoGPT 模型上的一系列优化,包括:
- 与基线相比,在批次大小不变的情况下,训练速度提升超过 26%
- 通过填充词汇量实现了额外的加速,使总优化量比基线提高了约 64%
- 额外的数值稳定性
附录 A:分析注意力数值稳定性
在本节中,我们将更深入地解释通过预缩放 SDPA 输入向量所获得的增强数值稳定性。以下是 nanoGPT SDPA 数学实现的简化版本。这里需要注意的重要一点是,查询在未经缩放的情况下进行矩阵乘法。
# nanoGPT implementation of SDPA
# notice q (our query vector) is not scaled !
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
# Dropout is set to 0, so we can safely ignore this line in the implementation# att = self.attn_dropout(att)
y_nanogpt = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
以下是 torch 的 scaled_dot_product_attention 中等效的数学实现。
# PyTorch implementation of SDPA
embed_size = q.size(-1)
scaling_factor = math.sqrt(math.sqrt(embed_size))
q = q / scaling_factor # notice q _is_ scaled here !
# same as above, but with scaling factor
att = q @ (k.transpose(-2, -1) / scaling_factor)
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att0, dim=-1)
# Dropout is set to 0, so we can safely ignore this line in the implementation# att = self.attn_dropout(att)
y_scale_before = att @ v
理论上这两种方法应该等价,但我们的实验表明,在实践中我们从每种方法中得到了不同的结果。
使用上述方法,我们验证了 y_scale_before 与使用 scaled_dot_product_attention 方法的预期输出一致,而 y_nanogpt 则不一致。
torch.allclose 方法用于测试等效性。具体来说,我们证明了
y_sdpa = torch.nn.functional._scaled_dot_product_attention(
q,
k,
v,
attn_mask=self.bias[:,:,:T,:T] != 0,
dropout_p=0.0,
need_attn_weights=False,
is_causal=False,
)
torch.allclose(y_sdpa, y_nanogpt) # False, indicating fp issues
torch.allclose(y_sdpa, y_scale_before) # True, as expected
附录 B:重现实验结果
寻求重现这些结果的研究人员应从 Andrej 的 nanoGPT 仓库中的以下提交开始—— b3c17c6c6a363357623f223aaa4a8b1e89d0a465。在测量每批次速度改进时,此提交被用作基线。对于包含填充词汇表优化的结果(这产生了批次速度最显著的改进),请使用以下提交—— 77e7e04c2657846ddf30c1ca2dd9f7cbb93ddeab。从任一检出,通过使用 torch.backends API 选择内核进行实验变得轻而易举。
可以通过上下文管理器选择所需的内核
with torch.backends.cuda.sdp_kernel (
enable_math = False,
enable_flash = False,
enable_mem_efficient = True
):
train(model)