
SuperOffload:在超级芯片上释放大规模 LLM 训练的强大潜力 ![]()


太长不看:在单个 NVIDIA GH200 上高效地对 GPT-OSS-20B 和 Qwen3-14B 模型进行全参数微调,以及……
当量化不足时:为何 2:4 稀疏性很重要 ![]()

太长不看:将 2:4 稀疏性与量化结合提供了一种强大的方法来压缩大型语言模型……
Mohammad Mozaffari, Jesse Cai, Supriya Rao2025 年 10 月 6 日
TorchAO 量化模型和量化方案现已在 HuggingFace Hub 上可用 ![TorchAO Quantized Models and Quantization Recipes Now Available on HuggingFace Hub]()

PyTorch 现在通过与 Meta 合作提供 Phi4-mini-instruct、Qwen3、SmolLM3-3B 和 gemma-3-270m-it 的原生量化变体……

在 Intel CPU 上使用原生 PyTorch 进行高性能量化 LLM 推理 ![]()

PyTorch 2.8 刚刚发布,带来了一系列令人兴奋的新功能,包括……
Intel PyTorch 团队2025 年 9 月 17 日
PyTorch 2.8 为 Intel GPU 带来原生 XCCL 支持:来自阿贡国家实验室的案例研究 ![]()

Intel 宣布 PyTorch 2.8 在分布式训练方面取得了重大增强:原生集成……
Intel PyTorch 团队, 阿贡国家实验室2025 年 9 月 12 日




PyTorch 2.8+TorchAO:在 Intel® AI PC 上释放高效 LLM 推理 ![]()

大型语言模型 (LLM) 已经彻底改变了我们撰写和消费文档的方式。在过去……
Intel PyTorch 团队2025 年 9 月 3 日
使用 TorchAO、MXFP8 和 TorchTitan 在 Crusoe B200 集群上将 2K 规模的预训练加速至 1.28 倍 ![]()

太长不看:使用 MXFP8 将训练加速 1.22 倍 - 1.28 倍,与 BF16 相比收敛性相同。我们最近……

DRAMA 模型推理效率提升 1.7 倍至 2.3 倍 ![]()

太长不看:NJT(嵌套锯齿张量)将 DRAMA 模型推理效率提升 1.7 倍至 2.3 倍,使其更……
Shreya Goyal2025 年 8 月 22 日

使用 Triton 持久缓存感知分组 GEMM 内核加速 MoE ![]()
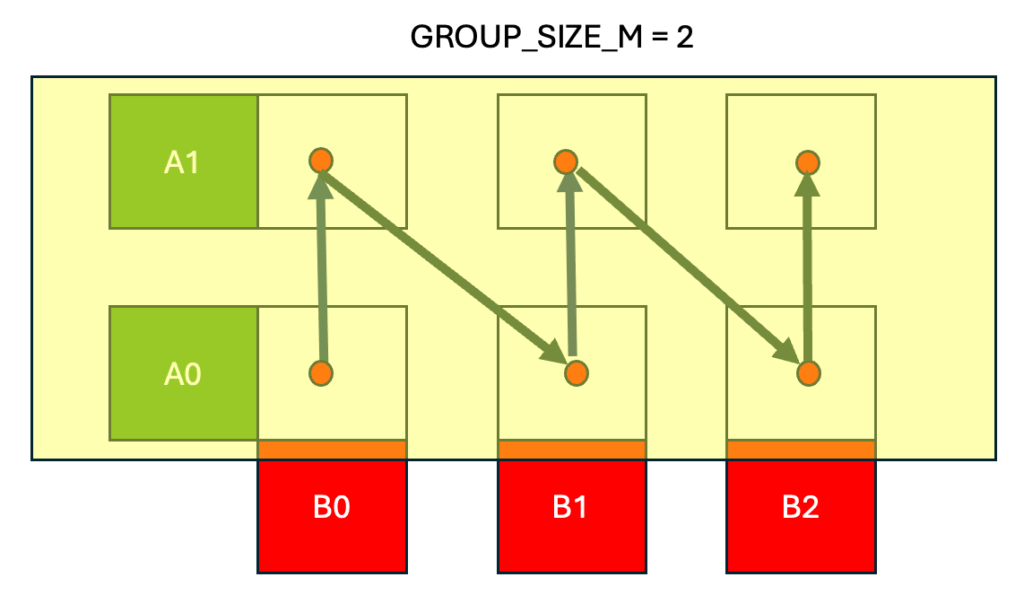
在这篇文章中,我们介绍了用于运行训练的优化 Triton BF16 分组 GEMM 内核……
Less Wright, Adnan Hoque, Garrett Goon2025 年 8 月 18 日
PyTorch Wheel 变体,Python 打包的前沿 ![]()

uv 的创建者 charliemarsh 的推文:PyTorch 是用于开发和……的领先机器学习框架。
Eli Uriegas2025 年 8 月 13 日
PyTorch Day China 回顾 ![]()

2025 年 6 月 7 日,PyTorch Day China 在北京举行,由 PyTorch 基金会联合主办…
PyTorch Foundation2025 年 8 月 12 日
Opacus 中引入混合精度训练 ![]()

引言 我们将混合精度和低精度训练与 Opacus 集成,以实现更高的吞吐量和训练……
Iden Kalemaj, Huanyu Zhang2025 年 8 月 12 日