除了 PyTorch 1.12 版本,我们还对当前的 PyTorch 库进行了一系列改进。这些更新表明我们致力于在所有领域开发通用且可扩展的 API,以便我们的社区更容易在 PyTorch 上构建生态系统项目。
总结
- TorchVision – 添加了多权重支持 API、新架构、模型变体和预训练权重。请在此处查看 发行说明。
- TorchAudio – 引入了 Beta 版功能,包括流式 API、CTC 束搜索解码器以及新的波束形成模块和方法。请在此处查看 发行说明。
- TorchText – 扩展了对可脚本化 BERT 分词器的支持,并为 GLUE 基准测试添加了数据集。请在此处查看 发行说明。
- TorchRec – 添加了 EmbeddingModule 基准测试、TwoTower 检索、推理和序列嵌入示例、指标,改进了规划器并演示了与生产组件的集成。请在此处查看 发行说明。
- TorchX – 将在本地工作区开发的 PyTorch 训练器部署到五种不同类型的调度器上。请在此处查看 发行说明。
- FBGemm – 为推荐系统推理工作负载添加并改进了内核,包括表格批处理嵌入袋、锯齿张量操作和其他特殊情况优化。
TorchVision v0.13
多权重支持 API
TorchVision v0.13 提供了一个新的 多权重支持 API,用于将不同权重加载到现有模型构建器方法中
from torchvision.models import *
# Old weights with accuracy 76.130%
resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
# New weights with accuracy 80.858%
resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
# Best available weights (currently alias for IMAGENET1K_V2)
# Note that these weights may change across versions
resnet50(weights=ResNet50_Weights.DEFAULT)
# Strings are also supported
resnet50(weights="IMAGENET1K_V2")
# No weights - random initialization
resnet50(weights=None)
新 API 将重要的细节(例如预处理转换和元数据(例如标签))与权重捆绑在一起。以下是如何充分利用它
from torchvision.io import read_image
from torchvision.models import resnet50, ResNet50_Weights
img = read_image("test/assets/encode_jpeg/grace_hopper_517x606.jpg")
# Step 1: Initialize model with the best available weights
weights = ResNet50_Weights.DEFAULT
model = resnet50(weights=weights)
model.eval()
# Step 2: Initialize the inference transforms
preprocess = weights.transforms()
# Step 3: Apply inference preprocessing transforms
batch = preprocess(img).unsqueeze(0)
# Step 4: Use the model and print the predicted category
prediction = model(batch).squeeze(0).softmax(0)
class_id = prediction.argmax().item()
score = prediction[class_id].item()
category_name = weights.meta["categories"][class_id]
print(f"{category_name}: {100 * score:.1f}%")
您可以在 文档 中阅读有关新 API 的更多信息。要提供您的反馈,请使用此专用 Github 问题。
新架构和模型变体
分类
Swin Transformer 和 EfficientNetV2 是两种流行的分类模型,通常用于下游视觉任务。此版本包括其分类变体的 6 个预训练权重。以下是如何使用新模型
import torch
from torchvision.models import *
image = torch.rand(1, 3, 224, 224)
model = swin_t(weights="DEFAULT").eval()
prediction = model(image)
image = torch.rand(1, 3, 384, 384)
model = efficientnet_v2_s(weights="DEFAULT").eval()
prediction = model(image)
此外,我们还为 ShuffleNetV2、ResNeXt 和 MNASNet 等现有架构提供了新变体。ImageNet-1K 上获得的所有新预训练模型的准确率如下所示
| 模型 | Acc@1 | Acc@5 |
|---|---|---|
| swin_t | 81.474 | 95.776 |
| swin_s | 83.196 | 96.36 |
| swin_b | 83.582 | 96.64 |
| efficientnet_v2_s | 84.228 | 96.878 |
| efficientnet_v2_m | 85.112 | 97.156 |
| efficientnet_v2_l | 85.808 | 97.788 |
| resnext101_64x4d | 83.246 | 96.454 |
| resnext101_64x4d (量化) | 82.898 | 96.326 |
| shufflenet_v2_x1_5 | 72.996 | 91.086 |
| shufflenet_v2_x1_5 (量化) | 72.052 | 0.700 |
| shufflenet_v2_x2_0 | 76.230 | 93.006 |
| shufflenet_v2_x2_0 (量化) | 75.354 | 92.488 |
| mnasnet0_75 | 71.180 | 90.496 |
| mnas1_3 | 76.506 | 93.522 |
我们感谢 Hu Ye 为 TorchVision 贡献了 Swin Transformer 的实现。
(BETA) 对象检测和实例分割
我们为 RetinaNet、FasterRCNN 和 MaskRCNN 引入了 3 个新的模型变体,其中包括多项 论文后架构优化 和改进的训练方案。所有模型都可以类似地使用
import torch
from torchvision.models.detection import *
images = [torch.rand(3, 800, 600)]
model = retinanet_resnet50_fpn_v2(weights="DEFAULT")
# model = fasterrcnn_resnet50_fpn_v2(weights="DEFAULT")
# model = maskrcnn_resnet50_fpn_v2(weights="DEFAULT")
model.eval()
prediction = model(images)
下面我们展示了 COCO val2017 上新变体的指标。括号中表示与旧变体相比的改进
| 模型 | Box mAP | Mask mAP |
|---|---|---|
| retinanet_resnet50_fpn_v2 | 41.5 (+5.1) | – |
| fasterrcnn_resnet50_fpn_v2 | 46.7 (+9.7) | – |
| maskrcnn_resnet50_fpn_v2 | 47.4 (+9.5) | 41.8 (+7.2) |
我们感谢 Ross Girshick、Piotr Dollar、Vaibhav Aggarwal、Francisco Massa 和 Hu Ye 过去的研究和对这项工作的贡献。
新预训练权重
SWAG 权重
ViT 和 RegNet 模型变体提供新的预训练 SWAG(Supervised Weakly from hashtAGs)权重。其中最大的模型之一在 ImageNet-1K 上实现了高达 88.6% 的准确率。我们目前提供两种版本的权重:1) 在 ImageNet-1K 上端到端微调的权重(最高准确率)和 2) 冻结主干权重,并在 ImageNet-1K 上拟合线性分类器(非常适合迁移学习)。下面我们看到每个模型变体的详细准确率
| 模型权重 | Acc@1 | Acc@5 |
|---|---|---|
| RegNet_Y_16GF_Weights.IMAGENET1K_SWAG_E2E_V1 | 86.012 | 98.054 |
| RegNet_Y_16GF_Weights.IMAGENET1K_SWAG_LINEAR_V1 | 83.976 | 97.244 |
| RegNet_Y_32GF_Weights.IMAGENET1K_SWAG_E2E_V1 | 86.838 | 98.362 |
| RegNet_Y_32GF_Weights.IMAGENET1K_SWAG_LINEAR_V1 | 84.622 | 97.48 |
| RegNet_Y_128GF_Weights.IMAGENET1K_SWAG_E2E_V1 | 88.228 | 98.682 |
| RegNet_Y_128GF_Weights.IMAGENET1K_SWAG_LINEAR_V1 | 86.068 | 97.844 |
| ViT_B_16_Weights.IMAGENET1K_SWAG_E2E_V1 | 85.304 | 97.65 |
| ViT_B_16_Weights.IMAGENET1K_SWAG_LINEAR_V1 | 81.886 | 96.18 |
| ViT_L_16_Weights.IMAGENET1K_SWAG_E2E_V1 | 88.064 | 98.512 |
| ViT_L_16_Weights.IMAGENET1K_SWAG_LINEAR_V1 | 85.146 | 97.422 |
| ViT_H_14_Weights.IMAGENET1K_SWAG_E2E_V1 | 88.552 | 98.694 |
| ViT_H_14_Weights.IMAGENET1K_SWAG_LINEAR_V1 | 85.708 | 97.73 |
SWAG 权重根据 署名-非商业性 4.0 国际 许可证发布。我们感谢 Laura Gustafson、Mannat Singh 和 Aaron Adcock 在使权重可用于 TorchVision 方面所做的工作和支持。
模型刷新
多权重支持 API 的发布使我们能够刷新最流行的模型并提供更准确的权重。我们平均每个模型提高了约 3 个点。使用的新方案是在 ResNet50 的基础上学习的,其细节已在 上一篇博客文章 中介绍。
| 模型 | 旧权重 | 新权重 |
|---|---|---|
| efficientnet_b1 | 78.642 | 79.838 |
| mobilenet_v2 | 71.878 | 72.154 |
| mobilenet_v3_large | 74.042 | 75.274 |
| regnet_y_400mf | 74.046 | 75.804 |
| regnet_y_800mf | 76.42 | 78.828 |
| regnet_y_1_6gf | 77.95 | 80.876 |
| regnet_y_3_2gf | 78.948 | 81.982 |
| regnet_y_8gf | 80.032 | 82.828 |
| regnet_y_16gf | 80.424 | 82.886 |
| regnet_y_32gf | 80.878 | 83.368 |
| regnet_x_400mf | 72.834 | 74.864 |
| regnet_x_800mf | 75.212 | 77.522 |
| regnet_x_1_6gf | 77.04 | 79.668 |
| regnet_x_3_2gf | 78.364 | 81.196 |
| regnet_x_8gf | 79.344 | 81.682 |
| regnet_x_16gf | 80.058 | 82.716 |
| regnet_x_32gf | 80.622 | 83.014 |
| resnet50 | 76.13 | 80.858 |
| resnet50 (量化) | 75.92 | 80.282 |
| resnet101 | 77.374 | 81.886 |
| resnet152 | 78.312 | 82.284 |
| resnext50_32x4d | 77.618 | 81.198 |
| resnext101_32x8d | 79.312 | 82.834 |
| resnext101_32x8d (量化) | 78.986 | 82.574 |
| wide_resnet50_2 | 78.468 | 81.602 |
| wide_resnet101_2 | 78.848 | 82.51 |
我们感谢 Piotr Dollar、Mannat Singh 和 Hugo Touvron 过去的研究和对这项工作的贡献。
新的增强、层和损失
此版本带来了一系列新的原语,可用于生成 SOTA 模型。其中一些亮点包括添加了 AugMix 数据增强方法、DropBlock 层、cIoU/dIoU 损失以及 更多。我们感谢 Aditya Oke、Abhijit Deo、Yassine Alouini 和 Hu Ye 为该项目做出的贡献,并帮助我们保持 TorchVision 的相关性和新鲜度。
文档
我们彻底改造了模型文档,使其更易于浏览,并添加了各种关键信息,例如支持的图像大小或预训练权重的图像预处理步骤。我们现在有一个 主模型页面,其中包含各种 可用权重摘要表,每个模型都有一个 专用页面。每个模型构建器也在其 自己的页面 中进行了文档说明,其中包含有关可用权重的更多详细信息,包括准确性、最小图像大小、训练方案链接和其他有价值的信息。为了进行比较,我们以前的模型文档在 此处。要提供有关新文档的反馈,请使用专用 Github 问题。
TorchAudio v0.12
(BETA) 流式 API


StreamReader 是 TorchAudio 的新 I/O API。它由 FFmpeg† 支持,允许用户
- 解码音频和视频格式,包括 MP4 和 AAC
- 处理输入形式,例如本地文件、网络协议、麦克风、网络摄像头、屏幕捕获和文件类对象
- 逐块迭代和解码,同时更改采样率或帧率
- 应用音频和视频滤镜,例如低通滤镜和图像缩放
- 使用 Nvidia 的基于硬件的解码器 (NVDEC) 解码视频
有关用法详细信息,请查看 文档 和教程
- 媒体流 API – 第 1 部分
- 媒体流 API – 第 2 部分
- 使用 Emformer RNN-T 进行在线 ASR
- 使用 Emformer RNN-T 进行设备 ASR
- 使用 NVDEC 加速视频解码
† 要使用 StreamReader,需要 FFmpeg 库。请安装 FFmpeg。编解码器的覆盖范围取决于这些库的配置方式。TorchAudio 官方二进制文件经过编译,可与 FFmpeg 4 库配合使用;如果 TorchAudio 从源代码构建,则可以使用 FFmpeg 5。
(BETA) CTC 束搜索解码器
TorchAudio 集成了来自 Flashlight (GitHub) 的 wav2letter CTC 束搜索解码器。添加此推理时间解码器后,可以使用 TorchAudio 工具运行端到端 CTC ASR 评估。
支持可定制的词典和无词典解码器,两者都与 KenLM n-gram 语言模型兼容,或者不使用语言模型。TorchAudio 还支持下载 LibriSpeech 数据集的 token、词典和预训练的 KenLM 文件。
(BETA) 新波束形成模块和方法
为了提高使用的灵活性,此版本在 torchaudio.transforms 下添加了两个新的波束形成模块:SoudenMVDR 和 RTFMVDR。与 MVDR 的主要区别在于
- 使用功率谱密度 (PSD) 和相对传递函数 (RTF) 矩阵作为输入,而不是时频掩码。该模块可以与直接预测语音和噪声的复值 STFT 系数的神经网络集成
- 在 forward 方法中添加 'reference_channel' 作为输入参数,允许用户在模型训练中选择参考通道或在推理中动态更改参考通道
除了这两个模块,torchaudio.functional 下还添加了新的函数级波束形成方法。其中包括
有关用法详细信息,请查看 torchaudio.transforms 和 torchaudio.functional 的文档以及 使用 MVDR 波束形成进行语音增强教程。
TorchText v0.13
GLUE 数据集
我们通过添加 GLUE 基准测试中剩余的 8 个数据集(SST-2 已受支持)将 TorchText 中的数据集数量从 22 个增加到 30 个。GLUE 数据集的完整列表如下
- CoLA (论文):单句二分类可接受性任务
- SST-2 (论文):单句二分类情感任务
- MRPC (论文):双句二分类释义任务
- QQP:双句二分类释义任务
- STS-B (论文):单句到浮点回归句子相似性任务
- MNLI (论文):句子三分类 NLI 任务
- QNLI (论文):句子二分类 QA 和 NLI 任务
- RTE (论文):双句二分类 NLI 任务
- WNLI (论文):双句二分类指代消解和 NLI 任务
可脚本化 BERT 分词器
TorchText 通过添加 BERT 中使用的 WordPiece 分词器扩展了对可脚本化分词器的支持。它是将输入文本拆分为子词单元的常用算法之一,由 Schuster 等人于 2012 年在日语和韩语语音搜索中引入。
TorchScriptabilty 支持将允许用户将 BERT 文本预处理原生嵌入到 C++ 中,而无需 Python 运行时的支持。由于 TorchText 现在支持 CMAKE 构建系统以将 torchtext 二进制文件原生链接到应用程序代码,因此用户可以轻松集成 BERT 分词器以满足部署需求。
有关用法详细信息,请参阅相应的 文档。
TorchRec v0.2.0
EmbeddingModule + DLRM 基准测试
一组 基准测试,展示了 TorchRec 基本模块和基于 TorchRec 构建的研究模型的性能特征。
TwoTower 检索示例,带 FAISS
我们提供了一个 示例,演示了训练一个使用 TorchRec 进行分片的分布式 TwoTower(即用户-项目)检索模型。投影的项目嵌入被添加到 IVFPQ FAISS 索引中用于候选生成。检索模型和 KNN 查找被捆绑在 PyTorch 模型中,以实现高效的端到端检索。
集成
我们演示了 TorchRec 可以与生产系统中 PyTorch 模型常用的许多组件无缝协作,例如
- 在 Ray 集群上 训练 TorchRec 模型,利用 Torchx Ray 调度器
- 使用 NVTabular 对 DLRM 进行 预处理 和数据加载
- 使用 TorchArrow 进行即时预处理的 TorchRec 模型 训练,展示 RecSys 领域 UDF
序列嵌入示例:Bert4Rec
我们提供了一个 示例,使用 TorchRec 重新实现了 BERT4REC 论文,展示了用于非池化嵌入的 EmbeddingCollection。使用 DistributedModelParallel,我们看到了比传统数据并行性高 35% 的 QPS 增益。
(Beta) 规划器
TorchRec 库包含一个内置的 规划器,它为给定模型选择接近最佳的分片计划。规划器通过评估一系列静态分析并馈送到整数分区器的建议来尝试识别最佳分片计划。规划器能够自动调整各种硬件设置的计划,允许用户从本地开发环境无缝扩展性能到大规模生产硬件。有关更详细的教程,请参阅此 笔记本。
(Beta) 推理
TorchRec Inference 是一个支持多 GPU 推理的 C++ 库。TorchRec 库用于通过 torch.package(TorchScript 的替代方案)对用 Python 编写和打包的模型进行分片。torch.deploy 库用于通过启动多个携带打包模型的 Python 解释器来从 C++ 提供推理服务,从而避免 GIL。提供了两个模型作为示例:DLRM 多 GPU(通过 TorchRec 分片)和 DLRM 单 GPU。
(Beta) RecMetrics
RecMetrics 是一个 指标 库,它收集了推荐模型的常用实用程序和优化。它扩展了 torchmetrics。
- 一个集中的指标模块,允许用户添加新指标
- 常用指标,包括 AUC、校准、CTR、MSE/RMSE、NE 和吞吐量
- 优化与指标相关的操作,以减少指标计算的开销
- 检查点
(原型) 单进程批量 + 融合嵌入
以前,TorchRec 对 FBGEMM 内核的抽象(EmbeddingBagCollection/EmbeddingCollection),它们提供了表批处理、优化器融合和 UVM 放置等优势,只能与 DistributedModelParallel 结合使用。我们已将这些概念与分片解耦,并引入了 FusedEmbeddingBagCollection,它可以作为独立模块使用,具有上述所有功能,并且也可以进行分片。
TorchX v0.2.0
TorchX 是一个作业启动器,它使在具有许多调度器集成(包括 Kubernetes 和 Slurm)的分布式训练集群中运行 PyTorch 变得更容易。我们很高兴发布 TorchX 0.2.0,其中包含多项改进。TorchX 目前已在本地和云环境中投入生产使用。
查看 快速入门 以开始启动本地和远程作业。
工作区
TorchX 现在支持工作区,允许用户使用其本地工作区轻松启动训练作业。TorchX 可以自动在基础镜像之上构建包含您的本地训练代码的补丁,以最大程度地缩短迭代时间和训练时间。
.torchxconfig
在 .torchxconfig 中指定选项可以避免您每次启动作业时都必须输入冗长的 CLI 命令。您还可以定义项目级通用配置,并将配置文件放在主目录中以进行用户级覆盖。
扩展的调度器支持
TorchX 现在支持 AWS Batch 和 Ray(实验性) 调度器,此外还有我们现有的集成。
所有调度器上的分布式训练
TorchX dist.ddp 组件现在可以在所有调度器上运行,无需任何配置。分布式训练 worker 将在使用 torchelastic 时通过 内置的 dist.ddp 组件 自动发现彼此。
超参数优化
TorchX 与 Ax 集成,让您通过将搜索试验启动到远程集群来扩展超参数优化 (HPO)。
文件和设备挂载
TorchX 现在支持 远程文件系统挂载和自定义设备。这使您的 PyTorch 作业能够高效访问云存储,例如 NFS 或 Lustre。设备挂载允许使用 Infiniband 等网络加速器和自定义推理/训练加速器。
FBGemm v0.2.0
FBGEMM 库包含优化的内核,旨在提高 PyTorch 工作负载的性能。在过去几个月中,我们添加了许多新功能和优化,我们很高兴报告这些进展。
推理表批处理嵌入 (TBE)
表批处理嵌入包 (TBE) 算子是 GPU 上推荐系统推理嵌入查找的重要基础操作。我们为性能和灵活性添加了以下增强功能
对齐限制已移除
- 以前,嵌入维度 * 数据类型大小必须是 4B 的倍数,现在是 1B。
统一虚拟内存 (UVM) 缓存内核优化
- UVM 缓存内核现在与使用 UVM 缓存的表数量呈线性关系。以前,它的开销与所有表使用 UVM 缓存的开销相似
- UVM 缓存内核开销比以前小得多
推理 FP8 表批处理嵌入 (TBE)
表批处理嵌入包 (TBE) 以前支持 FP32、FP16、INT8、INT4 和 INT2 嵌入权重类型。虽然这些权重类型在许多模型中都表现良好,但我们集成了 FP8 权重类型(在 GPU 和 CPU 操作中),以允许在我们的模型中进行 FP8 的数值和性能评估。与 INT8 相比,FP8 不需要额外的偏差和比例存储和计算。此外,下一代 H100 GPU 在 Tensor Core 上支持 FP8(主要是 matmul 操作)。
锯齿张量内核
我们添加了优化的内核来加速 TorchRec JaggedTensor。JaggedTensor 的目的是处理输入数据的一个维度“锯齿状”的情况,这意味着给定维度中的每个连续行可能长度不同,这在推荐系统中的稀疏特征输入中经常发生。内部表示如下
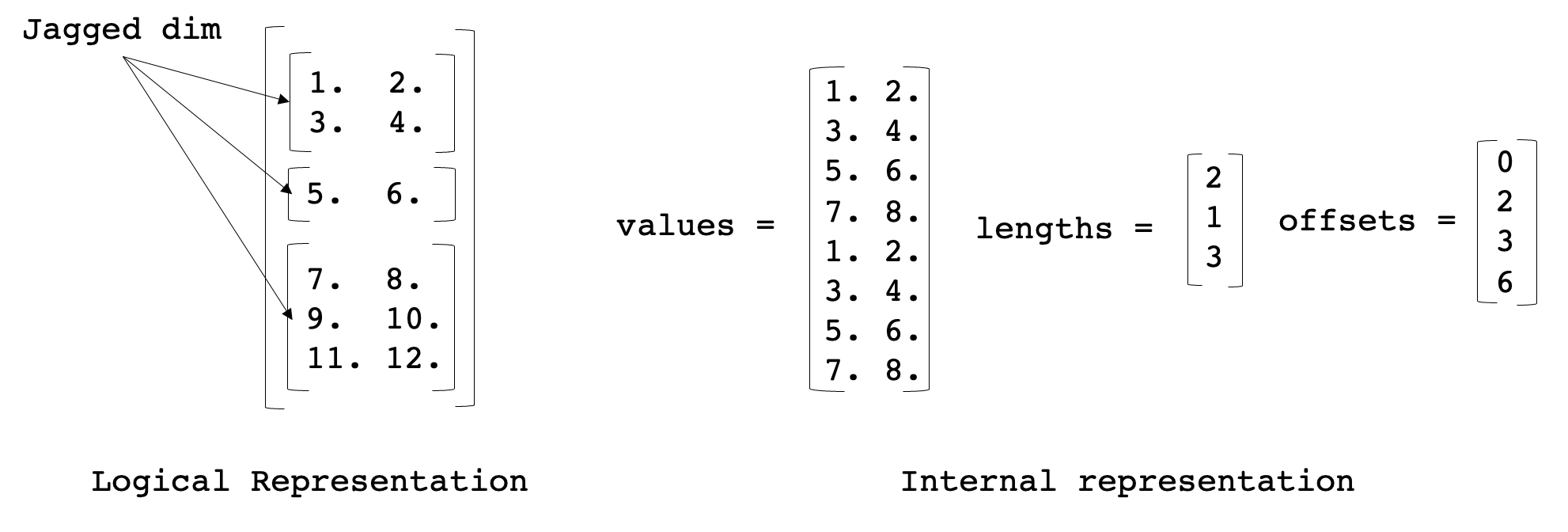
我们添加了用于将锯齿张量从稀疏格式转换为密集格式并返回、对锯齿张量执行矩阵乘法以及逐元素操作的运算符。
优化的 permute102-baddbmm-permute102
在批大小不是模型批大小的情况下融合各种矩阵乘法很困难,切换批维度是一个快速解决方案。我们创建了 permute102_baddbmm_permute102 操作,它切换第一个和第二个维度,执行批处理矩阵乘法,然后切换回来。目前我们只支持 FP16 数据类型的前向传播,未来将支持 FP32 类型和后向传播。
针对维度 0 索引选择的优化 index_select
index_select 通常用作稀疏操作的一部分。虽然 PyTorch 支持用于任意维度索引选择的通用 index_select,但它在维度 0 索引选择等特殊情况下的性能不佳。因此,我们为维度 0 实现了一个专用的 index_select。在某些情况下,我们观察到 FBGEMM 的 index_select 比 PyTorch 的 index_select 性能提高了 1.4 倍(使用均匀索引分布)。
有关有影响力实例的实现的更多信息,请访问我们的 GitHub 页面和教程。
感谢阅读,如果您对这些更新感兴趣并希望加入 PyTorch 社区,我们鼓励您加入 讨论论坛 并 提交 GitHub issue。要获取 PyTorch 的最新消息,请在 Twitter、Medium、YouTube 和 LinkedIn 上关注我们。
干杯!
PyTorch 团队