不规则张量运算符¶
高层概述¶
不规则张量运算符的目的是处理输入数据的某些维度“不规则”的情况,即给定维度中的每个连续行可能具有不同的长度。这类似于 PyTorch 中的 NestedTensor 实现 和 Tensorflow 中的 RaggedTensor 实现。
这种类型的输入有两个值得注意的例子:
推荐系统中的稀疏特征输入
可能输入到自然语言处理系统的批量分词句子。
不规则张量格式¶
不规则张量在 FBGEMM_GPU 中有效地表示为一个三张量对象。这三个张量是:Values(值)、MaxLengths(最大长度)和 Offsets(偏移量)。
Values(值)¶
Values 被定义为一个 2D 张量,其中包含不规则张量中的所有元素值,即 Values.numel() 是不规则张量中元素的数量。Values 中每行的大小从不规则张量中最小(最内层)维度子张量的最大公约数(不包括大小为 0 的张量)导出。
Offsets(偏移量)¶
Offsets 是张量列表,其中每个张量 Offsets[i] 表示列表中下一个张量 Offsets[i + 1] 值的分区索引。
例如,Offset[i] = [ 0, 3, 4 ] 表示当前维度 i 被分成两组,由索引边界 [0 , 3) 和 [3, 4) 表示。对于每个 Offsets[i],其中 0 <= i < len(Offests) - 1,Offsets[i][0] = 0,并且 Offsets[i][-1] = Offsets[i+1].length。
Offsets[-1] 指的是 Values 的外维度索引(行索引),即 offsets[-1] 将是 Values 本身的分区索引。因此,Offsets[-1] 张量以 0 开头,以 Values.size(0)(即 Values 的行数)结尾。
Max Lengths(最大长度)¶
MaxLengths 是一个整数列表,其中每个值 MaxLengths[i] 表示 Offsets[i] 中相应偏移量值之间的最大值
MaxLengths[i] = max( Offsets[i][j] - Offsets[i][j-1] | 0 < j < len(Offsets[i]) )
MaxLengths 中的信息用于执行从不规则张量到普通(稠密)张量的转换,其中它将用于确定张量稠密形式的形状。
不规则张量示例¶
下图显示了一个示例不规则张量,其中包含三个 2D 子张量,每个子张量具有不同的维度
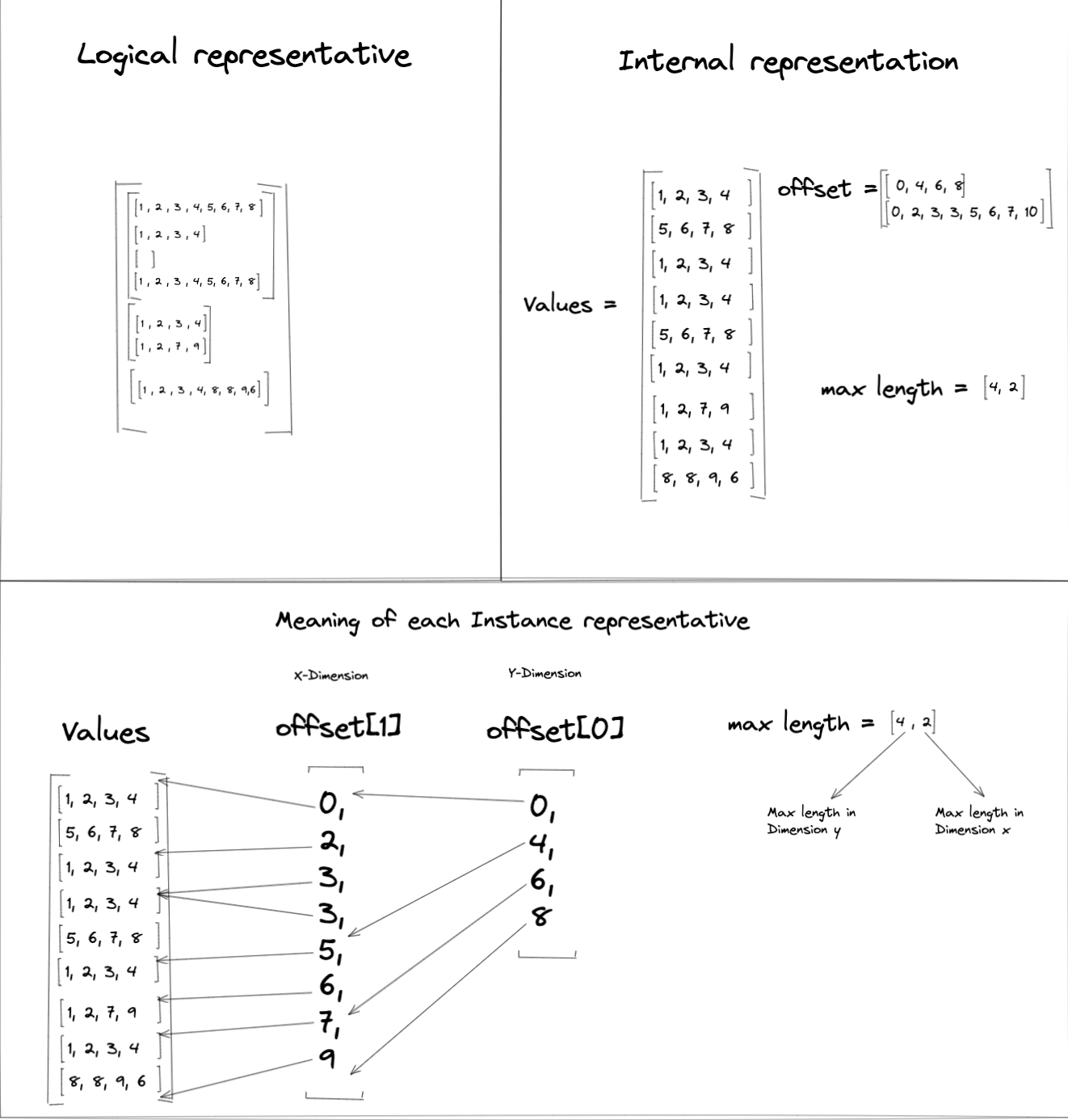
在此示例中,不规则张量最内层维度中行的尺寸为 8、4 和 0,因此 Values 中每行的元素数设置为 4(最大公约数)。这意味着 Values 的大小必须为 9 x 4,以便容纳不规则张量中的所有值。
由于示例不规则张量包含 2D 子张量,因此 Offsets 列表需要具有长度 2 才能创建分区索引。Offsets[0] 表示维度 0 的分区,Offsets[1] 表示维度 1 的分区。
示例不规则张量中的 MaxLengths 值为 [4 , 2]。MaxLengths[0] 从 Offsets[0] 范围 [4, 0) 导出,MaxLengths[1] 从 Offsets[1] 范围 [0, 2)(或 [7, 9],[3,5])导出。
下表显示了应用于 Values 张量的分区索引,以构建示例不规则张量的逻辑表示
|
|
|
对应的 |
|
|
对应的 |
|---|---|---|---|---|---|---|
|
|
组 1 |
|
|
组 1 |
|
|
组 2 |
|
||||
|
组 3 |
|
||||
|
组 4 |
|
||||
|
组 2 |
|
|
组 5 |
|
|
|
组 6 |
|
||||
|
组 3 |
|
|
组 7 |
|
不规则张量运算¶
在当前阶段,FBGEMM_GPU 仅支持不规则张量的元素级加法、乘法和转换运算。
算术运算¶
不规则张量的加法和乘法类似于 Hadamard 积,并且仅涉及不规则张量的 Values。例如:
因此,对不规则张量进行算术运算需要两个操作数具有相同的形状。换句话说,如果我们有不规则张量 \(A\)、\(X\)、\(B\) 和 \(C\),其中 \(C = AX + B\),则以下属性成立:
// MaxLengths are the same
C.maxlengths == A.maxlengths == X.maxlengths == B.maxlengths
// Offsets are the same
C.offsets == A.offsets == X.offsets == B.offsets
// Values are elementwise equal to the operations applied
C.values[i][j] == A.values[i][j] * X.values[i][j] + B.values[i][j]
转换运算¶
不规则到稠密¶
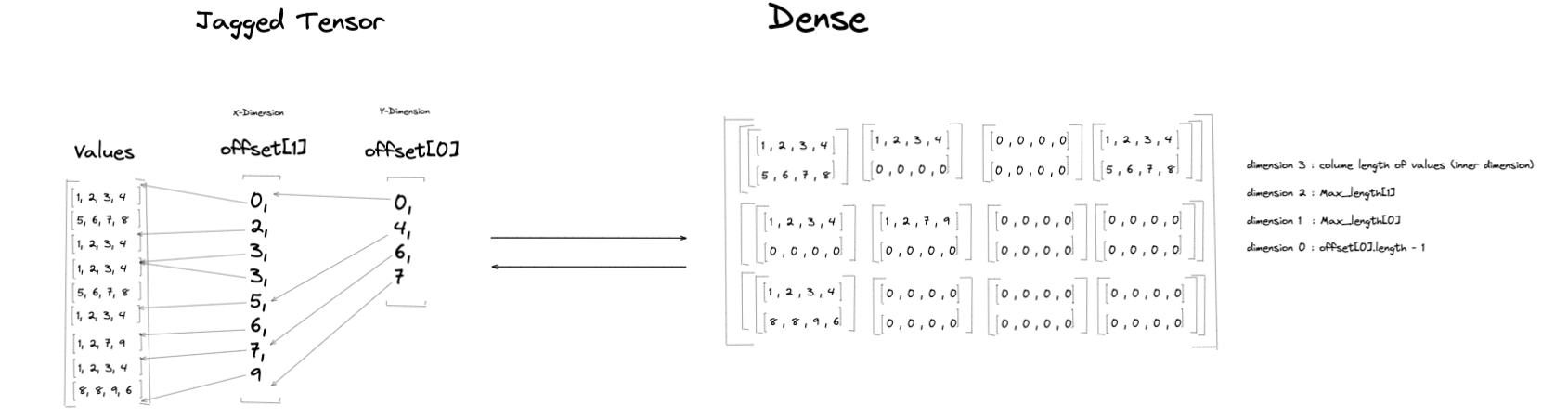
将不规则张量 \(J\) 转换为等效的稠密张量 \(D\) 从一个空的稠密张量开始。\(D\) 的形状基于 MaxLengths、Values 的内维度和 Offsets[0] 的长度。\(D\) 中的维度数是:
rank(D) = len(MaxLengths) + 2
\(D\) 中每个维度的维度大小为:
dim(i) = MaxLengths[i-1] // (0 < i < D.rank-1)
使用来自 不规则张量示例 的示例不规则张量,len(MaxLengths) = 2,因此等效稠密张量的秩(维度数)将为 4。示例不规则张量有两个偏移量张量:Offsets[0] 和 Offsets[1]。在转换过程中,Values 中的元素将根据 Offsets[0] 和 Offsets[1] 的分区索引中表示的范围加载到稠密张量上(请参阅 表格 以获取组到稠密表格中相应行的映射)
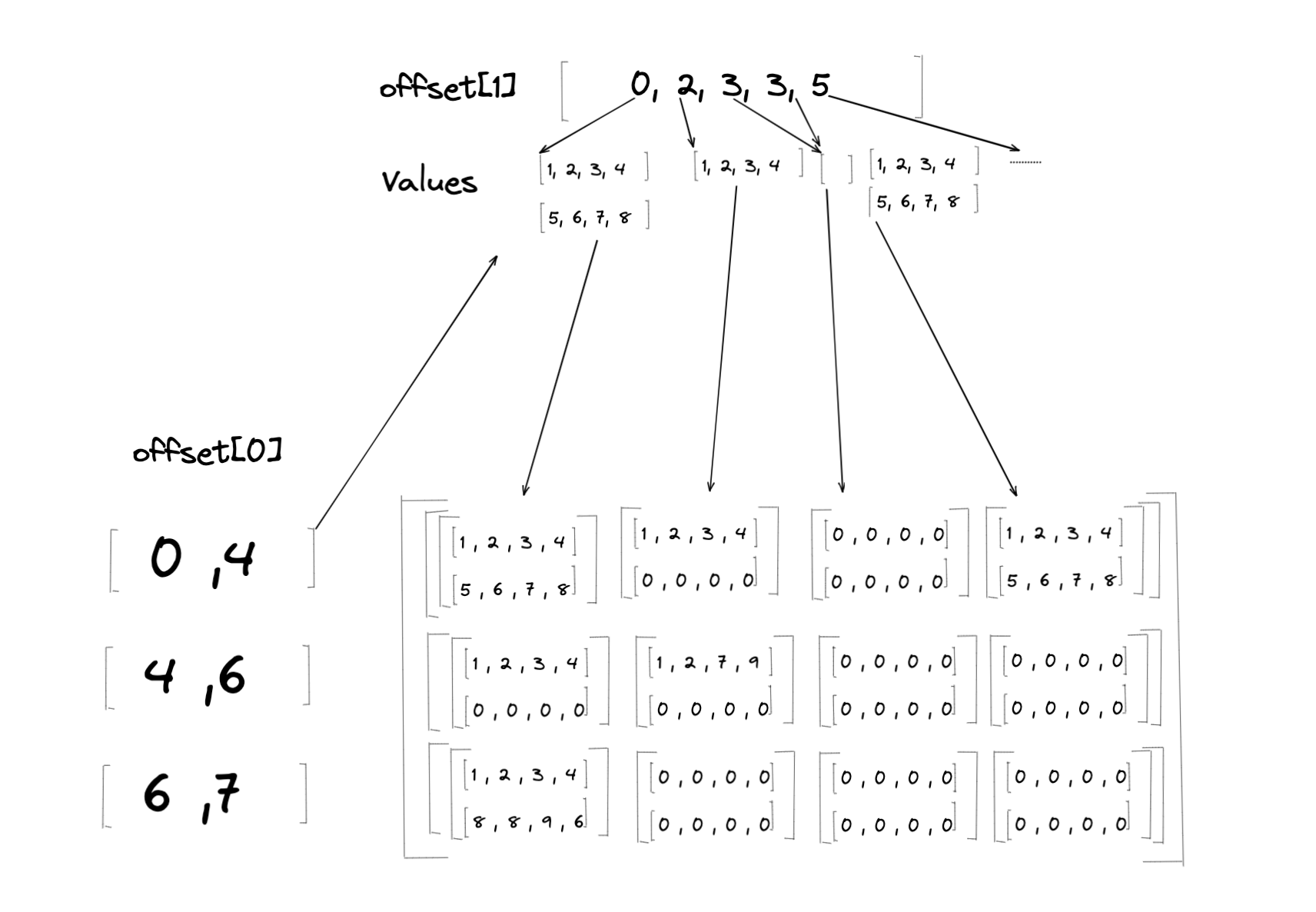
\(D\) 的某些部分将不会加载来自 \(J\) 的值,因为并非 Offsets[i] 中表示的每个分区范围的大小都等于 MaxLengths[i]。在这种情况下,这些部分将用填充值填充。在上面的示例中,填充值为 0。
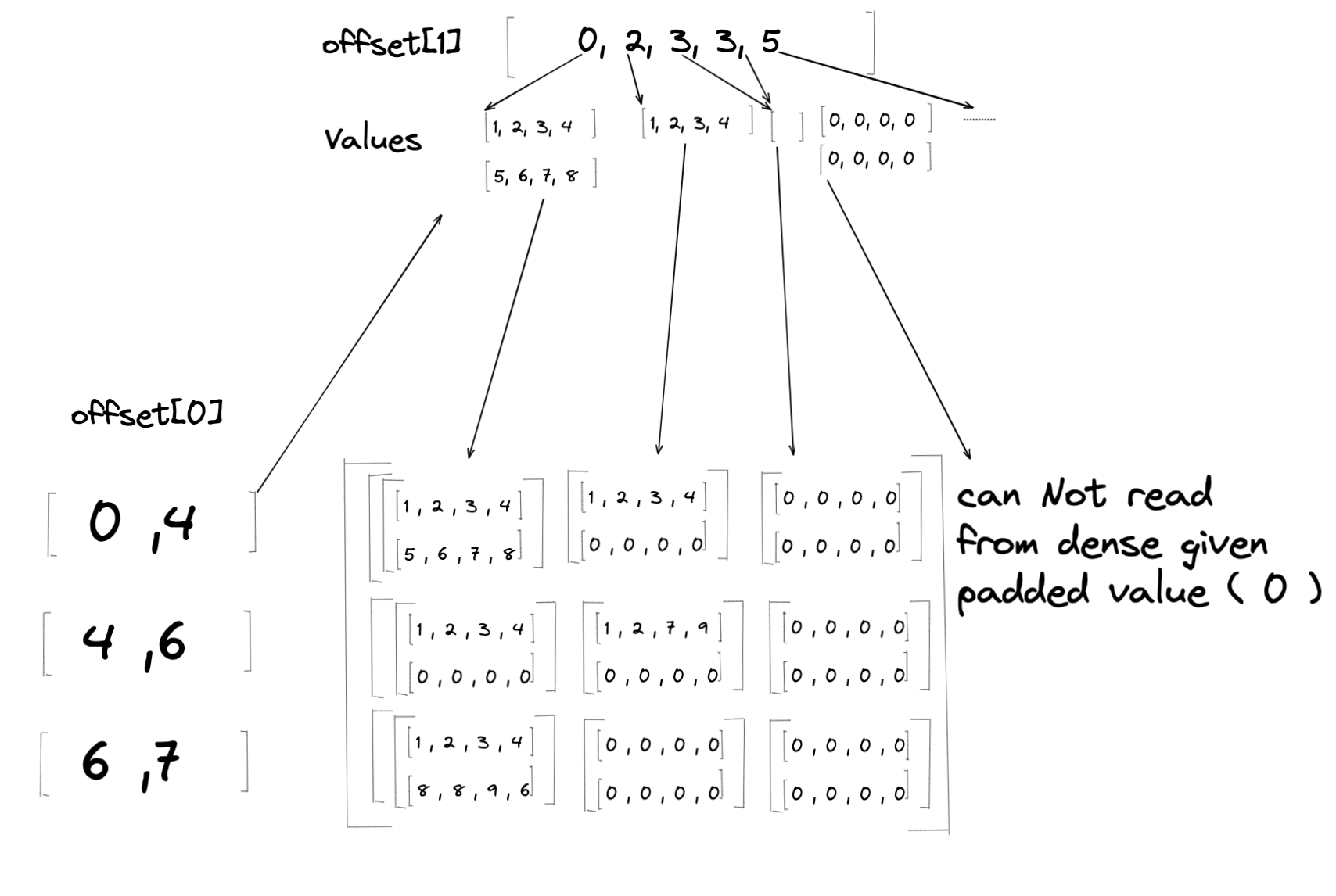
稠密到不规则¶
对于从稠密张量到不规则张量的转换,稠密张量中的值将加载到不规则张量的 Values 中。但是,给定的稠密张量可能与参考 Offsets 的形状不同。如果稠密张量的相关维度小于预期,则可能导致不规则张量无法读取相应的稠密位置。当这种情况发生时,我们将填充值赋给相应的 Values(见下文)
组合的算术 + 转换运算¶
在某些情况下,我们希望执行以下操作:
dense_tensor + jagged_tensor → dense_tensor (or jagged_tensor)
我们可以将此类操作分解为两个步骤:
转换运算 - 根据目标张量的期望格式,从不规则 → 稠密或稠密 → 不规则转换。转换后,操作数张量(无论是稠密还是不规则)应具有完全相同的形状。
算术运算 - 像往常一样对稠密或不规则张量执行算术运算。
