分布式自动微分设计¶
本笔记将介绍分布式自动微分的详细设计,并逐步介绍其内部机制。在继续之前,请确保您熟悉自动微分机制和分布式 RPC 框架。
背景¶
假设您有两个节点,并且有一个非常简单的模型分布在两个节点上。这可以使用torch.distributed.rpc 实现,如下所示
import torch
import torch.distributed.rpc as rpc
def my_add(t1, t2):
return torch.add(t1, t2)
# On worker 0:
t1 = torch.rand((3, 3), requires_grad=True)
t2 = torch.rand((3, 3), requires_grad=True)
# Perform some computation remotely.
t3 = rpc.rpc_sync("worker1", my_add, args=(t1, t2))
# Perform some computation locally based on remote result.
t4 = torch.rand((3, 3), requires_grad=True)
t5 = torch.mul(t3, t4)
# Compute some loss.
loss = t5.sum()
分布式自动微分背后的主要动机是能够使用我们计算出的loss 对此类分布式模型运行反向传播,并为所有需要梯度的张量记录相应的梯度。
正向传播过程中的自动微分记录¶
PyTorch 在正向传播过程中构建自动微分图,该图用于执行反向传播。有关更多详细信息,请参见自动微分如何编码历史记录。
对于分布式自动微分,我们需要跟踪正向传播过程中的所有 RPC,以确保反向传播以适当的方式执行。为此,我们在执行 RPC 时将send 和recv 函数附加到自动微分图。
send函数附加到 RPC 的源,其输出边指向 RPC 输入张量的自动微分函数。反向传播期间此函数的输入是从目标接收到的,作为相应recv函数的输出。recv函数附加到 RPC 的目标,其输入从使用输入张量在目标上执行的运算符中检索。此函数的输出梯度在反向传播期间发送回源节点,发送给相应的send函数。每个
send-recv对都被分配一个全局唯一的autograd_message_id,以唯一地标识该对。这有助于在反向传播期间查找远程节点上的相应函数。对于RRef,无论何时调用
torch.distributed.rpc.RRef.to_here(),我们都会为所涉及的张量附加一个合适的send-recv对。
例如,这是我们上面示例的自动微分图的样子(为简单起见,排除了 t5.sum())
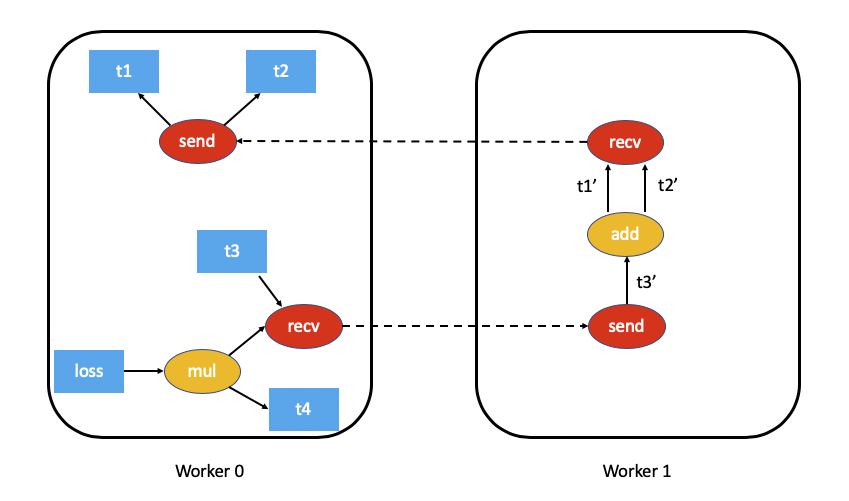
分布式自动微分上下文¶
每个使用分布式自动微分的正向传播和反向传播都分配了一个唯一的torch.distributed.autograd.context,并且该上下文具有全局唯一的autograd_context_id。根据需要,每个节点都会创建此上下文。
该上下文用于以下目的
多个运行分布式反向传播的节点可能会在同一个张量上累积梯度,因此在有机会运行优化器之前,该张量的
.grad字段将包含来自各种分布式反向传播的梯度。这类似于在本地多次调用torch.autograd.backward()。为了提供一种分离每个反向传播梯度的方法,梯度会在每个反向传播的torch.distributed.autograd.context中累积。在正向传播期间,我们将每个自动微分传递的
send和recv函数存储在此上下文中。这确保我们持有对自动微分图中适当节点的引用,以使其保持活动状态。除此之外,在反向传播期间,可以轻松查找合适的send和recv函数。通常,我们还使用此上下文存储每个分布式自动微分传递的一些元数据。
从用户的角度来看,自动微分上下文设置如下
import torch.distributed.autograd as dist_autograd
with dist_autograd.context() as context_id:
loss = model.forward()
dist_autograd.backward(context_id, loss)
请注意,您的模型的前向传播必须在分布式自动微分上下文管理器中调用,因为需要有效的上下文才能确保所有 send 和 recv 函数都正确存储,以便在所有参与节点上运行反向传播。
分布式反向传播¶
在本节中,我们将概述在分布式反向传播期间准确计算依赖项的挑战,并描述两种算法(具有权衡)来执行分布式反向传播。
计算依赖项¶
考虑以下在单台机器上运行的代码片段
import torch
a = torch.rand((3, 3), requires_grad=True)
b = torch.rand((3, 3), requires_grad=True)
c = torch.rand((3, 3), requires_grad=True)
d = a + b
e = b * c
d.sum.().backward()
以下是上述代码的自动微分图
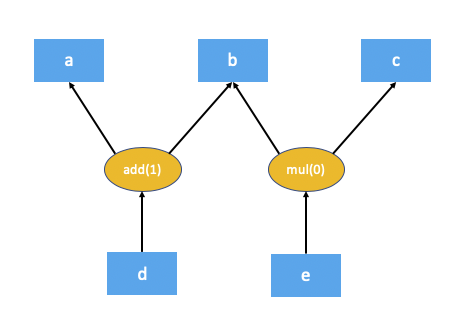
自动微分引擎作为反向传播的一部分执行的第一个步骤是计算自动微分图中每个节点的依赖项数量。这有助于自动微分引擎了解图中的哪个节点已准备好执行。add(1) 和 mul(0) 的方括号中的数字表示依赖项的数量。如您所见,这意味着在反向传播期间,add 节点需要 1 个输入,而 mul 节点不需要任何输入(换句话说,不需要执行)。本地自动微分引擎通过从根节点(在本例中为 d)遍历图来计算这些依赖项。
自动微分图中的某些节点可能不会在反向传播中执行这一事实给分布式自动微分带来了挑战。考虑使用 RPC 的以下代码片段。
import torch
import torch.distributed.rpc as rpc
a = torch.rand((3, 3), requires_grad=True)
b = torch.rand((3, 3), requires_grad=True)
c = torch.rand((3, 3), requires_grad=True)
d = rpc.rpc_sync("worker1", torch.add, args=(a, b))
e = rpc.rpc_sync("worker1", torch.mul, args=(b, c))
loss = d.sum()
上述代码的关联自动微分图将是
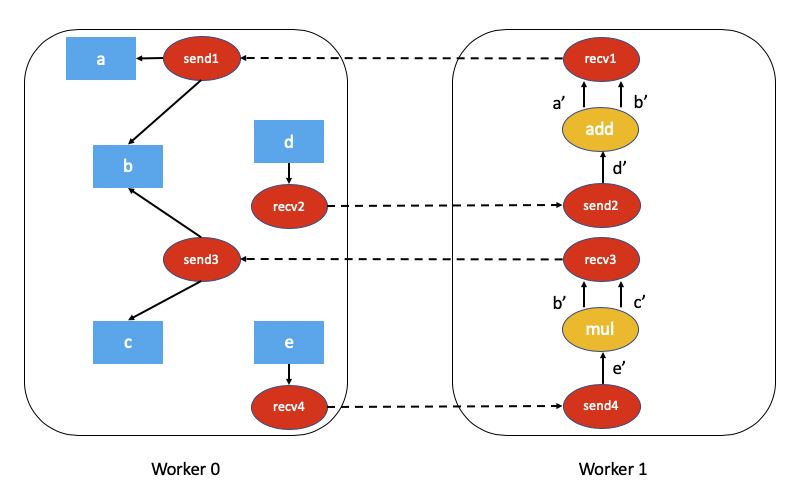
计算此分布式自动微分图的依赖项要困难得多,需要一些开销(无论是计算还是网络通信)。
为了提高性能敏感型应用程序的性能,我们可以通过假设每个 send 和 recv 函数在反向传播中都是有效的来避免大量的开销(大多数应用程序不执行未使用的 RPC)。这简化了分布式自动微分算法,效率更高,但以应用程序需要了解限制为代价。该算法被称为 FAST 模式算法,下面将详细介绍。
在一般情况下,可能并非每个 send 和 recv 函数在反向传播中都是有效的。为了解决这个问题,我们提出了一种 SMART 模式算法,将在后面的章节中介绍。请注意,目前只实现了 FAST 模式算法。
FAST 模式算法¶
该算法的关键假设是,当我们运行反向传播时,每个 send 函数都具有 1 个依赖项。换句话说,我们假设我们将通过 RPC 从另一个节点接收梯度。
该算法如下
我们从具有反向传播根节点的 worker 开始(所有根节点必须是本地的)。
查找当前 分布式自动微分上下文 的所有
send函数。从提供的根节点和我们检索到的所有
send函数开始,在本地计算依赖项。计算完依赖项后,使用提供的根节点启动本地自动微分引擎。
当自动微分引擎执行
recv函数时,recv函数会通过 RPC 将输入梯度发送到相应的 worker。每个recv函数都知道目标 worker ID,因为它是在前向传播期间记录的。recv函数还会将autograd_context_id和autograd_message_id发送到远程主机。当远程主机接收到此请求时,我们使用
autograd_context_id和autograd_message_id来查找相应的send函数。如果这是 worker 第一次收到针对给定
autograd_context_id的请求,它将按照上述 1-3 点中的说明在本地计算依赖项。然后将步骤 6 中检索到的
send函数排队,以便在该 worker 的本地自动微分引擎上执行。最后,我们不会在 Tensor 的
.grad字段上累积梯度,而是根据每个 分布式自动微分上下文 分别累积梯度。梯度存储在Dict[Tensor, Tensor]中,它本质上是 Tensor 到其关联梯度的映射,可以使用get_gradients()API 检索此映射。
例如,使用分布式自动微分的完整代码如下
import torch
import torch.distributed.autograd as dist_autograd
import torch.distributed.rpc as rpc
def my_add(t1, t2):
return torch.add(t1, t2)
# On worker 0:
# Setup the autograd context. Computations that take
# part in the distributed backward pass must be within
# the distributed autograd context manager.
with dist_autograd.context() as context_id:
t1 = torch.rand((3, 3), requires_grad=True)
t2 = torch.rand((3, 3), requires_grad=True)
# Perform some computation remotely.
t3 = rpc.rpc_sync("worker1", my_add, args=(t1, t2))
# Perform some computation locally based on remote result.
t4 = torch.rand((3, 3), requires_grad=True)
t5 = torch.mul(t3, t4)
# Compute some loss.
loss = t5.sum()
# Run the backward pass.
dist_autograd.backward(context_id, [loss])
# Retrieve the gradients from the context.
dist_autograd.get_gradients(context_id)
带有依赖项的分布式自动微分图如下(为简单起见,已排除 t5.sum())
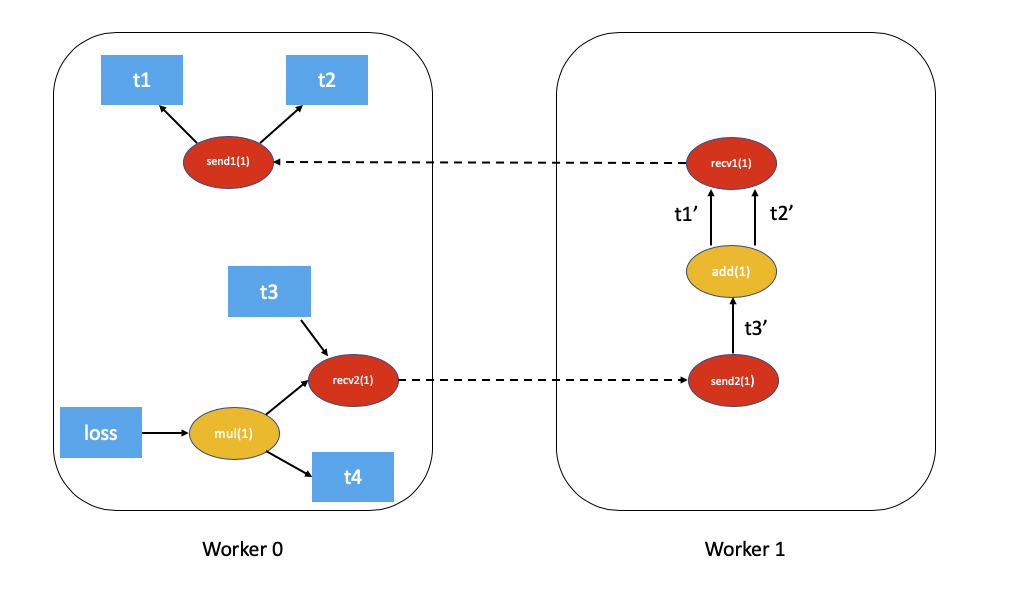
将 FAST 模式算法 应用于上述示例,结果如下
在
Worker 0上,我们从根节点loss和send1开始计算依赖项。因此,send1被标记为具有 1 个依赖项,而Worker 0上的mul被标记为具有 1 个依赖项。现在,我们在
Worker 0上启动本地自动微分引擎。我们首先执行mul函数,并将它的输出在自动微分上下文中累积为t4的梯度。然后,我们执行recv2,它将梯度发送到Worker 1。由于这是
Worker 1第一次听到关于此反向传播的信息,因此它开始依赖项计算,并为send2、add和recv1适当地标记依赖项。接下来,我们将
send2排队到Worker 1的本地自动微分引擎上,它反过来会执行add和recv1。当执行
recv1时,它会将梯度发送到Worker 0。由于
Worker 0已经计算了此反向传播的依赖项,因此它只需在本地排队并执行send1。最后,
t1、t2和t4的梯度在 分布式自动微分上下文 中累积。
分布式优化器¶
DistributedOptimizer 的工作方式如下
接收要优化的远程参数列表 (
RRef)。这些也可以是包装在本地RRef中的本地参数。接收一个
Optimizer类作为要对所有不同的RRef所有者运行的本地优化器。分布式优化器在每个 worker 节点上创建一个本地
Optimizer实例,并保存指向它们的RRef。当调用
torch.distributed.optim.DistributedOptimizer.step()时,分布式优化器使用 RPC 在相应的远程 worker 上远程执行所有本地优化器。必须将分布式自动微分context_id作为输入提供给torch.distributed.optim.DistributedOptimizer.step()。本地优化器使用此 ID 来应用存储在相应上下文中的梯度。如果多个并发分布式优化器正在 worker 上更新相同的参数,则这些更新会通过锁进行序列化。
简单的端到端示例¶
将所有这些整合在一起,以下是一个使用分布式自动微分和分布式优化器的简单端到端示例。如果将代码放在名为“dist_autograd_simple.py”的文件中,则可以使用命令 MASTER_ADDR="localhost" MASTER_PORT=29500 python dist_autograd_simple.py 运行它。
import torch
import torch.multiprocessing as mp
import torch.distributed.autograd as dist_autograd
from torch.distributed import rpc
from torch import optim
from torch.distributed.optim import DistributedOptimizer
def random_tensor():
return torch.rand((3, 3), requires_grad=True)
def _run_process(rank, dst_rank, world_size):
name = "worker{}".format(rank)
dst_name = "worker{}".format(dst_rank)
# Initialize RPC.
rpc.init_rpc(
name=name,
rank=rank,
world_size=world_size
)
# Use a distributed autograd context.
with dist_autograd.context() as context_id:
# Forward pass (create references on remote nodes).
rref1 = rpc.remote(dst_name, random_tensor)
rref2 = rpc.remote(dst_name, random_tensor)
loss = rref1.to_here() + rref2.to_here()
# Backward pass (run distributed autograd).
dist_autograd.backward(context_id, [loss.sum()])
# Build DistributedOptimizer.
dist_optim = DistributedOptimizer(
optim.SGD,
[rref1, rref2],
lr=0.05,
)
# Run the distributed optimizer step.
dist_optim.step(context_id)
def run_process(rank, world_size):
dst_rank = (rank + 1) % world_size
_run_process(rank, dst_rank, world_size)
rpc.shutdown()
if __name__ == '__main__':
# Run world_size workers
world_size = 2
mp.spawn(run_process, args=(world_size,), nprocs=world_size)
