Diffusers 是一个首选库,它为图像、视频和音频提供了统一的尖端开放扩散模型接口。在过去的几个月里,我们加深了它与torch.compile的集成。通过根据扩散模型架构定制编译工作流程,torch.compile以最小的用户体验影响实现了显著的加速。在这篇文章中,我们将展示如何实现这些提升。本文的目标受众是:
- 扩散模型作者 – 学习如何进行小幅代码更改,使您的模型对编译器友好,以便最终用户可以从性能提升中受益。
- 扩散模型用户 – 了解编译时与运行时权衡,如何避免不必要的重新编译,以及其他可以帮助您选择正确设置的方面。我们将通过Diffusers中两个社区喜爱的管道来展示其收益。
虽然这些示例存在于Diffusers仓库中,但大多数原理也适用于其他深度学习工作负载。
目录
- 背景
- 有效使用
torch.compile处理扩散模型- 普通编译
- 对于模型作者:使用
fullgraph=True - 对于模型用户:使用区域编译
- 对于模型用户:减少重新编译
- 将
torch.compile扩展到流行的 Diffusers 功能- 内存受限的 GPU
- LoRA 适配器
- 操作强化
- 结论
- 重要资源链接
背景
torch.compile在您足够了解模型以编译正确的子模块时,才能发挥其最大效用。在本节中,我们将首先概述影响torch.compile用户体验的因素,然后剖析扩散架构以找出哪些组件最能从编译中受益。
影响torch.compile性能和可用性的核心因素
torch.compile将 Python 程序转换为优化图,然后生成机器代码,但加速和易用性取决于以下因素:
编译延迟 – 作为 JIT 编译器,torch.compile在首次运行时启动,因此用户会预先经历编译成本。此启动成本可能很高,尤其是对于大型图。
缓解措施:尝试区域编译,以针对小型、重复的区域。虽然这可能会限制与编译整个模型相比的最大可能加速,但它通常在性能和编译时间之间取得了更好的平衡,因此在决定之前请评估权衡。
图中断 — 动态 Python 或不支持的操作将 Python 程序切成许多小图,从而大大降低了潜在的加速。模型开发人员应努力使模型的计算密集部分没有任何图中断。
缓解措施:打开fullgraph=True,识别中断,并在准备模型时消除它们。
重新编译 – torch.compile将其代码专门化为精确的输入形状,因此将分辨率从512 × 512更改为1024 × 1024会触发重新编译和随之而来的延迟。
缓解措施:启用dynamic=True以放宽形状约束。请注意,dynamic=True对扩散模型效果很好,但推荐的方式是使用mark_dynamic选择性地将动态性应用于您的模型。
设备到主机 (DtoH) 同步也可能妨碍最佳性能,但这并非易事,必须逐案处理。Diffusers 中最广泛使用的扩散管道没有这些同步。有兴趣的读者可以查看此文档以了解更多信息。由于这些同步与其他提及的因素相比导致的延迟增加很小,因此本文的其余部分将不再关注它们。
扩散模型架构
我们将使用 Black Forest Labs 的开源文本到图像模型Flux‑1‑Dev作为我们的运行示例。扩散管道不是单个网络;它是一个模型集合:
- 文本编码器 – CLIP‑Text 和 T5 将用户提示转换为嵌入。
- 去噪器 – 扩散 Transformer (DiT) 逐步细化一个嘈杂的潜在变量,并以这些嵌入为条件。
- 解码器 (VAE) – 将最终的潜在变量转换为 RGB 像素。
在这些组件中,DiT在计算预算中占主导地位。您可以编译管道中的每个组件,但这只会增加编译延迟、重新编译和潜在的图中断,这些开销几乎无关紧要,因为这些部分已经只占总运行时间的一小部分。由于这些原因,我们将torch.compile限制在 DiT 组件而不是整个管道。
有效使用torch.compile处理扩散模型
普通编译
让我们建立一个基线,我们可以逐步改进它,同时保持流畅的torch.compile用户体验。加载 Flux‑1‑Dev 检查点并以通常的方式生成图像:
import torch from diffusers import FluxPipeline pipe = FluxPipeline.from_pretrained( "black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16 ).to("cuda") prompt = "A cat holding a sign that says hello world" out = pipe( prompt=prompt, guidance_scale=3.5, num_inference_steps=28, max_sequence_length=512, ).images[0] out.save("image.png")
现在编译计算密集型扩散 Transformer子模块:
pipe.transformer.compile(fullgraph=True)
在 H100 上,这一行代码将延迟从 6.7 秒缩短到 4.5 秒,实现了大约1.5 倍的加速,同时不牺牲图像质量。在底层,torch.compile融合了内核并消除了 Python 开销,从而提高了内存和计算效率。
对于模型作者:使用 fullgraph=True
DiT 的前向传播结构简单,因此我们期望它形成一个连续的图。此标志指示torch.compile在发生任何图中断时引发错误,让您及早发现不支持的操作,而不是默默地放弃潜在的性能提升。我们建议扩散模型作者在模型准备阶段早期设置fullgraph=True并修复图中断。请参阅torch.compile故障排除文档和手册以修复图中断。
对于模型用户:使用区域编译
如果您正在跟随,您会注意到第一次推理调用非常慢,在 H100 机器上需要 67.4 秒。这是编译开销。编译延迟随着交给编译器处理的图的大小而增加。一种降低此成本的实用方法是编译更小的、重复的块,我们称之为区域编译。
DiT 本质上是一堆相同的 Transformer 层。如果我们将一个层编译一次并将其内核用于每个后续层,我们可以缩短编译时间,同时保留与全图编译几乎相同的所有运行时增益。
Diffusers 通过一行代码助手实现了这一点
pipe.transformer.compile_repeated_blocks(fullgraph=True)
在 H100 上,这将编译延迟从67.4 秒缩短到 9.6 秒,将冷启动时间减少了7 倍,同时仍提供了全模型编译实现的 1.5 倍运行时加速。如果您想深入了解或使用区域编译启用您的新模型,实现讨论位于PR中。
请注意,上面的编译时间数字是冷启动测量值:我们使用torch._inductor.utils.fresh_inductor_cacheAPI 清除了编译缓存,因此torch.compile必须从头开始。或者,在热启动中,缓存的编译器工件(存储在本地磁盘或远程缓存中)让编译器跳过部分编译过程,从而减少编译延迟。对于我们的模型,区域编译在冷启动时需要 9.6 秒,但在缓存预热后只需 2.4 秒。有关有效使用编译缓存的详细信息,请参阅链接的指南。
对于模型用户:减少重新编译
因为torch.compile是一个即时编译器,它会根据其看到的输入的属性(形状、dtype 和设备等)专门化编译器工件(有关更多详细信息,请参阅此博客)。更改其中任何一个都会导致重新编译。虽然这会自动在幕后发生,但此重新编译会导致更高的编译时间成本,从而导致糟糕的用户体验。
如果您的应用程序需要处理多种图像大小或批次形状,请在编译时传入dynamic=True。对于一般模型,PyTorch建议使用mark_dynamic,但dynamic=True在扩散模型中效果很好。
pipe.transformer.compile_repeated_blocks( fullgraph=True, dynamic=True )
我们基准测试了 Flux DiT 在形状变化下进行完整编译的前向传播,并获得了令人信服的结果。
将torch.compile扩展到流行的 Diffusers 功能
现在,您应该清楚地了解如何使用torch.compile加速扩散模型,而不会影响用户体验。接下来,我们将讨论两个社区喜爱的 Diffusers 功能,并使它们与torch.compile完全兼容。我们将默认使用区域编译,因为它提供了与完整编译相同的加速,同时编译延迟降低了 8 倍。
- 内存受限的 GPU – 许多 Diffusers 用户在 VRAM 无法容纳整个模型的显卡上工作。我们将研究 CPU 卸载和量化,以使在这些设备上进行生成成为可能。
- 使用 LoRA 适配器快速个性化 – 通过低秩适配器进行微调是使扩散模型适应新样式或任务的首选方法。我们将演示如何在不触发重新编译的情况下交换 LoRA。
内存受限的 GPU
CPU 卸载: bfloat16 中的完整 Flux 管道消耗大约33GB,超过了大多数消费级 GPU 所能提供的。幸运的是,并非每个子模块都必须在整个前向传播过程中占用 GPU 内存。一旦文本编码器完成生成提示嵌入,它们就可以移动到系统 RAM。同样,在 DiT 优化潜在变量后,它也可以将 GPU 内存让给 VAE 解码器。
Diffusers 将这种卸载变成了一行代码
pipe.enable_model_cpu_offload()
峰值 GPU 使用率下降到大约22.7 GB,使得在较小的显卡上进行高分辨率生成成为可能,但代价是增加了PCIe流量。卸载以内存换时间,端到端运行现在大约需要21.5 秒,而不是 6.7 秒。
您可以通过启用torch.compile与卸载一起使用来挽回一些时间。编译器的内核融合抵消了一点 PCIe 开销,将延迟缩短到大约18.7 秒,同时保持了较小的 22.6 GB 占用空间。
pipe.enable_model_cpu_offload() pipe.transformer.compile_repeated_blocks(fullgraph=True)
Diffusers 提供了多种卸载模式,每种模式都有独特的“速度-内存”最佳平衡点。请查看卸载指南以了解完整菜单。
量化:CPU 卸载释放了 GPU 内存,但它仍然假设最大的组件 DiT 可以装入 GPU 内存。减轻内存压力的另一种方法是利用权重 量化,如果对有损输出有一些容忍度的话。
Diffusers 支持多种量化后端;这里我们使用来自bitsandbytes的 4 位NF4量化。它将 DiT 的权重占用空间减少了大约一半,将峰值 GPU 内存从大约 33 GB 降低到15 GB,同时保持了图像质量。

与 CPU 卸载不同,权重 量化将权重保留在 GPU 内存中,从而导致运行时惩罚增加较小——从基线的 6.7 秒增加到 7.3 秒。在torch.compile之上添加它融合了 4 位操作,将推理时间从7.279 秒减少到 5.048 秒,实现了大约 1.5 倍的加速。
您可以在此处找到不同的后端和代码指针。
(我们对 DiT 和 T5 启用了量化,因为它们的内存消耗都远高于 CLIP 和 VAE。)
量化 + 卸载:正如您可能预期的那样,您可以将 NF4 量化与 CPU 卸载结合起来,以获得最大的内存优势。这种组合技术将内存占用减少到 12.2 GB,推理时间为 12.2 秒。应用torch.compile无缝地工作,将运行时减少到9.8 秒,实现了 1.24 倍的加速。
这些基准测试是使用此脚本在单台 H100 机器上进行的。以下是我们目前讨论过的数字摘要。灰色框表示基线数字,绿色框表示最佳配置。
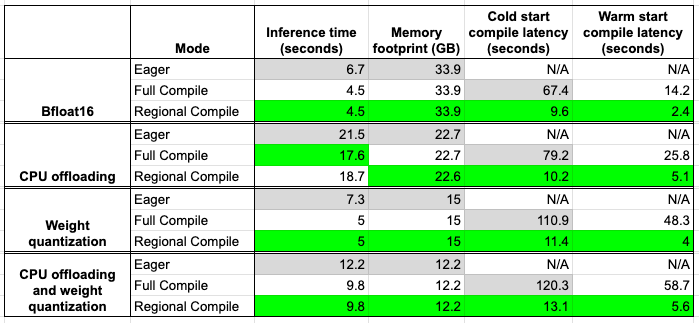
仔细查看上表,我们可以立即看到区域编译提供的加速几乎与完整编译相似,同时在编译时间方面显著更快。
LoRA 适配器
LoRA 适配器允许您个性化基本扩散模型,而无需微调数百万个参数。缺点是,在适配器之间切换通常会交换 DiT 内部的权重张量,迫使torch.compile重新跟踪和重新编译。
Diffusers 现在集成了PEFT的 LoRA 热插拔以避免这种情况。您声明您将需要的最大 LoRA 秩,编译一次,然后即时交换适配器。无需重新编译。
pipe = FluxPipeline.from_pretrained( "black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16 ).to("cuda") pipe.enable_lora_hotswap(target_rank=max_rank) pipe.load_lora_weights(<lora-adapter-name1>) pipe.transformer.compile(fullgraph=True) # from this point on, load new LoRAs with `hotswap=True` pipe.load_lora_weights(<lora-adapter-name2>, hotswap=True)
因为只有LoRA 权重张量发生变化,且它们的形状保持不变,所以编译后的内核仍然有效,推理延迟保持不变。
注意事项
- 我们需要提前提供所有 LoRA 适配器中的最大秩。因此,如果我们有一个秩为 16 的适配器和另一个秩为 32 的适配器,我们需要传递 `max_rank=32`。
- 热插拔的 LoRA 适配器只能针对第一个 LoRA 适配器所针对的相同层或其子集。
- 目前不支持文本编码器的热插拔。
有关更多详细信息,请参阅LoRA 热插拔文档和测试套件。
LoRA 推理与上述卸载和量化功能无缝集成。如果您受到 GPU VRAM 的限制,请考虑使用它们。
操作强化
Diffusers 每晚都会运行一个专门的 CI 作业,以保持对torch.compile的强大支持。该套件测试最流行的管道并自动检查:
- 图中断和静默回退
- 常见输入形状的意外重新编译
- 编译、CPU 卸载和我们支持的每个量化后端之间的兼容性
鼓励有兴趣的读者查看此链接,以查看改进torch.compile覆盖范围的最新 PR。
基准测试
正确性只是故事的一半;我们同样关心性能。现在,改进后的基准测试工作流与 CI 同时运行,捕获了本文中涵盖的每个场景的延迟和峰值内存。结果导出到合并的 CSV中,以便轻松发现回归(或胜利!)。设计和早期数据位于此PR中。

结论
torch.compile可以将标准 Diffusers 管道转变为高性能、内存高效的利器。通过将编译集中在 DiT 上,利用区域编译和动态形状,并将编译器与卸载、量化和 LoRA 热插拔结合使用,您可以显著提高速度并节省 VRAM,而无需牺牲图像质量或灵活性。
我们希望这些方法能启发您将torch.compile融入您自己的扩散工作流中。我们期待看到您接下来构建什么。
愉快的编译 ⚡️
Diffusers 团队感谢Animesh和Ryan在改进torch.compile支持方面提供的帮助和支持。
重要资源链接
torch.compile教程- 区域编译教程
torch.compile,缺失的手册- 使用
torch.compile时的技巧 - Diffusers x 编译文档