PyTorch/XLA SPMD 用户指南¶
在本用户指南中,我们将讨论 GSPMD 如何集成到 PyTorch/XLA 中,并提供设计概述以说明 SPMD 分片注释 API 及其构造的工作原理。然后,我们提供了一系列参考示例供用户尝试。
什么是 PyTorch/XLA SPMD?¶
GSPMD 是一个用于常见机器学习工作负载的自动并行化系统。XLA 编译器将根据用户提供的分片提示,将单设备程序转换为具有适当集体通信的分区程序。此功能允许开发人员编写 PyTorch 程序,就像它们在一个大型设备上一样,无需任何自定义分片计算操作和/或集体通信来进行扩展。
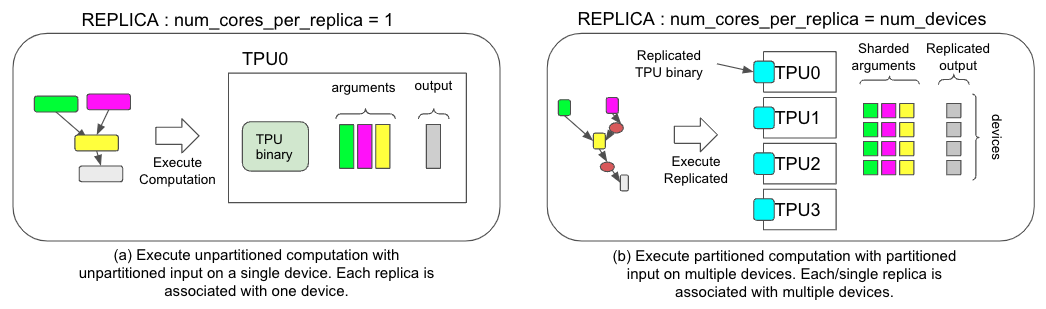
*图 1. 两种不同执行策略的比较,(a) 用于非 SPMD 和 (b) 用于 SPMD。*
为了在 PyTorch/XLA 中支持 GSPMD,我们引入了新的执行模式。在 GSPMD 之前,PyTorch/XLA 中的执行模式假设多个模型副本,每个副本都有一个内核(图 1.a)。如上所示,这种执行模式适用于数据并行框架,例如流行的 PyTorch 分布式数据并行 (DDP) 或完全分片数据并行 (FSDP),但也受到限制,因为副本只能驻留在一个设备内核上进行执行。PyTorch/XLA SPMD 引入了一种新的执行模式,该模式假设一个具有多个内核的副本(图 1.b),允许副本跨多个设备内核运行。这种转变为更好的大型模型训练性能解锁了更高级的并行策略。
PyTorch/XLA SPMD 在新的 PJRT 运行时上可用。要启用 PyTorch/XLA SPMD 执行模式,用户必须调用 [use_spmd() API](https://github.com/pytorch/xla/blob/b8b484515a97f74e013dcf38125c44d53a41f011/torch_xla/runtime.py#L214)。
import torch_xla.runtime as xr
# Enable PyTorch/XLA SPMD execution mode.
xr.use_spmd()
assert xr.is_spmd() == True
需要注意的是,SPMD 替换了任何现有的并行机制,包括 DDP 和 FSDP。用户不能混合两种不同的执行模式(SPMD 和非 SPMD),在本指南的后面,我们将介绍如何使用 SPMD 注释执行 DDP 和 FSDP。
此外,此版本的 SPMD 目前仅在 Google Cloud TPU 上进行了测试和优化。GPU 支持和优化将在 2.2 版本中提供。
PyTorch/XLA SPMD 设计概述¶
简单示例和分片注释 API¶
用户可以使用 mark_sharding API(源代码)对原生 PyTorch 张量进行注释。它以 torch.Tensor 作为输入,并返回 XLAShardedTensor 作为输出。
def mark_sharding(t: Union[torch.Tensor, XLAShardedTensor], mesh: Mesh, partition_spec: Tuple[Union[int, None]]) -> XLAShardedTensor
调用 mark_sharding API 会接收用户定义的逻辑 网格 和 分区规范,并为 XLA 编译器生成分片注释。分片规范附加到 XLATensor。以下是一个来自 [RFC] 的简单使用示例,说明分片注释 API 如何工作
import numpy as np
import torch
import torch_xla.core.xla_model as xm
import torch_xla.runtime as xr
import torch_xla.distributed.spmd as xs
from torch_xla.distributed.spmd import Mesh
# Enable XLA SPMD execution mode.
xr.use_spmd()
# Device mesh, this and partition spec as well as the input tensor shape define the individual shard shape.
mesh_shape = (2, 4)
num_devices = xr.global_runtime_device_count()
device_ids = np.array(range(num_devices))
mesh = Mesh(device_ids, mesh_shape, ('x', 'y'))
t = torch.randn(8, 4).to(xm.xla_device())
# Mesh partitioning, each device holds 1/8-th of the input
partition_spec = (0, 1)
m1_sharded = xs.mark_sharding(t, mesh, partition_spec)
assert isinstance(m1_sharded, XLAShardedTensor) == True
我们可以注释 PyTorch 程序中的不同张量以启用不同的并行技术,如下面的注释中所述
# Sharding annotate the linear layer weights.
model = SimpleLinear().to(xm.xla_device())
xs.mark_sharding(model.fc1.weight, mesh, partition_spec)
# Training loop
model.train()
for step, (data, target) in enumerate(loader):
# Assumes `loader` returns data, target on XLA device
optimizer.zero_grad()
# Sharding annotate input data, we can shard any input
# dimensions. Sharidng the batch dimension enables
# in data parallelism, sharding the feature dimension enables
# spatial partitioning.
xs.mark_sharding(data, mesh, partition_spec)
ouput = model(data)
loss = loss_fn(output, target)
optimizer.step()
xm.mark_step()
PyTorch/XLA 代码库 中提供了更完整的单元测试用例和集成测试示例。
网格¶
对于给定的设备集群,物理网格是互连拓扑的表示。
我们基于此拓扑推导出逻辑网格,以创建设备子组,这些子组可用于对模型中张量的不同轴进行分区。
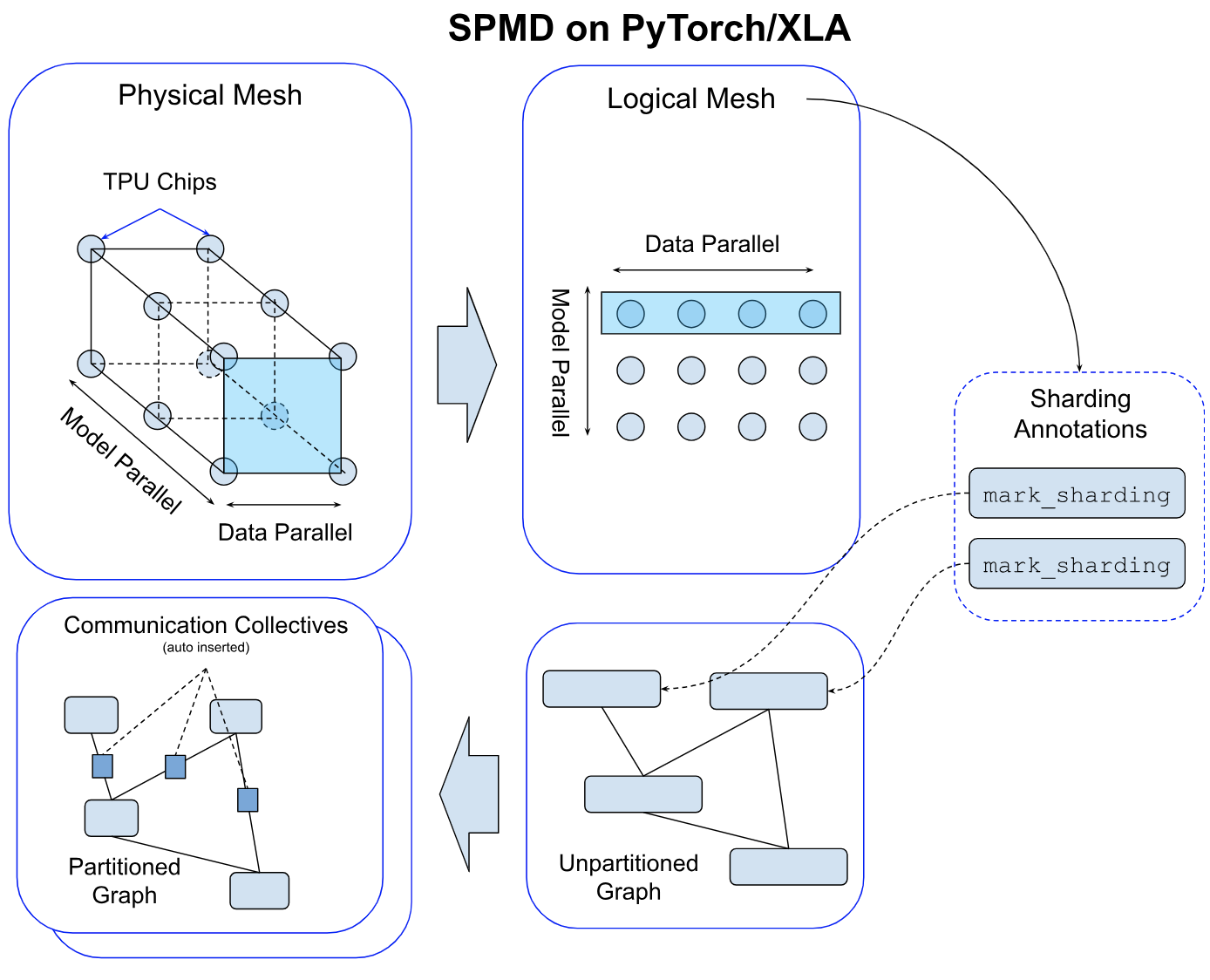
我们使用 网格 API 对逻辑网格进行抽象。逻辑网格的轴可以命名。以下是一个示例
import torch_xla.runtime as xr
from torch_xla.distributed.spmd import Mesh
# Assuming you are running on a TPU host that has 8 devices attached
num_devices = xr.global_runtime_device_count()
# mesh shape will be (4,2) in this example
mesh_shape = (num_devices // 2, 2)
device_ids = np.array(range(num_devices))
# axis_names 'x' nad 'y' are optional
mesh = Mesh(device_ids, mesh_shape, ('x', 'y'))
mesh.get_logical_mesh()
>> array([[0, 1],
[2, 3],
[4, 5],
[6, 7]])
mesh.shape()
>> OrderedDict([('x', 4), ('y', 2)])
一般而言,SPMD 程序应创建一个网格并在所有分片中重复使用它,以确保平铺分配与预期分片策略一致。通过操作下面进一步描述的分区规范,相同的网格可用于不同形状和分片的张量。
混合网格¶
网格很好地抽象了物理设备网格的构建方式。用户可以使用逻辑网格以任何形状和顺序排列设备。但是,可以基于物理拓扑定义一个性能更高的网格,尤其是在涉及数据中心网络 (DCN) 跨切片连接时。HybridMesh 创建一个网格,在这样的多切片环境中开箱即用地提供良好的性能。它接受 ici_mesh_shape 和 dcn_mesh_shape,它们分别表示内部和外部网络的逻辑网格形状。
from torch_xla.distributed.spmd import HybridMesh
# This example is assuming 2 slices of v4-8.
# - ici_mesh_shape: shape of the logical mesh for inner connected devices.
# - dcn_mesh_shape: shape of logical mesh for outer connected devices.
ici_mesh_shape = (1, 4, 1) # (data, fsdp, tensor)
dcn_mesh_shape = (2, 1, 1)
mesh = HybridMesh(ici_mesh_shape, dcn_mesh_shape, ('data','fsdp','tensor'))
print(mesh.shape())
>> OrderedDict([('data', 2), ('fsdp', 4), ('tensor', 1)])
分区规范¶
partition_spec 与输入张量具有相同的秩。每个维度都描述了相应的输入张量维度如何在设备网格(由 mesh_shape 逻辑定义)上进行分片。partition_spec 是 device_mesh 维度 index 或 None 的元组。如果相应的网格维度已命名,则索引可以是 int 或 str。这指定了每个输入秩如何进行分片(index 到 mesh_shape)或复制(None)。
# Provide optional mesh axis names and use them in the partition spec
mesh = Mesh(device_ids, (4, 2), ('data', 'model'))
partition_spec = ('model', 'data')
xs.mark_sharding(input_tensor, mesh, partition_spec)
我们支持原始 GSPMD 论文中描述的所有三种类型分片。例如,可以这样指定部分复制
# Provide optional mesh axis names and use them in the partition spec
mesh = Mesh(device_ids, (2, 2, 2), ('x', 'y', 'z'))
# evenly shard across x and z and replicate among y
partition_spec = ('x', 'z') # equivalent to ('x', None, 'z')
xs.mark_sharding(input_tensor, mesh, partition_spec)
分区规范使相同的网格可用于不同的张量形状和所需的分片策略。以下示例使用 3D 网格演示了这一点
# Create a 3-D mesh of 8 devices with logical dimensions replica, fsdp, and
# tensor
mesh = Mesh(device_ids, (2, 2, 2), ('replica', 'fsdp', 'tensor'))
# A 2D tensor can be sharded along the fsdp and tensor axes and replicated
# along the replica axis by omitting `replica` from the partition spec.
two_d_partially_replicated = torch.randn(64, 64, device='xla')
xs.mark_sharding(two_d_partially_replicated, mesh, ('fsdp', 'tensor'))
# A 2D tensor can be sharded across all dimensions by combining, for example,
# the replica and fsdp mesh axes using a tuple
two_d_fully_sharded = torch.randn(64, 64, device='xla')
xs.mark_sharding(two_d_fully_sharded, mesh, (('replica', 'fsdp'), 'tensor'))
# A 4D tensor can be sharded along up to three of its axes using the 3D mesh
four_d = torch.randn(64, 64, 64, 64, device='xla')
xs.mark_sharding(four_d, ('replica', 'fsdp', None, 'tensor'))
XLAShardedTensor¶
XLAShardedTensor [RFC] 的主要用例是使用分片规范对原生 torch.tensor(在单个设备上)进行注释。注释会立即进行,但张量的实际分片会延迟,因为计算是惰性执行的,除了输入张量,它们会立即进行分片。一旦张量被注释并封装在 XLAShardedTensor 中,它就可以作为 torch.Tensor 传递给现有的 PyTorch 操作和 nn.Module 层。这对于确保相同的 PyTorch 层和张量操作可以与 XLAShardedTensor 结合在一起非常重要。这意味着用户无需为分片计算重写现有的操作和模型代码。也就是说,XLAShardedTensor 将满足以下要求
XLAShardedTensor是torch.Tensor的子类,可直接与原生 torch 操作和module.layers一起使用。我们使用__torch_dispatch__将XLAShardedTensor发送到 XLA 后端。PyTorch/XLA 检索附加的分片注释以跟踪图并调用 XLA SPMDPartitioner。在内部,
XLAShardedTensor(及其global_tensor输入)由XLATensor支持,并使用一个特殊的数据结构来保存对分片设备数据的引用。在延迟执行后,分片张量可能会被收集并在主机上请求时(例如,打印全局张量的值)重新物化回主机作为global_tensor。
本地分片的句柄在延迟执行严格完成后才被物化。
XLAShardedTensor公开了local_shards,以将可寻址设备上的本地分片作为List[[XLAShard](https://github.com/pytorch/xla/blob/4e8e5511555073ce8b6d1a436bf808c9333dcac6/torch_xla/distributed/spmd/xla_sharded_tensor.py#L12)]返回。
还有一个正在进行的努力,旨在将XLAShardedTensor集成到DistributedTensor API中,以支持XLA后端 [RFC]。
DTensor集成¶
PyTorch在2.1版本中原型发布了DTensor。我们正在将PyTorch/XLA SPMD集成到DTensor API中 RFC。我们有一个distribute_tensor的概念验证集成,它调用mark_sharding注释API来使用XLA对张量及其计算进行分片。
import torch
from torch.distributed import DeviceMesh, Shard, distribute_tensor
# distribute_tensor now works with `xla` backend using PyTorch/XLA SPMD.
mesh = DeviceMesh("xla", list(range(world_size)))
big_tensor = torch.randn(100000, 88)
my_dtensor = distribute_tensor(big_tensor, mesh, [Shard(0)])
此功能处于实验阶段,敬请关注即将发布的版本中更多更新、示例和教程。
分片感知主机到设备的数据加载¶
PyTorch/XLA SPMD采用单设备程序,对其进行分片并在并行执行。SPMD执行需要使用原生PyTorch DataLoader,它会将数据从主机同步传输到XLA设备。这会阻塞每一步输入数据传输期间的训练。为了提高原生数据加载性能,我们在PyTorch/XLA ParallelLoader中直接支持输入分片(src),当传递可选的kwarg _input_sharding_时。
# MpDeviceLoader returns ParallelLoader.per_device_loader as iterator
train_loader = pl.MpDeviceLoader(
train_loader, # wraps PyTorch DataLoader
device,
# optional input_sharding field
input_sharding=xs.ShardingSpec(input_mesh, (0, 1, 2, 3)))
分布式检查点¶
PyTorch/XLA SPMD通过专用的Planner实例与torch.distributed.checkpoint库兼容。用户可以通过此通用接口同步保存和加载检查点。
SPMDSavePlanner和SPMDLoadPlanner(src)类使save和load函数能够直接对XLAShardedTensor的分片进行操作,从而在SPMD训练中获得分布式检查点的所有优势。
下面是同步分布式检查点API的演示。
import torch.distributed.checkpoint as dist_cp
import torch_xla.experimental.distributed_checkpoint as xc
# Saving a state_dict
state_dict = {
"model": model.state_dict(),
"optim": optim.state_dict(),
}
dist_cp.save(
state_dict=state_dict,
storage_writer=dist_cp.FileSystemWriter(CHECKPOINT_DIR),
planner=xc.SPMDSavePlanner(),
)
...
# Loading the model's state_dict from the checkpoint. The model should
# already be on the XLA device and have the desired sharding applied.
state_dict = {
"model": model.state_dict(),
}
dist_cp.load(
state_dict=state_dict,
storage_reader=dist_cp.FileSystemReader(CHECKPOINT_DIR),
planner=xc.SPMDLoadPlanner(),
)
model.load_state_dict(state_dict["model"])
CheckpointManager¶
实验性的CheckpointManager接口在torch.distributed.checkpoint函数之上提供了更高级别的API,以启用一些关键功能。
管理检查点:
CheckpointManager捕获的每个检查点都由捕获时的步骤标识。所有跟踪的步骤都可以通过CheckpointManager.all_steps方法访问,并且可以使用CheckpointManager.restore恢复任何跟踪的步骤。异步检查点:通过
CheckpointManager.save_asyncAPI捕获的检查点被异步写入持久存储,以在检查点持续时间内解除训练阻塞。在将检查点分派到后台线程之前,输入分片state_dict首先被移动到CPU。抢占时的自动检查点:在Cloud TPU上,可以检测到抢占并在进程终止之前捕获检查点。要使用此功能,请确保您的TPU通过启用了自动检查点的QueuedResource进行预配,并确保在构造CheckpointManager时设置了
chkpt_on_preemption参数(此选项默认启用)。FSSpec支持:
CheckpointManager使用fsspec存储后端,以启用直接到任何与fsspec兼容的文件系统(包括GCS)的检查点。
CheckpointManager的使用示例如下。
from torch_xla.experimental.distributed_checkpoint import CheckpointManager, prime_optimizer
# Create a CheckpointManager to checkpoint every 10 steps into GCS.
chkpt_mgr = CheckpointManager('gs://my-bucket/my-experiment', 10)
# Select a checkpoint to restore from, and restore if applicable
tracked_steps = chkpt_mgr.all_steps()
if tracked_steps:
# Choose the highest step
best_step = max(tracked_steps)
# Before restoring the checkpoint, the optimizer state must be primed
# to allow state to be loaded into it.
prime_optimizer(optim)
state_dict = {'model': model.state_dict(), 'optim': optim.state_dict()}
chkpt_mgr.restore(best_step, state_dict)
model.load_state_dict(state_dict['model'])
optim.load_state_dict(state_dict['optim'])
# Call `save` or `save_async` every step within the train loop. These methods
# return True when a checkpoint is taken.
for step, data in enumerate(dataloader):
...
state_dict = {'model': model.state_dict(), 'optim': optim.state_dict()}
if chkpt_mgr.save_async(step, state_dict):
print(f'Checkpoint taken at step {step}')
恢复优化器状态¶
在分布式检查点中,state_dicts是就地加载的,并且只加载检查点所需的碎片。由于优化器状态是延迟创建的,因此在第一次optimizer.step调用之前,状态不存在,并且尝试加载未准备好的优化器将失败。
为此提供了实用方法prime_optimizer:它通过将所有梯度设置为零并调用optimizer.step来运行一个伪训练步骤。这是一种破坏性方法,将同时影响模型参数和优化器状态,因此应仅在恢复之前调用它。
进程组¶
要使用torch.distributed API(如分布式检查点),需要一个进程组。在SPMD模式下,xla后端不受支持,因为编译器负责所有集体操作。
相反,必须使用CPU进程组,例如gloo。在TPU上,仍然支持xla:// init_method来发现主机的IP、全局世界大小和主机排名。下面是一个初始化示例。
import torch.distributed as dist
# Import to register the `xla://` init_method
import torch_xla.distributed.xla_backend
import torch_xla.runtime as xr
xr.use_spmd()
# The `xla://` init_method will automatically discover master worker IP, rank,
# and global world size without requiring environment configuration on TPUs.
dist.init_process_group('gloo', init_method='xla://')
虚拟设备优化¶
PyTorch/XLA通常在定义张量后异步地将张量数据从主机传输到设备。这是为了将数据传输与图形跟踪时间重叠。但是,由于GSPMD允许用户在定义张量_之后_修改张量分片,因此我们需要一个优化来防止张量数据在主机和设备之间不必要地来回传输。我们引入了虚拟设备优化,这是一种将张量数据首先放置在虚拟设备SPMD:0上,然后在所有分片决策最终确定后上传到物理设备的技术。SPMD模式下的每个张量数据都放置在虚拟设备SPMD:0上。虚拟设备对用户显示为XLA设备XLA:0,实际分片位于物理设备上,例如TPU:0、TPU:1等。
进程数¶
与现有的DDP和FSDP不同,在SPMD模式下,每个加速器主机上始终运行一个进程。这带来的好处是PyTorch/XLA只需要编译每个图一次,该图可以重复用于连接到此主机的所有加速器。
在TPU Pod上运行SPMD¶
如果您根据设备数量而不是某些硬编码常量来构建网格和分区规范,则从单个TPU主机切换到TPU Pod不需要进行任何代码更改。要在TPU Pod上运行PyTorch/XLA工作负载,请参阅我们PJRT指南的Pods部分。
在GPU上运行SPMD¶
PyTorch/XLA支持在NVIDIA GPU(单节点或多节点)上运行SPMD。训练/推理脚本与用于TPU的脚本相同,例如此ResNet脚本。要使用SPMD执行脚本,我们利用torchrun。
PJRT_DEVICE=CUDA \
torchrun \
--nnodes=${NUM_GPU_MACHINES} \
--node_rank=${RANK_OF_CURRENT_MACHINE} \
--nproc_per_node=1 \
--rdzv_endpoint="<MACHINE_0_IP_ADDRESS>:<PORT>" \
training_or_inference_script_using_spmd.py
--nnodes:要使用的GPU机器数量。--node_rank:当前GPU机器的索引。该值可以是0、1、…、${NUMBER_GPU_VM}-1。--nproc_per_node:由于SPMD要求,该值必须为1。–rdzv_endpoint: 节点排名为 0 的 GPU 机器端点,格式为host:port`。主机将是内部 IP 地址。``port` 可以是机器上的任何可用端口。对于单节点训练/推理,可以省略此参数。
例如,如果您想使用SPMD在2台GPU机器上训练ResNet模型,您可以在第一台机器上运行以下脚本。
XLA_USE_SPMD=1 PJRT_DEVICE=CUDA \
torchrun \
--nnodes=2 \
--node_rank=0 \
--nproc_per_node=1 \
--rdzv_endpoint="<MACHINE_0_INTERNAL_IP_ADDRESS>:12355" \
pytorch/xla/test/spmd/test_train_spmd_imagenet.py --fake_data --batch_size 128
并在第二台机器上运行以下脚本。
XLA_USE_SPMD=1 PJRT_DEVICE=CUDA \
torchrun \
--nnodes=2 \
--node_rank=1 \
--nproc_per_node=1 \
--rdzv_endpoint="<MACHINE_0_INTERNAL_IP_ADDRESS>:12355" \
pytorch/xla/test/spmd/test_train_spmd_imagenet.py --fake_data --batch_size 128
有关更多信息,请参阅GPU上的SPMD支持RFC。
参考示例¶
使用SPMD表达数据并行¶
SPMD API足够通用,可以表达数据并行和模型并行。只需注释输入批次维度以进行分片,即可实现数据并行。在这里,我们将批次维度跨所有可用设备(N路)进行分片:有两种使用SPMD表达数据并行或批次分片的方法。
num_devices = xr.global_runtime_device_count()
# Assume data is 4d and 0th dimension is the batch dimension
mesh_shape = (num_devices,)
input_mesh = xs.Mesh(device_ids, mesh_shape, ('Data'))
partition_spec = ('data', None, None, None)
# Shard the input's batch dimension along the `data` axis, no sharding along other dimensions
xs.mark_sharding(input_tensor, input_mesh, partition_spec)
PyTorch/XLA的MpDeviceLoader支持输入批次分片,它还将批次加载到后台的设备中。
num_devices = xr.global_runtime_device_count()
# Assume data is 4d and 0th dimension is the batch dimension
mesh_shape = (num_devices)
input_mesh = xs.Mesh(device_ids, mesh_shape, ('Data'))
partition_spec = ('data', None, None, None)
# Use MpDeviceLoader to load data in background
train_loader = pl.MpDeviceLoader(
train_loader,
device,
input_sharding=xs.ShardingSpec(input_mesh, partition_spec))
我们强烈推荐第二种方法,因为它应该会产生更好的训练性能。
使用SPMD表达FSDP(完全分片数据并行)¶
PyTorch的FSDP是数据并行+在第0维分片模型参数。用户首先需要使用SPMD表达数据并行,如上一节所述。
for name, param in model.named_parameters():
shape = (num_devices,)
mesh = xs.Mesh(device_ids, shape, ('fsdp'))
partition_spec = [None] * len(param.shape)
partition_spec[0] = 'fsdp'
xs.mark_sharding(param, mesh, partition_spec)
PyTorch/XLA还为带SPMD的FSDP提供了一个方便的包装器,请查看此用户指南。
使用SPMD运行Resnet50示例¶
我们提供了一个resnet50的快速示例,其中包含几个不同的SPMD分片策略,供您尝试。您可以首先使用以下命令在没有SPMD的情况下运行它。
python test/spmd/test_train_spmd_imagenet.py --fake_data --batch_size 512
并检查吞吐量。之后,您可以使用以下命令启用批次分片。
XLA_USE_SPMD=1 python test/spmd/test_train_spmd_imagenet.py --fake_data --batch_size 2048 --model=resnet50 --sharding=batch
请注意,我使用了 4 倍大的批次大小,因为我是在 TPU v4 上运行它,TPU v4 附带了 4 个 TPU 设备。您应该会看到吞吐量大约是无SPMD运行的 4 倍。
SPMD调试工具¶
我们为在 TPU/GPU/CPU 上使用单主机/多主机的 PyTorch/XLA SPMD 用户提供了一个 shard placement visualization debug tool:您可以使用 visualize_tensor_sharding 可视化分片张量,或者使用 visualize_sharding 可视化分片字符串。以下是在 TPU 单主机 (v4-8) 上使用 visualize_tensor_sharding 或 visualize_sharding 的两个代码示例。
使用
visualize_tensor_sharding的代码片段和可视化结果
import rich
# Here, mesh is a 2x2 mesh with axes 'x' and 'y'
t = torch.randn(8, 4, device='xla')
xs.mark_sharding(t, mesh, ('x', 'y'))
# A tensor's sharding can be visualized using the `visualize_tensor_sharding` method
from torch_xla.distributed.spmd.debugging import visualize_tensor_sharding
generated_table = visualize_tensor_sharding(t, use_color=False)

使用
visualize_sharding的代码片段和可视化结果
from torch_xla.distributed.spmd.debugging import visualize_sharding
sharding = '{devices=[2,2]0,1,2,3}'
generated_table = visualize_sharding(sharding, use_color=False)

您可以在 TPU/GPU/CPU 单主机上使用这些示例,并修改它以在多主机上运行。您还可以修改它以适应 tiled、partial_replication 和 replicated 等分片样式。
自动分片¶
我们正在引入一项新的 PyTorch/XLA SPMD 功能,称为 auto-sharding,RFC。这是一个实验性功能,在 r2.3 和 nightly 版本中可用,支持 XLA:TPU 和单个 TPUVM 主机。
可以通过以下方法之一启用 PyTorch/XLA 自动分片:
设置环境变量
XLA_AUTO_SPMD=1在代码开头调用 SPMD API
import torch_xla.runtime as xr
xr.use_spmd(auto=True)
使用
auto-policy和xla调用pytorch.distributed._tensor.distribute_module
import torch_xla.runtime as xr
from torch.distributed._tensor import DeviceMesh, distribute_module
from torch_xla.distributed.spmd import auto_policy
device_count = xr.global_runtime_device_count()
device_mesh = DeviceMesh("xla", list(range(device_count)))
# Currently, model should be loaded to xla device via distribute_module.
model = MyModule() # nn.module
sharded_model = distribute_module(model, device_mesh, auto_policy)
可选地,可以设置以下选项/环境变量来控制基于 XLA 的自动分片传递的行为:
XLA_AUTO_USE_GROUP_SHARDING:对参数进行分组重新分片。默认情况下设置。XLA_AUTO_SPMD_MESH:用于自动分片的逻辑网格形状。例如,XLA_AUTO_SPMD_MESH=2,2对应于一个具有 4 个全局设备的 2x2 网格。如果未设置,则将使用默认的设备网格形状num_devices,1。
