PyTorch 2.0 刚刚发布。其最重要的新特性是 torch.compile(),只需一行代码修改,便有望自动提升代码库的性能。我们之前已经在 Hugging Face Transformers 和 TIMM 模型中验证了这一承诺,并深入探讨了其动机、架构和未来发展。
尽管 torch.compile() 很重要,但 PyTorch 2.0 的内容远不止于此。值得注意的是,PyTorch 2.0 包含了多种加速 Transformer 块的策略,这些改进对于扩散模型也至关重要。例如,FlashAttention 等技术因其能够显著加速 Stable Diffusion 并实现更大批量大小的能力,在扩散社区中变得非常流行,现在它们已成为 PyTorch 2.0 的一部分。
在这篇文章中,我们将讨论 PyTorch 2.0 中注意力层是如何优化的,以及这些优化如何应用于流行的 🧨 Diffusers 库。最后,我们将通过基准测试展示使用 PyTorch 2.0 和 Diffusers 如何立即在不同硬件上带来显著的性能提升。
更新(2023 年 6 月):新增了一个章节,展示了在修正 diffusers 代码库中的图中断之后,使用最新版 PyTorch (2.0.1) 的 torch.compile() 带来了显著的性能提升。关于如何查找和修复图中断的更详细分析将在另一篇文章中发布。
加速 Transformer 块
PyTorch 2.0 在 torch.nn.functional 中包含了一个缩放点积注意力函数。该函数包含多种实现,可根据输入和所使用的硬件进行应用。在 PyTorch 2.0 之前,您必须搜索第三方实现并安装单独的软件包,才能利用内存优化算法,如 FlashAttention。可用的实现有:
- FlashAttention,来自官方的 FlashAttention 项目。
- 内存高效注意力,来自 xFormers 项目。
- 适用于非 CUDA 设备或需要高精度时的原生 C++ 实现。
所有这些方法默认可用,PyTorch 将尝试通过使用新的缩放点积注意力 (SDPA) API 自动选择最佳方法。您也可以单独切换它们以进行更精细的控制,详情请参见文档。
在 diffusers 中使用缩放点积注意力
将加速 PyTorch 2.0 Transformer 注意力整合到 Diffusers 库中,是通过使用 set_attn_processor 方法实现的,该方法允许配置可插拔的注意力模块。在这种情况下,创建了一个新的注意力处理器,它在 PyTorch 2.0 可用时默认启用。为了清晰起见,以下是手动启用它的方法(但通常没有必要,因为 diffusers 会自动处理):
from diffusers import StableDiffusionPipeline
from diffusers.models.cross_attention import AttnProcessor2_0
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipe.to("cuda")
pipe.unet.set_attn_processor(AttnProcessor2_0())
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
Stable Diffusion 基准测试
我们使用 PyTorch 2.0 中的加速点积注意力在 Diffusers 中运行了多项测试。我们从 pip 安装了 diffusers,并使用了 PyTorch 2.0 的每晚版本,因为我们的测试是在官方发布之前进行的。我们还使用了 torch.set_float32_matmul_precision('high') 来启用额外的快速矩阵乘法算法。
我们将结果与 diffusers 中传统的注意力实现(下面称为 vanilla)以及 PyTorch 2.0 之前性能最佳的解决方案:安装了 xFormers 包 (v0.0.16) 的 PyTorch 1.13.1 进行了比较。
结果在未编译(即,完全没有代码更改)和对 UNet 模块进行一次 torch.compile() 调用(编译)的情况下进行测量。我们没有编译图像解码器,因为大部分时间都花在运行 UNet 评估的 50 次去噪迭代中。
float32 结果
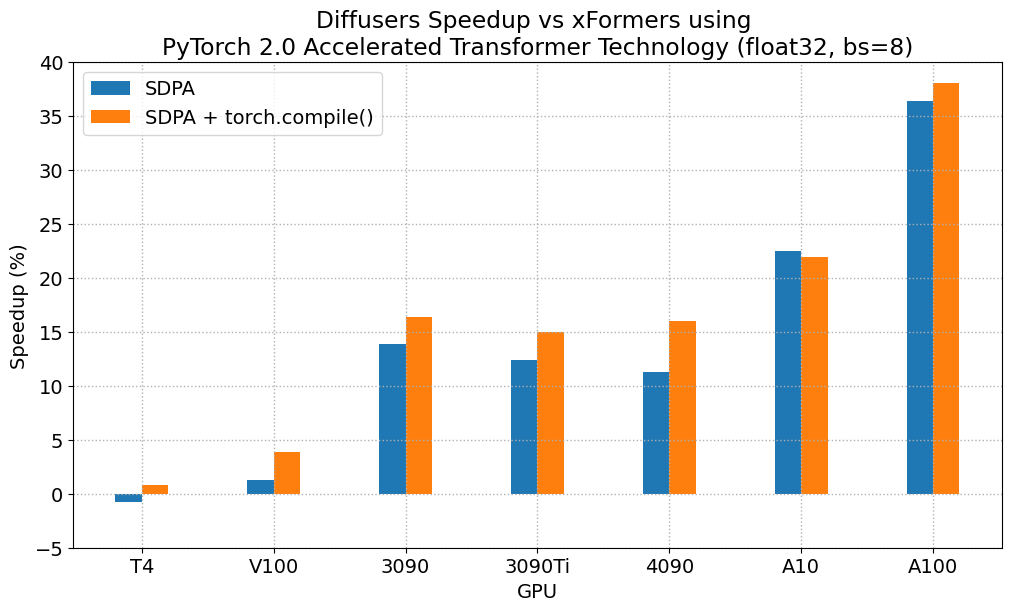
下图探讨了不同代各种代表性 GPU 的性能改进与批量大小的关系。我们收集了每种组合的数据,直到达到最大内存利用率。Vanilla 注意力比 xFormers 或 PyTorch 2.0 更早地耗尽内存,这解释了较大批量大小缺少柱状图的原因。同样,A100(我们使用的是 40 GB 版本)能够运行 64 的批量大小,但在我们的测试中,其他 GPU 只能达到 32。
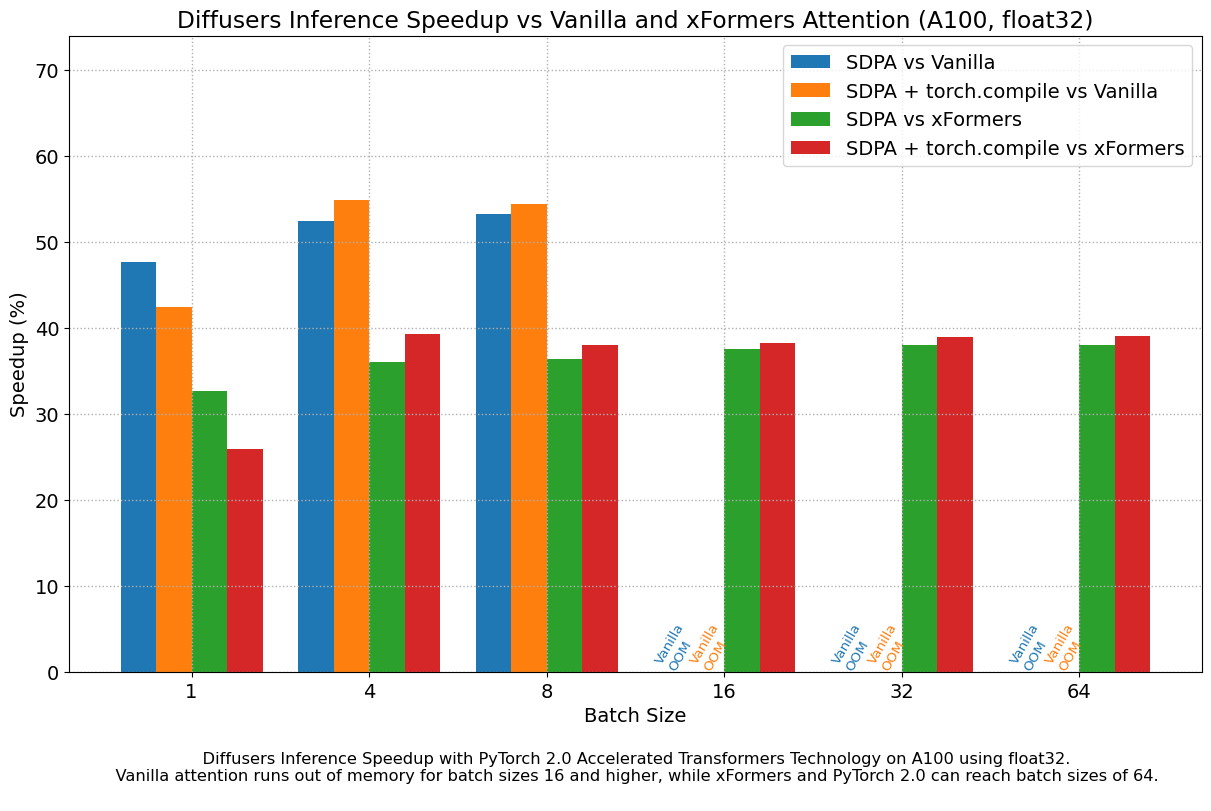
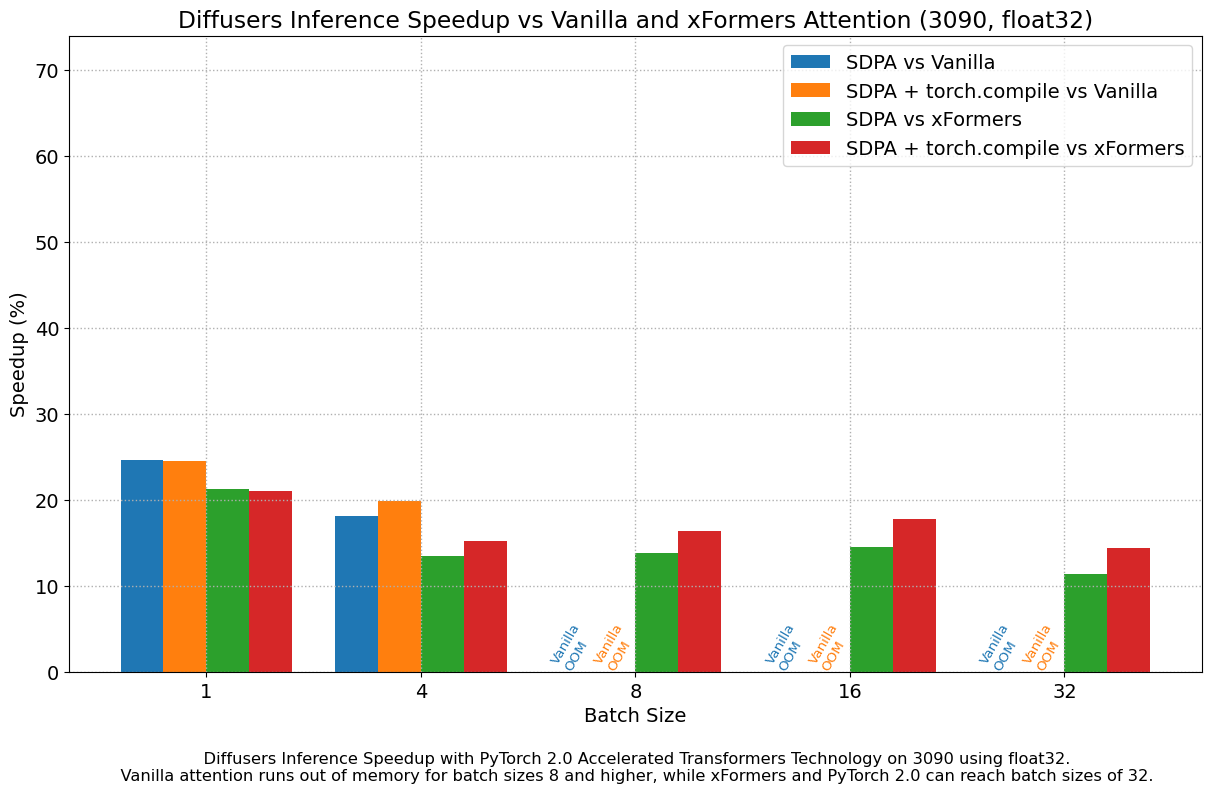
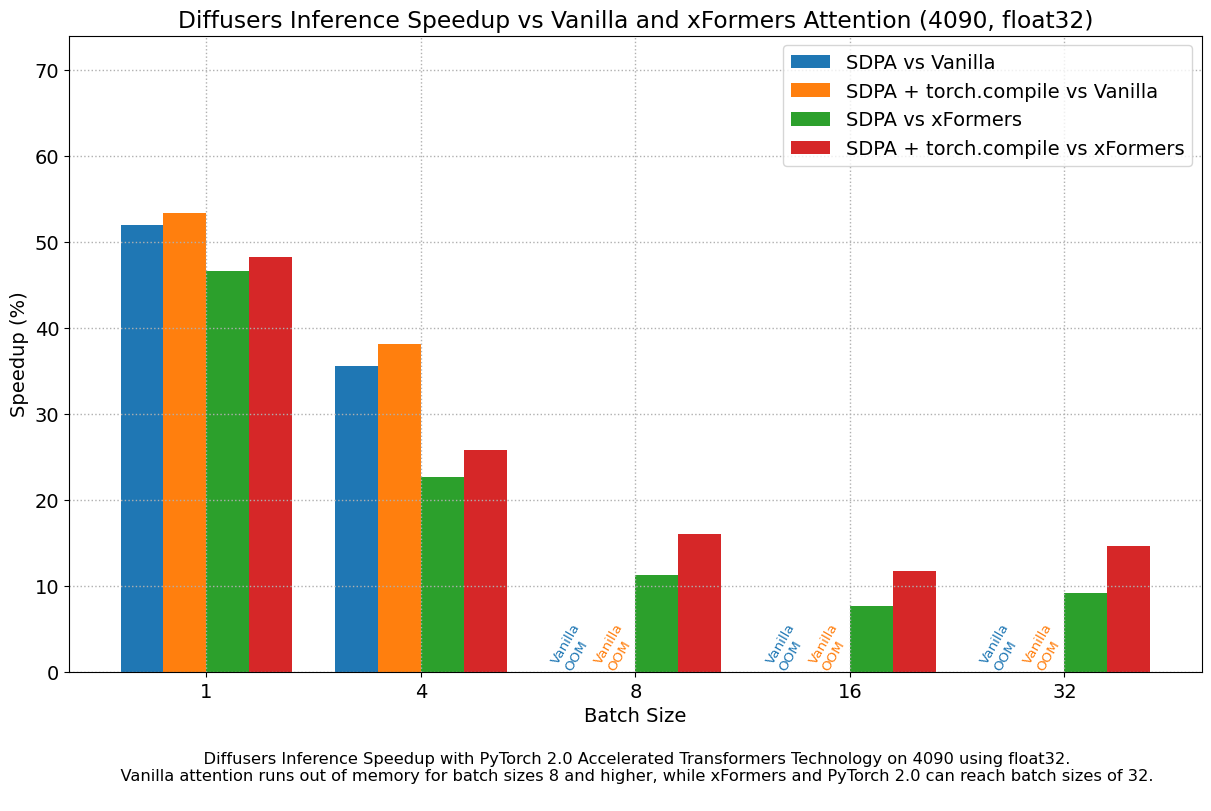
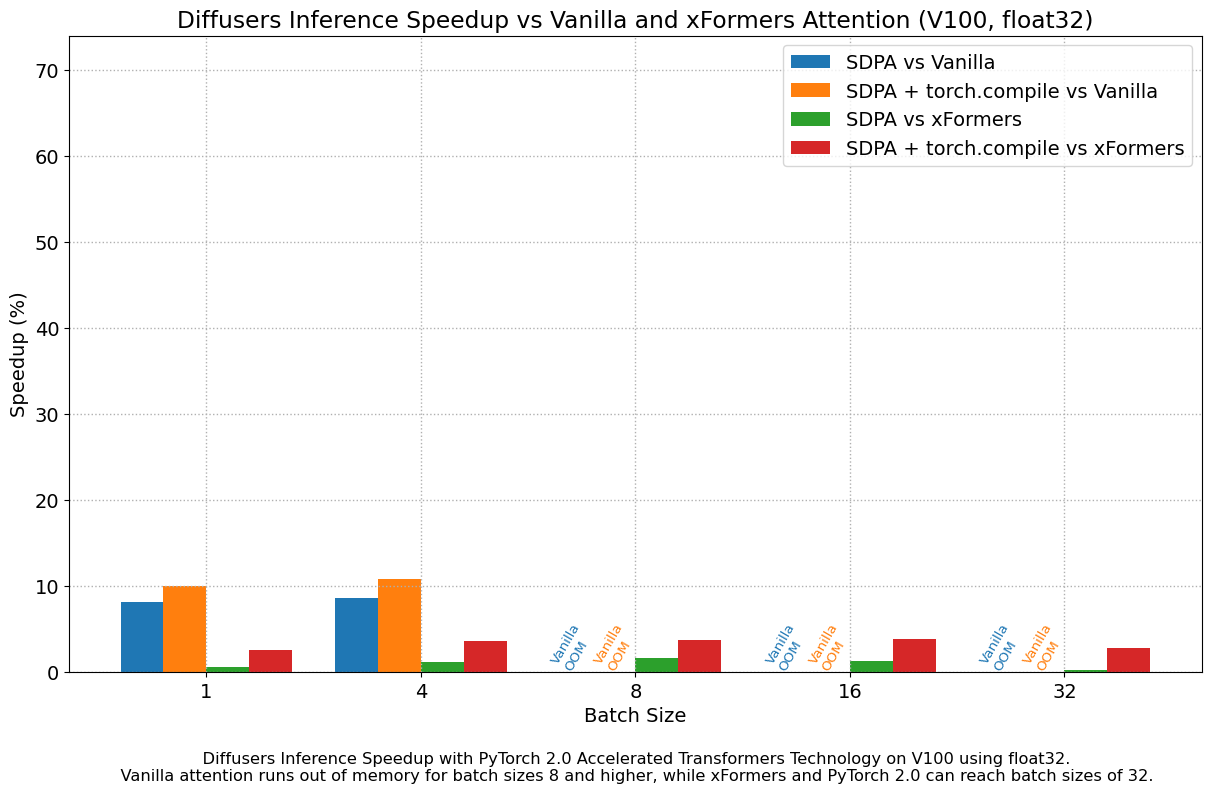
我们发现,即使不使用 torch.compile(),与 vanilla 注意力相比,性能也有非常显著的提升。开箱即用的 PyTorch 2.0 和 diffusers 安装在 A100 上带来了大约 50% 的加速,在 4090 GPU 上根据批量大小的不同,加速介于 35% 和 50% 之间。性能改进在 Ada (4090) 或 Ampere (A100) 等现代 CUDA 架构上更为显著,但对于仍在云服务中大量使用的旧架构,它们仍然非常显著。
除了更快的速度,PyTorch 2.0 中加速的 Transformer 实现允许使用更大的批量大小。单个 40GB A100 GPU 在批量大小为 10 时内存不足,而 24 GB 高端消费级显卡(如 3090 和 4090)无法一次生成 8 张图像。使用 PyTorch 2.0 和 diffusers,我们可以在 3090 和 4090 上实现 **48** 的批量大小,在 A100 上实现 **64** 的批量大小。这对于云服务和应用程序意义重大,因为它们可以一次高效地处理更多图像。
与 PyTorch 1.13.1 + xFormers 相比,新的加速 Transformer 实现仍然更快,并且无需额外的软件包或依赖项。在这种情况下,我们发现在 A100 或 T4 等数据中心卡上,速度适度提升了高达 2%,但在两代最新的消费级卡上表现出色:3090 上速度提升高达 20%,4090 上根据批量大小的不同,速度提升介于 10% 和 45% 之间。
当使用 torch.compile() 时,我们在之前的改进基础上额外获得了(通常)2% 到 3% 的性能提升。由于编译需要一些时间,这更适合面向用户的推理服务或训练。**更新**:当图中断最小时,torch.compile() 实现的改进要大得多,详情请参阅新章节。
float16 结果
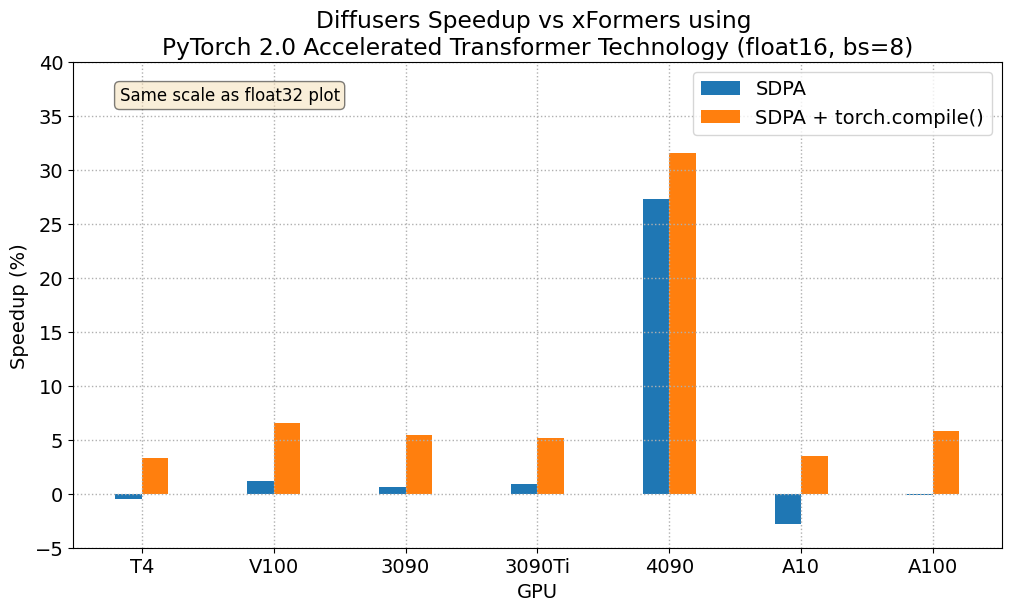
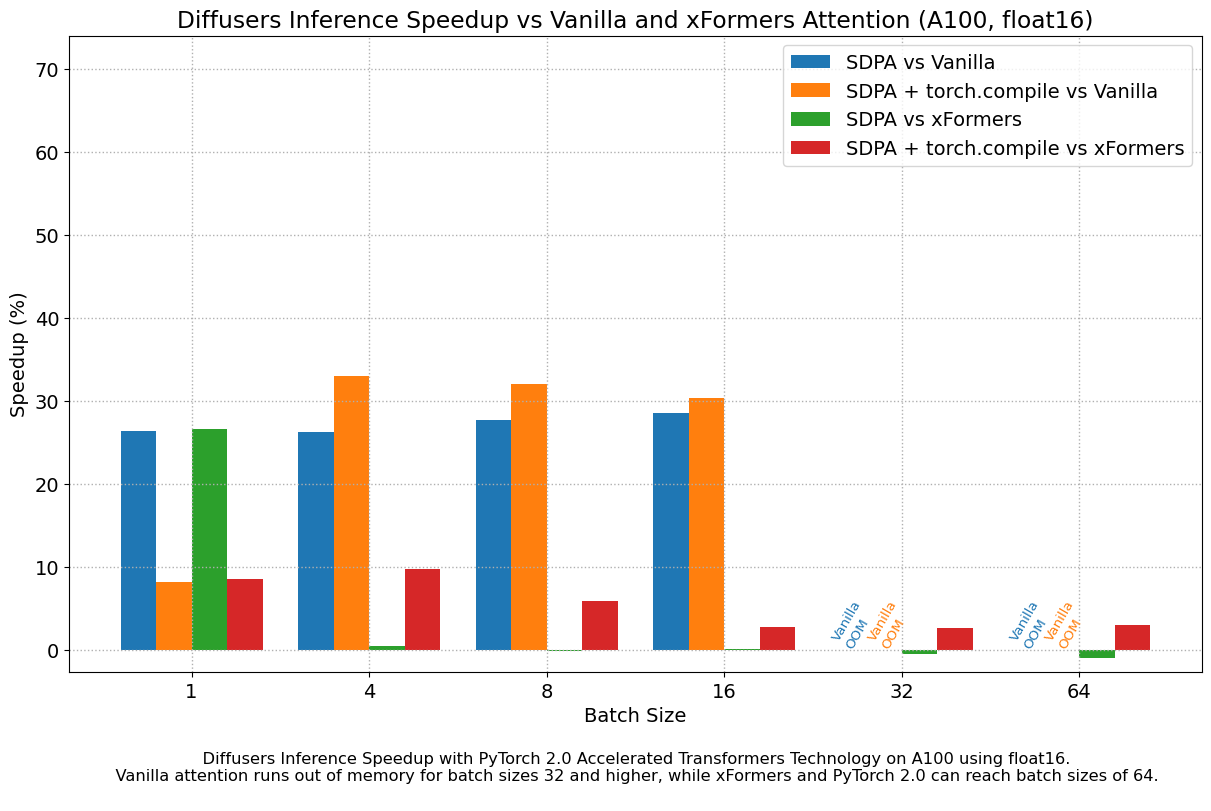
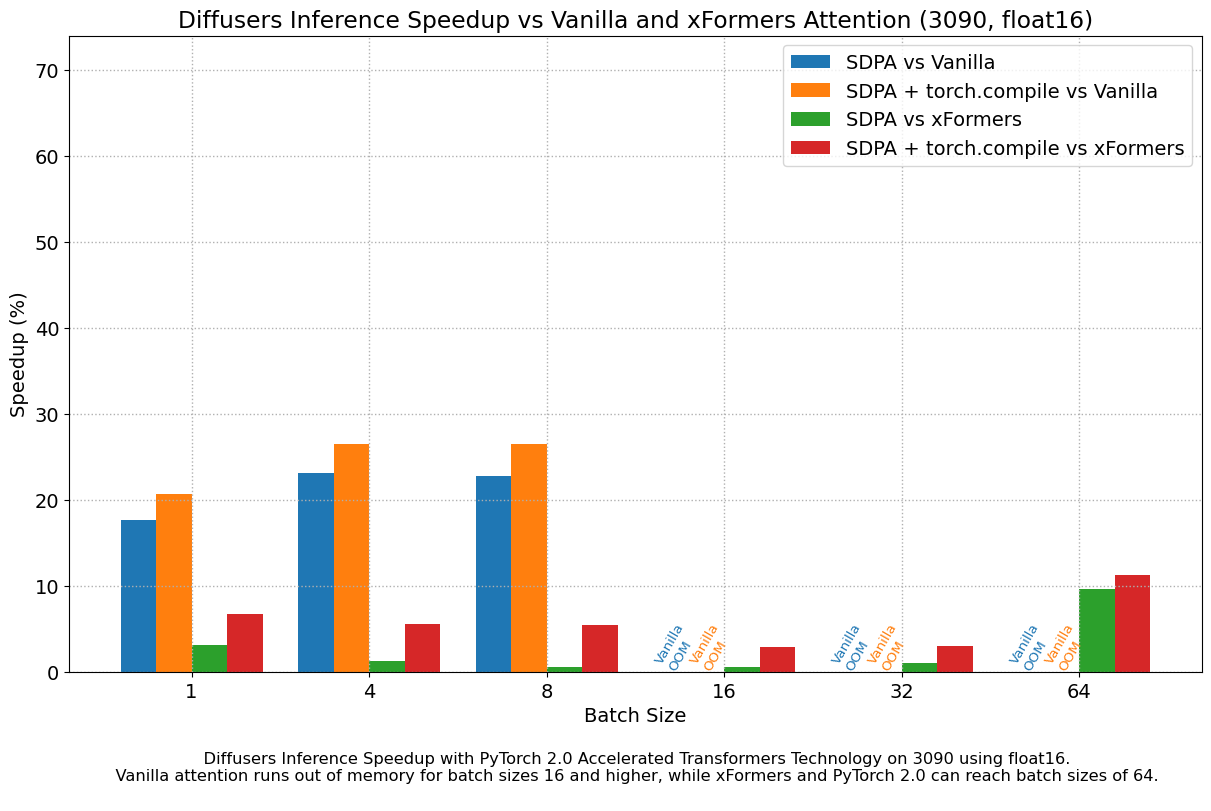
当我们考虑 float16 推理时,PyTorch 2.0 中加速 Transformer 实现的性能提升,在所有我们测试的 GPU 上,与标准注意力相比,介于 20% 到 28% 之间,但 4090 除外,它属于更现代的 Ada 架构。当使用 PyTorch 2.0 每晚版本时,这款 GPU 受益于显著的性能提升。至于优化的 SDPA 与 xFormers 相比,除了 4090,大多数 GPU 的结果通常持平。将 torch.compile() 添加到其中,将整体性能再提升了几个百分点。
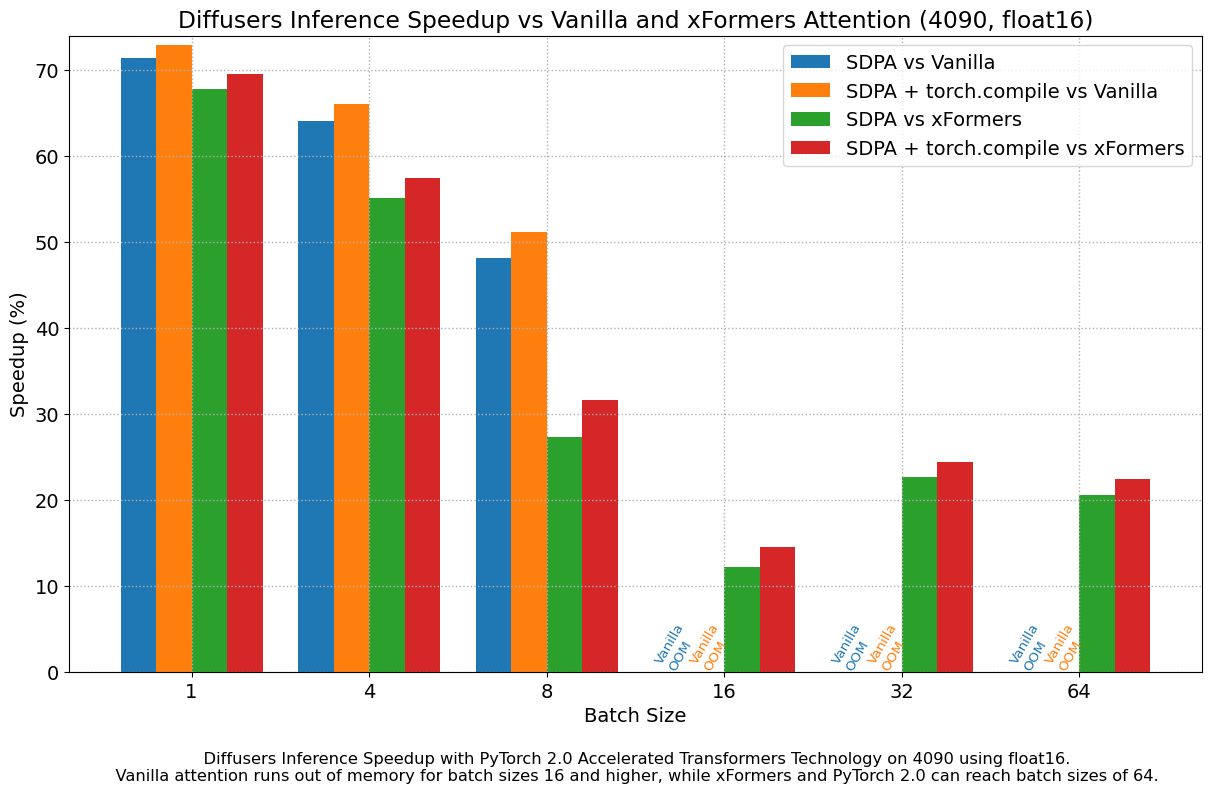
最小化图中断后 torch.compile() 的性能
在前面的章节中,我们看到使用 PyTorch 2.0 的加速 Transformer 实现相对于 PyTorch 的早期版本(无论是否使用 xFormers)提供了重要的性能改进。然而,torch.compile() 只带来了适度的边际改进。在 PyTorch 团队的帮助下,我们发现这些适度改进的原因是 diffusers 源代码中的某些操作导致了图中断,这阻止了 torch.compile() 充分利用图优化。
修复图中断后(详情请参见这些PR),我们测量了 torch.compile() 相对于 PyTorch 2 未编译版本的额外改进,并看到了非常重要的增量性能提升。下图是使用 2023 年 5 月 1 日下载的 PyTorch 2 每晚版本获得的结果,它显示了大多数工作负载的改进范围约为 13% 到 22%。对于现代 GPU 系列,性能提升更好,A100 的提升超过 30%。图中还有两个异常值。首先,我们看到 T4 在批量大小为 16 时性能下降,这给该卡带来了巨大的内存压力。另一方面,我们看到 A100 在批量大小仅为 1 时性能提升超过 100%,这很有趣,但并不代表具有如此大内存的 GPU 的实际使用情况——能够服务多个客户的更大批量大小通常对 A100 上的服务部署更有意义。
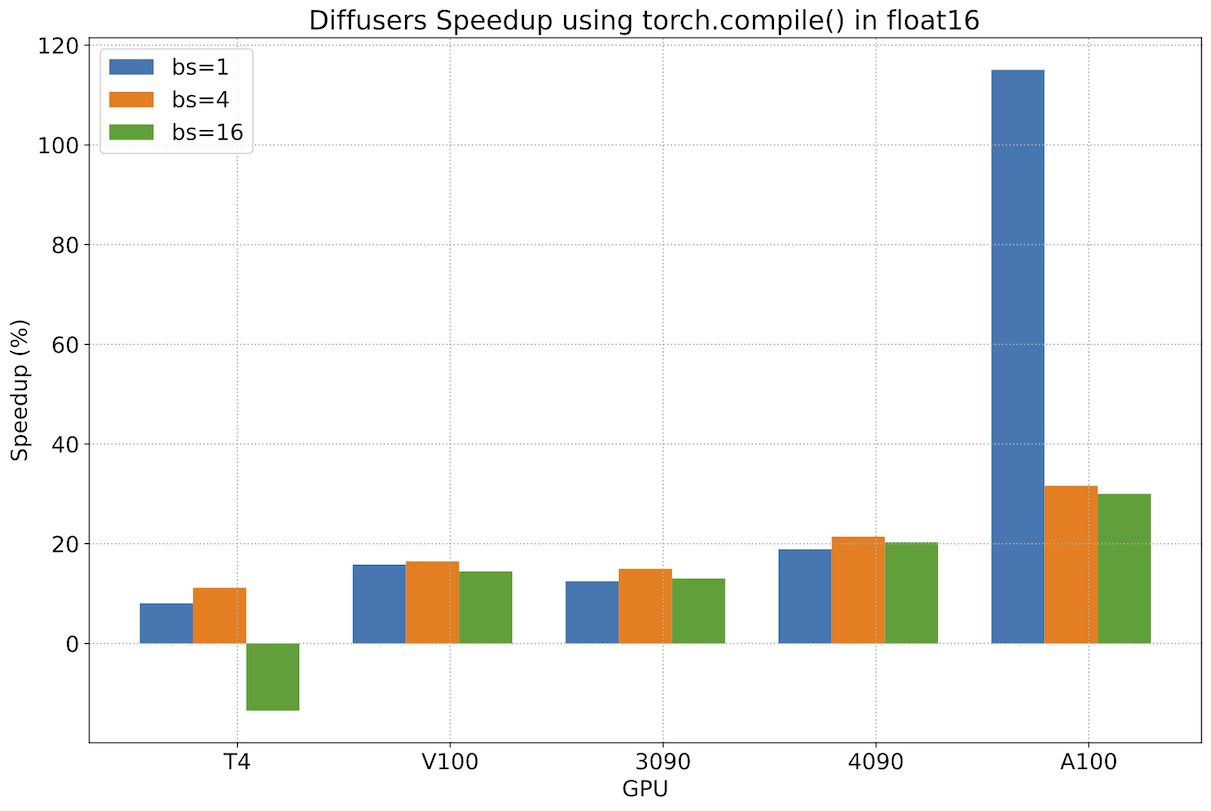
再次强调,这些性能提升是**额外**的,是在迁移到 PyTorch 2 并使用加速 Transformer 缩放点积注意力实现的基础上实现的。我们建议在生产环境中部署 diffusers 时使用 torch.compile()。
结论
PyTorch 2.0 带来了多项功能,可以优化基础 Transformer 块的关键组件,并且可以通过使用 torch.compile 进一步改进。这些优化为扩散模型带来了显著的内存和时间改进,并且不再需要安装第三方库。
要利用这些速度和内存改进,您只需升级到 PyTorch 2.0 并使用 diffusers >= 0.13.0。
有关更多示例和详细的基准测试数据,请参阅 PyTorch 2.0 与 Diffusers 文档。
致谢
作者感谢 PyTorch 团队开发出如此优秀的软件。