这篇博文是关于如何使用纯原生 PyTorch 加速生成式 AI 模型的多系列博客的第三部分。我们很高兴能分享一系列新发布的 PyTorch 性能特性以及实际示例,以展示我们能将 PyTorch 原生性能推向多远。在第一部分中,我们展示了如何仅使用纯原生 PyTorch 将 Segment Anything 加速 8 倍以上。在第二部分中,我们展示了如何仅使用原生 PyTorch 优化将 Llama-7B 加速近 10 倍。在本篇博客中,我们将重点关注将文本到图像扩散模型加速多达 3 倍。
我们将利用一系列优化,包括:
- 使用 bfloat16 精度运行
- scaled_dot_product_attention (SPDA)
- torch.compile
- 组合用于注意力计算的 q、k、v 投影
- 动态 int8 量化
我们将主要关注 Stable Diffusion XL (SDXL),展示 3 倍的延迟改进。这些技术都是 PyTorch 原生的,这意味着您无需依赖任何第三方库或任何 C++ 代码即可利用它们。
使用 🤗Diffusers 库启用这些优化只需几行代码。如果您已经感到兴奋并迫不及待地想查看代码,请在此处查看附带的仓库:https://github.com/huggingface/diffusion-fast。
(所讨论的技术并非 SDXL 特有,也可用于加速其他文本到图像扩散系统,如下文所示。)
下面是一些关于类似主题的博客文章:
设置
我们将使用 🤗Diffusers 库演示优化及其各自的加速增益。除此之外,我们还将使用以下 PyTorch 原生库和环境:
- Torch nightly(受益于最高效注意力的最快内核;2.3.0.dev20231218+cu121)
- 🤗 PEFT(版本:0.7.1)
- torchao(提交 SHA:54bcd5a10d0abbe7b0c045052029257099f83fd9)
- CUDA 12.1
为了更简单的复现环境,您还可以参考此 Dockerfile。本文中提供的基准测试数据来自一块 400W 80GB A100 GPU(其时钟频率设置为最大容量)。
由于我们在此处使用 A100 GPU(Ampere 架构),我们可以指定 torch.set_float32_matmul_precision("high") 以受益于 TF32 精度格式。
使用降低的精度运行推理
在 Diffusers 中运行 SDXL 只需几行代码:
from diffusers import StableDiffusionXLPipeline
## Load the pipeline in full-precision and place its model components on CUDA.
pipe = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0").to("cuda")
## Run the attention ops without efficiency.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]
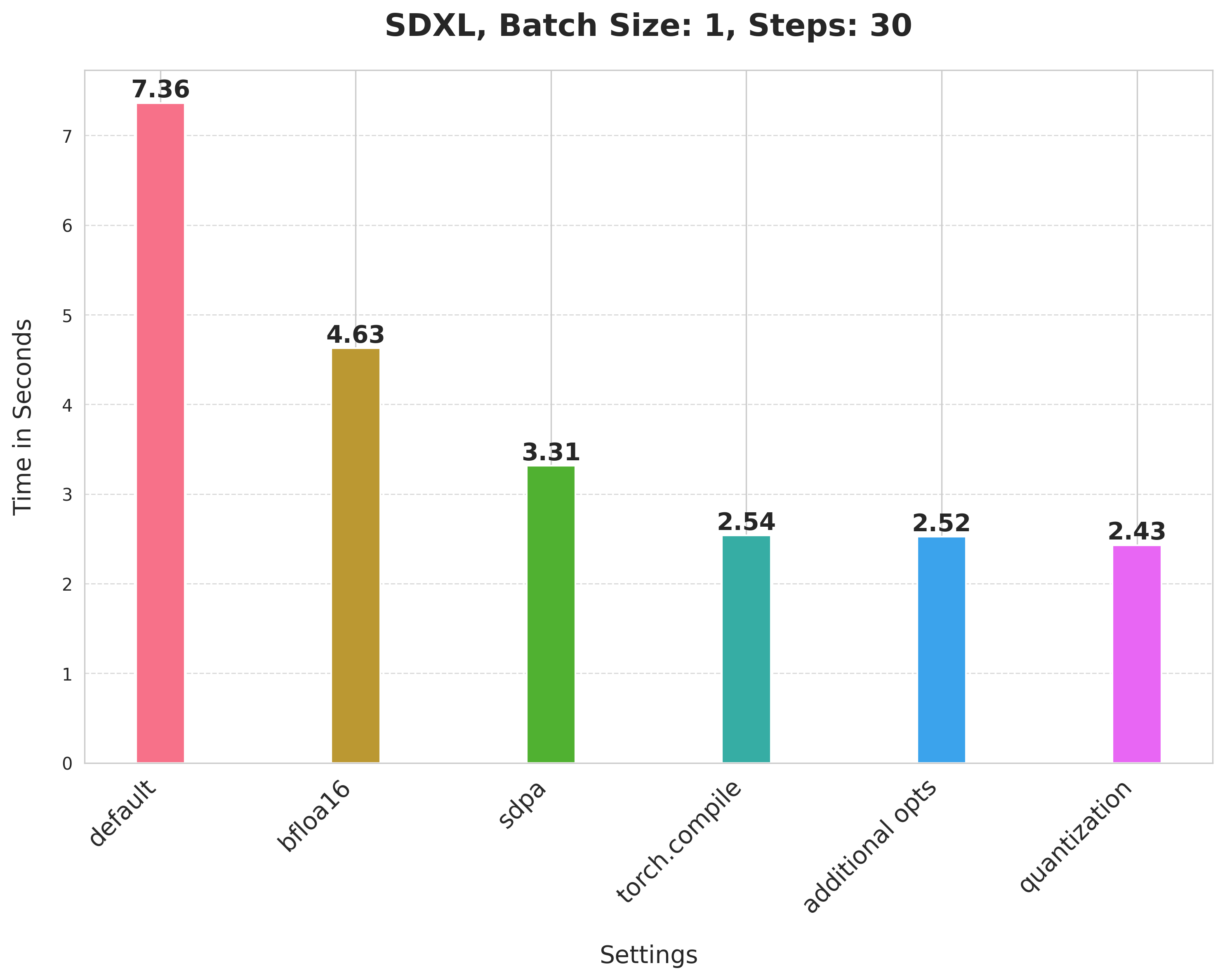
但这不是很实用,因为它需要 7.36 秒才能生成一张 30 步的图像。这是我们的基线,我们将尝试一步步优化。
在这里,我们以全精度运行流水线。我们可以通过使用降低的精度(例如 bfloat16)立即缩短推理时间。此外,现代 GPU 配备了专用的核心,用于运行受益于降低精度的加速计算。要在 bfloat16 精度下运行流水线的计算,我们只需在初始化流水线时指定数据类型:
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
## Run the attention ops without efficiency.
pipe.unet.set_default_attn_processor()
pipe.vae.set_default_attn_processor()
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]
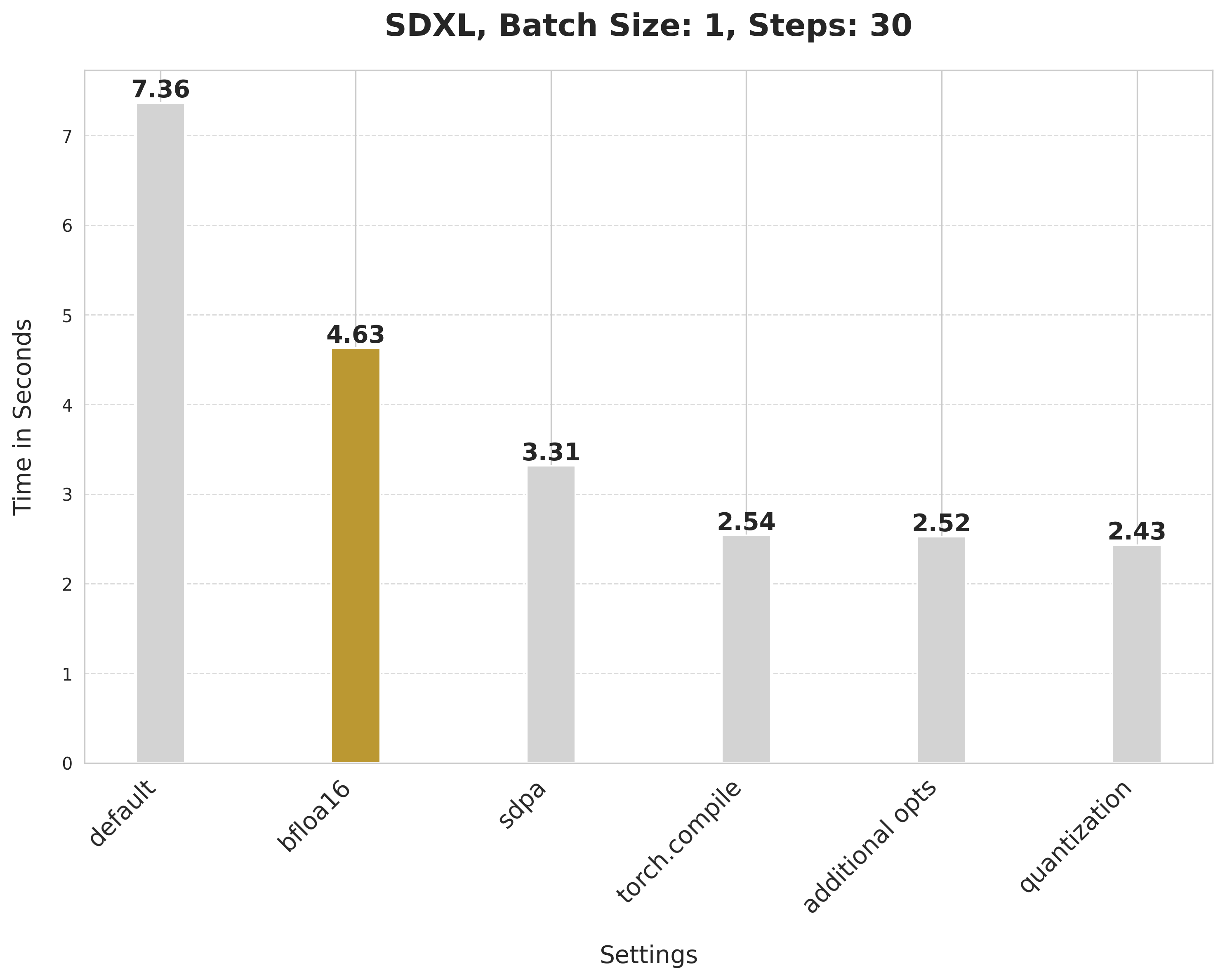
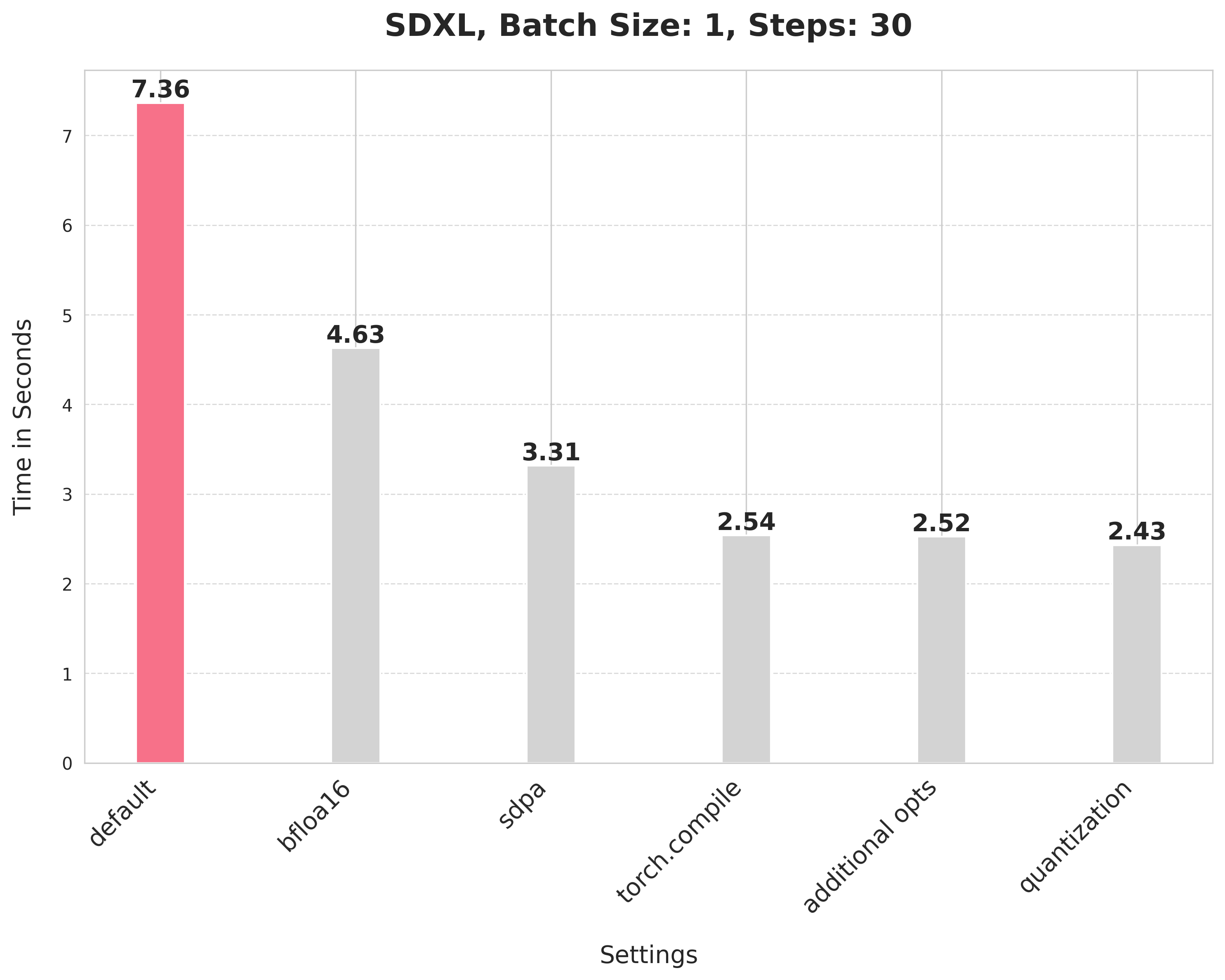
通过使用降低的精度,我们将推理延迟从 7.36 秒缩短到 4.63 秒。
关于使用 bfloat16 的一些注意事项:
- 使用降低的数值精度(如 float16、bfloat16)运行推理不会影响生成质量,但会显著改善延迟。
- 与 float16 相比,使用 bfloat16 数值精度的优势取决于硬件。现代 GPU 倾向于支持 bfloat16。
- 此外,在我们的实验中,我们发现 bfloat16 在与量化一起使用时比 float16 更具弹性。
(我们后来在 float16 中运行了实验,发现最新版本的 torchao 不会因 float16 引起数值问题。)
使用 SDPA 执行注意力计算
默认情况下,Diffusers 在使用 PyTorch 2 时使用 scaled_dot_product_attention (SDPA) 执行注意力相关计算。SDPA 提供更快、更高效的内核来运行密集型注意力相关操作。要运行 SDPA 流水线,我们只需不设置任何注意力处理器,如下所示:
from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
image = pipe(prompt, num_inference_steps=30).images[0]
SDPA 带来了从 4.63 秒到 3.31 秒的显著提升。
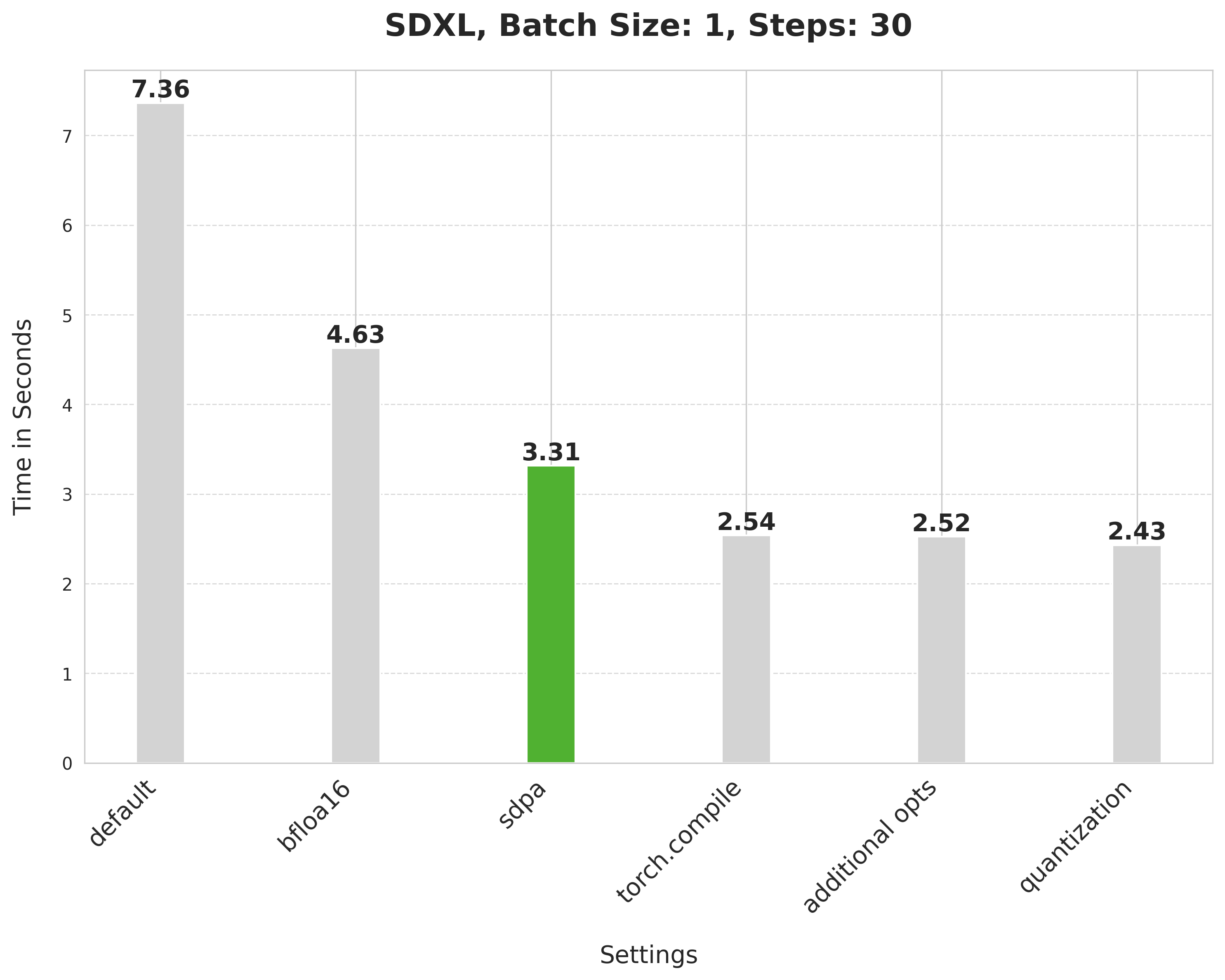
编译 UNet 和 VAE
我们可以通过使用 torch.compile 要求 PyTorch 执行一些低级优化(例如运算符融合和使用 CUDA 图启动更快的内核)。对于 StableDiffusionXLPipeline,我们编译去噪器 (UNet) 和 VAE:
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
).to("cuda")
## Compile the UNet and VAE.
pipe.unet = torch.compile(pipe.unet, mode="max-autotune", fullgraph=True)
pipe.vae.decode = torch.compile(pipe.vae.decode, mode="max-autotune", fullgraph=True)
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
## First call to `pipe` will be slow, subsequent ones will be faster.
image = pipe(prompt, num_inference_steps=30).images[0]
使用 SDPA 注意力并编译 UNet 和 VAE 将延迟从 3.31 秒缩短到 2.54 秒。
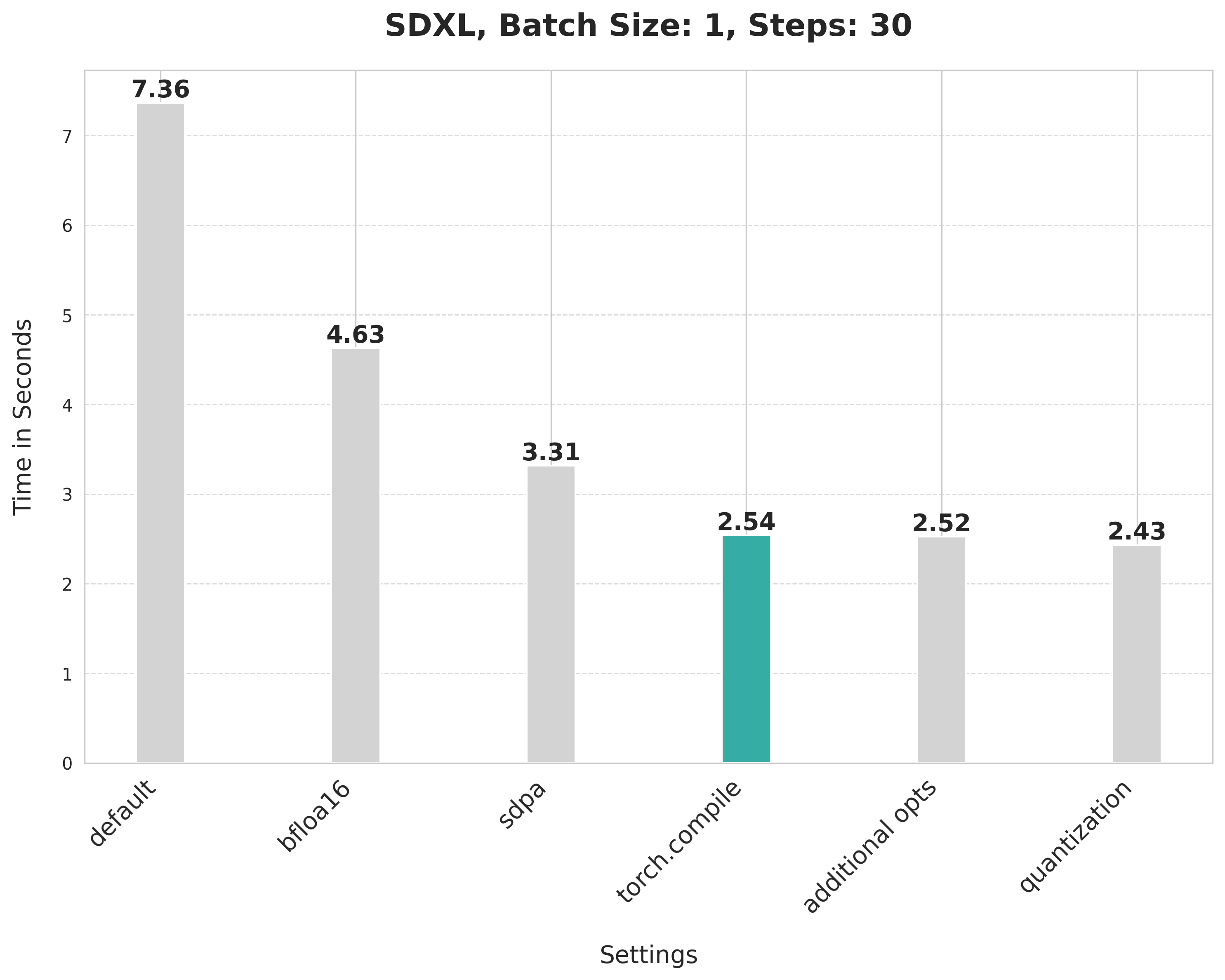
关于 torch.compile 的注意事项
torch.compile 提供不同的后端和模式。由于我们旨在实现最大推理速度,我们选择使用“max-autotune”的 inductor 后端。“max-autotune”使用 CUDA 图并专门针对延迟优化编译图。使用 CUDA 图大大减少了启动 GPU 操作的开销。它通过一种机制,通过单个 CPU 操作启动多个 GPU 操作来节省时间。
将 fullgraph 指定为 True 可确保底层模型中没有图中断,从而确保 torch.compile 的最大潜力。在我们的例子中,以下编译器标志也需要明确设置:
torch._inductor.config.conv_1x1_as_mm = True
torch._inductor.config.coordinate_descent_tuning = True
torch._inductor.config.epilogue_fusion = False
torch._inductor.config.coordinate_descent_check_all_directions = True
有关编译器标志的完整列表,请参阅此文件。
我们还在编译 UNet 和 VAE 时将其内存布局更改为“channels_last”,以确保最大速度:
pipe.unet.to(memory_format=torch.channels_last)
pipe.vae.to(memory_format=torch.channels_last)
在下一节中,我们将展示如何进一步提高延迟。
其他优化
torch.compile 期间无图中断
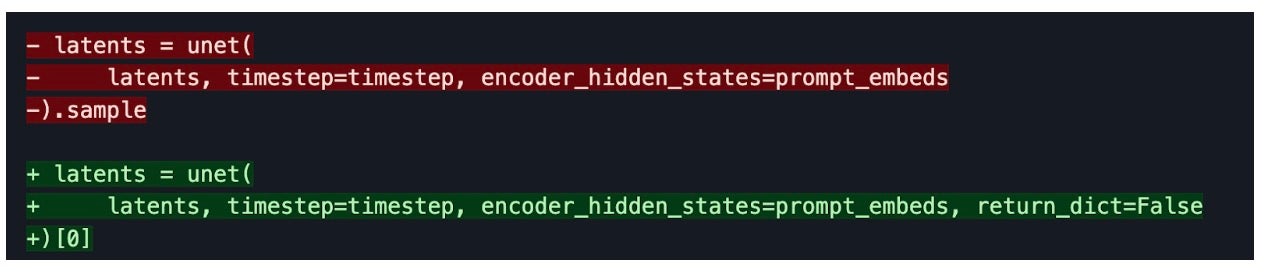
确保底层模型/方法可以完全编译对于性能至关重要(torch.compile 和 fullgraph=True)。这意味着没有图中断。我们通过改变访问返回变量的方式对 UNet 和 VAE 实现了这一点。考虑以下示例:
编译后消除 GPU 同步
在迭代逆扩散过程中,我们在去噪器预测噪声较小的潜在嵌入后,每次都会在调度器上调用 step()。在 step() 内部,sigmas 变量被索引。如果 sigmas 数组放置在 GPU 上,索引会导致 CPU 和 GPU 之间的通信同步。这会导致延迟,当去噪器已经编译时,这种情况会更加明显。
但是,如果 sigmas 数组始终保留在 CPU 上(请参阅此行),则不会发生此同步,从而提高了延迟。通常,任何 CPU <-> GPU 通信同步都应该没有或保持在最低限度,因为它会影响推理延迟。
使用组合投影进行注意力操作
SDXL 中使用的 UNet 和 VAE 都使用了类似 Transformer 的块。一个 Transformer 块由注意力块和前馈块组成。
在注意力块中,输入使用三个不同的投影矩阵——Q、K 和 V——投影到三个子空间中。在朴素实现中,这些投影是单独对输入执行的。但是我们可以水平组合投影矩阵成一个矩阵,并一次性执行投影。这增加了输入投影的矩阵乘法的大小,并提高了量化的影响(接下来讨论)。
在 Diffusers 中启用这种计算只需一行代码:
pipe.fuse_qkv_projections()
这将使 UNet 和 VAE 的注意力操作都利用组合投影。对于交叉注意力层,我们只组合键和值矩阵。要了解更多信息,您可以参考官方文档此处。值得注意的是,我们在此处内部利用了 PyTorch 的 scaled_dot_product_attention。
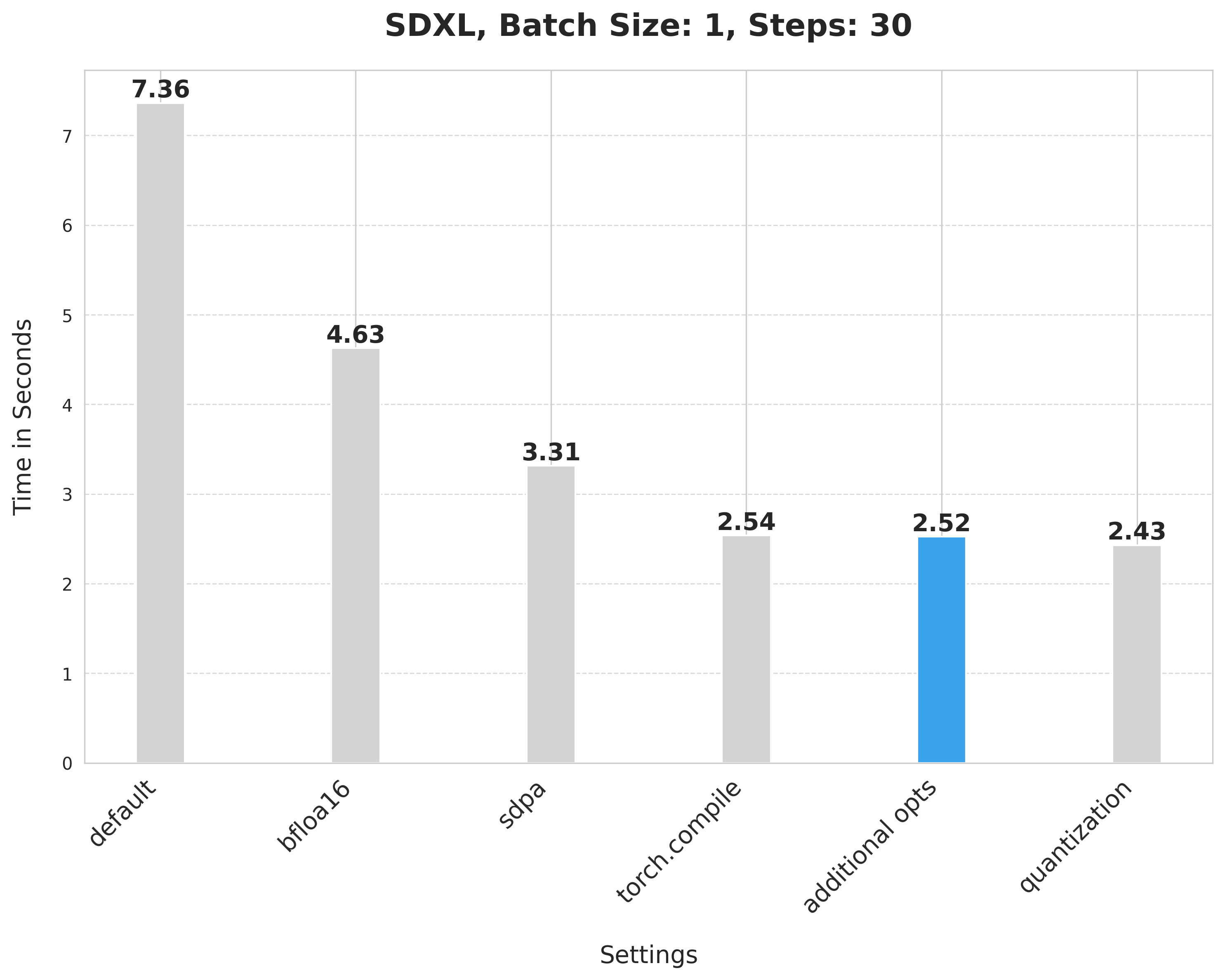
这些附加技术将推理延迟从 2.54 秒提高到 2.52 秒。
动态 int8 量化
我们选择性地对 UNet 和 VAE 应用动态 int8 量化。这是因为量化会增加模型的额外转换开销,希望通过更快的矩阵乘法(动态量化)来弥补。如果矩阵乘法太小,这些技术可能会降低性能。
通过实验,我们发现 UNet 和 VAE 中的某些线性层无法从动态 int8 量化中受益。您可以在此处查看过滤这些层的完整代码(下文称为 dynamic_quant_filter_fn)。
我们利用超轻量级纯 PyTorch 库 torchao 来使用其用户友好的 API 进行量化:
from torchao.quantization import apply_dynamic_quant
apply_dynamic_quant(pipe.unet, dynamic_quant_filter_fn)
apply_dynamic_quant(pipe.vae, dynamic_quant_filter_fn)
由于此量化支持仅限于线性层,我们还将合适的逐点卷积层转换为线性层,以最大限度地提高收益。在使用此选项时,我们还指定了以下编译器标志:
torch._inductor.config.force_fuse_int_mm_with_mul = True
torch._inductor.config.use_mixed_mm = True
为了防止量化引起的任何数值问题,我们以 bfloat16 格式运行所有内容。
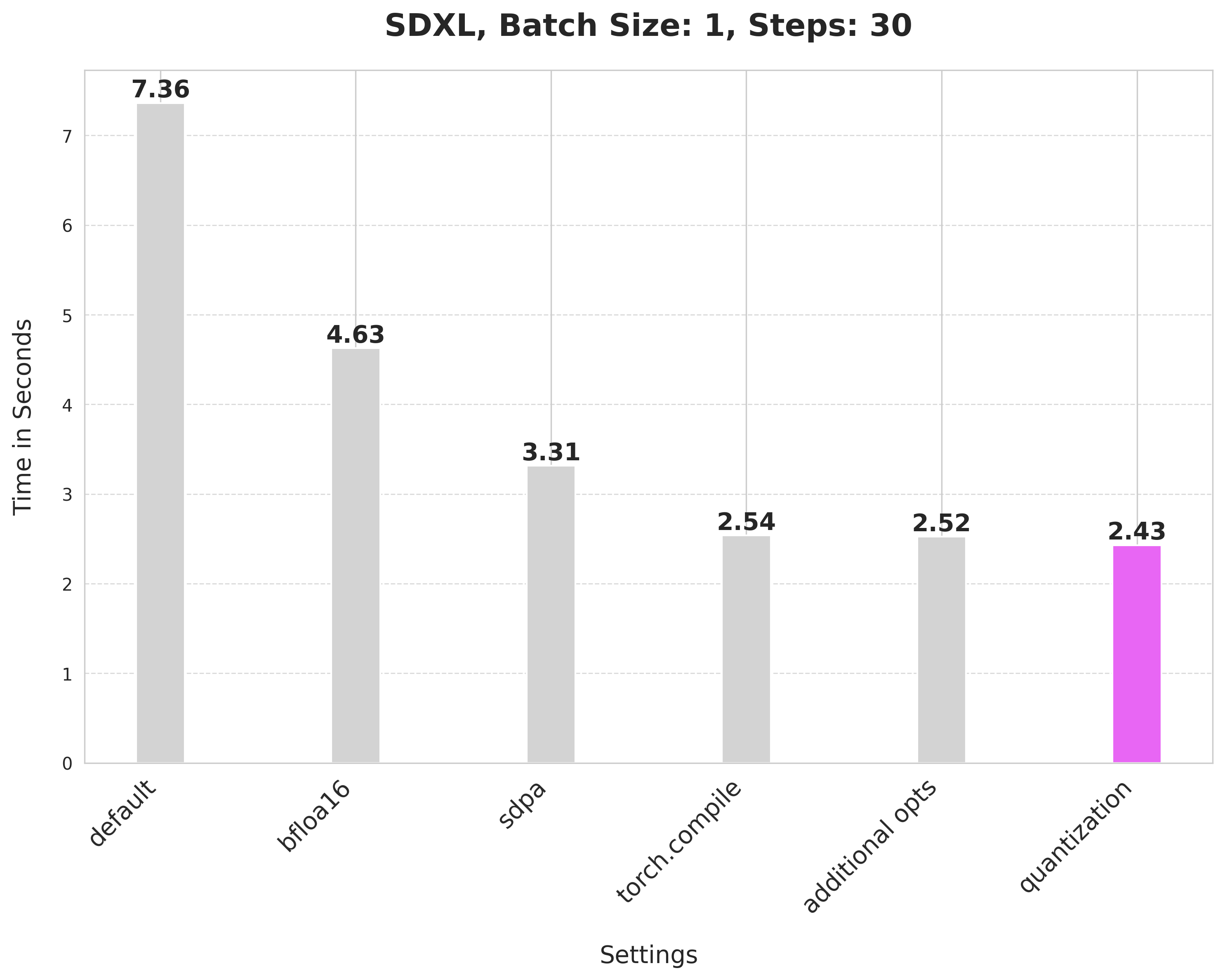
以这种方式应用量化将延迟从 2.52 秒提高到 2.43 秒。
资源
我们欢迎您查看以下代码库,以复现这些数字并将技术扩展到其他文本到图像扩散系统:
- diffusion-fast(提供所有代码以复现上述数字和图表的仓库)
- torchao 库
- Diffusers 库
- PEFT 库
其他链接
其他流水线的改进
我们将这些技术应用于其他流水线,以测试我们方法的通用性。以下是我们的发现:
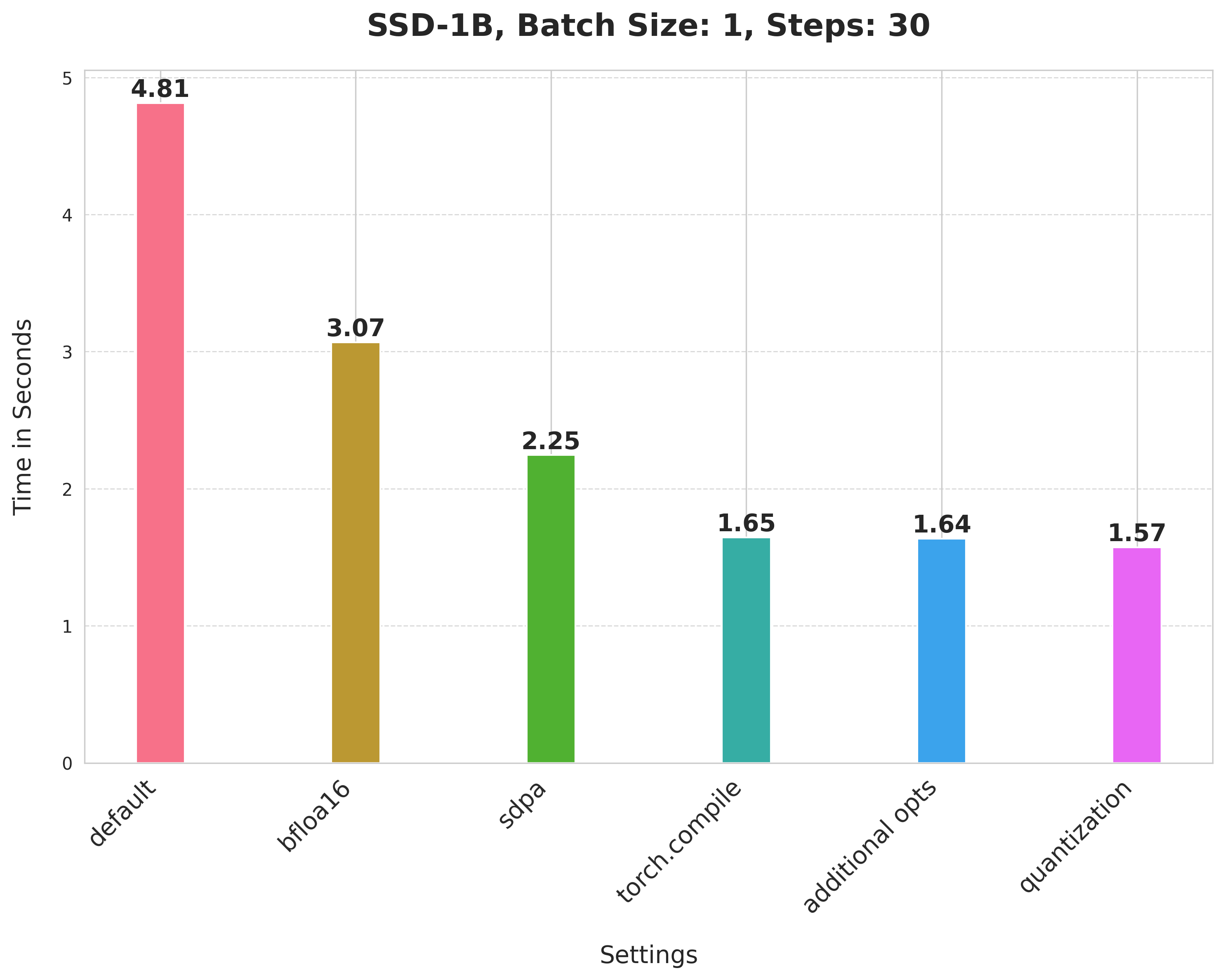
SSD-1B
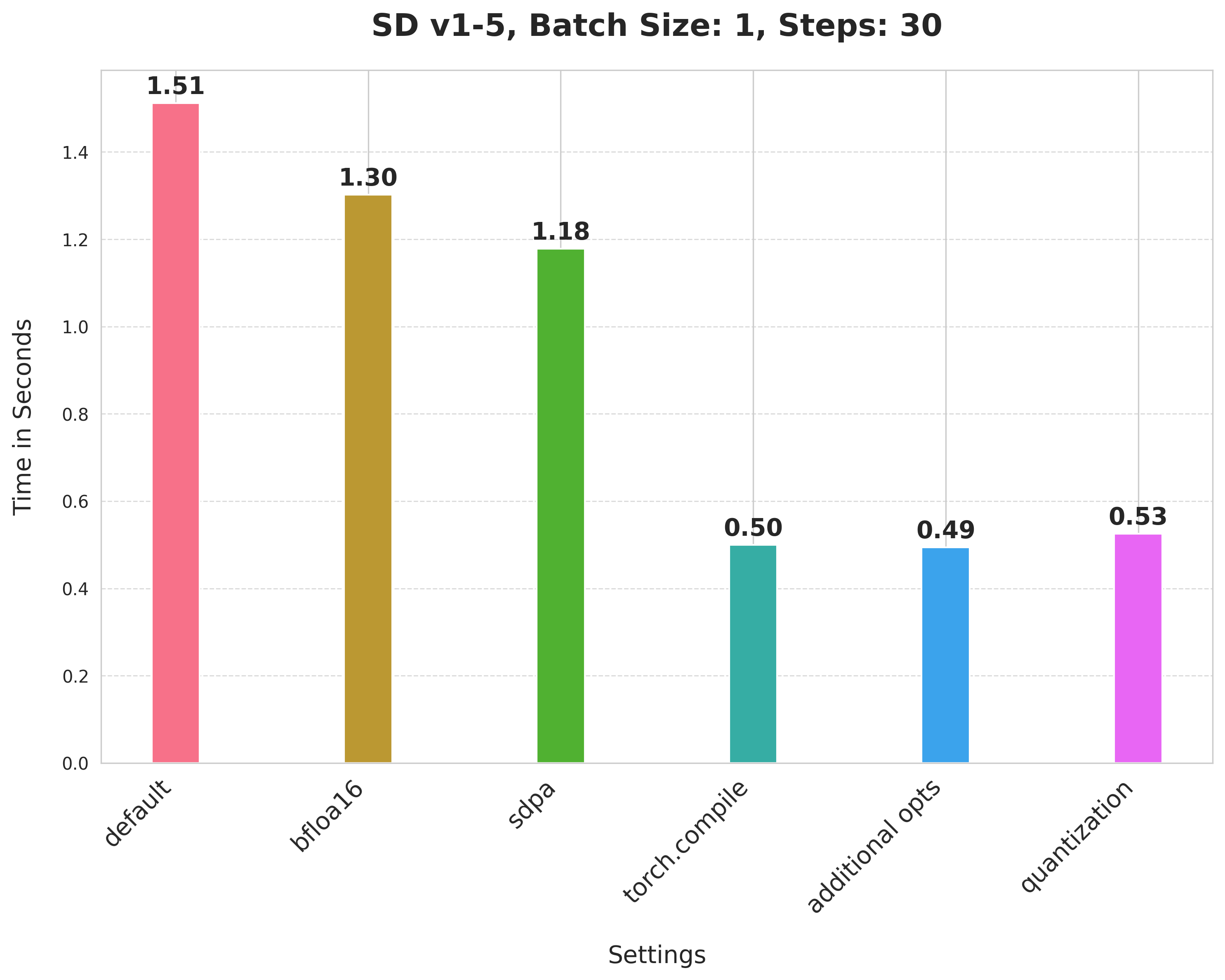
Stable Diffusion v1-5
PixArt-alpha/PixArt-XL-2-1024-MS
值得注意的是,PixArt-Alpha 使用基于 Transformer 的架构作为其逆扩散过程的去噪器,而不是 UNet。
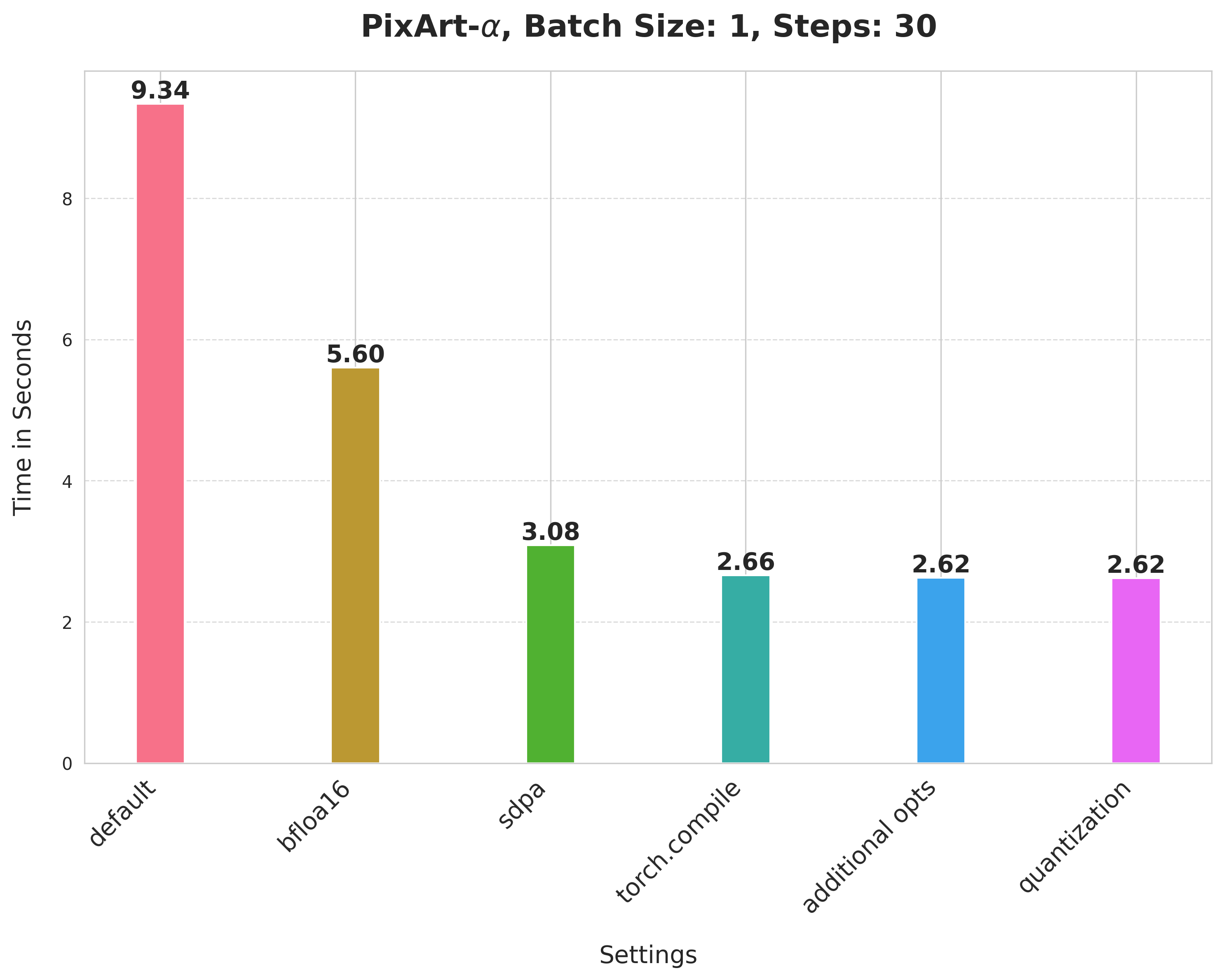
请注意,对于 Stable Diffusion v1-5 和 PixArt-Alpha,我们没有探索应用动态 int8 量化的最佳形状组合标准。通过更好的组合,可能会获得更好的数字。
总的来说,我们提出的方法在不降低生成质量的情况下,比基线提供了显著的加速。此外,我们认为这些方法应该补充社区中流行的其他优化方法(例如 DeepCache、Stable Fast 等)。
结论和后续步骤
在这篇文章中,我们提出了一系列简单而有效的技术,可以帮助提高纯 PyTorch 中文本到图像扩散模型的推理延迟。总结如下:
- 使用降低的精度执行计算
- 使用 scaled-dot product attention 高效运行注意力块
- 使用“max-autotune”进行 torch.compile 以提高延迟
- 组合不同的投影以计算注意力
- 动态 int8 量化
我们认为在如何将量化应用于文本到图像扩散系统方面还有很多值得探索的地方。我们没有详尽地探索 UNet 和 VAE 中哪些层倾向于从动态量化中受益。通过更好的量化目标层组合,可能还有进一步加速的机会。
除了以 bfloat16 运行之外,我们没有触及 SDXL 的文本编码器。优化它们也可能导致延迟的改进。
致谢
感谢 Ollin Boer Bohan,其 VAE 在整个基准测试过程中被使用,因为它在降低的数值精度下更稳定。
感谢 Hugging Face 的 Hugo Larcher 协助基础设施。