在我们之前的帖子《diffusion-fast》中,我们展示了如何使用原生 PyTorch 代码将 Stable Diffusion XL (SDXL) 管道优化多达 3 倍。当时,SDXL 是用于图像生成的开放式 SoTA 管道。毫不奇怪,自那时以来,许多事情都发生了变化,可以说 Flux 现在是该领域中最有能力的开源权重模型之一。
在这篇帖子中,我们很高兴展示了如何通过(主要)纯 PyTorch 代码和像 H100 这样的强大 GPU,实现了 Flux.1-Schnell 和 Flux.1-Dev 大约 2.5 倍的加速。
如果您迫不及待想开始使用代码,可以在此处找到仓库。
优化概述
Diffusers 库中提供的管道力求尽可能地与 torch.compile 兼容。这意味着
- 尽可能减少图中断
- 尽可能减少重新编译
- CPU<->GPU 同步极少或没有,以减少 Inductor 缓存查找开销
因此,它已经为我们提供了一个合理的起点。对于这个项目,我们采用了 diffusion-fast 项目中使用的相同基本原理,并将其应用于 FluxPipeline。下面,我们分享了我们应用的优化概述(详细信息请参阅仓库):
torch.compile使用 “fullgraph=True” 和 “max-autotune” 模式,确保使用 CUDAgraphs- 结合 q、k、v 投影进行注意力计算。这在量化期间特别有用,因为它会增加维度,提高计算密度。
- 解码器输出的
torch.channels_last内存格式 - Flash Attention v3 (FA3),输入(未缩放)转换为
torch.float8_e4m3fn - 通过 torchao 的
float8_dynamic_activation_float8_weight进行动态 float8 激活量化和线性层权重量化 - 用于调整该模型 Inductor 性能的一些标志
- conv_1x1_as_mm = True
- epilogue_fusion = False
- coordinate_descent_tuning = True
- coordinate_descent_check_all_directions = True
- torch.export + 提前(AOT)Inductor + CUDAGraphs
这些优化大部分不言自明,除了这两个
- Inductor 标志。感兴趣的读者可以查看 这篇博文了解更多详情。
- 通过 AoT 编译,我们旨在消除框架开销,并获得可通过
torch.export导出的已编译二进制文件。通过 CUDAGraphs,我们希望实现内核启动优化。更多详情请参阅这篇帖子。
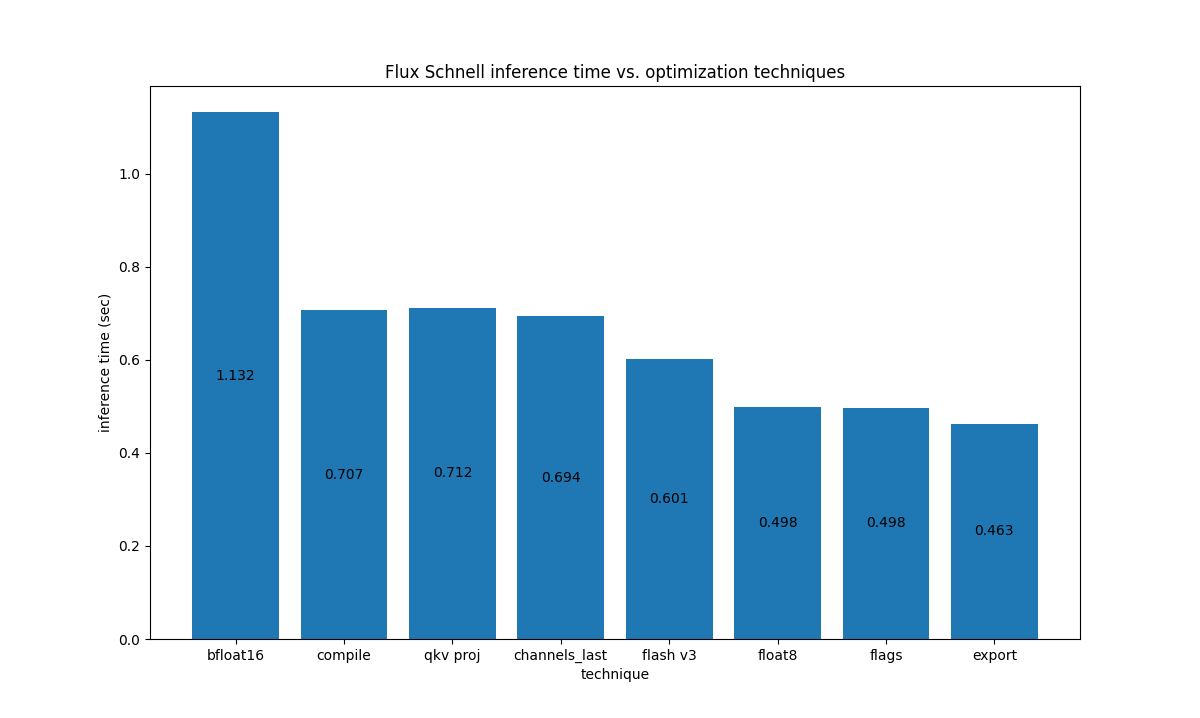
与 LLM 不同,扩散模型是计算密集型的,因此 gpt-fast 中的优化在这里并不完全适用。下图显示了各项优化(从左到右递增应用)对 H100 700W GPU 上 Flux.1-Schnell 的影响:
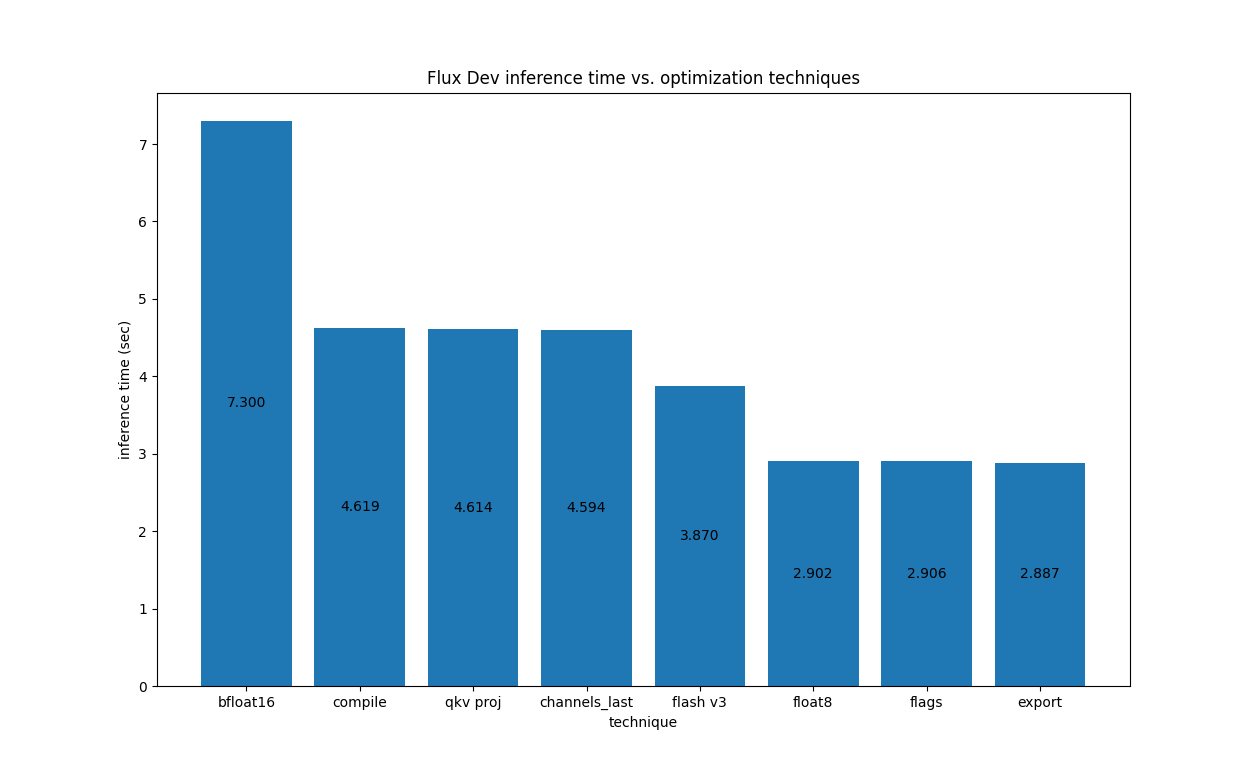
 对于 H100 上的 Flux.1-Dev,我们有以下结果
对于 H100 上的 Flux.1-Dev,我们有以下结果
 下面是应用于 Flux.1-Dev 的不同优化所获得的图像的视觉比较:
下面是应用于 Flux.1-Dev 的不同优化所获得的图像的视觉比较:

应该注意的是,只有 FP8 量化本质上是有损的,因此,对于大多数这些优化,图像质量应该保持不变。然而,在这种情况下,我们看到 FP8 的差异非常微不足道。
关于 CUDA 同步的注意事项
在我们的调查中,我们发现在去噪循环的第一步,在调度程序中的这个步骤会造成 CPU<->GPU 同步点。我们可以通过在去噪循环开始时添加 self.scheduler.set_begin_index(0) 来消除它 (PR)。
当使用 torch.compile 时,这实际上影响更大,因为 CPU 必须等待同步才能进行 Dynamo 缓存查找,然后才能在 GPU 上启动指令,而这种缓存查找有点慢。因此,重要的启示是,始终明智的做法是分析您的管道实现,并尽可能消除这些同步,以从编译中受益。
结论
这篇帖子介绍了一种使用原生 PyTorch 代码优化 Hopper 架构上 Flux 的方法。该方法力求在简洁性和性能之间取得平衡。其他类型的优化也可能实现(例如使用融合的 MLP 内核和融合的自适应 LayerNorm 内核),但为了简洁起见,我们没有深入探讨它们。
另一个关键点是,采用 Hopper 架构的 GPU 通常成本较高。因此,为了在消费级 GPU 上提供合理的速度-内存权衡,Diffusers 库中也提供了其他(通常与 torch.compile 兼容的)选项。我们邀请您在此处和此处查看它们。
我们邀请您在其他模型上尝试这些技术并分享结果。祝您优化愉快!