摘要
最初,PyTorch 使用一种即时执行模式,其中构成模型的每个 PyTorch 操作在被执行时会立即独立运行。PyTorch 2.0 引入了 torch.compile,以加速 PyTorch 代码的运行速度,超越默认的即时执行模式。与即时执行模式相反,torch.compile 会预先将整个模型编译成一个单一图,其方式最适合在给定硬件平台上运行。AWS 优化了 PyTorch 的 torch.compile 功能,使其适用于 AWS Graviton3 处理器。这种优化使 Hugging Face 模型推理性能提升高达 2 倍(基于 33 个模型的性能提升几何平均值),使 TorchBench 模型推理性能提升高达 1.35 倍(基于 45 个模型的性能提升几何平均值),与在基于 AWS Graviton3 的 Amazon EC2 实例上跨多个自然语言处理 (NLP)、计算机视觉 (CV) 和推荐模型的默认即时执行模式推理相比。从 PyTorch 2.3.1 开始,这些优化功能已在 torch Python wheels 和 AWS Graviton PyTorch 深度学习容器 (DLC) 中可用。
在这篇博文中,我们将展示我们如何优化 AWS Graviton3-based EC2 实例上的 torch.compile 性能,如何利用这些优化来提高推理性能,以及由此带来的速度提升。
为什么选择 torch.compile 以及目标是什么?
在即时执行模式下,模型中的运算符在遇到时会立即运行。它更容易使用,更适合机器学习 (ML) 研究人员,因此是默认模式。然而,即时执行模式会因为冗余的内核启动和内存读取开销而产生运行时开销。而在 torch compile 模式下,运算符首先被合成为一个图,其中一个运算符与另一个运算符合并,以减少和局部化内存读取和总内核启动开销。
AWS Graviton 团队的目标是优化 Graviton3 处理器的 torch.compile 后端。PyTorch 即时执行模式已经针对 Graviton3 处理器进行了优化,使用了 Arm Compute Library (ACL) 内核和 oneDNN (也称为 MKLDNN)。所以问题是,如何在 torch.compile 模式下重用这些内核,以同时获得图编译和优化内核性能的最佳效果?
结果
AWS Graviton 团队扩展了 torch inductor 和 oneDNN 原语,这些原语重用了 ACL 内核,并优化了 Graviton3 处理器上的编译模式性能。从 PyTorch 2.3.1 开始,这些优化已在 torch Python wheels 和 AWS Graviton DLC 中可用。有关安装、运行时配置以及如何运行测试的说明,请参阅后面的“运行推理”部分。
为了展示性能改进,我们使用了来自 TorchBench 的 NLP、CV 和推荐模型,以及来自 Hugging Face 的下载量最高的 NLP 模型,涵盖了问答、文本分类、标记分类、翻译、零样本分类、翻译、摘要、特征提取、文本生成、文本到文本生成、填充掩码和句子相似性任务,以涵盖各种客户用例。
我们首先测量了即时执行模式下 TorchBench 模型推理的延迟,单位是毫秒 (msec),在下图中用红色虚线标为 1.0。然后,我们比较了 torch.compile 对相同模型推理的改进,并将归一化结果绘制在图中。您可以看到,对于我们测试的 45 个模型,延迟提升了 1.35 倍(45 个模型的几何平均值)。
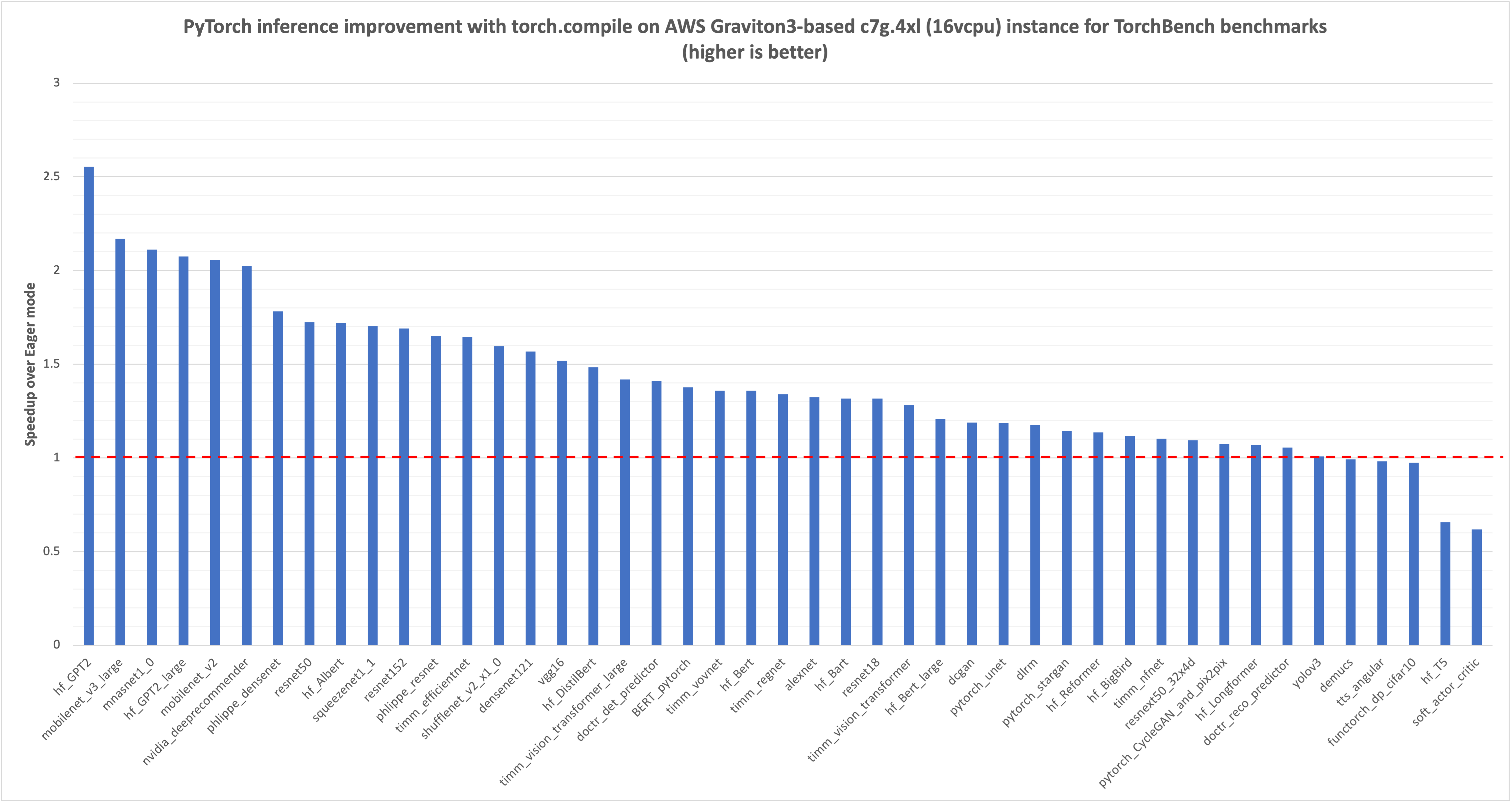
图 1:在 AWS Graviton3-based c7g 实例上使用 TorchBench 框架,通过 torch.compile 提升 PyTorch 模型推理性能。参考的即时执行模式性能标记为 1.0。(越高越好)
与之前的 TorchBench 推理性能图类似,我们首先测量了 Hugging Face NLP 模型在即时执行模式下的推理延迟(毫秒),在下图中用红色虚线标记为 1.0。然后,我们比较了 torch.compile 对相同模型推理的改进,并将归一化结果绘制在图中。您可以看到,对于我们基准测试的 33 个模型,性能提升了大约 2 倍(33 个模型的几何平均值)。
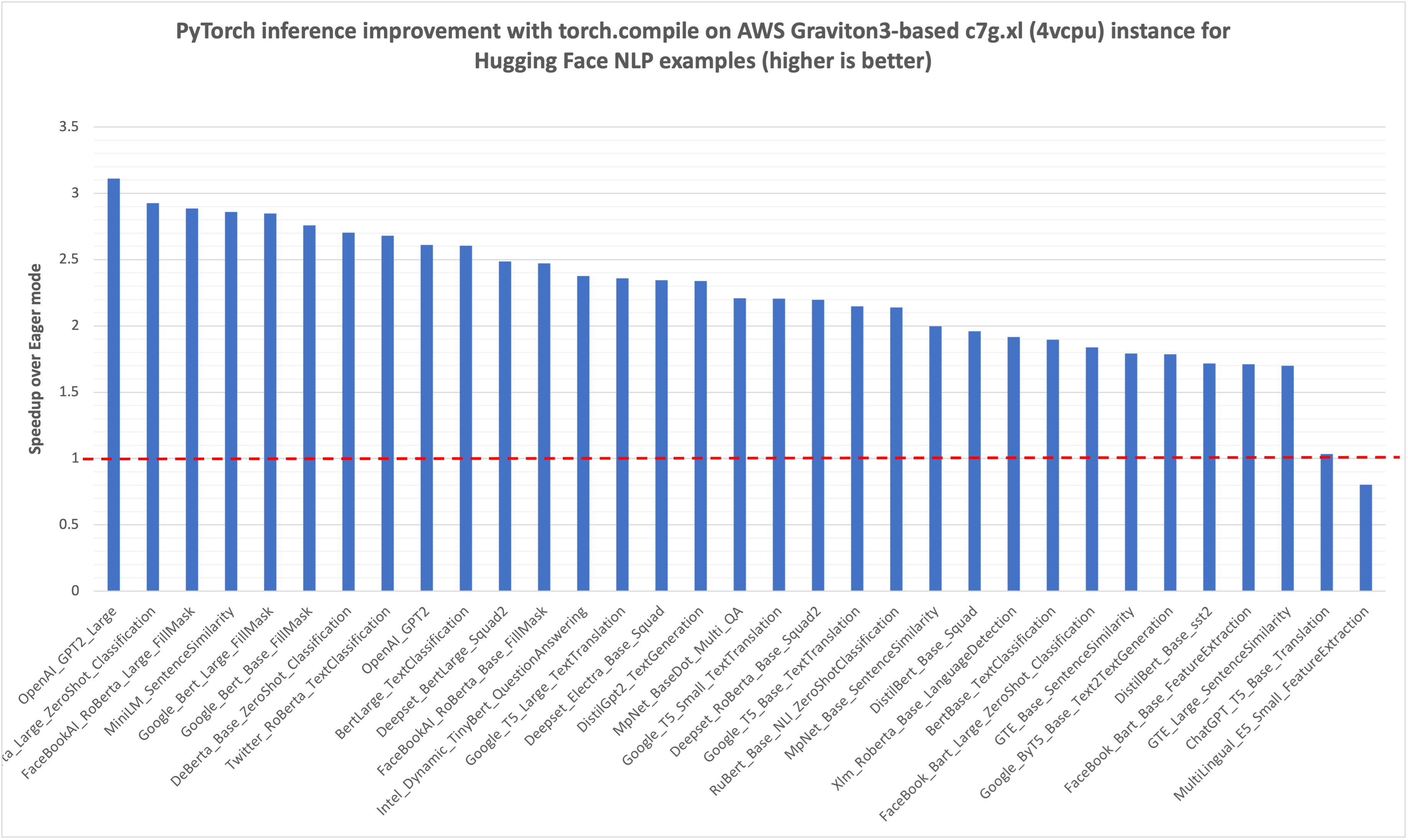
图 2:在 AWS Graviton3-based c7g 实例上,使用 Hugging Face 示例脚本,通过 torch.compile 提升 Hugging Face NLP 模型推理性能。参考的即时执行模式性能标记为 1.0。(越高越好)
运行推理
从 PyTorch 2.3.1 开始,优化功能已在 torch Python wheel 和 AWS Graviton PyTorch DLC 中可用。本节将展示如何使用 torch Python wheels 以及 Hugging Face 和 TorchBench 仓库中的基准测试脚本,在即时执行模式和 torch.compile 模式下运行推理。
为了成功运行脚本并复现本文中提到的加速数据,您需要一个 Graviton3 系列(c7g/r7g/m7g/hpc7g)的硬件实例。在本文中,我们使用了 c7g.4xl (16 vcpu) 实例。实例、AMI 详细信息和所需的 torch 库版本在以下代码片段中提及。
Instance: c7g.4xl instance
Region: us-west-2
AMI: ami-05cc25bfa725a144a (Ubuntu 22.04/Jammy with 6.5.0-1017-aws kernel)
# Install Python
sudo apt-get update
sudo apt-get install -y python3 python3-pip
# Upgrade pip3 to the latest version
python3 -m pip install --upgrade pip
# Install PyTorch and extensions
python3 -m pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1
为即时执行模式推理实现的通用运行时调优同样适用于 torch.compile 模式,因此,我们设置了以下环境变量,以进一步提高 AWS Graviton3 处理器上的 torch.compile 性能。
# Enable the fast math GEMM kernels, to accelerate fp32 inference with bfloat16 gemm
export DNNL_DEFAULT_FPMATH_MODE=BF16
# Enable Linux Transparent Huge Page (THP) allocations,
# to reduce the tensor memory allocation latency
export THP_MEM_ALLOC_ENABLE=1
# Set LRU Cache capacity to cache the primitives and avoid redundant
# memory allocations
export LRU_CACHE_CAPACITY=1024
TORCHBENCH 基准测试脚本
TorchBench 是一个用于评估 PyTorch 性能的开源基准测试集合。我们使用 TorchBench 仓库中的脚本对 45 个模型进行了基准测试。以下代码展示了如何为即时执行模式和使用 inductor 后端的编译模式运行脚本。
# Set OMP_NUM_THREADS to number of vcpus, 16 for c7g.4xl instance
export OMP_NUM_THREADS=16
# Install the dependencies
sudo apt-get install -y libgl1-mesa-glx
sudo apt-get install -y libpangocairo-1.0-0
python3 -m pip install psutil numpy transformers pynvml numba onnx onnxruntime scikit-learn timm effdet gym doctr opencv-python h5py==3.10.0 python-doctr
# Clone pytorch benchmark repo
git clone https://github.com/pytorch/benchmark.git
cd benchmark
# PyTorch benchmark repo doesn't have any release tags. So,
# listing the commit we used for collecting the performance numbers
git checkout 9a5e4137299741e1b6fb7aa7f5a6a853e5dd2295
# Setup the models
python3 install.py
# Colect eager mode performance using the following command. The results will be
# stored at .userbenchmark/cpu/metric-<timestamp>.json.
python3 run_benchmark.py cpu --model BERT_pytorch,hf_Bert,hf_Bert_large,hf_GPT2,hf_Albert,hf_Bart,hf_BigBird,hf_DistilBert,hf_GPT2_large,dlrm,hf_T5,mnasnet1_0,mobilenet_v2,mobilenet_v3_large,squeezenet1_1,timm_efficientnet,shufflenet_v2_x1_0,timm_regnet,resnet50,soft_actor_critic,phlippe_densenet,resnet152,resnet18,resnext50_32x4d,densenet121,phlippe_resnet,doctr_det_predictor,timm_vovnet,alexnet,doctr_reco_predictor,vgg16,dcgan,yolov3,pytorch_stargan,hf_Longformer,timm_nfnet,timm_vision_transformer,timm_vision_transformer_large,nvidia_deeprecommender,demucs,tts_angular,hf_Reformer,pytorch_CycleGAN_and_pix2pix,functorch_dp_cifar10,pytorch_unet --test eval --metrics="latencies,cpu_peak_mem"
# Collect torch.compile mode performance with inductor backend
# and weights pre-packing enabled. The results will be stored at
# .userbenchmark/cpu/metric-<timestamp>.json
python3 run_benchmark.py cpu --model BERT_pytorch,hf_Bert,hf_Bert_large,hf_GPT2,hf_Albert,hf_Bart,hf_BigBird,hf_DistilBert,hf_GPT2_large,dlrm,hf_T5,mnasnet1_0,mobilenet_v2,mobilenet_v3_large,squeezenet1_1,timm_efficientnet,shufflenet_v2_x1_0,timm_regnet,resnet50,soft_actor_critic,phlippe_densenet,resnet152,resnet18,resnext50_32x4d,densenet121,phlippe_resnet,doctr_det_predictor,timm_vovnet,alexnet,doctr_reco_predictor,vgg16,dcgan,yolov3,pytorch_stargan,hf_Longformer,timm_nfnet,timm_vision_transformer,timm_vision_transformer_large,nvidia_deeprecommender,demucs,tts_angular,hf_Reformer,pytorch_CycleGAN_and_pix2pix,functorch_dp_cifar10,pytorch_unet --test eval --torchdynamo inductor --freeze_prepack_weights --metrics="latencies,cpu_peak_mem"
推理运行成功完成后,脚本将结果以 JSON 格式存储。以下是示例输出:
{
"name": "cpu"
"environ": {
"pytorch_git_version": "d44533f9d073df13895333e70b66f81c513c1889"
},
"metrics": {
"BERT_pytorch-eval_latency": 56.3769865,
"BERT_pytorch-eval_cmem": 0.4169921875
}
}
HUGGING FACE 基准测试脚本
Google T5 Small Text Translation 模型是我们测试的大约 30 个 Hugging Face 模型之一。我们将其作为一个示例模型,演示如何在即时执行和编译模式下运行推理。在编译模式下运行所需的额外配置和 API 以粗体突出显示。将以下脚本保存为 google_t5_small_text_translation.py。
import argparse
from transformers import T5Tokenizer, T5Model
import torch
from torch.profiler import profile, record_function, ProfilerActivity
import torch._inductor.config as config
config.cpp.weight_prepack=True
config.freezing=True
def test_inference(mode, num_iter):
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5Model.from_pretrained("t5-small")
input_ids = tokenizer(
"Studies have been shown that owning a dog is good for you", return_tensors="pt"
).input_ids # Batch size 1
decoder_input_ids = tokenizer("Studies show that", return_tensors="pt").input_ids # Batch size 1
if (mode == 'compile'):
model = torch.compile(model)
with torch.no_grad():
for _ in range(50):
outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
with profile(activities=[ProfilerActivity.CPU]) as prof:
with record_function("model_inference"):
for _ in range(num_iter):
outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
print(prof.key_averages().table(sort_by="self_cpu_time_total"))
def main() -> None:
global m, args
parser = argparse.ArgumentParser(__doc__)
parser.add_argument(
"-m",
"--mode",
choices=["eager", "compile"],
default="eager",
help="Which test to run.",
)
parser.add_argument(
"-n",
"--number",
type=int,
default=100,
help="how many iterations to run.",
)
args = parser.parse_args()
test_inference(args.mode, args.number)
if __name__ == "__main__":
main()
按照以下步骤运行脚本:
# Set OMP_NUM_THREADS to number of vcpus to 4 because
# the scripts are running inference in sequence, and
# they don't need large number of vcpus
export OMP_NUM_THREADS=4
# Install the dependencies
python3 -m pip install transformers
# Run the inference script in Eager mode
# using number of iterations as 1 just to show the torch profiler output
# but for the benchmarking, we used 1000 iterations.
python3 google_t5_small_text_translation.py -n 1 -m eager
# Run the inference script in torch compile mode
python3 google_t5_small_text_translation.py -n 1 -m compile
推理运行成功完成后,脚本将打印 torch profiler 输出,其中包含 torch 运算符的延迟分解。以下是 torch profiler 的示例输出:
# Torch profiler output for the eager mode run on c7g.xl (4vcpu)
------------------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
------------------------ ------------ ------------ ------------ ------------ ------------ ------------
aten::mm 40.71% 12.502ms 40.71% 12.502ms 130.229us 96
model_inference 26.44% 8.118ms 100.00% 30.708ms 30.708ms 1
aten::bmm 6.85% 2.102ms 9.47% 2.908ms 80.778us 36
aten::matmul 3.73% 1.146ms 57.26% 17.583ms 133.205us 132
aten::select 1.88% 576.000us 1.90% 583.000us 0.998us 584
aten::transpose 1.51% 464.000us 1.83% 563.000us 3.027us 186
------------------------ ------------ ------------ ------------ ------------ ------------ -------------------
Self CPU time total: 30.708ms
# Torch profiler output for the compile mode run for the same model on the same instance
--------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
--------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
mkldnn::_linear_pointwise 37.98% 5.461ms 45.91% 6.602ms 68.771us 96
Torch-Compiled Region 29.56% 4.251ms 98.53% 14.168ms 14.168ms 1
aten::bmm 14.90% 2.143ms 21.73% 3.124ms 86.778us 36
aten::select 4.51% 648.000us 4.62% 665.000us 1.155us 576
aten::view 3.29% 473.000us 3.29% 473.000us 1.642us 288
aten::empty 2.53% 364.000us 2.53% 364.000us 3.165us 115
--------------------------------- ------------ ------------ ------------ ------------ ------------ --------------------
Self CPU time total: 14.379ms
技术深入探讨:挑战和优化细节
torch.compile 的基础是新技术——TorchDynamo、AOTDispatcher 和 TorchInductor。
TorchDynamo 使用 Python 帧评估钩子安全地捕获 PyTorch 程序。
AOTDispatcher 将 PyTorch 的自动梯度引擎重载为跟踪自动微分器,用于生成提前反向跟踪。
TorchInductor 是一个深度学习编译器,可为多个加速器和后端生成快速代码。
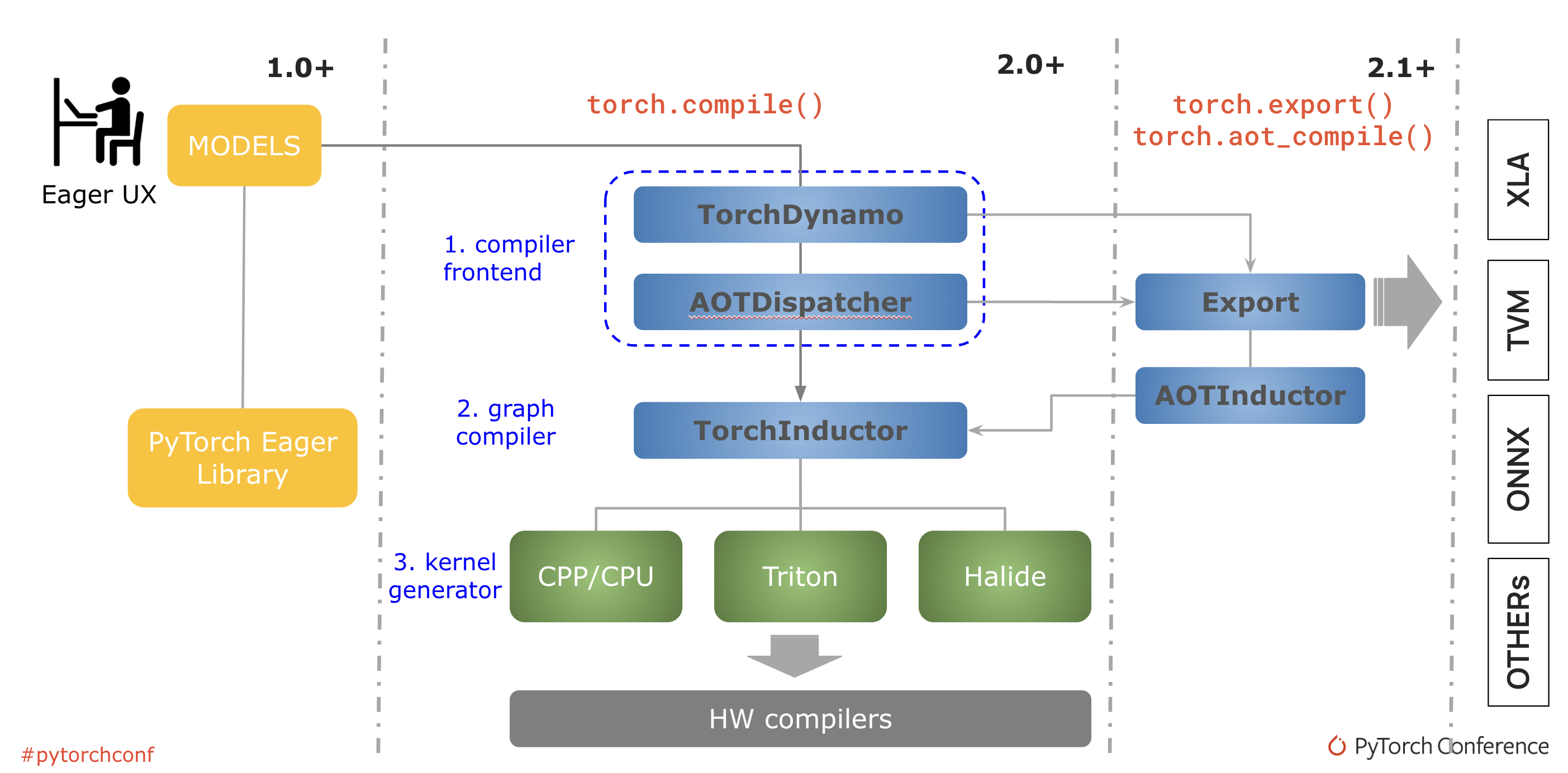
图 3:PyTorch 编译过程
当调用 torch.compile 时,torch dynamo 会重写 Python 字节码,将 PyTorch 操作序列提取为 FX 图,然后用 inductor 后端编译。对于典型的推理场景,其中图是冻结的并且梯度计算被禁用,inductor 会调用特定于平台的优化,例如将图重写为更高性能的运算符、运算符融合和权重预打包。
然而,在 Graviton3 上,inductor 无法执行任何这些优化,因为没有定义 aarch64 后端。为了解决这个问题,我们扩展了 inductor 的 FX 传递,使其能够在 Graviton3 处理器上使用 ACL 后端为线性层编译选择 oneDNN 运算符。以下是其代码片段:
packed_weight_op = (
mkldnn._reorder_linear_weight
if (is_bf16_weight or mkldnn._is_mkldnn_acl_supported())
packed_linear_inputs: Tuple[Any, ...] = (input, packed_weight_node)
if is_bf16_weight or mkldnn._is_mkldnn_acl_supported():
packed_linear_inputs += (bias, "none", [], "")
packed_linear_op = mkldnn._linear_pointwise.default
完成此操作后,FX 传递成功地将 matmul 运算符编译为 linear_pointwise。以下代码片段突出显示了原始模型中的 matmul 运算符:
%attention_scores : [num_users=1] = call_function[target=torch.matmul](args = (%query_layer, %transpose), kwargs = {})
%attention_scores_1 : [num_users=1] = call_function[target=operator.truediv](args = (%attention_scores, 8.0), kwargs = {})
%attention_scores_2 : [num_users=1] = call_function[target=operator.add](args = (%attention_scores_1, %extended_attention_mask_3), kwargs = {})
以下代码片段突出显示了编译图中 linear_pointwise 运算符。
%_linear_pointwise_default_140 : [num_users=2] = call_function[target=torch.ops.mkldnn._linear_pointwise.default](args = (%add_7, %_frozen_param278, %_frozen_param16, none, [], ), kwargs = {})
%mul_5 : [num_users=1] = call_function[target=torch.ops.aten.mul.Tensor](args = (%_linear_pointwise_default_140, 0.5), kwargs = {})
%mul_6 : [num_users=1] = call_function[target=torch.ops.aten.mul.Tensor](args = (%_linear_pointwise_default_140, 0.7071067811865476), kwargs = {})
%erf : [num_users=1] = call_function[target=torch.ops.aten.erf.default](args = (%mul_6,), kwargs = {})
%add_8 : [num_users=1] = call_function[target=torch.ops.aten.add.Tensor](args = (%erf, 1), kwargs = {})
这完成了在 AWS Graviton3 处理器上将图编译为优化运算符所需的 torch inductor 更改。接下来是实际的推理,其中编译后的图被调度运行。oneDNN 结合 ACL 是我们在 inductor 编译期间选择的后端,因此,新的运算符按预期调度到 oneDNN,例如 mkldnn._linear_pointwise。然而,由于 oneDNN ACL 原语的不足,运算符使用 C++ 参考内核而不是优化的 ACL 内核运行。因此,编译性能仍然显著落后于即时执行模式性能。
oneDNN ACL 原语主要有三个方面缺乏对 torch.compile 模式的支持。以下部分将详细讨论这些方面。
1. ACL 原语不支持阻塞布局的权重
最初为即时执行模式设计的 ACL 原语仅支持标准通道优先 (NHWC) 格式的权重,且不进行预打包。然而,将权重预打包成阻塞布局是 inductor 编译过程中的主要优化之一,其中权重根据运行时平台重新排列成特定的块。这避免了在运行通用矩阵乘法 (GEMM) 时冗余的即时重新排序,否则这将成为推理性能的瓶颈。但是 ACL 原语不支持阻塞布局,因此运算符使用 oneDNN C++ 参考内核运行。
2. oneDNN 不支持混合精度原语
AWS Graviton3 处理器支持 bfloat16 MMLA 指令,这些指令可用于通过 bfloat16 GEMM 作为混合精度计算来加速 fp32 推理。ACL 支持 bfloat16 混合精度 GEMM 内核,并作为现有 fp32 运算符的快速数学计算选项集成到 oneDNN 中。然而,由于权重预打包优化,快速数学方法不适用于编译模式。编译模式需要 oneDNN 中明确的混合精度原语实现才能使用 bfloat16 加速。
3. ACL 原语不支持某些激活函数的融合内核
在即时执行模式下,操作符是单独调度的,因为模型在遇到时会独立运行。而在编译模式下,操作符融合是另一个重要的优化,操作符会被融合以提高运行时效率。例如,高斯误差线性单元 (GELU) 是基于 Transformer 的神经网络架构中最广泛使用的激活函数之一。因此,通常会有一个线性层(包含矩阵乘法)后跟 GELU 激活。作为将模型编译成高效操作符的一部分,torch inductor 将 matmul 和 GELU 融合到一个单一的 linearpointwise+gelu 操作符中。然而,oneDNN ACL 原语不支持与 GELU 融合的内核。
我们通过扩展 oneDNN 原语来处理额外的布局和新的原语定义,从而解决了这些不足。以下部分将详细讨论这些优化。
优化 1:扩展 ACL 原语以接受阻塞布局的权重张量
我们扩展了 ACL 原语以接受阻塞布局,除了标准 NHWC 格式。以下是其代码片段:
const bool is_weights_md_format_ok
= utils::one_of(weights_format_kind_received,
format_kind::any, format_kind::blocked);
const memory_desc_t weights_md_received = weights_md_;
acl_utils::reorder_to_weight_format(aip.wei_tensor_info,
weights_md_, expected_weight_format, inner_dim, o_dim,
remaining_dims, {});
ACL_CHECK_SUPPORT(
(weights_format_kind_received == format_kind::blocked)
&& !(dnnl_memory_desc_equal(
&weights_md_received, &weights_md_)),
"specified blocked format not supported by ACL, use "
"format_kind_t::any to find a supported blocked format for "
"your platform");
优化 2:定义新的 ACL 原语以处理混合精度运算符(权重为 bfloat16,激活为 fp32)
我们定义了混合精度原语定义,并更新了现有的 oneDNN ACL fp32 原语以处理 bfloat16 张量。
/* With graph compilation, we are able to reorder and pre-pack the weights during the model load
* and compilation phase itself so that redundant and on-the-fly reorders can be avoided.
* This primitive definition is to support gemm fastmath mode for the compile scenario where src is
* in fp32 and weights are in bf16
*/
{{forward, f32, bf16, f32}, {
CPU_INSTANCE_AARCH64_ACL(acl_inner_product_fwd_t)
nullptr,
}},
优化 3:禁用 torch inductor 中的运算符融合传递
我们绕过了 torch inductor 中的运算符融合过程,以便编译后的图不包含 GELU 融合运算符。这是在 torch.compile 中启用 ACL 内核的临时解决方案。目前正在进行一项工作,以便在未来的 PyTorch 版本中启用运算符融合过程。通过此变通方法,我们能够成功地将线性层调度到 ACL。如以下 torch.profiler 输出所示,原始模型中的 aten::addmm(matmul 运算符的一种变体)和 aten::gelu(如图 4 中突出显示)被编译为 mkldnn::_linear_pointwise,没有 gelu 运算符融合(如图 5 中突出显示)。
--------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
--------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::addmm 73.32% 46.543ms 74.49% 47.287ms 647.767us 73
model_inference 9.92% 6.296ms 100.00% 63.479ms 63.479ms 1
aten::bmm 4.37% 2.776ms 5.46% 3.467ms 144.458us 24
aten::copy_ 1.74% 1.102ms 1.74% 1.102ms 8.103us 136
aten::gelu 1.50% 950.000us 1.50% 950.000us 79.167us 12
图 4:Hugging Face bert base 模型在即时执行模式下的推理 torch.profiler 输出,显示 addmm 和 gelu 运算符。
----------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
----------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------
mkldnn::_linear_pointwise 53.61% 15.529ms 57.53% 16.665ms 228.288us 73
Torch-Compiled Region 36.95% 10.705ms 99.31% 28.769ms 28.769ms 1
aten::_scaled_dot_product_flash_attention_for_cpu 3.67% 1.064ms 4.43% 1.284ms 107.000us 12
aten::view 1.97% 572.000us 1.97% 572.000us 2.509us 228
aten::empty 1.38% 399.000us 1.38% 399.000us 3.270us 122
图 5:Hugging Face Bert base 模型在 torch.compile 模式下的推理 torch.profiler 输出,显示 linear_pointwise 运算符,不带 gelu 融合
最后,gelu 运算符被编译成 erf(误差函数),并调度到 inductor 自动向量化后端。以下代码片段展示了编译图中的 erf 运算符以及使用 libm.so 运行它的情况。
%_linear_pointwise_default_140 : [num_users=2] = call_function[target=torch.ops.mkldnn._linear_pointwise.default](args = (%add_7, %_frozen_param278, %_frozen_param16, none, [], ), kwargs = {})
%mul_5 : [num_users=1] = call_function[target=torch.ops.aten.mul.Tensor](args = (%_linear_pointwise_default_140, 0.5), kwargs = {})
%mul_6 : [num_users=1] = call_function[target=torch.ops.aten.mul.Tensor](args = (%_linear_pointwise_default_140, 0.7071067811865476), kwargs = {})
%erf : [num_users=1] = call_function[target=torch.ops.aten.erf.default](args = (%mul_6,), kwargs = {})
%add_8 : [num_users=1] = call_function[target=torch.ops.aten.add.Tensor](args = (%erf, 1), kwargs = {})
图 6:grad pass 后显示编译图中 erf 函数的片段
0.82% 0.40% python3 libm.so.6 [.] erff32
0.05% 0.00% python3 libtorch_python.so [.] torch::autograd::THPVariable_erf
0.05% 0.00% python3 libtorch_cpu.so [.] at::_ops::erf::call
图 7:Linux perf 报告显示 erf 调度到 libm.so
通过这项工作,我们成功地优化了 Graviton3 处理器上的 torch.compile 性能,利用了 inductor 图编译和 oneDNN+ACL 后端。
TorchBench 增强功能
为了展示 AWS Graviton3 处理器上 torch.compile 性能的改进,我们扩展了 TorchBench 框架,增加了一个新参数,用于启用图冻结和权重预打包,并禁用评估测试模式下的 torch 自动梯度。以下是其代码片段:
parser.add_argument(
"—freeze_prepack_weights",
action='store_true',
help="set to freeze the graph and prepack weights",
)
if args.freeze_prepack_weights:
torch._inductor.config.freezing=True
torch._inductor.config.cpp.weight_prepack=True
图 8:为 TorchBench 中的 torchdynamo 后端添加了 freeze_prepack_weights 选项,以展示 AWS Graviton3 处理器上的 torch.compile 性能改进。
我们已经将所有优化都向上游化,从 PyTorch 2.3.1 开始,这些优化已在 torch Python wheels 和 AWS Graviton PyTorch DLC 中得到支持。
下一步
接下来,我们将扩展 torch inductor CPU 后端支持以编译 Llama 模型,并增加对融合 GEMM 内核的支持,以在 AWS Graviton3 处理器上启用 torch inductor 运算符融合优化。
结论
在本教程中,我们介绍了如何优化基于 AWS Graviton3 的 EC2 实例上的 torch.compile 性能,如何利用这些优化来提高 PyTorch 模型推理性能,并展示了由此带来的加速效果。我们希望您能尝试一下!如果您在使用 Graviton 上的 ML 软件方面需要任何支持,请在 AWS Graviton 技术指南 GitHub 上提出问题。
致谢
我们衷心感谢 PyTorch 社区提供的基础 torch.compile 框架及其持续的优化工作。
参考文献:https://pytorch.ac.cn/assets/pytorch2-2.pdf
作者
Sunita Nadampalli 是 AWS 的软件开发经理和 AI/ML 专家。她领导 AWS Graviton 软件在 AI/ML 和 HPC 工作负载上的性能优化。她热衷于开源软件开发,并致力于为基于 Arm ISA 的 SoC 提供高性能和可持续的软件解决方案。