这篇博文是多系列博客的第二部分,重点介绍如何使用纯原生 PyTorch 加速生成式 AI 模型。我们很高兴能分享大量新发布的 PyTorch 性能功能,并提供实际示例,以展示我们能将 PyTorch 原生性能推向多远。在第一部分中,我们展示了如何仅使用纯原生 PyTorch 将Segment Anything 加速 8 倍以上。在本篇博客中,我们将专注于 LLM 优化。
在过去一年中,生成式 AI 用例的受欢迎程度爆炸式增长。文本生成是一个特别受欢迎的领域,在开源项目(如llama.cpp、vLLM 和MLC-LLM)中涌现出大量创新。
虽然这些项目性能强大,但它们通常会在易用性方面做出权衡,例如需要将模型转换为特定格式或构建和发布新的依赖项。这引出了一个问题:我们仅使用纯原生 PyTorch,能多快地运行 Transformer 推理?
正如我们在最近的PyTorch 开发者大会上宣布的那样,PyTorch 团队从头开始编写了一个 LLM,其速度比基线快近 10 倍,且没有精度损失,所有这些都使用了原生 PyTorch 优化。我们利用了广泛的优化,包括
- Torch.compile:用于 PyTorch 模型的编译器
- GPU 量化:通过降低精度操作来加速模型
- 推测解码:使用小型“草稿”模型预测大型“目标”模型的输出来加速 LLM
- 张量并行:通过在多个设备上运行模型来加速模型。
更好的是,我们可以在不到 1000 行原生 PyTorch 代码中完成。
如果这足以让您直接投入代码,请在https://github.com/pytorch-labs/gpt-fast查看!

注意:所有这些基准测试都将重点关注延迟(即批量大小=1)。除非另有说明,所有基准测试均在 A100-80GB 上运行,功耗限制为 330W。
起点 (25.5 tok/s)
让我们从一个极其基本和简单的实现开始。
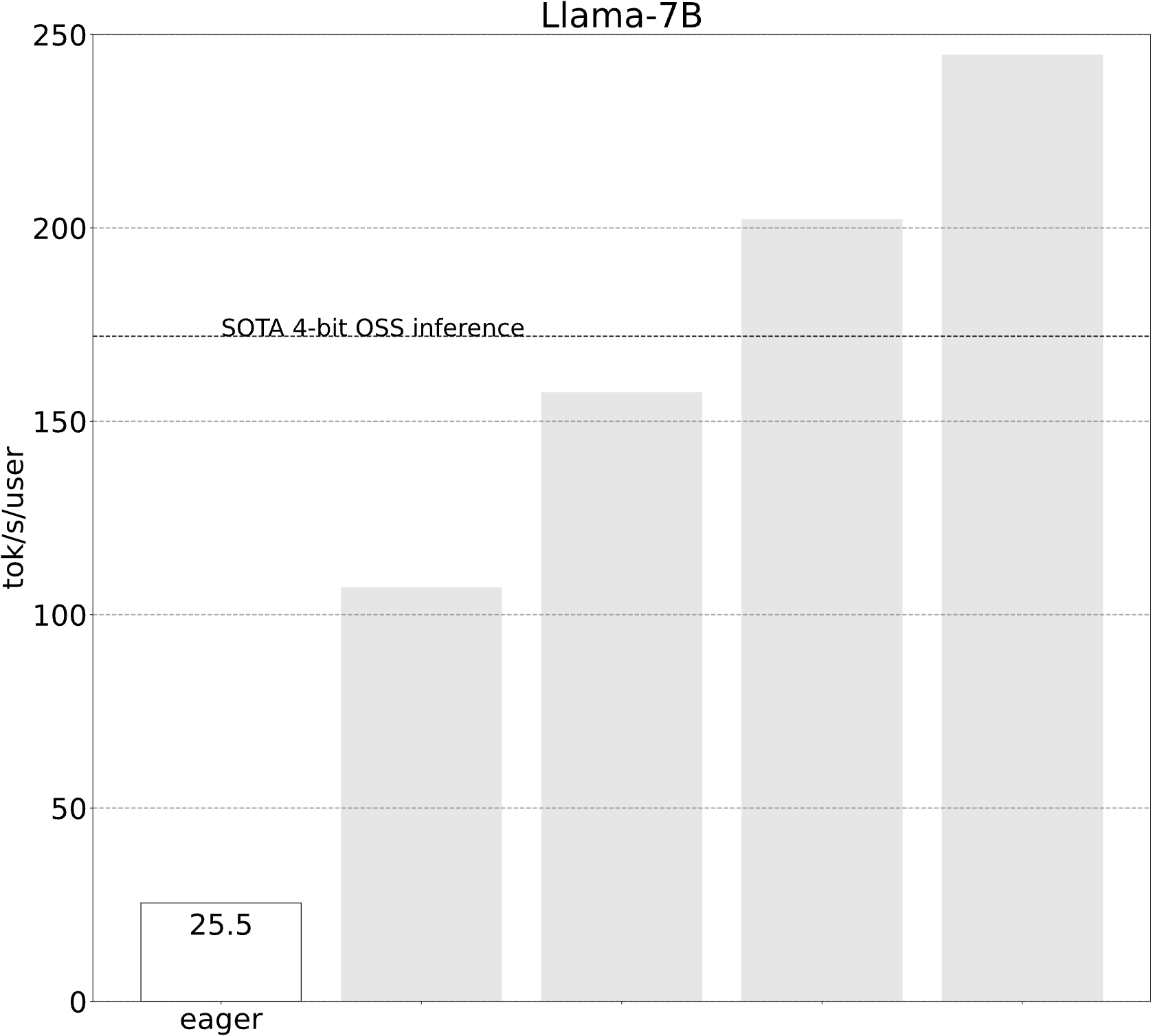
遗憾的是,这表现不佳。但为什么呢?查看追踪会揭示答案——它严重受到 CPU 开销的限制!这意味着我们的 CPU 无法足够快地告诉 GPU 该做什么,以致 GPU 无法充分利用。

想象一下 GPU 是一个拥有巨大计算能力的超级工厂。然后,想象一下 CPU 是一些信使,在 GPU 之间来回传递指令。请记住,在大型深度学习系统中,GPU 负责完成 100% 的工作!在这样的系统中,CPU 的唯一作用是告诉 GPU 它应该做什么工作。
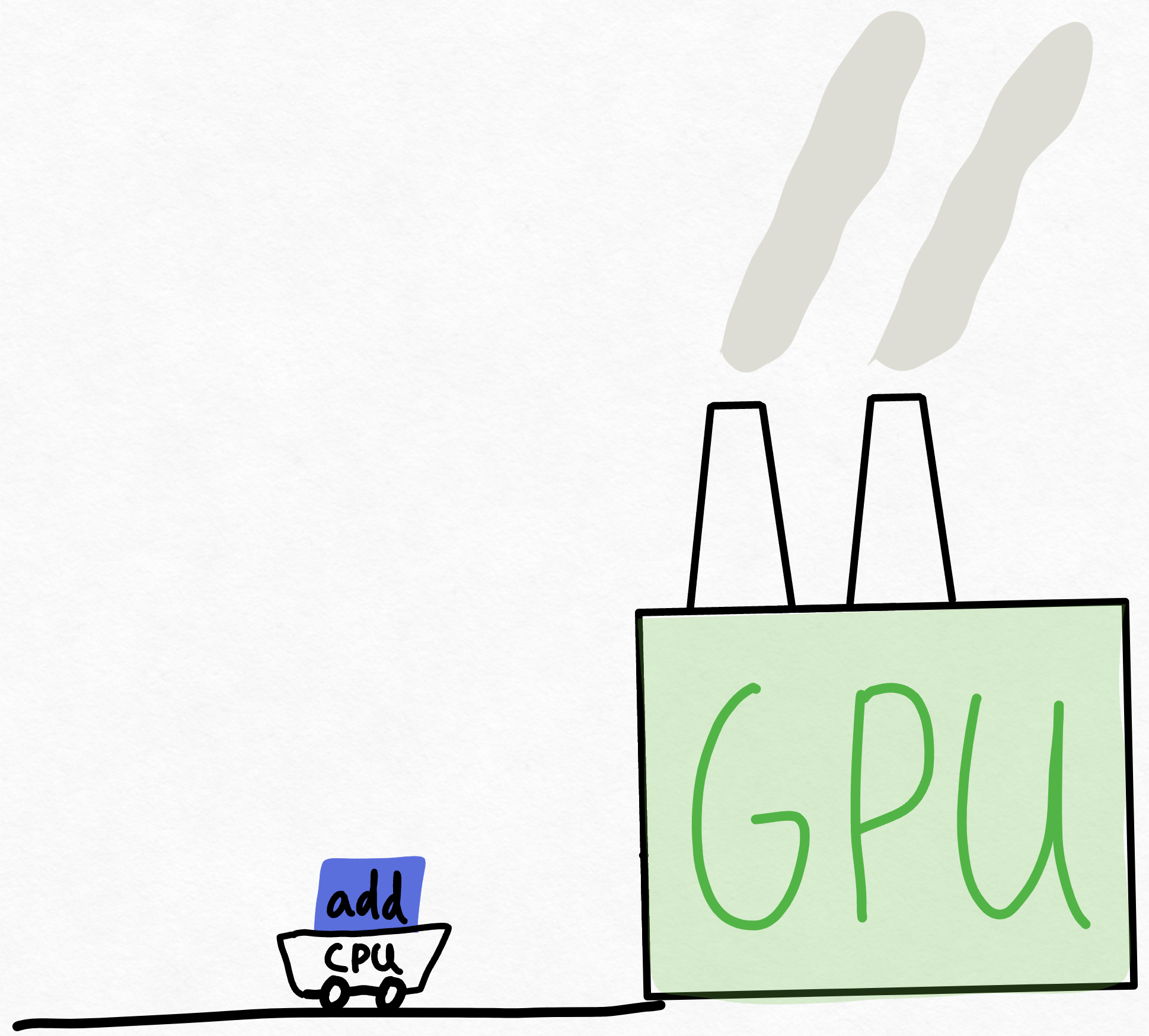
因此,CPU 跑过去告诉 GPU 执行一个“加法”,但是当 CPU 能够给 GPU 另一块工作时,GPU 早已完成了前一块工作。
尽管 GPU 需要执行数千次计算,而 CPU 只需进行协调工作,但这却出奇地常见!造成这种情况的原因有很多,从 CPU 可能正在运行一些单线程 Python 到如今 GPU 速度惊人。
无论原因如何,我们现在都处于 开销受限状态。那么,我们能做什么呢?一、我们可以用 C++ 重写我们的实现,甚至完全放弃框架并编写原始 CUDA。或者……我们可以一次性向 GPU 发送更多工作。
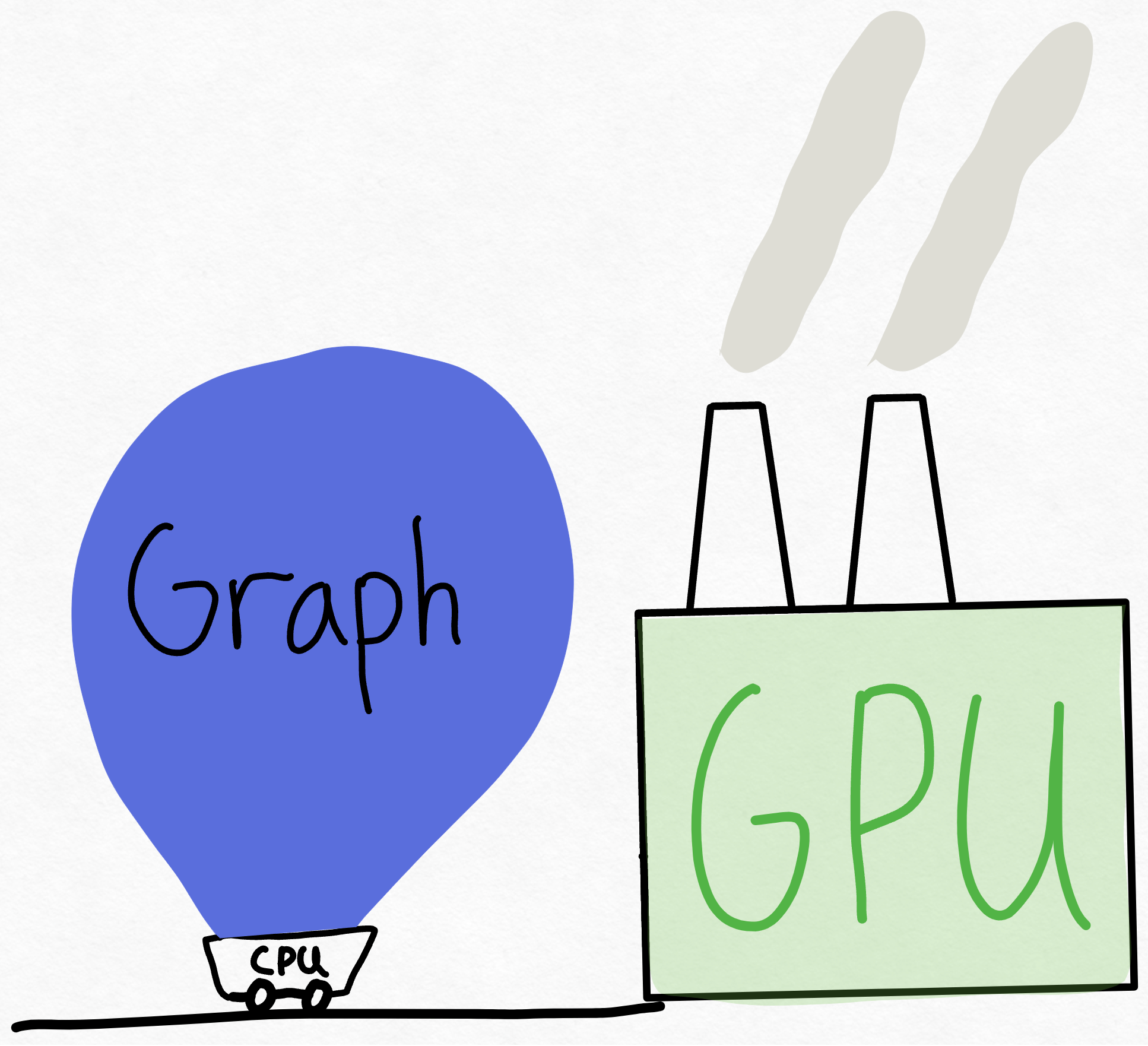
通过一次性发送大量工作,我们可以让 GPU 保持忙碌!尽管在训练期间,这可能只需增加批量大小即可实现,但在推理期间我们该怎么做呢?
进入 torch.compile。
第一步:通过 torch.compile 和静态 kv-cache 减少 CPU 开销 (107.0 tok/s)
Torch.compile 允许我们将更大的区域捕获到一个编译区域中,特别是在运行 `mode="reduce-overhead"` 时,它在减少 CPU 开销方面非常有效。在这里,我们还指定 `fullgraph=True`,这验证了模型中没有“图中断”(即 torch.compile 无法编译的部分)。换句话说,它确保 torch.compile 正在充分发挥其潜力。
要应用它,我们只需用它包装一个函数(或模块)即可。
torch.compile(decode_one_token, mode="reduce-overhead", fullgraph=True)
然而,这里有一些细微之处,使得人们很难通过将 torch.compile 应用于文本生成来获得显著的性能提升。
第一个障碍是 kv-cache。kv-cache 是一种推理时优化,它缓存为先前 token 计算的激活(有关更深入的解释,请参见此处)。然而,随着我们生成更多 token,kv-cache 的“逻辑长度”会增长。这带来两个问题。一是每次 cache 增长时重新分配(和复制!)kv-cache 都很昂贵。另一个是这种动态性使得减少开销更加困难,因为我们无法再利用 cudagraphs 等方法。
为了解决这个问题,我们使用了一个“静态”kv-cache,这意味着我们静态分配 kv-cache 的最大大小,然后在计算的注意力部分掩盖未使用的值。

第二个障碍是预填充阶段。Transformer 文本生成最好被视为一个两阶段过程:1. 预填充,其中处理整个提示,2. 解码,其中自回归地生成每个 token。
尽管一旦 kv-cache 变为静态,解码就可以完全静态化,但由于提示长度可变,预填充阶段仍然需要更多的动态性。因此,我们实际上需要使用不同的编译策略来编译这两个阶段。

虽然这些细节有些棘手,但实际实现一点也不难(请参见 gpt-fast)!性能提升是巨大的。
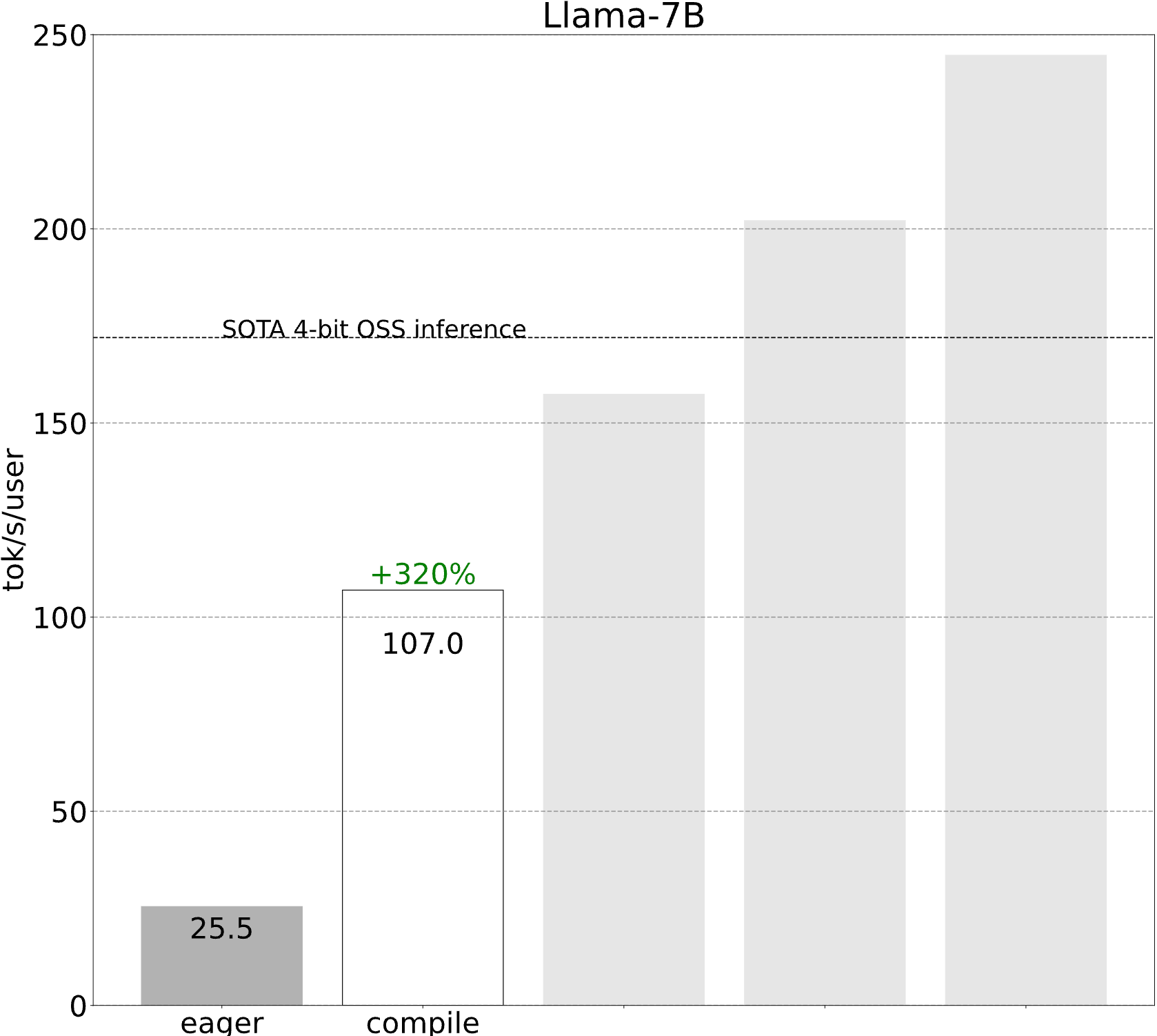
突然之间,我们的性能提高了 4 倍以上!当工作负载受开销限制时,这种性能提升通常很常见。
旁注:torch.compile 如何提供帮助?
值得仔细分析 torch.compile 究竟是如何提高性能的。有两个主要因素导致 torch.compile 的性能提升。
第一个因素,如上所述,是开销减少。Torch.compile 能够通过各种优化来减少开销,其中最有效的一种叫做CUDAGraphs。虽然 torch.compile 在设置“reduce-overhead”时会自动为您应用此功能,从而省去了您手动在没有 torch.compile 的情况下进行此操作所需的额外工作和代码。
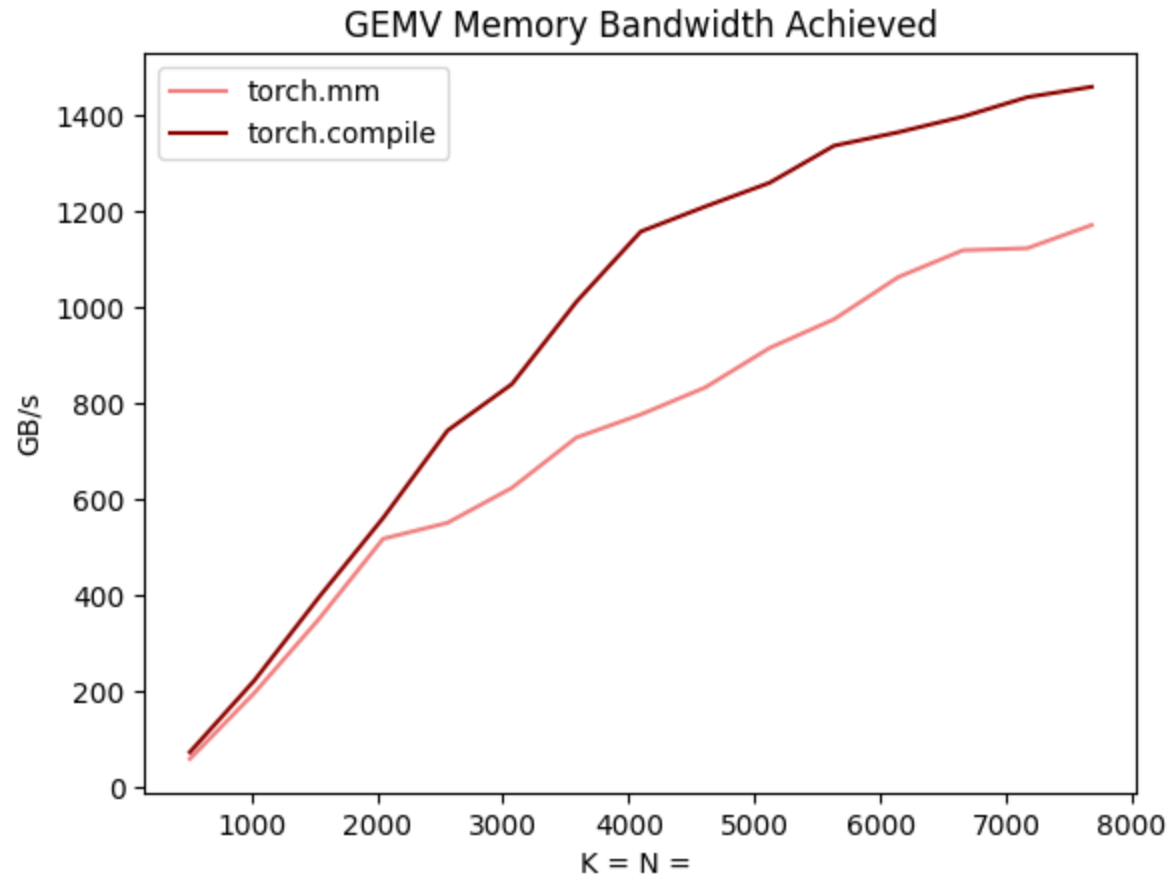
然而,第二个因素是 torch.compile 只是生成了更快的内核。在上面的解码基准测试中,torch.compile 实际上从头开始生成了每一个内核,包括矩阵乘法和注意力!更酷的是,这些内核实际上比内置的替代方案(CuBLAS 和 FlashAttention2)更快!
这对于许多人来说可能听起来难以置信,考虑到编写高效的矩阵乘法/注意力内核是多么困难,以及在 CuBLAS 和 FlashAttention 上投入了多少人力。然而,这里的关键在于,Transformer 解码具有非常不寻常的计算特性。特别是,由于 KV-cache,对于 BS=1,Transformer 中的每一次矩阵乘法实际上都是矩阵向量乘法。
这意味着计算完全受 内存带宽限制,因此,在编译器自动生成的范围内。事实上,当我们对照 CuBLAS 对 torch.compile 的矩阵向量乘法进行基准测试时,我们发现 torch.compile 的内核实际上要快得多!

步骤 2:通过 int8 仅权重量化缓解内存带宽瓶颈 (157.4 tok/s)
那么,既然我们已经看到应用 torch.compile 带来了巨大的加速,是否有可能做得更好呢?思考这个问题的一种方法是计算我们与理论峰值有多接近。在这种情况下,最大的瓶颈是将权重从 GPU 全局内存加载到寄存器的成本。换句话说,每次前向传播都需要我们“触摸”GPU 上的每个参数。那么,我们理论上能多快地“触摸”模型中的每个参数呢?
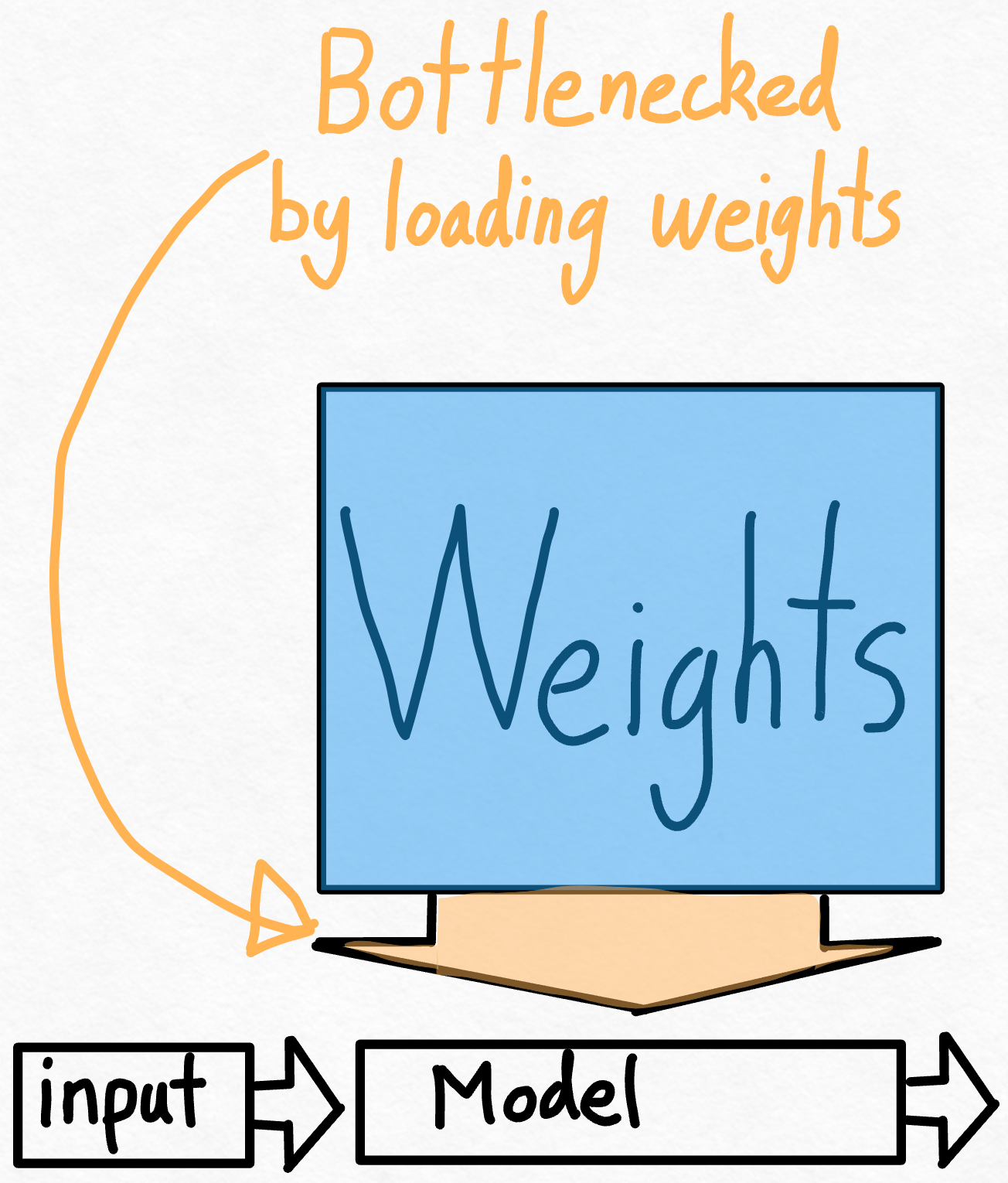
为了衡量这一点,我们可以使用 模型带宽利用率 (MBU)。 这衡量了我们在推理期间能够使用的内存带宽的百分比。
计算起来很简单。我们只需将模型的总大小(参数数量 * 每个参数的字节数)乘以我们每秒可以执行的推理次数。然后,我们将此结果除以 GPU 的峰值带宽即可得到 MBU。

例如,在上述案例中,我们有一个 7B 参数模型。每个参数以 fp16 存储(每个参数 2 字节),我们实现了 107 token/s。最后,我们的 A100-80GB 具有理论上 2 TB/s 的内存带宽。
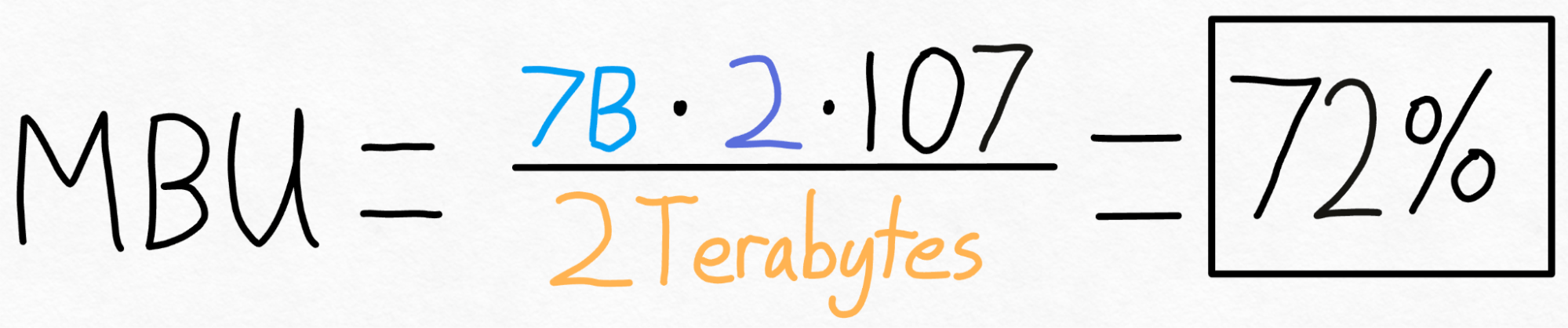
把所有这些加起来,我们得到 **72% MBU!** 这相当不错了,考虑到即使只是复制内存也很难突破 85%。
但是……这确实意味着我们已经非常接近理论极限了,而且我们显然受限于从内存加载权重。无论我们做什么——如果不以某种方式改变问题陈述,我们可能只能再挤出 10% 的性能。
让我们再看看上面的方程。我们无法真正改变模型中的参数数量。我们无法真正改变 GPU 的内存带宽(嗯,除非支付更多费用)。但是,我们 可以 改变每个参数的存储字节数!

因此,我们来到了下一个技术——int8 量化。这里的想法很简单。如果从内存加载权重是我们的主要瓶颈,为什么我们不把权重做得更小呢?
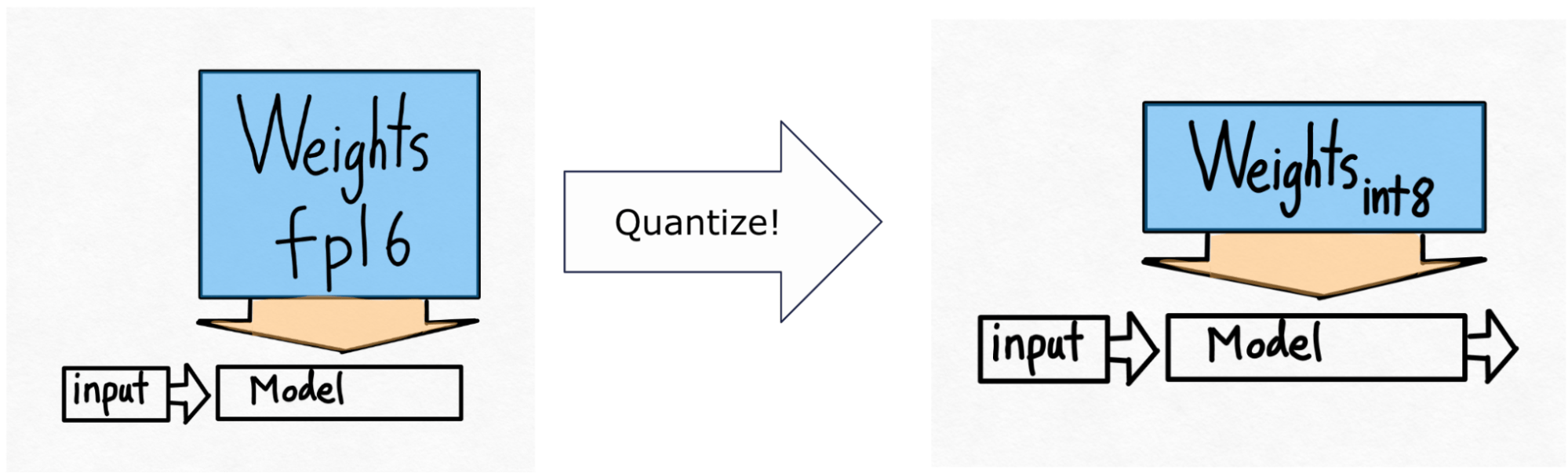
请注意,这 仅 对权重进行量化——计算本身仍然以 bf16 完成。这使得这种形式的量化易于应用,并且几乎不会导致精度下降。
此外,torch.compile 还可以轻松生成用于 int8 量化的高效代码。让我们再次看看上面的基准测试,这次包含了 int8 仅权重 量化。

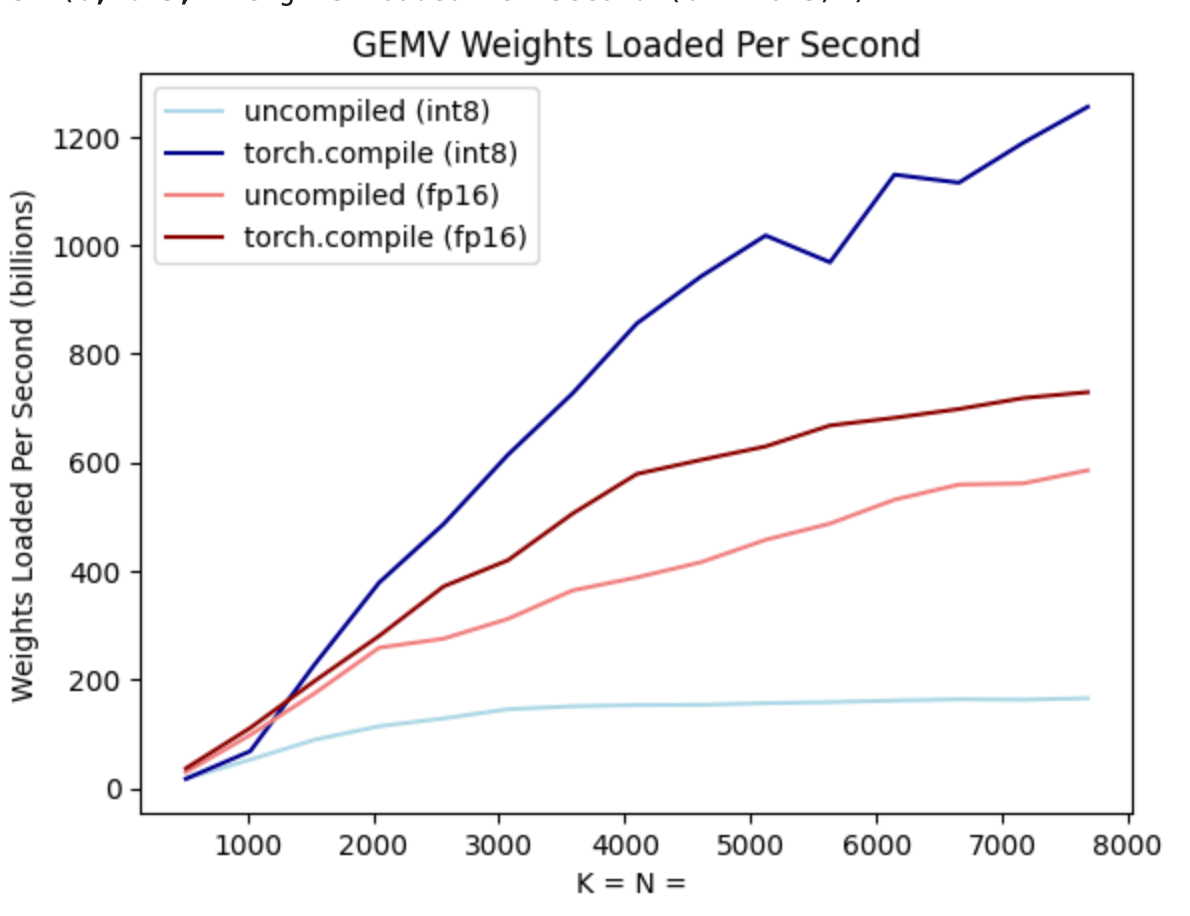
正如你从深蓝色线(torch.compile + int8)中看到的,使用 torch.compile + int8 仅权重 量化时,性能有了显著提升!此外,浅蓝色线(无 torch.compile + int8)实际上比 fp16 性能差得多!这是因为为了利用 int8 量化的性能优势,我们需要融合内核。这展示了 torch.compile 的一个优点——这些内核可以为用户自动生成!
将 int8 量化应用于我们的模型,我们看到了 50% 的性能提升,使我们达到 157.4 tokens/s!
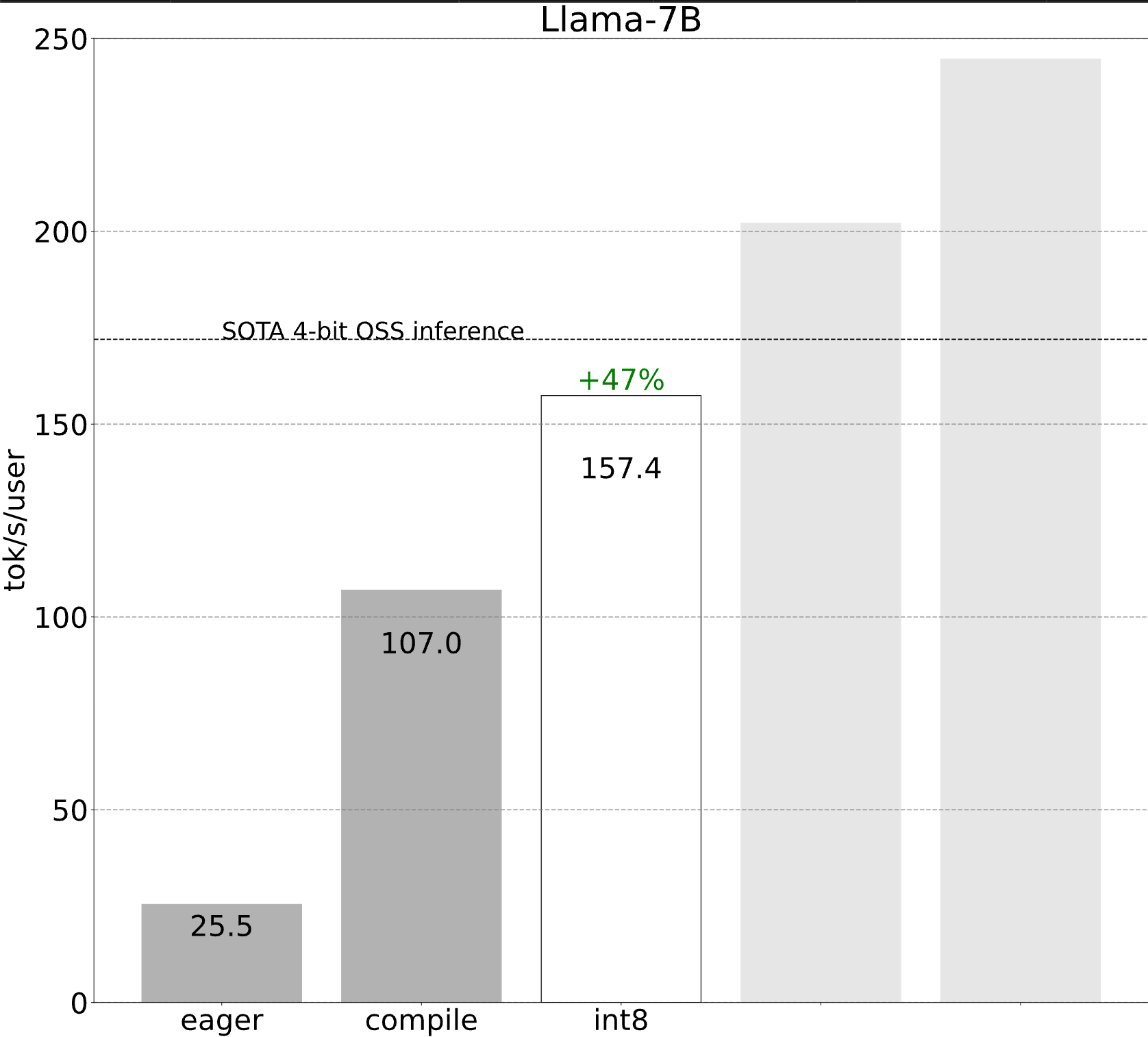
第三步:利用推测解码重新构建问题 (202.1 tok/s)
即使在使用量化等技术之后,我们仍然面临另一个问题。为了生成 100 个 token,我们必须加载 100 次权重。
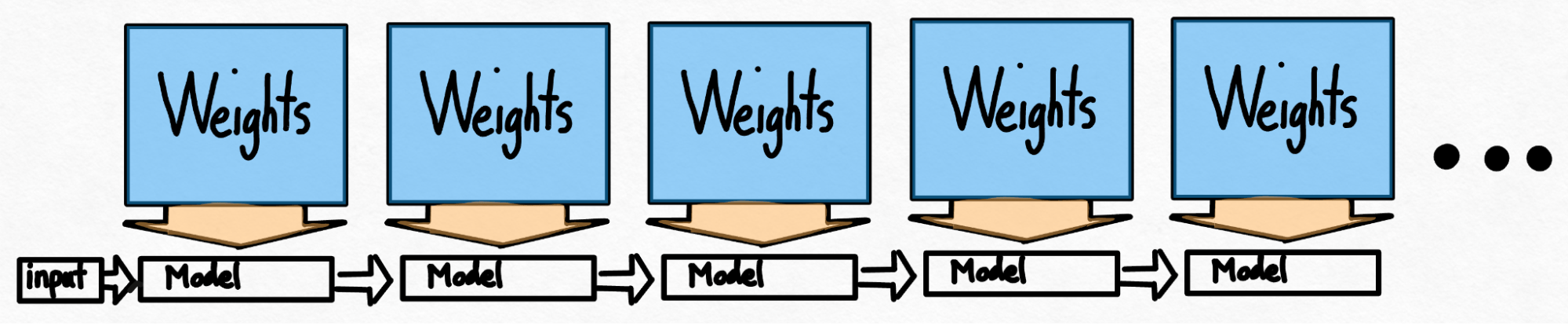
即使权重经过量化,我们仍然必须一遍又一遍地加载权重,每生成一个 token 就加载一次!有没有办法解决这个问题?
乍一看,答案似乎是否定的——我们的自回归生成存在严格的串行依赖。然而,事实证明,通过利用推测解码,我们能够打破这种严格的串行依赖并获得加速!
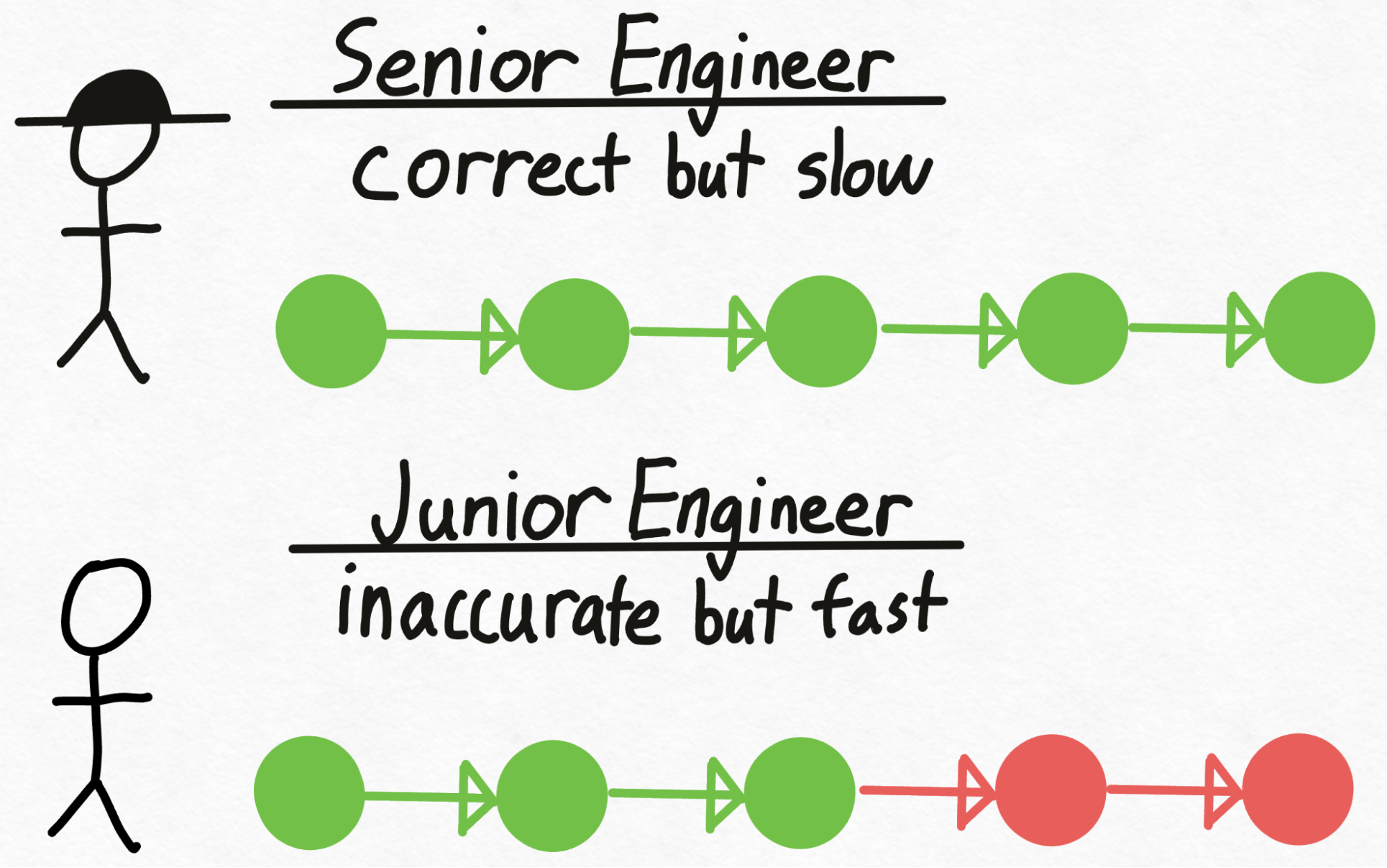
想象一下,你有一位高级工程师(名叫 Verity),他能做出正确的技术决策,但编写代码相当慢。然而,你还有一位初级工程师(名叫 Drake),他并不总是能做出正确的技术决策,但他编写代码的速度比 Verity 快得多(也更便宜!)。我们如何利用 Drake(初级工程师)更快地编写代码,同时确保我们仍然做出正确的技术决策?

首先,Drake 经历编写代码的劳动密集型过程,在此过程中做出技术决策。接下来,我们将代码交给 Verity 审核。
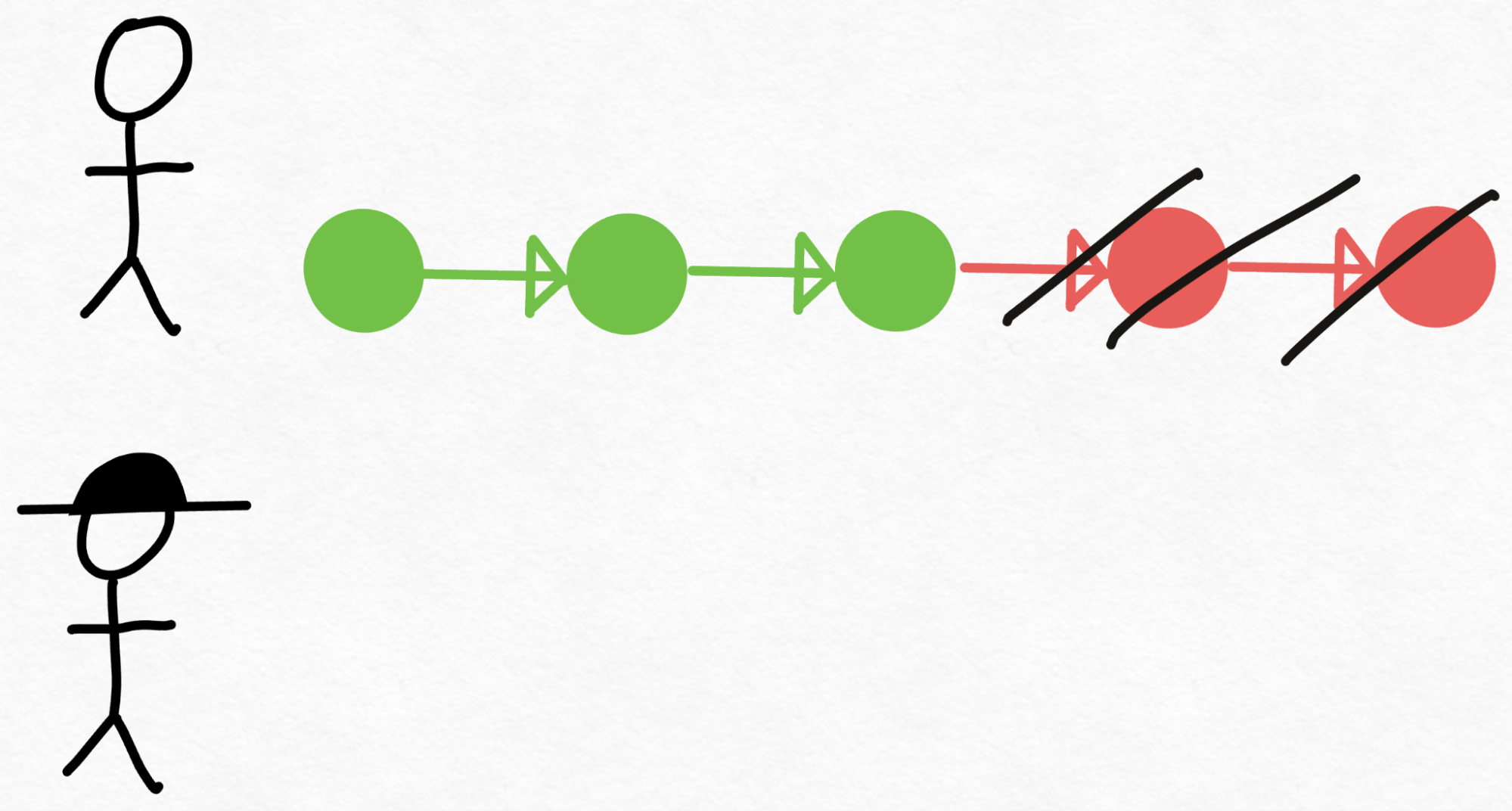
在审查代码时,Verity 可能会决定 Drake 做出的前 3 个技术决策是正确的,但最后 2 个需要重做。于是,Drake 回去,抛弃了他最后 2 个决策,并从那里重新开始编码。
值得注意的是,尽管 Verity(高级工程师)只看了一次代码,但我们能够生成 3 块经过验证的代码,与她自己编写的代码完全相同!因此,假设 Verity 审核代码的速度比她自己编写这 3 块代码所需的时间要快,那么这种方法就会胜出。
在 transformer 推理的背景下,Verity 将由我们希望获得其输出的较大模型扮演,称为 验证器模型。同样,Drake 将由一个比大模型生成文本快得多的较小模型扮演,称为 草稿模型。因此,我们将使用草稿模型生成 8 个 token,然后使用验证器模型并行处理所有这八个 token,丢弃不匹配的 token。
如上所述,推测解码的一个关键特性是 它不会改变输出的质量。只要使用草稿模型生成 token + 验证 token 所花费的时间少于生成这些 token 所需的时间,我们就会领先。
在原生 PyTorch 中实现这一切的好处之一是,这项技术实际上非常容易实现!这是整个实现,大约 50 行原生 PyTorch 代码。

虽然推测解码保证了我们在数学上与常规生成结果相同,但它的运行时性能确实会因生成的文本以及草稿模型和验证器模型的对齐程度而异。例如,运行 CodeLlama-34B + CodeLlama-7B 时,我们能够将生成代码的 tokens/s 提高 2 倍。另一方面,当使用 Llama-7B + TinyLlama-1B 时,我们只能将 tokens/s 提高约 1.3 倍。
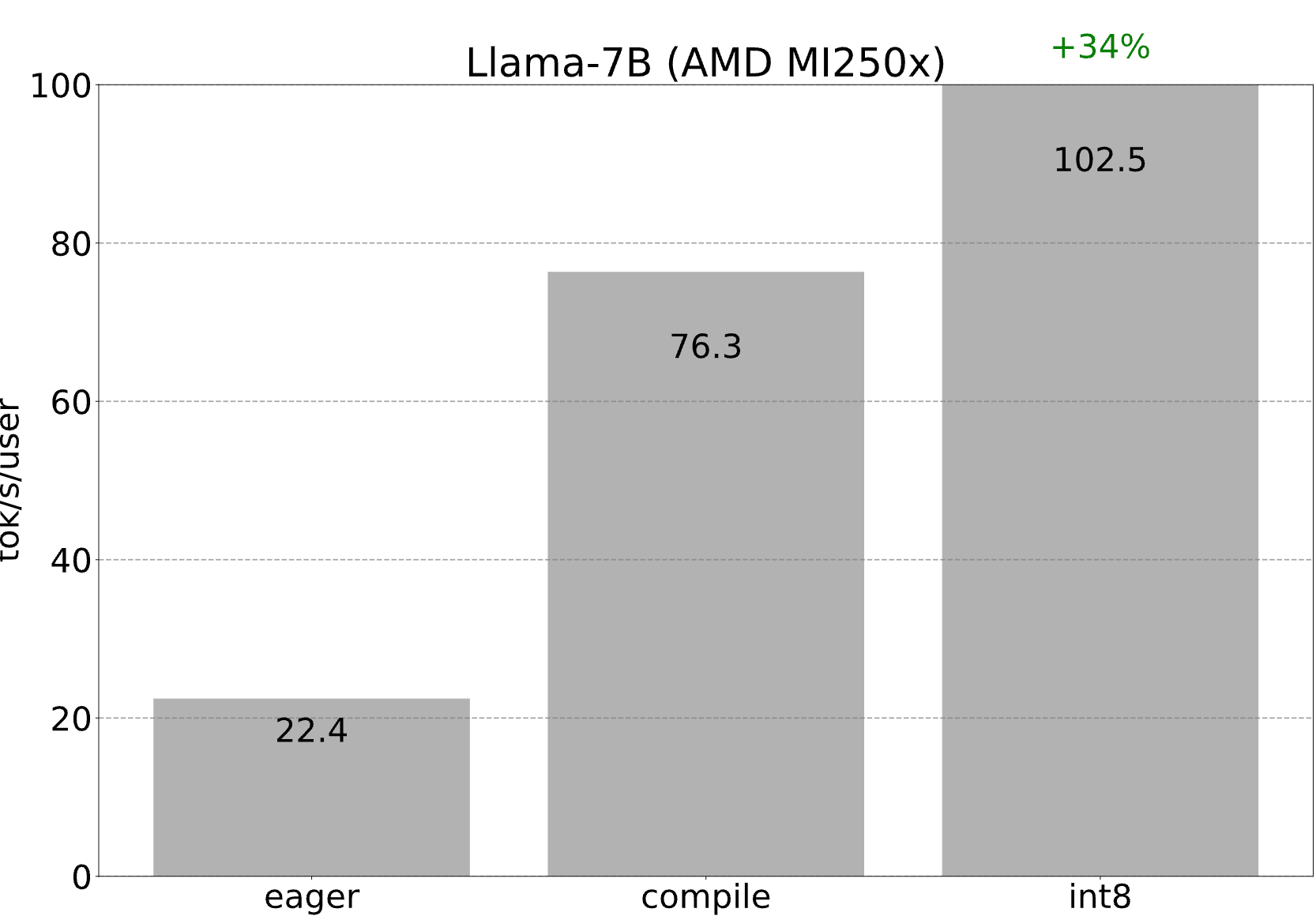
旁注:在 AMD 上运行此功能
如上所述,解码中的每个内核都由 torch.compile 从头开始生成,并转换为 OpenAI Triton。由于 AMD 有一个torch.compile 后端(以及一个 Triton 后端),我们只需经历上述所有优化……但在 AMD GPU 上!通过 int8 量化,我们能够在一个 MI250x 的一个 GCD(即一半)上达到 102.5 tokens/s!
第四步:通过 int4 量化和 GPTQ 进一步减小权重大小 (202.1 tok/s)
当然,如果将权重从 16 位减小到 8 位可以通过减少需要加载的字节数来提高速度,那么将权重减小到 4 位将导致更大的速度提升!
不幸的是,当将权重减小到 4 位时,模型的准确性开始成为一个更大的问题。从我们初步评估来看,尽管使用 int8 仅权重 量化没有明显的精度下降,但使用 int4 仅权重 量化却有。
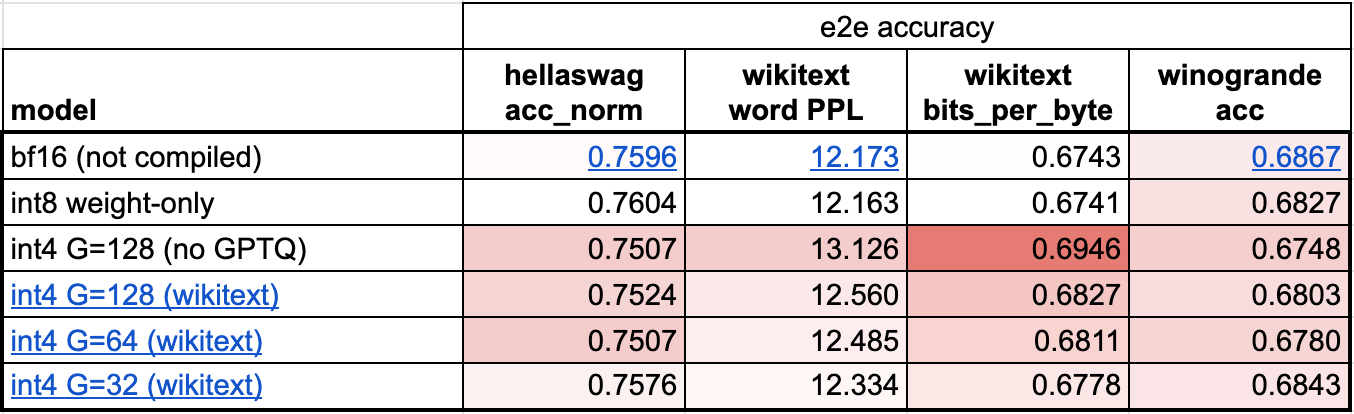
我们可以使用两种主要技巧来限制 int4 量化的精度下降。
第一个是采用更细粒度的缩放因子。理解缩放因子的一种方法是,当我们有一个量化张量表示时,它介于浮点张量(每个值都有一个缩放因子)和整数张量(没有值有缩放因子)之间。例如,在 int8 量化中,我们每行有一个缩放因子。然而,如果我们需要更高的精度,我们可以将其更改为“每 32 个元素一个缩放因子”。我们选择 32 的组大小是为了最大程度地减少精度下降,这也是社区中的一个常见选择。
另一个是使用比简单地舍入权重更高级的量化策略。例如,像GPTQ这样的方法利用示例数据来更准确地校准权重。在这种情况下,我们基于 PyTorch 最近发布的torch.export在存储库中原型化了 GPTQ 的实现。
此外,我们需要将 int4 反量化与矩阵向量乘法融合的内核。在这种情况下,torch.compile 不幸无法从头开始生成这些内核,因此我们利用了 PyTorch 中的一些手写 CUDA 内核。
这些技术需要一些额外的工作,但将它们结合起来会带来更好的性能!
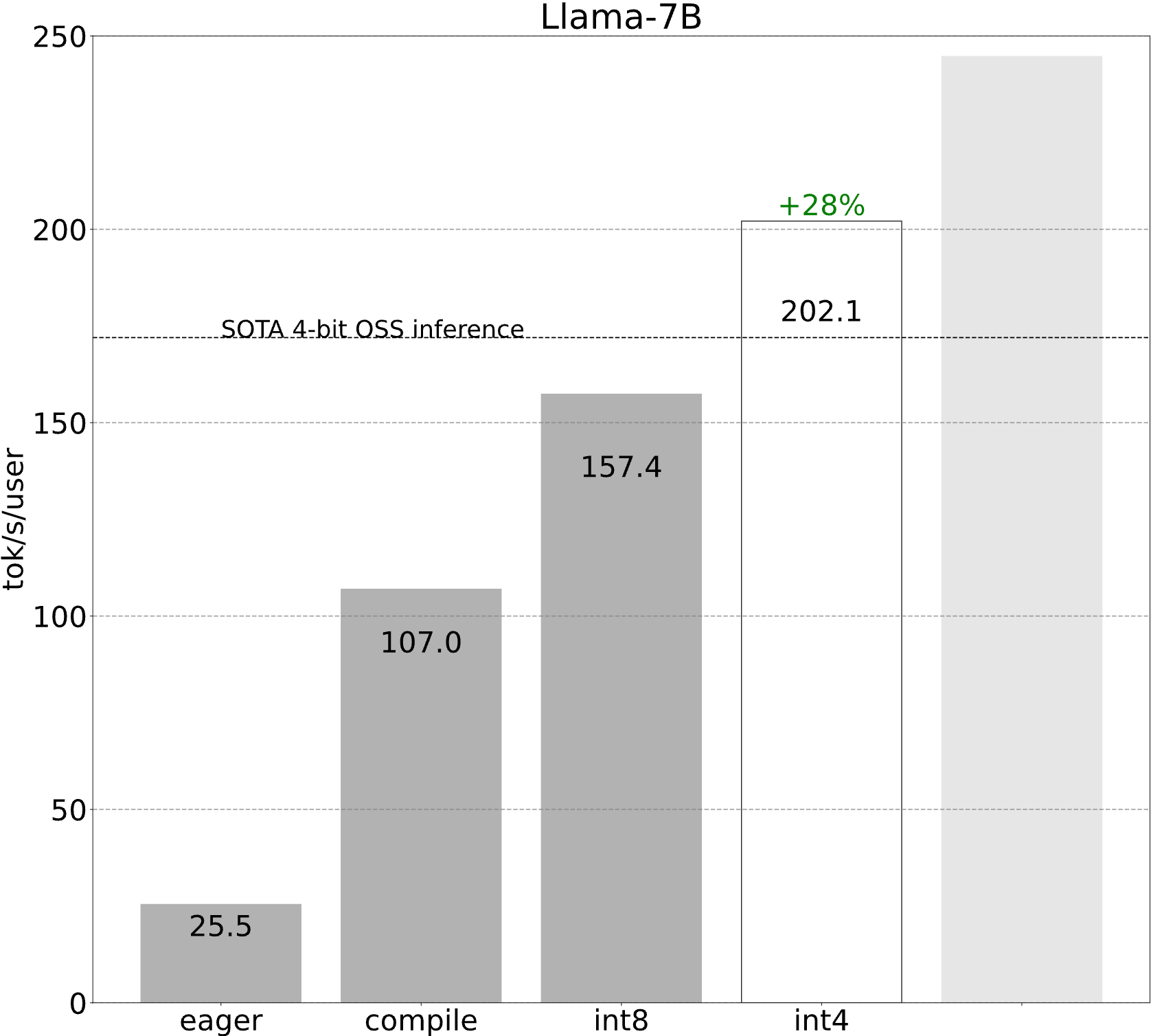
第五步:将所有技术结合起来 (244.7 tok/s)
最后,我们可以将所有技术结合起来,以实现更好的性能!
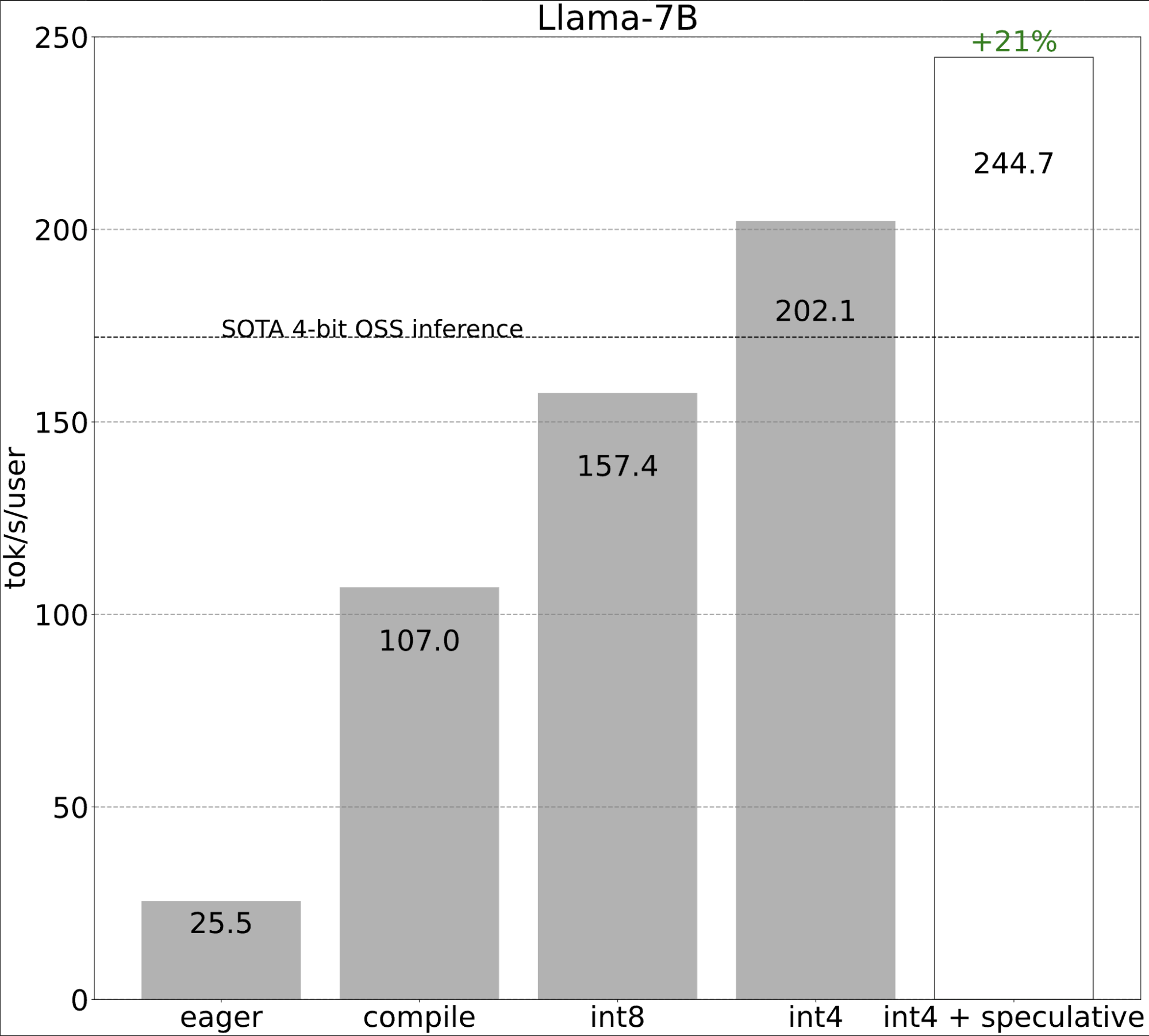
第六步:使用张量并行
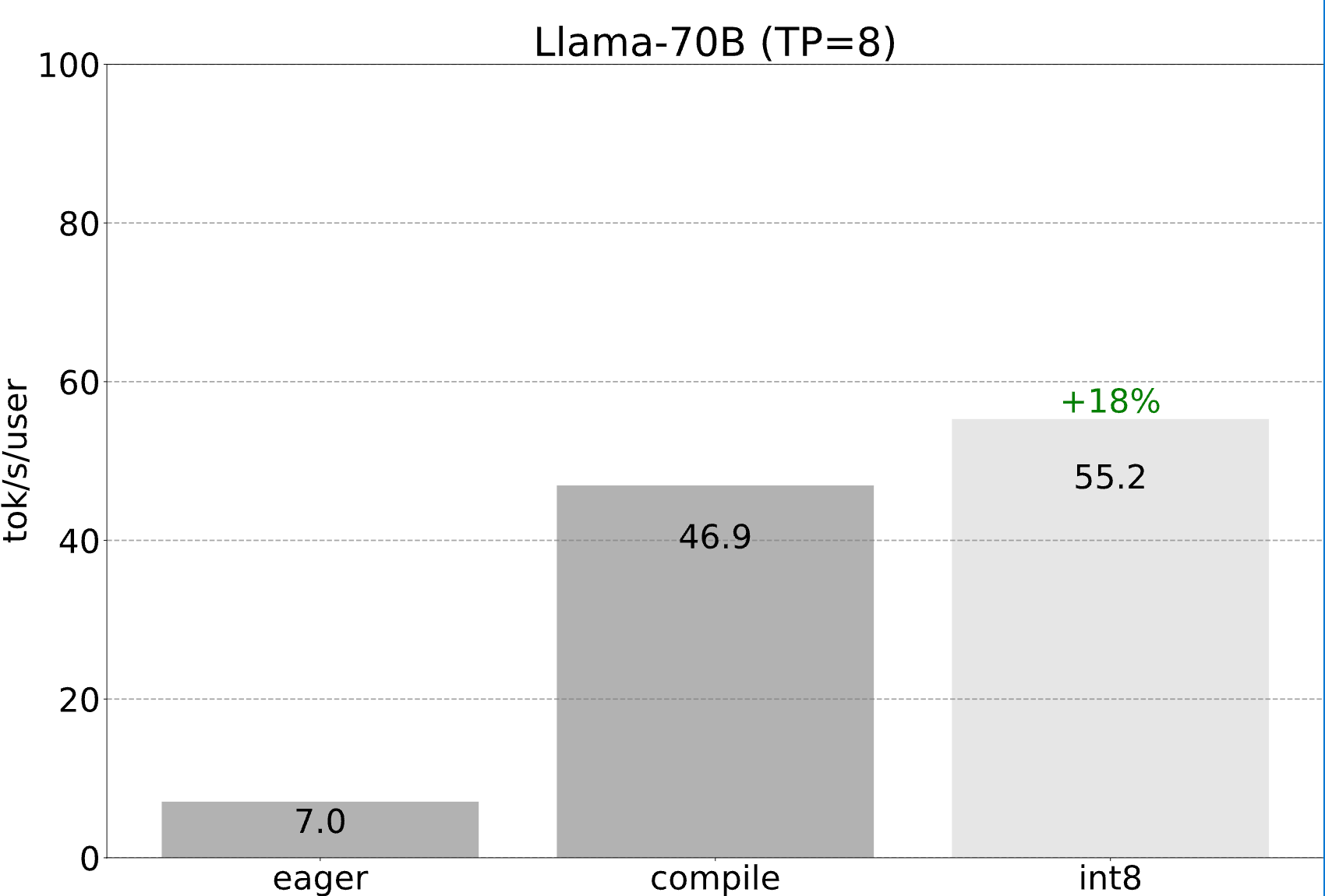
到目前为止,我们一直将自己限制在单个 GPU 上最小化延迟。然而,在许多设置中,我们都可以访问多个 GPU。这使我们能够进一步改善延迟!
为了直观地理解为什么这能提高我们的延迟,让我们看看 MBU 的前一个方程,特别是分母。在多个 GPU 上运行使我们能够访问更多的内存带宽,从而获得更高的潜在性能。
至于选择哪种并行策略,请注意,为了减少单个示例的延迟,我们需要能够同时跨多个设备利用我们的内存带宽。这意味着我们需要将一个 token 的处理分散到多个设备上。换句话说,我们需要使用张量并行。
幸运的是,PyTorch 也提供了与 torch.compile 兼容的张量并行低级工具。我们还在开发更高级的 API 来表达张量并行,敬请期待!
然而,即使没有更高级别的 API,添加张量并行仍然非常容易。我们的实现仅需150 行代码,并且不需要任何模型更改。

我们仍然可以利用前面提到的所有优化,这些优化都可以继续与张量并行组合。将这些结合起来,我们能够以 55 tokens/s 的速度使用 int8 量化为 Llama-70B 提供服务!
总结
让我们看看我们能够完成什么。
- 简洁性:忽略量化,model.py (244 LOC) + generate.py (371 LOC) + tp.py (151 LOC) 总共 766 LOC,实现了快速推理 + 推测解码 + 张量并行。
- 性能:对于 Llama-7B,我们能够使用编译 + int4 量化 + 推测解码达到 241 tok/s。对于 Llama-70B,我们还可以加入张量并行达到 80 tok/s。这些都接近或超越了 SOTA 性能数据!
PyTorch 始终提供简洁性、易用性和灵活性。然而,借助 torch.compile,我们还可以兼顾性能。
代码可以在这里找到:https://github.com/pytorch-labs/gpt-fast。我们希望社区觉得它有用。我们这个仓库的目标不是提供另一个供人们导入的库或框架。相反,我们鼓励用户复制粘贴、分支和修改仓库中的代码。
致谢
我们要感谢活跃的开源社区对扩展 LLM 的持续支持,其中包括
- Lightning AI 对 pytorch 和 flash attention、int8 量化以及 LoRA 微调工作的支持。
- GGML 推动了 LLM 在设备上的快速推理
- Andrej Karpathy 率先提出了简单、可解释且快速的 LLM 实现
- MLC-LLM 推动了异构硬件上的 4 位量化性能