我们很高兴地宣布 PyTorch 1.12 发布了(发行说明)!本次发布包含 3124 多个提交,433 位贡献者。除了 1.12 之外,我们还发布了 AWS S3 集成、CPU 上 Channels Last 的 PyTorch Vision 模型、使用 Bfloat16 和 FSDP API 增强 Intel® Xeon® 可扩展处理器上的 PyTorch 的测试版。我们衷心感谢我们敬业的社区所做的贡献。
总结
- 通过给定的一组参数功能性地应用模块计算的功能性 API
- PyTorch 中的 Complex32 和复杂卷积
- TorchData 的 DataPipes 与 DataLoader 完全向后兼容
- functorch 改进了 API 的覆盖范围
- nvFuser,一个用于 PyTorch 的深度学习编译器
- Ampere 及更高版本 CUDA 硬件上 float32 矩阵乘法精度的更改
- TorchArrow,一个用于批处理数据的机器学习预处理的新测试版库
前端 API
TorchArrow 简介
我们发布了一个新的 Beta 版本供您尝试和使用:TorchArrow。这是一个用于批处理数据的机器学习预处理库。它具有高性能和 Pandas 风格、易于使用的 API,以加快您的预处理工作流程和开发。
目前,它提供了一个带有以下功能的 Python DataFrame 接口:
- 高性能 CPU 后端,利用 Velox 实现向量化和可扩展的用户定义函数 (UDF)
- 与 PyTorch 或其他模型作者无缝衔接,例如张量整理,并轻松插入 PyTorch DataLoader 和 DataPipes
- 通过 Arrow 内存柱状格式实现外部读取器的零拷贝
有关更多详细信息,请查阅我们的10 分钟教程、安装说明、API文档以及 TorchRec 中数据预处理的原型。
(Beta)模块的功能性 API
PyTorch 1.12 引入了一个新的 Beta 功能,用于以给定的一组参数功能性地应用模块计算。有时,传统的 PyTorch 模块使用模式(在内部维护一组静态参数)过于严格。在实现元学习算法时,这通常是这种情况,其中可能需要在优化器步骤中维护多组参数。
新的 torch.nn.utils.stateless.functional_call() API 允许:
- 模块计算,对所用参数集具有完全灵活性
- 无需以函数式方式重新实现您的模块
- 模块中存在的任何参数或缓冲区都可以与外部定义的值交换以用于调用。引用参数/缓冲区的命名遵循模块
state_dict()中的完全限定形式
例子
import torch
from torch import nn
from torch.nn.utils.stateless import functional_call
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(3, 3)
self.bn = nn.BatchNorm1d(3)
self.fc2 = nn.Linear(3, 3)
def forward(self, x):
return self.fc2(self.bn(self.fc1(x)))
m = MyModule()
# Define parameter / buffer values to use during module computation.
my_weight = torch.randn(3, 3, requires_grad=True)
my_bias = torch.tensor([1., 2., 3.], requires_grad=True)
params_and_buffers = {
'fc1.weight': my_weight,
'fc1.bias': my_bias,
# Custom buffer values can be used too.
'bn.running_mean': torch.randn(3),
}
# Apply module computation to the input with the specified parameters / buffers.
inp = torch.randn(5, 3)
output = functional_call(m, params_and_buffers, inp)
(Beta)PyTorch 中的 Complex32 和复杂卷积
PyTorch 目前原生支持复数、复数自动求导、复数模块和许多复数操作,包括线性代数和快速傅里叶变换 (FFT) 运算符。包括 torchaudio 和 ESPNet 在内的许多库已经利用 PyTorch 中的复数,PyTorch 1.12 通过复杂卷积和实验性的 complex32(“复数半精度”)数据类型进一步扩展了复数功能,该数据类型支持半精度 FFT 操作。由于 CUDA 11.3 包中的错误,如果您正在使用复数,我们建议使用 wheel 中的 CUDA 11.6 包。
(Beta)前向模式自动微分
前向模式 AD 允许在前向传播中急切地计算方向导数(或等效地,雅可比向量积)。PyTorch 1.12 显著提高了前向模式 AD 的算子覆盖范围。有关更多信息,请参阅我们的教程。
TorchData
BC DataLoader + DataPipe
TorchData 的 `DataPipe` 在多进程和分布式环境中,关于 shuffle 确定性和动态分片方面,与现有的 `DataLoader` 完全向后兼容。
(Beta)AWS S3 集成
基于 AWSSDK 的 DataPipes 已集成到 TorchData 中。它提供以下由原生 AWSSDK 支持的功能:
- 根据前缀从每个 S3 存储桶检索 URL 列表
- 支持超时以防止无限期挂起
- 支持指定 S3 存储桶区域
- 从 S3 URL 加载数据
- 支持缓冲和多分段下载
- 支持指定 S3 存储桶区域
AWS 原生 DataPipes 仍处于 Beta 阶段。我们将继续对其进行调整以提高其性能。
(原型)DataLoader2
DataLoader2 已以原型模式发布。我们正在引入 DataPipes、数据加载 API 和后端(又称 ReadingServices)之间交互的新方式。该功能在 API 方面是稳定的,但功能上尚未完全完成。我们欢迎早期采用者和反馈,以及潜在的贡献者。
有关更多详细信息,请查看此链接。
functorch
受 Google JAX 的启发,functorch 是一个提供可组合 vmap(向量化)和自动微分转换的库。它支持在 PyTorch 中难以表达的高级自动微分用例。这些示例包括:
我们很高兴地宣布 functorch 0.2.0 版本,其中包含多项改进和新的实验性功能。
显著提高覆盖率
我们显著提高了 functorch.jvp(我们的前向模式自动微分 API)以及依赖于它的其他 API(functorch.{jacfwd, hessian})的覆盖率。
(原型)functorch.experimental.functionalize
给定一个函数 f,functionalize(f) 返回一个没有修改的新函数(有注意事项)。这对于构建没有原地操作的 PyTorch 函数的跟踪非常有用。例如,您可以使用 make_fx(functionalize(f)) 来构建 PyTorch 函数的无修改跟踪。要了解更多信息,请参阅文档。
有关更多详细信息,请参阅我们的安装说明、文档、教程和发行说明。
性能改进
nvFuser 简介,一个用于 PyTorch 的深度学习编译器
在 PyTorch 1.12 中,Torchscript 正在将其默认熔合器(用于 Volta 及更高版本的 CUDA 加速器)更新为 nvFuser,它支持更广泛的操作范围,并且比以前 CUDA 设备的熔合器 NNC 更快。一篇即将发布的博客文章将详细阐述 nvFuser 并展示它如何在各种网络上加速训练。
有关用法和调试的更多详细信息,请参阅 nvFuser 文档。
Ampere 及更高版本 CUDA 硬件上 float32 矩阵乘法精度的更改
PyTorch 支持多种“混合精度”技术,例如 torch.amp(自动混合精度)模块,以及在 Ampere 及更高版本的 CUDA 硬件上使用 TensorFloat32 数据类型执行 float32 矩阵乘法以加快内部计算。在 PyTorch 1.12 中,我们正在更改 float32 矩阵乘法的默认行为,使其始终使用完整的 IEEE fp32 精度,这比使用 TensorFloat32 数据类型进行内部计算更精确但更慢。对于 TensorFloat32 与 float32 吞吐量比例特别高的设备(例如 A100),此默认值更改可能会导致大幅减速。
如果您一直在使用 TensorFloat32 矩阵乘法,则可以通过设置 torch.backends.cuda.matmul.allow_tf32 = True 继续这样做
这自 PyTorch 1.7 起受支持。从 PyTorch 1.12 开始,也可以使用新的 matmul 精度 API:torch.set_float32_matmul_precision(“highest”|”high”|”medium”)
再次强调,PyTorch 的新默认设置为所有设备类型提供“最高”精度。我们认为这为矩阵乘法提供了更好的跨设备类型一致性。新精度 API 的文档可以在此处找到。将精度类型设置为“high”或“medium”将启用 Ampere 及更高版本 CUDA 设备上的 TensorFloat32。如果您正在更新到 PyTorch 1.12,则为了保持 Ampere 设备上矩阵乘法的当前行为和更快性能,请将精度设置为“high”。
使用混合精度技术对于高效训练许多现代深度学习网络至关重要,如果您已经在使用 torch.amp,则此更改不太可能影响您。如果您不熟悉混合精度训练,请参阅我们即将发布的“每个用户都应该了解的 PyTorch 混合精度训练”博客文章。
(Beta)通过 CPU 上的 Channels Last 加速 PyTorch Vision 模型
运行视觉模型时,内存格式对性能有显著影响,通常情况下,Channels Last 在性能方面更具优势,因为它具有更好的数据局部性。1.12 包含了内存格式的基本概念,并展示了在 Intel® Xeon® 可扩展处理器上使用 Channels Last 在流行 PyTorch 视觉模型上的性能优势。
- 在 CPU 上为 CV 领域常用操作符启用 Channels Last 内存格式支持,适用于推理和训练
- 提供 ATen 中 Channels Last 内核的本地级别优化,适用于 AVX2 和 AVX512
- 在 Intel® Xeon® Ice Lake(或更新)CPU 上,TorchVision 模型的推理性能比 Channels First 提高 1.3 倍至 1.8 倍
(Beta)使用 Bfloat16 增强 Intel® Xeon® 可扩展处理器上的 PyTorch
bfloat16 等降低精度数字格式可提高 PyTorch 在多个深度学习训练工作负载中的性能。PyTorch 1.12 包含 bfloat16 的最新软件增强功能,适用于更广泛的用户场景,并展示出更高的性能提升。主要改进包括:
- 与 float32 相比,通过 Intel® Xeon® Cooper Lake CPU 上引入的新 bfloat16 本机指令 VDPBF16PS,硬件计算吞吐量提高 2 倍
- 内存占用是 float32 的 1/2,内存带宽密集型操作符速度更快
- 在 Intel® Xeon® Cooper Lake(或更新)CPU 上,TorchVision 模型的推理性能比 float32 提高 1.4 倍至 2.2 倍
(原型)Mac 上加速 PyTorch 训练简介
随着 PyTorch 1.12 的发布,开发人员和研究人员现在可以利用 Apple 芯片 GPU 大幅加快模型训练。这使得在本地 Mac 上直接进行原型设计和微调等机器学习工作流程成为可能。通过使用 Apple 的 Metal Performance Shaders (MPS) 作为后端,可以实现加速 GPU 训练。其好处包括加速 GPU 训练带来的性能提升,以及能够在本地训练更大的网络或批次大小。在此处了解更多信息。
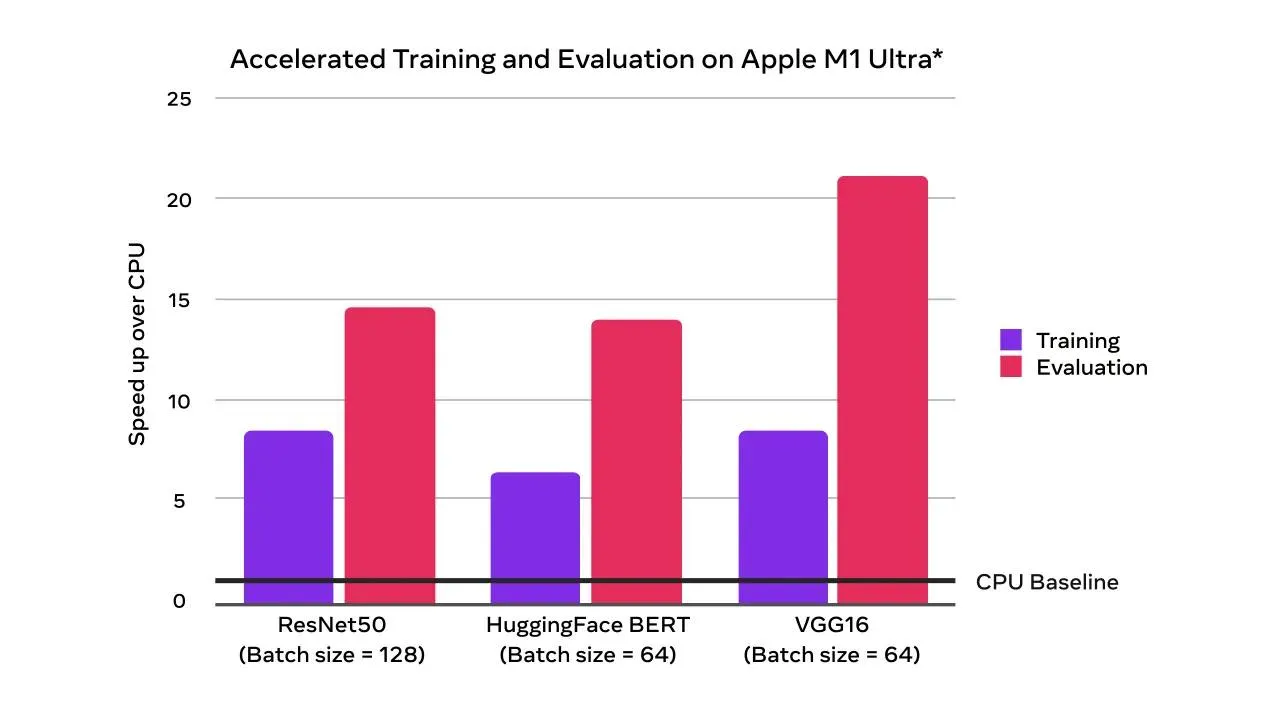
加速 GPU 训练和评估速度比仅 CPU 快(倍数)
除了新的 MPS 设备支持外,过去几个版本中提供的用于核心和领域库的 M1 二进制文件现已成为官方原型功能。这些二进制文件可用于在 Apple Silicon 上原生运行 PyTorch。
(原型)BetterTransformer:Transformer Encoder 推理的快速路径执行
PyTorch 现在支持多个 Transformer Encoder 模块(包括 TransformerEncoder、TransformerEncoderLayer 和 MultiHeadAttention (MHA))的 CPU 和 GPU 快速路径实现(“BetterTransformer”)。BetterTransformer 快速路径架构始终更快——对于许多常见的执行场景,根据模型和输入特性,速度提高 2 倍。新的支持 BetterTransformer 的模块与 PyTorch Transformer API 的先前版本 API 兼容,并且如果它们满足快速路径执行要求,将加速现有模型,并读取使用 PyTorch 先前版本训练的模型。PyTorch 1.12 包括:
- Torchtext 预训练 RoBERTa 和 XLM-R 模型的 BetterTransformer 集成
- Torchtext,它基于 PyTorch Transformer API 构建
- 通过融合内核(将多个操作符组合成一个内核)减少执行开销,从而提高性能的快速路径执行
- 通过利用自然语言处理中填充令牌处理期间的数据稀疏性来获得额外加速的选项(通过在创建 TransformerEncoder 时设置 enable_nested_tensor=True)
- 诊断工具可帮助用户了解快速路径执行未发生的原因
分布式
(Beta)全分片数据并行 (FSDP) API
FSDP API 通过将模型的参数、梯度和优化器状态分片到数据并行工作者中,同时保持数据并行的简单性,帮助轻松扩展大型模型训练。原型版本在 PyTorch 1.11 中发布,具有最少的功能集,帮助了具有多达 1T 参数的模型的扩展测试。
在此 Beta 版本中,FSDP API 添加了以下功能以支持各种生产工作负载。此 Beta 版本中新添加功能的主要亮点包括:
- 通用分片策略 API – 用户可以通过一行代码轻松更改分片策略,从而比较和使用 DDP(仅数据分片)、FSDP(完整模型和数据分片)或 Zero2(仅优化器和梯度分片)来优化内存和性能,以满足其特定的训练需求
- 细粒度混合精度策略 – 用户可以通过混合精度策略为模型参数、梯度通信和缓冲区指定半精度和全精度数据类型(bfloat16、fp16 或 fp32)的组合。模型会自动以 fp32 格式保存,以实现最大可移植性
- Transformer 自动封装策略 – 通过注册模型的层类,实现基于 Transformer 的模型的最佳封装,从而加速训练性能
- 使用 device_id init 更快地初始化模型 – 初始化以流式方式执行,以避免 OOM 问题并优化初始化性能,优于 CPU 初始化
- 大型模型的完整模型保存的 Rank0 流式传输 – 全分片模型可以通过所有 GPU 将其分片流式传输到 rank 0 GPU 来保存,并且模型在 rank 0 CPU 上以完整状态构建以进行保存
感谢阅读,如果您对这些更新感兴趣并希望加入 PyTorch 社区,我们鼓励您加入 讨论论坛 并 提交 GitHub issue。要获取 PyTorch 的最新消息,请在 Twitter、Medium、YouTube 和 LinkedIn 上关注我们。
干杯!
PyTorch 团队