PyTorch 2.7 在英特尔® GPU 架构上持续提供重要的功能和性能增强,以简化 AI 工作流程。寻求在英特尔 GPU 上微调、推理和开发 PyTorch 模型的应用程序开发人员和研究人员现在将通过改进的安装、急切模式脚本调试、性能分析器和图模型(torch.compile)部署,在各种操作系统(包括 Windows、Linux 和适用于 Linux 的 Windows 子系统 (WSL2))上获得一致的用户体验。因此,开发人员在前端和后端开发中都拥有了更多的选择,并采用统一的 GPU 编程范式。
PyTorch 中英特尔 GPU 支持的增量改进
自 PyTorch 2.4 以来,我们一直在每个版本中稳步改进英特尔 GPU 支持。在 PyTorch 2.7 中,我们很高兴地宣布,我们已经为英特尔 GPU 在 Windows 和 Linux 的图模式(torch.compile)和急切模式下工作奠定了坚实的基础。这包括各种英特尔 GPU 产品,其中许多您可能已经在使用。我们希望这些增强功能能够为您的 AI 研究和开发解锁更普遍的硬件。
- 随着时间的推移,我们已将英特尔 GPU 支持扩展到 Windows 和 Linux,包括以下产品:
- 更简单的 torch-xpu PIP 轮子安装和轻松的设置体验。
- SYCL 和 oneDNN 提供了高 ATen 操作覆盖率,实现了功能和性能兼备的流畅急切模式支持。
- 通过默认的 TorchInductor 和 Triton 后端,torch.compile 实现了显著的加速,通过 Hugging Face、TIMM 和 TorchBench 基准测试可测量出性能提升。
请查阅这些相关发布博客中的详细进展:PyTorch 2.4、PyTorch 2.5 和 PyTorch 2.6。
PyTorch 2.7 中的新增功能
以下是 PyTorch 2.7 中为加速英特尔 GPU 性能而添加的功能。
- 改进了 bfloat16 和 float16 的缩放点积注意力 (SDPA) 推理性能,以加速英特尔 GPU 上的基于注意力的模型。
借助 PyTorch 2.7 中针对英特尔 GPU 的全新 SDPA 优化,在英特尔® 锐炫™ B580 显卡和搭载英特尔® 锐炫™ 显卡 140V 的英特尔® 酷睿™ Ultra 7 处理器 258V 上,在急切模式下,Stable Diffusion float16 推理相对于 PyTorch 2.6 版本实现了高达 3 倍的性能提升。请参见下文图 1。
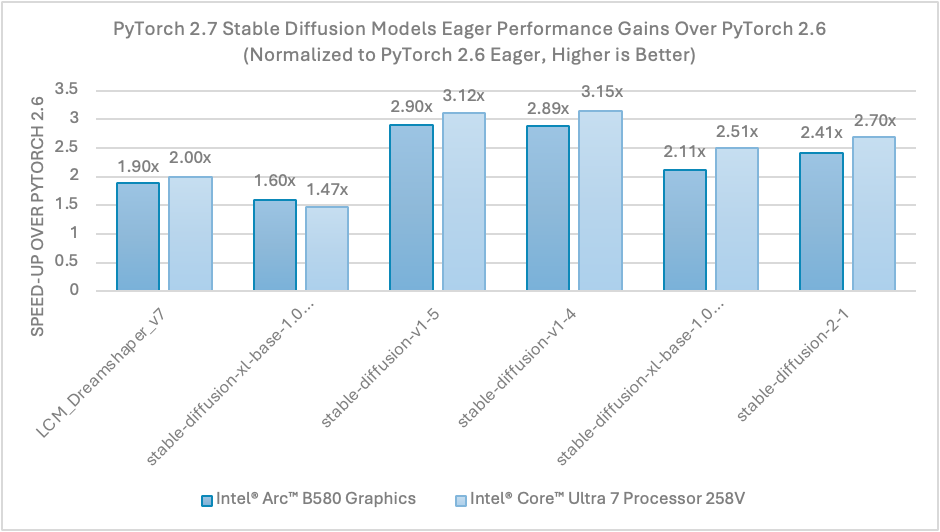
图 1. PyTorch 2.7 相对于 PyTorch 2.6 的 Stable Diffusion 性能提升
- 在 Windows 11 上为英特尔 GPU 启用 torch.compile,提供与 Linux 上急切模式相同的性能优势。借此,英特尔 GPU 成为第一个在 Windows 上支持 torch.compile 的加速器。有关详细信息,请参阅Windows 教程。
PyTorch 2.7 首次在 Windows 11 上为英特尔 GPU 启用了图模型(torch.compile),提供了与 Linux 上急切模式相同的性能优势。最新的性能数据是在 PyTorch Dynamo 基准测试套件之上使用英特尔® 锐炫™ B580 显卡在 Windows 上测量得到的,展示了 torch.compile 相对于急切模式的加速比,如图 2 所示。训练和推理都取得了类似的显著改进。
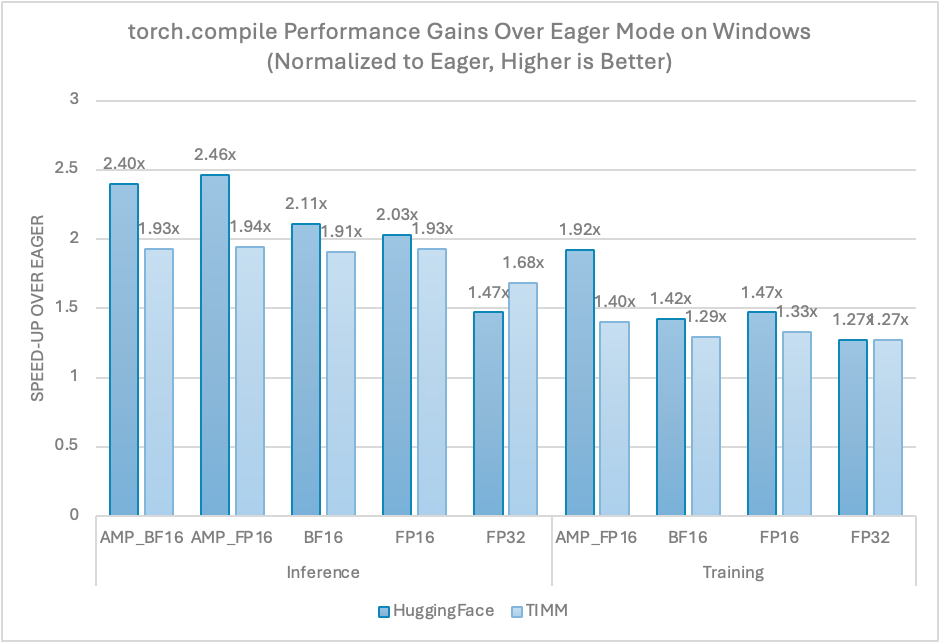
图 2. Windows 上 torch.compile 相对于急切模式的性能提升
- 优化 PyTorch 2 导出训练后量化 (PT2E) 在英特尔 GPU 上的性能,以提供具有增强计算效率的完整图模式量化管道。有关详细信息,请参阅PT2E 教程。
- 在 Linux 上启用 AOTInductor 和 torch.export 以简化部署工作流程。有关详细信息,请参阅AOTInductor 教程。
- 在 Windows 和 Linux 上启用分析器以促进模型性能分析。有关详细信息,请参阅PyTorch 分析器教程。
请查阅英特尔 GPU 入门指南,了解环境设置和英特尔 GPU 的快速入门。
未来工作
展望未来,我们将在未来的 PyTorch 版本中继续英特尔 GPU 上游工作,以:
- 实现最先进的 PyTorch 原生性能,展示 torch.compile 具有竞争力的 GEMM 计算效率,并通过 FlexAttention 和较低精度数据类型增强 LLM 模型的性能。
- 通过为英特尔® 数据中心 GPU Max 系列提供分布式 XCCL 后端支持来拓宽功能兼容性。
- 扩展核心 PyTorch 生态系统组件(包括 torchao、torchtune 和 torchtitan)的加速器支持。
请关注PyTorch 开发讨论,了解有关英特尔 GPU 和 CPU 启用状态和功能的更多信息。随着我们的深入,我们将在 GitHub 上创建工单以记录我们的进展。
总结
在这篇博客中,我们回顾了从 PyTorch 2.4 开始的英特尔 GPU 上游进展,并重点介绍了 PyTorch 2.7 的新功能,这些功能加速了各种英特尔 GPU 上的 AI 工作负载性能。这些新功能,尤其是 Windows 上的 SDPA,在英特尔锐炫 B580 显卡和搭载英特尔锐炫显卡 140V 的英特尔酷睿 Ultra 7 处理器 258V 上,实现了相对于 PyTorch 2.6 版本高达 3 倍的推理(Stable Diffusion,float16)性能提升。此外,Windows 上的 torch.compile 在 Dynamo 基准测试中提供了与 Linux 上急切模式相似的性能优势。
相关视频
使用 AOTInductor 在英特尔 GPU 上部署编译后的 PyTorch 模型
致谢
我们感谢以下 PyTorch 维护者提供的技术讨论和见解:Nikita Shulga、Jason Ansel、Andrey Talman、Alban Desmaison 和 Bin Bao。
我们还要感谢 PyTorch 合作者提供的专业支持和指导。
产品和性能信息
在英特尔酷睿 Ultra 7 258V 上的测量:2200 MHz,8 核,8 个逻辑处理器,搭载英特尔锐炫 140V GPU(16GB),GPU 内存 18.0 GB,使用英特尔显卡驱动程序 32.0.101.6647(WHQL 认证),Windows 11 专业版 – 24H2。以及英特尔酷睿 Ultra 5 245KF:4200 MHz,14 核,14 个逻辑处理器,英特尔锐炫 B580 显卡,专用 GPU 内存 12.0 GB,共享 GPU 内存 15.8 GB,使用英特尔显卡驱动程序 32.0.101.6647(WHQL 认证),Windows 11 企业版 LTSC – 24H2。英特尔于 2025 年 4 月 8 日测试。
注意事项和免责声明
性能因使用、配置和其他因素而异。请访问性能指数网站了解更多信息。性能结果基于所示配置下的测试日期,可能无法反映所有公开发布的更新。 请参阅备份以获取配置详情。 没有任何产品或组件是绝对安全的。您的成本和结果可能有所不同。英特尔技术可能需要启用硬件、软件或服务激活。
英特尔公司。英特尔、英特尔徽标和其他英特尔标志是英特尔公司或其子公司的商标。其他名称和品牌可能属于他人所有。
AI 免责声明
AI 功能可能需要购买软件、订阅或由软件或平台提供商启用,或者可能有特定的配置或兼容性要求。详情请见www.intel.com/AIPC。结果可能有所不同。