在过去的一年里,专家混合 (MoE) 模型的人气飙升,这得益于强大的开源模型,如 DBRX、Mixtral、DeepSeek 等等。在 Databricks,我们与 PyTorch 团队紧密合作,以扩展 MoE 模型的训练规模。在这篇博客文章中,我们将讨论如何使用 PyTorch Distributed 和 MegaBlocks(PyTorch 中高效的开源 MoE 实现)扩展到三千多个 GPU。
什么是 MoE?
MoE 模型是一种使用多个专家网络进行预测的模型架构。门控网络用于路由和组合专家输出,确保每个专家都在不同的、专门的 token 分布上进行训练。基于 Transformer 的大型语言模型架构通常由一个嵌入层组成,该层连接到多个 Transformer 块(图 1,子图 A)。每个 Transformer 块包含一个注意力块和一个密集前馈网络(图 1,子图 B)。这些 Transformer 块堆叠起来,使得一个 Transformer 块的输出成为下一个块的输入。最终输出通过一个全连接层和 softmax,以获得下一个输出 token 的概率。
在 LLM 中使用 MoE 时,密集前馈层被 MoE 层替换,MoE 层由一个门控网络和多个专家组成(图 1,子图 D)。门控网络通常是一个线性前馈网络,它接收每个 token 并生成一组权重,这些权重决定了哪些 token 被路由到哪些专家。专家本身通常也实现为前馈网络。在训练过程中,门控网络适应将输入分配给专家,从而使模型能够专门化并提高其性能。然后,路由器输出用于对专家输出进行加权,以提供 MoE 层的最终输出。
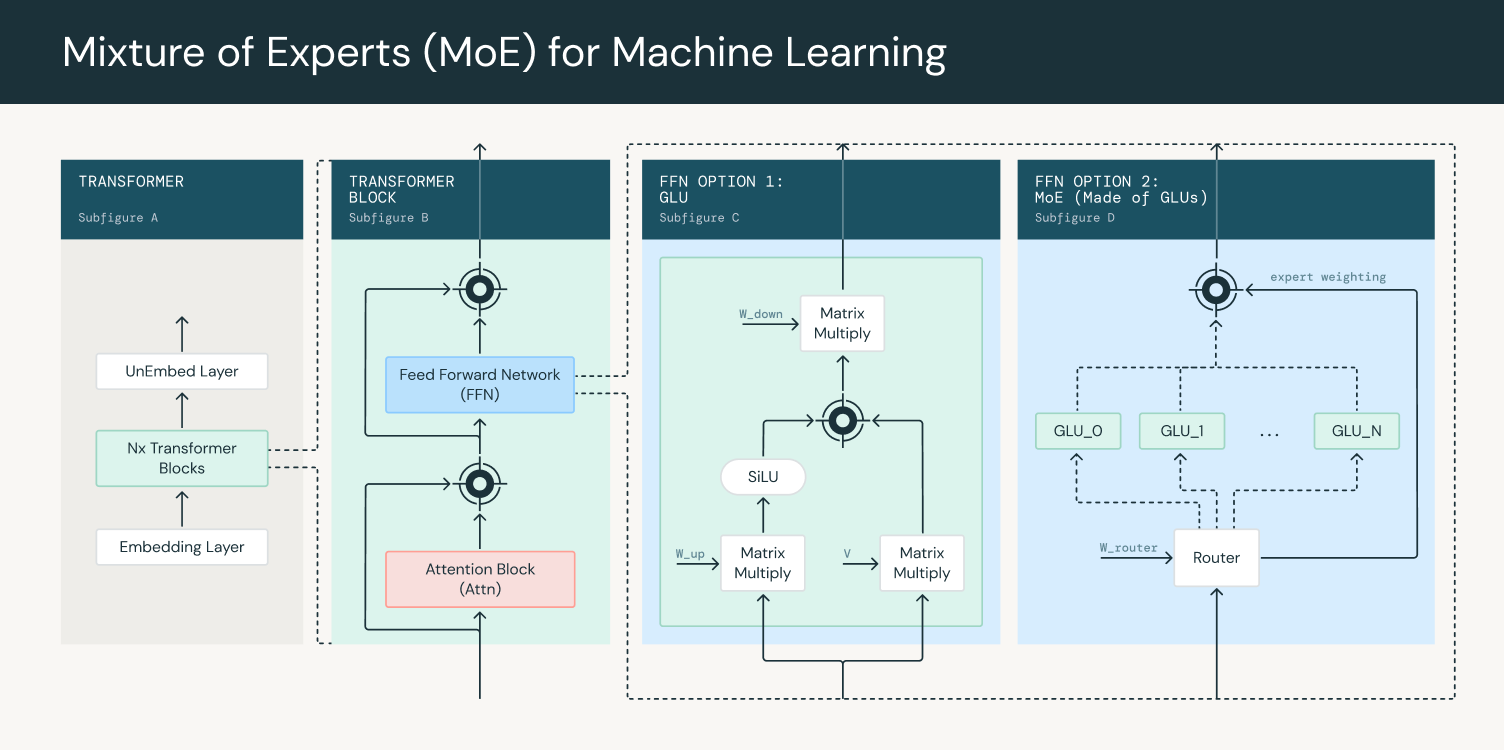
图 1:在 Transformer 块中使用专家混合
与密集模型相比,MoE 在给定的计算预算下提供了更高效的训练。这是因为门控网络只将 token 发送到专家子集,从而减少了计算负载。因此,可以在不按比例增加计算要求的情况下增加模型的容量(其总参数数量)。在推理过程中,只使用部分专家,因此 MoE 能够比密集模型更快地执行推理。然而,整个模型需要加载到内存中,而不仅仅是正在使用的专家。
MoE 中的稀疏性使得计算效率更高,原因在于特定 token 只会被路由到专家子集。专家的数量以及如何选择专家取决于门控网络的实现,但常见的方法是 top k。门控网络首先预测每个专家的概率值,然后将 token 路由到 top k 专家以获得输出。然而,如果所有 token 总是流向相同的专家子集,训练就会变得低效,其他专家最终会训练不足。为了缓解这个问题,引入了负载均衡损失,鼓励所有专家之间均匀路由。
专家的数量和选择 top k 专家是设计 MoE 的重要因素。更多的专家数量允许扩展到更大的模型而无需增加计算成本。这意味着模型具有更高的学习能力,然而,超过某个点后,性能增益往往会减小。专家的数量需要与服务模型的推理成本相平衡,因为整个模型都需要加载到内存中。类似地,在选择 top k 时,训练期间较低的 top k 会导致较小的矩阵乘法,如果通信成本足够大,则会留下未使用的计算资源。然而,在推理期间,较高的 top k 通常会导致较慢的推理速度。
MegaBlocks
MegaBlocks 是一种高效的 MoE 实现,它使用稀疏矩阵乘法并行计算专家输出,尽管 token 分配不均匀。MegaBlocks 实现了一个无丢弃 MoE,它避免丢弃 token,同时使用 GPU 内核来保持高效训练。在 MegaBlocks 之前,动态路由公式迫使模型质量和硬件效率之间进行权衡。以前,用户必须要么从计算中丢弃 token,要么浪费计算和内存进行填充。专家可以接收可变数量的 token,并且可以使用块稀疏矩阵乘法高效地执行专家计算。我们已将 MegaBlocks 集成到 LLM Foundry 中,以实现将 MoE 训练扩展到数千个 GPU。
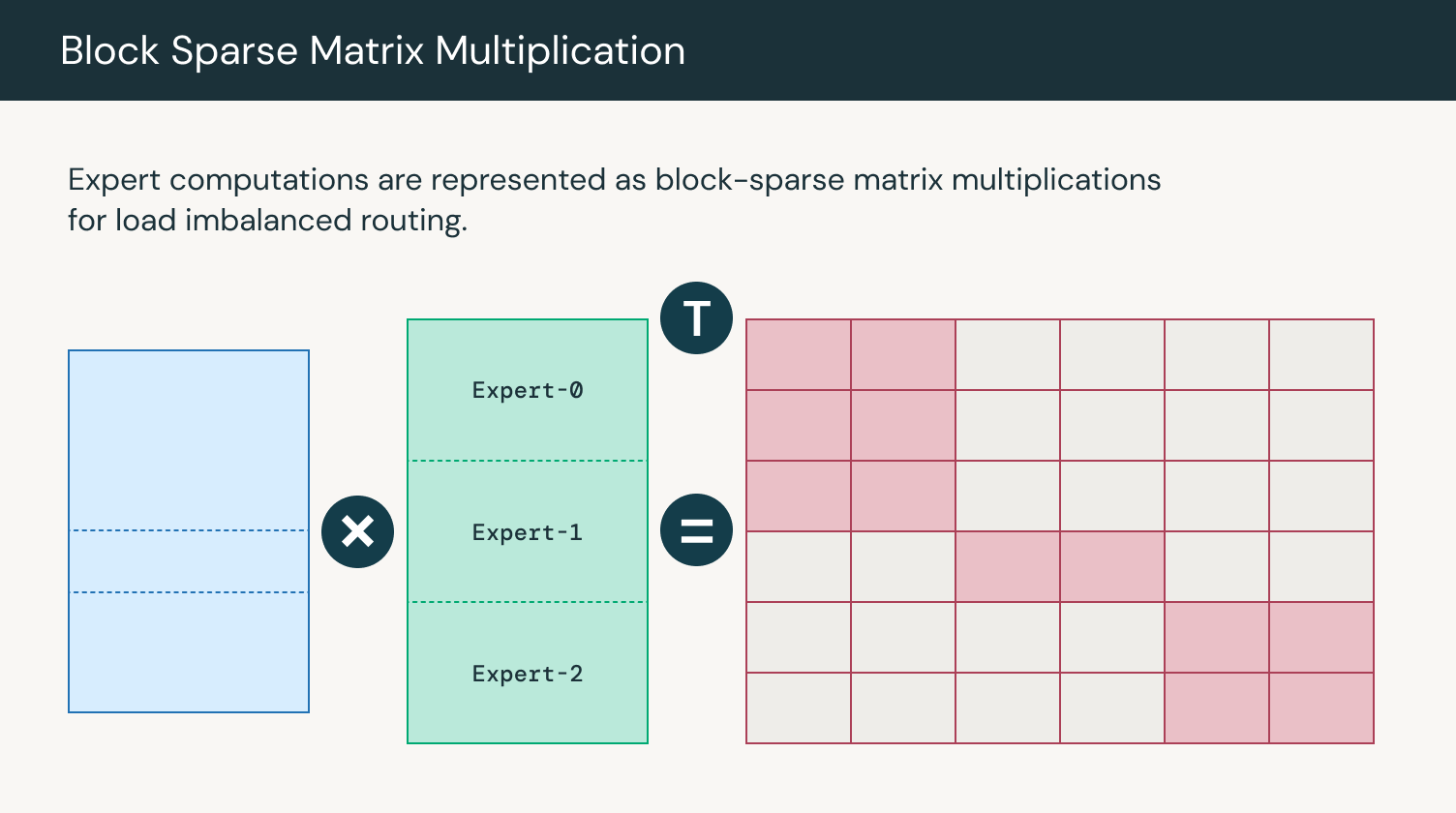
图 2:专家计算的矩阵乘法
专家并行性
随着模型扩展到更大的规模并无法在单个 GPU 上容纳,我们需要更高级的并行形式。专家并行性是一种模型并行形式,我们将不同的专家放置在不同的 GPU 上以获得更好的性能。不是在所有 GPU 之间通信专家权重,而是将 token 发送到包含专家的设备。通过移动数据而不是权重,我们可以跨多台机器聚合数据以供单个专家使用。路由器确定输入序列中的哪些 token 应该发送到哪些专家。这通常通过计算每个 token-专家对的门控分数,然后将每个 token 路由到得分最高的专家来完成。一旦确定了 token 到专家的分配,就执行全对全通信步骤以将 token 分派到托管相关专家的设备。这涉及每个设备发送分配给其他设备上专家的 token,同时接收分配给其本地专家的 token。
专家并行性的主要优点是处理少数、更大的矩阵乘法,而不是几个小的矩阵乘法。由于每个 GPU 只拥有一个专家子集,因此它只需要为这些专家进行计算。相应地,随着我们在多个 GPU 之间聚合 token,每个矩阵的大小也按比例增大。由于 GPU 针对大规模并行计算进行了优化,因此更大的操作可以更好地利用其功能,从而提高利用率和效率。有关更大矩阵乘法的优势的更深入解释可以在 这里 找到。计算完成后,再次执行全对全通信步骤,将专家输出发送回其原始设备。
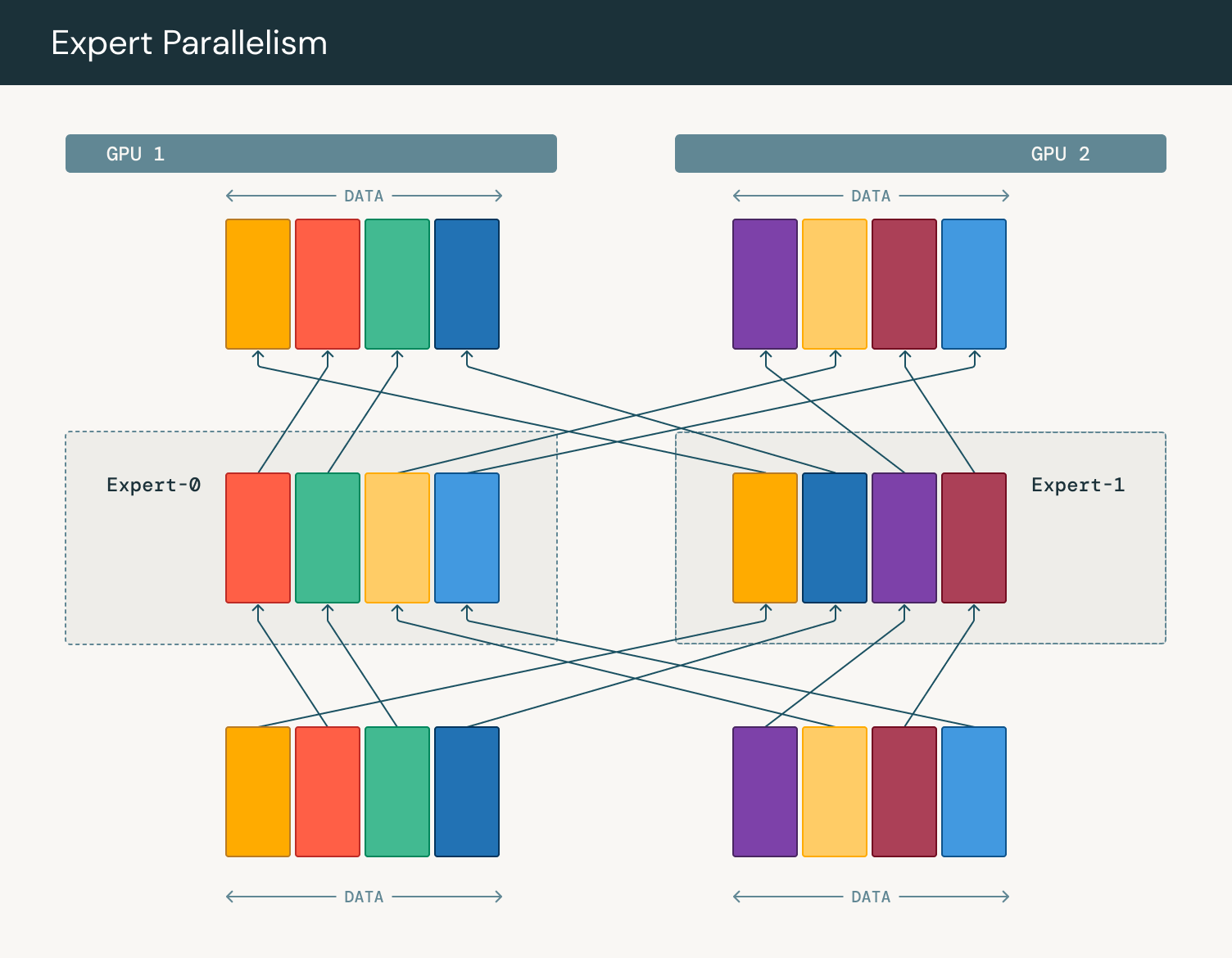
图 3:专家并行性中的 token 路由
我们利用 PyTorch 的 DTensor(一种描述张量如何分片和复制的低级抽象)来有效实现专家并行性。我们首先手动将专家放置在不同的 GPU 上,通常在节点之间进行分片,以确保在路由 token 时我们可以利用 NVLink 进行快速 GPU 通信。然后我们可以在此布局之上构建一个 设备网格,这使我们能够简洁地描述整个集群的并行性。当我们需要其他形式的并行性时,我们可以使用此设备网格轻松地检查点或重新排列专家。
使用 PyTorch FSDP 扩展 ZeRO-3
除了专家并行性之外,我们还对所有其他层使用数据并行性,其中每个 GPU 存储模型和优化器的副本并处理不同的数据块。在每个 GPU 完成前向和反向传播后,在 GPU 之间累积梯度以进行全局模型更新。
ZeRO-3 是一种数据并行形式,其中权重和优化器在每个 GPU 之间进行分片而不是复制。现在每个 GPU 只存储完整模型的一个子集,大大减少了内存压力。当计算需要模型的一部分时,它会在所有 GPU 之间进行收集,计算完成后,收集到的权重会被丢弃。我们使用 PyTorch 对 ZeRO-3 的实现,称为 完全分片数据并行 (FSDP)。
随着我们扩展到数千个 GPU,设备之间的通信成本增加,从而减慢了训练速度。由于需要在所有 GPU 之间同步和共享模型参数、梯度和优化器状态(涉及 all-gather 和 reduce-scatter 操作),通信量增加。为了在保持 FSDP 优势的同时缓解此问题,我们利用混合分片数据并行 (HSDP) 将模型和优化器分片到一组固定的 GPU 上,并将其多次复制以充分利用集群。使用 HSDP,在反向传播中需要额外的 all reduce 操作来同步副本之间的梯度。这种方法允许我们在大规模分布式训练期间平衡内存效率和通信成本。要使用 HSDP,我们可以扩展我们之前来自专家并行性的设备网格,并让 PyTorch 在需要时完成实际的分片和收集的繁重工作。
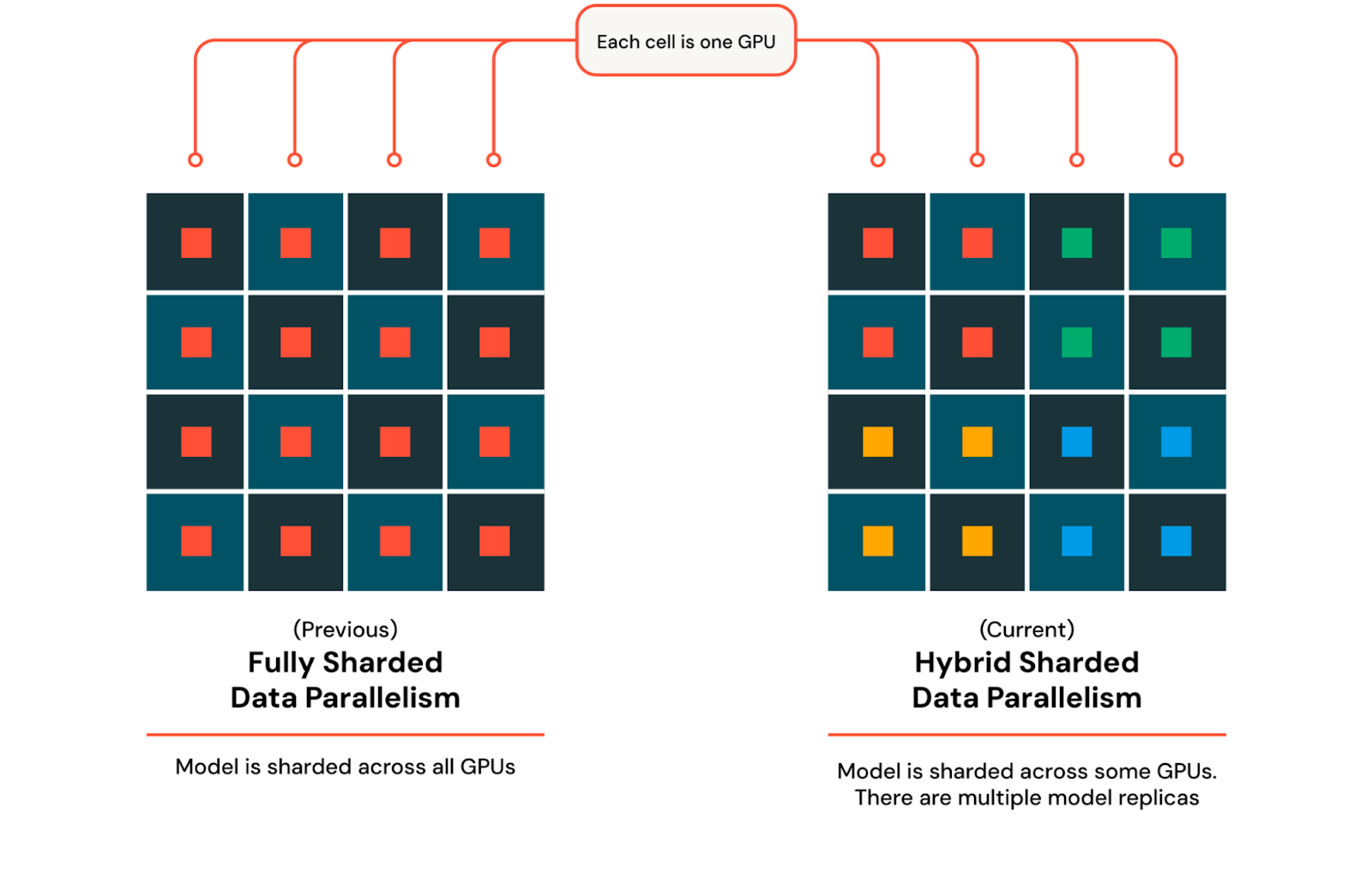
图 4:FSDP 和 HSDP
通过 PyTorch,我们可以有效地结合这两种并行类型,利用 FSDP 的高级 API,同时在我们想要实现像专家并行性这样的自定义功能时使用低级 DTensor 抽象。我们现在拥有一个 3D 设备网格,具有专家并行分片维度、ZeRO-3 分片维度和纯数据并行的复制维度。这些技术共同实现了在非常大型集群上的近线性扩展,使我们能够实现超过 40% 的 MFU 数字。
使用 Torch Distributed 进行弹性检查点
容错性对于确保 LLM 能够在较长时间内可靠训练至关重要,尤其是在节点故障常见的分布式环境中。为了避免在作业不可避免地遇到故障时丢失进度,我们会检查点模型的状态,其中包括参数、优化器状态和其他必要的元数据。发生故障时,系统可以从上次保存的状态恢复,而不是从头开始。为了确保对故障的鲁棒性,我们需要经常检查点,并以尽可能最佳的性能方式保存和加载检查点,以最大限度地减少停机时间。此外,如果太多 GPU 发生故障,我们的集群大小可能会改变。因此,我们需要能够在不同数量的 GPU 上弹性恢复的能力。
PyTorch 通过其分布式训练框架支持弹性检查点,其中包括用于在不同集群配置中保存和加载检查点的实用程序。PyTorch Distributed Checkpoint 确保模型的状态可以在训练集群中的所有节点上并行准确地保存和恢复,无论集群组成因节点故障或添加而发生任何变化。
此外,在训练非常大的模型时,检查点的大小可能非常大,导致检查点上传和下载时间非常慢。PyTorch Distributed Checkpoint 支持分片检查点,这使得每个 GPU 只能保存和加载模型的一部分。当分片检查点与弹性训练结合使用时,每个 GPU 读取元数据文件以确定在恢复时下载哪些分片。元数据文件包含有关每个张量的哪些部分存储在每个分片中的信息。然后,GPU 可以下载其模型部分的分片并加载检查点的该部分。
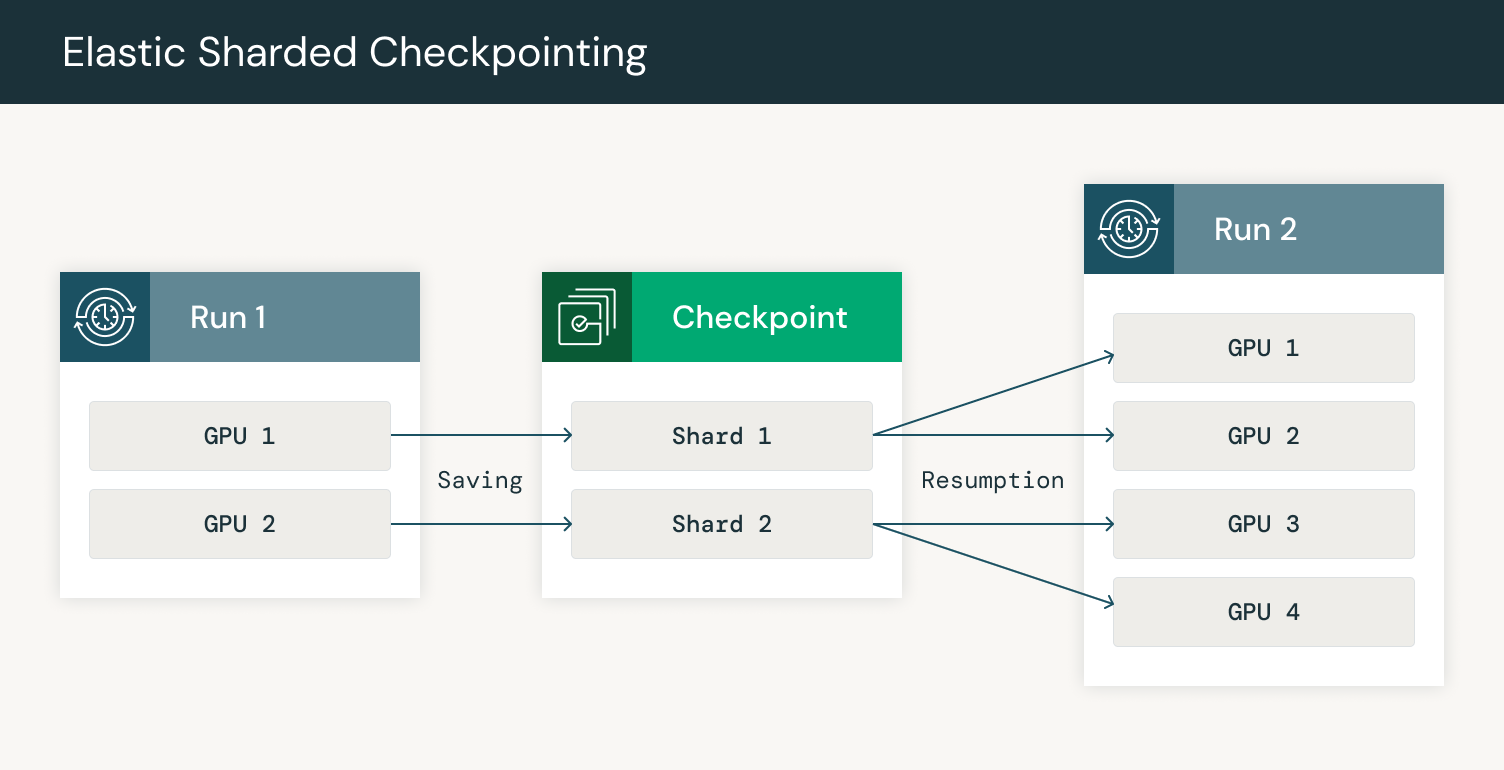
图 5:在额外 GPU 上重新分片的检查点保存和恢复
通过并行化 GPU 上的检查点,我们可以分散网络负载,提高鲁棒性和速度。当训练一个拥有 3000 多个 GPU 的模型时,网络带宽很快成为瓶颈。我们利用 HSDP 中的复制功能,首先在一个副本上下载检查点,然后将必要的分片发送到其他副本。通过我们与 Composer 的集成,我们可以可靠地将检查点上传到云存储,频率高达每 30 分钟一次,并在节点故障时在不到 5 分钟内自动从最新检查点恢复。
结论
我们非常高兴看到 PyTorch 正在如何以出色的性能训练最先进的 LLM。在我们的文章中,我们展示了如何在 Foundry 上通过 Pytorch Distributed 和 MegaBlocks 实现高效的 MoE 训练。此外,Pytorch 弹性检查点使我们能够在节点故障时快速在不同数量的 GPU 上恢复训练。使用 Pytorch HSDP 使我们能够高效地扩展训练并缩短检查点恢复时间。我们期待继续在强大而充满活力的开源社区中建设,以帮助将出色的 AI 模型带给每个人。欢迎加入我们,在 LLM Foundry 和 PyTorch 构建出色的模型。