前沿 AI 模型变得极其庞大。训练这些模型的成本和开销迅速增加,并且需要大量的工程设计和猜测才能找到正确的训练方案。FSDP 通过让您使用相同数量的资源训练更大的模型,显著降低了这些成本。FSDP 降低了 GPU 的内存占用,并且可以通过轻量级配置使用,通常只需几行代码,大大减少了工作量。
FSDP 的主要性能提升来自最大化网络通信和模型计算之间的重叠,并消除了传统数据并行训练 (DDP) 中固有的内存冗余。PyTorch FSDP 可以在与 DDP 相同的服务器资源上训练大约 4 倍大的模型,如果结合激活检查点和激活卸载,则可以训练 20 倍大的模型。
自 PyTorch 1.12 起,FSDP 现已处于测试阶段,并新增了许多可调优以进一步加速模型训练的功能。
在本系列博客文章中,我们将解释您可以使用 FSDP 运行的多种性能优化,以在可用服务器资源的背景下提高分布式训练速度和模型大小。我们将 HuggingFace T5 3B、11B 和 DeepVit 在微调模式下作为本系列的运行示例。
作为本系列讨论的一些优化的预览,我们展示了 Flops 中的性能对比(请注意,这些结果可能因您的服务器资源和模型架构而异)。
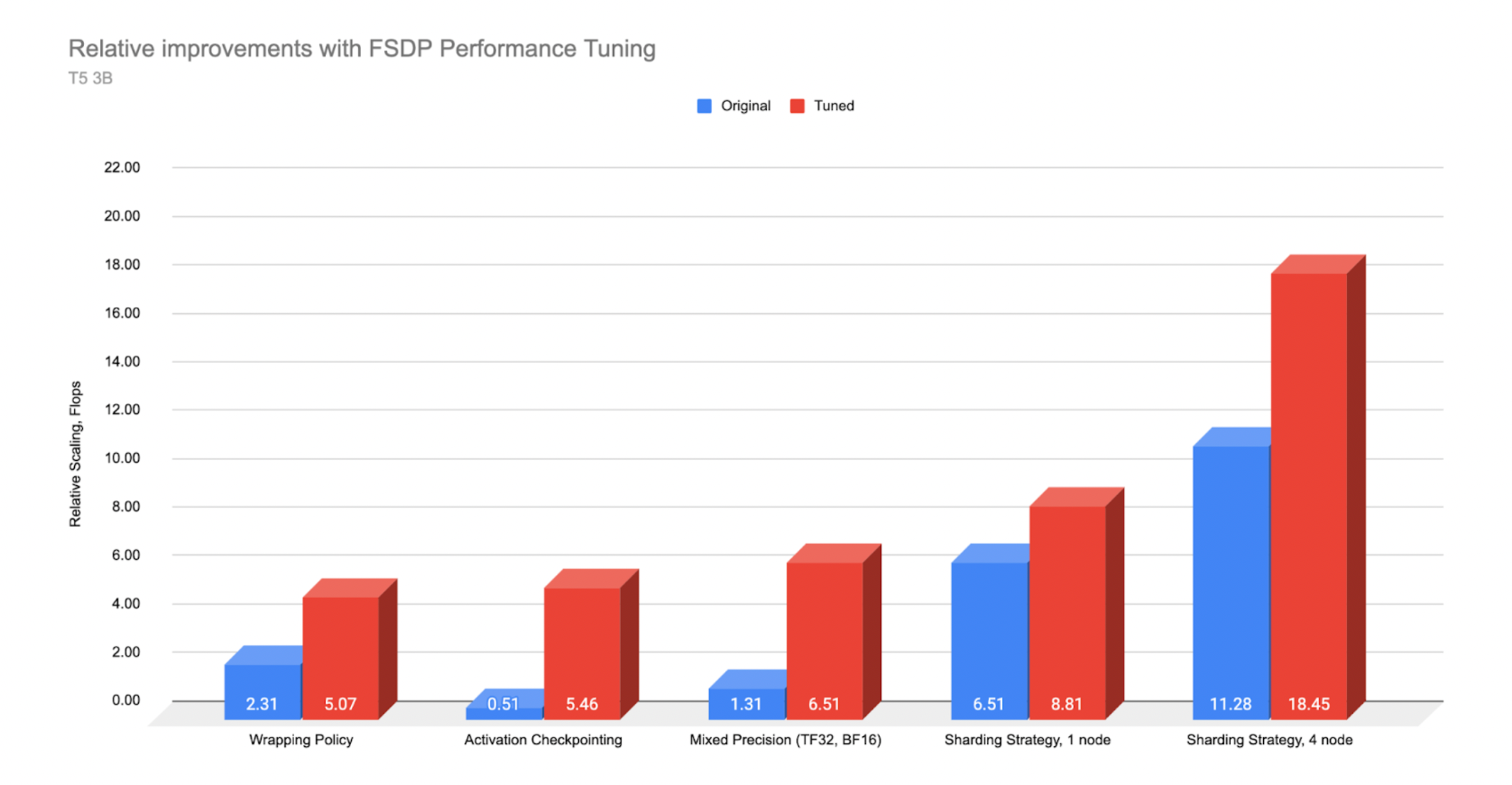
*T5 3B 性能在 AWS A100 和 A10 服务器上测量。原始版本未优化,调优版本应用了优化。
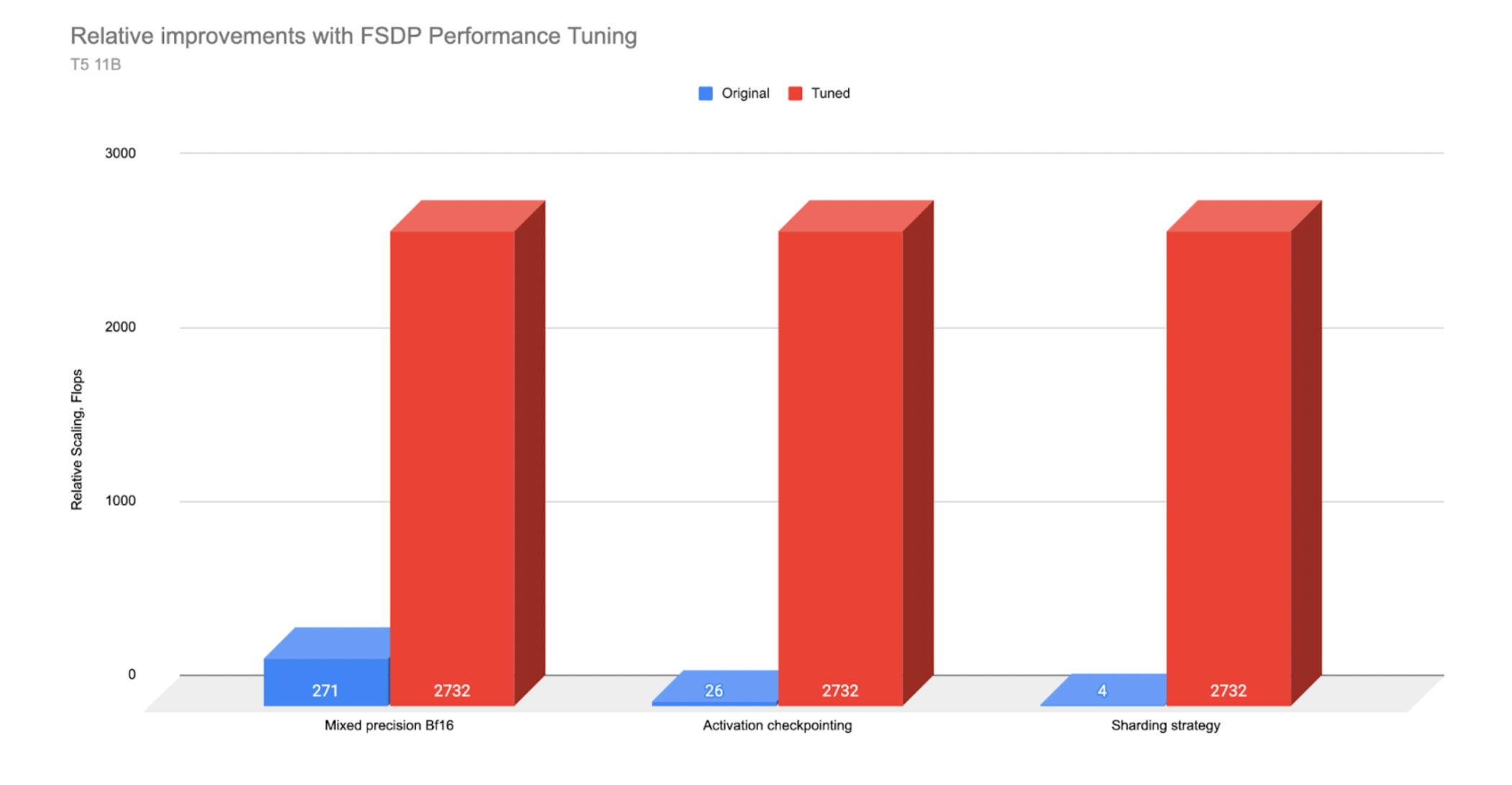
*T5 11B 性能在 A100 服务器上测量。原始版本未优化,调优版本应用了优化。
在第一篇文章中,我们将简要概述 FSDP 以及它如何使大规模 AI 模型训练更高效。我们将简要强调可用的多种性能选项,并在后续文章中深入探讨这些细节。然后,我们将总结如何利用 AWS ParallelCluster 进行 FSDP 大规模训练。
| 优化 | T5 模型 | 吞吐量提升 |
| 混合精度 | 3 B | 5 倍 |
| 11 B | 10 倍 | |
| 激活检查点 (AC) | 3 B | 10 倍 |
| 11 B | 100 倍 | |
| Transformer 封装策略 | 3 B | 2 倍 |
| 11 B | 无法在没有 Transformer 封装策略的情况下运行实验。 | |
| 全分片策略 | 3 B | 1.5 倍 |
| 11 B | 无法与 Zero2 一起运行 |
T5 模型在未优化基础上的性能优化增益。
在我们使用 T5 3B 模型进行的实验中,使用Transformer 封装策略导致吞吐量(以 TFLOPS 衡量)比默认封装策略高出 2 倍以上。激活检查点通过将检查点释放的内存重新投入到更大的批量大小中,带来了 10 倍的改进。混合精度与 BFloat16 相比 FP32 带来了约 5 倍的改进,最后全分片策略与 Zero2 (DDP) 相比带来了 1.5 倍的改进。
我们对更大的模型 T5 11B 进行了类似的实验,但更大的模型大小导致实验空间发生了一些变化。具体来说,我们发现需要两种优化:Transformer 封装策略和激活检查点,才能在 3 个节点(每个节点有 8 个 A100 GPU,80GB 内存)上运行这些实验。通过这些优化,我们可以适应 50 的批量大小,并获得比单独移除其中任何一个更高的吞吐量。因此,对于 11B 模型,我们没有像 3B 模型那样仅仅针对单一优化进行开/关测试,而是对 3 种优化中的 1 种进行开/关测试,同时始终运行另外两种优化,以便在每个项目的两种测试状态下都能使用可用的批量大小。
根据 TFLOP 比较,对于 11B 模型,我们从优化中获得了更大的收益。混合精度(约 10 倍改进)和激活检查点(约 100 倍改进)对 11B 模型的影响比 3B 参数模型更大。通过混合精度,我们可以适应约 2 倍大的批量大小,通过激活检查点,可以适应 >15 倍大的批量大小(从没有激活检查点的 3 增加到有激活检查点的 50),这转化为巨大的吞吐量改进。
我们还观察到,对于这些大于 3B 的模型,使用 Zero2 分片策略会导致内存中用于批量数据剩余空间极小,必须使用非常小的批量大小(例如 1-2),这使得全分片策略成为启用更大批量大小的必要条件。
注意 – 本教程假设您对 FSDP 有基本了解。要了解 FSDP 的基础知识,请参阅入门和高级 FSDP 教程。
什么是 FSDP?它如何提高大规模训练效率
FSDP 扩展了分布式数据并行,不仅并行化数据,还并行化模型参数、优化器状态以及与模型相关的梯度。具体来说——每个 GPU 只存储整个模型的子集以及相关的优化器状态和梯度子集。
为了展示分布式训练的演变,我们可以从最初开始,当时 AI 模型只是在单个 GPU 上进行训练。
DDP (分布式数据并行) 是从单个 GPU 训练到分布式训练的初步提升,旨在解决数据和模型规模增长的问题,其中多个 GPU 各自拥有同一模型的副本。这里的优势在于,每个批次的数据可以同时在每个 GPU 上独立拆分和处理,从而并行化数据集的处理,并通过增加 GPU 数量来提高训练速度。缺点是需要在反向传播后在每个 GPU 之间通信梯度以同步模型。
FSDP 通过消除 DDP (DDP = 分布式数据并行) 中存在的优化器计算和状态存储以及模型参数的梯度和内存存储的冗余来扩展模型缩放。这种冗余减少,以及增加通信重叠(模型参数通信与模型计算同时进行),使得 FSDP 能够以与 DDP 相同的资源训练更大的模型。
一个关键点是,这种效率还允许训练大于单个 GPU 的 AI 模型。现在可用于训练的模型大小已增加到所有 GPU 的聚合内存,而不是单个 GPU 的大小。(值得注意的是,FSDP 还可以通过利用 CPU 内存超越聚合 GPU 内存,尽管我们在这里不直接讨论这方面)。
正如之前一篇博客文章所讨论的,使用 DDP,我们可以在 32 个 A100 GPU(每个 40GB 内存,4 个节点)上训练的最大模型是 3B 参数,批量大小为 128,并借助激活检查点。相比之下,使用 FSDP,我们能够训练高达 81B 的模型大小,结合了激活检查点以及激活和参数卸载。在另一次实验中,我们使用 512 个 GPU 和 FSDP 对一个 1T 参数模型进行了基准测试。

为了直观理解 FSDP 的参数级别工作原理,下面我们展示了一个动画,详细说明了在两个 GPU 场景和一个简单的 8 参数模型中,模型参数是如何进行分片和通信的。
上方——动画逐步展示了模型在各等级之间初始分片的过程,我们开始执行 `all_gathers` 和前向传播。

我们继续通过前向传播遍历模型。每个 FSDP 单元完成后,非本地拥有的参数将被丢弃以释放内存,并且可以选择对激活进行检查点。这个过程一直持续到我们完成前向传播并计算损失。

在反向传播过程中,使用另一个 `all_gather` 来加载参数并计算梯度。然后,这些梯度被 `reduce_scatter`,以便每个参数的本地所有者可以聚合并准备更新权重。
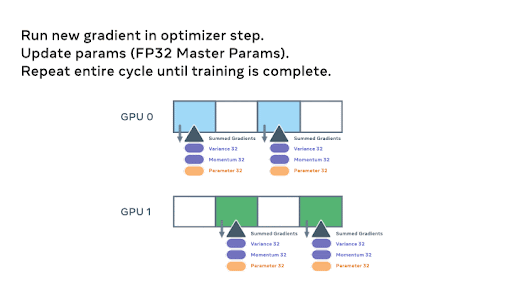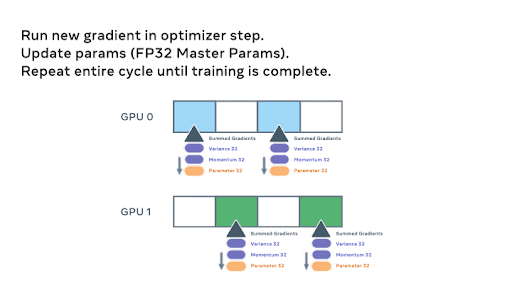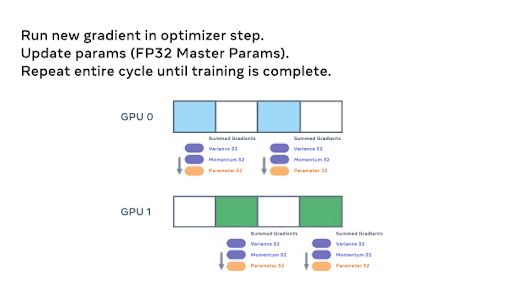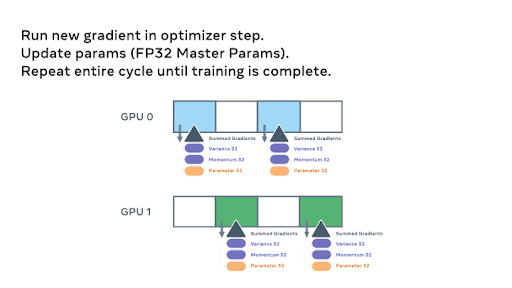
最后,每个等级通过优化器状态传递求和梯度并更新权重以完成小批量。
模型现在分布在所有可用的 GPU 上,那么一个合理的问题是数据如何通过模型移动,考虑到模型参数的分片。
这通过 FSDP 与所有 GPU 协调来有效共享(通信)模型的各个部分来实现。模型被分解为 FSDP 单元,每个单元内的参数被展平,然后跨所有 GPU 进行分片。在每个 FSDP 单元内,GPU 被分配交错拥有单个模型参数。
通过交错,我们的意思是——假设有两个 GPU,ID 分别为 1 和 2,FSDP 单元的所有权模式将是 [12121212],而不是连续的 [111222] 块。
在训练期间,会启动一个 `all_gather`,FSDP 单元内本地拥有的模型参数由所有者 GPU 在需要时以“即时”类型的基础与非所有者共享。FSDP 会预取参数以实现 `all_gather` 通信与计算的重叠。
当那些请求的参数到达时,GPU 使用所交付的参数,结合其已经拥有的参数,来创建一个完全填充的 FSDP 单元。因此,在某个时刻,每个 GPU 在持有完全填充的 FSDP 单元时会达到峰值内存使用量。
然后,它通过 FSDP 单元处理数据,并丢弃从其他 GPU 接收到的参数以释放内存供下一个单元使用……这个过程一遍又一遍地进行,通过整个模型完成前向传播。然后(通常)为反向传播重复此过程。(注意——这是一个简化的理解版本……存在额外的复杂性,但这应该有助于构建 FSDP 过程的基本心智模型)。
这消除了 DDP 中存在的许多内存冗余,但增加了在所有 GPU 之间来回传输这些请求参数的更高网络通信成本。将通信时间与正在进行的计算重叠是我们将在本系列中讨论的许多性能改进的基础。 关键收益通常基于通信可以与计算同时发生的事实。正如您所推测的,拥有高速通信对 FSDP 性能至关重要。
我如何使用 FSDP 优化我的训练?
我们将介绍四种主要的性能改进——Transformer 封装器、激活检查点、混合精度以及选择合适的分片策略。下面的流程图将作为一个核对清单,帮助您检查本文中将讨论的调优选项。
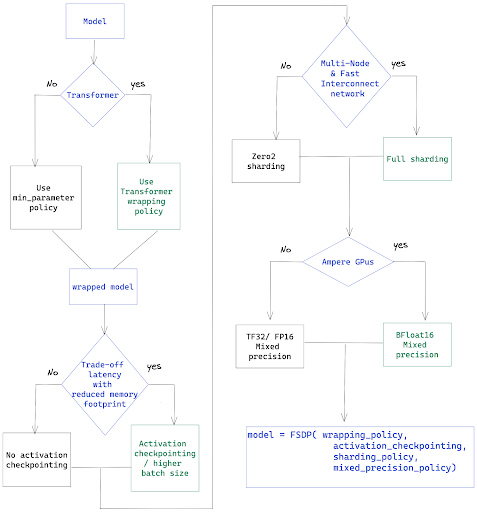
封装策略——对于 Transformer,使用 Transformer 封装策略
第一个性能优化是利用 FSDP Transformer 封装器用于 Transformer 模型。
其中一个预定义的封装策略是`size_based_autowrap_policy`。使用`size_based_autowrap_policy`,FSDP将从下到上遍历模块结构,一旦当前单元的参数数量至少达到大小策略中指定的`min_num_params`(默认为1e8,即1亿),就会创建一个新的FSDP单元。如果模块无法创建为FSDP单元,FSDP将继续检查其父模块。这种基于大小的封装策略可能不适用于某些模型结构,PyTorch分布式团队正在积极开发下一个版本中基于大小和模块执行顺序的新默认封装策略,用户可以简单地调整大小并实现优化性能。
在当前版本中,您可以通过使用“Transformer 封装器”大大提高运行 Transformer 模型时的性能。您需要为模型提供适当的层类。这里,层类是包含多头注意力(Multi-Head Attention)和前馈网络(Feed Forward Network)的类。
FSDP 将围绕层类形成 FSDP 单元,而不是基于参数大小进行任意分割。通过围绕 Transformer 中统一重复的层类进行模型分片,FSDP 可以创建统一的 FSDP 单元,从而更好地平衡计算和通信的重叠。相比之下,基于大小的封装可能会为模型产生非常不均匀或倾斜的分片,从而导致计算与通信重叠不匹配。如前所述,FSDP 高性能的主要驱动力是通信和计算的重叠,因此 Transformer 封装器提供了改进的性能。请注意,如果非 Transformer 模型具有统一的层列表,也可以使用 Transformer 封装器。
让我们比较在默认封装器和 Transformer 封装器下运行 T5 3B 参数模型时的性能差异。
对于默认封装,我们不需要采取任何操作——我们只需将模型传递给 FSDP,如下所示:
model = FSDP(
model,
device_id=torch.cuda.current_device(),
)
在这种情况下,FSDP 将简单地将整个模型封装在一个 FSDP 单元中。
在配备 8 个 GPU 的NVIDIA A100-SXM4-40GB 上运行,我们能够达到 2.3 TFlops 的性能,GPU 内存利用率达到 95%,批量大小为 14。
然而,由于 T5 是一个 Transformer 模型,我们最好利用 Transformer 封装器来处理这个模型。
要使用它,我们需要隔离 Transformer 的层类,然后将其传递进去以创建我们的 Transformer 封装器。
from transformers.models.t5.modeling_t5 import T5Block
现在我们可以创建我们的 Transformer 封装器了
transformer_auto_wrapper_policy = functools.partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
T5Block, # < ---- Your Transformer layer class
},
)
有了模型感知的封装器,我们就可以初始化 FSDP 了。
# invoke FSDP with your transformer wrapper policy:
model = FSDP(
model,
auto_wrap_policy=transformer_auto_wrapper_policy,
device_id=torch.cuda.current_device(), # streaming init
)
运行这个封装后的模型,我们可以看到显著的性能提升。我们几乎可以容纳两倍的批量大小,达到 28,并且在更好的内存和通信效率下,TFlops 从 2.3 增加到 5.07。
因此,由于向 FSDP 提供了更多的模型信息,我们使训练吞吐量提高了 200% 以上(2.19 倍)!Transformer 封装策略导致了更细粒度且平衡的 FSDP 单元,每个单元包含一个层类,从而实现了更有效的通信-计算重叠。
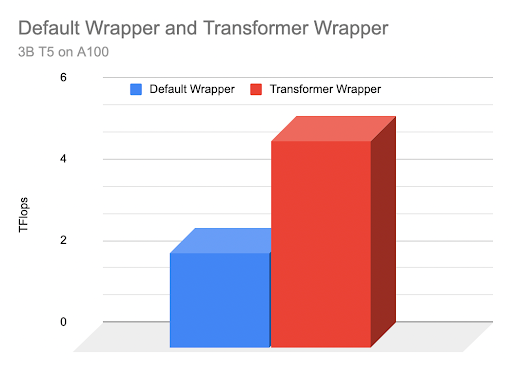
上方:基于封装器类型的 TFlops 图形比较
如果您正在训练 Transformer 模型,使用 Transformer 封装器配置 FSDP 训练是值得的。有关如何隔离层类的更多信息,请参阅我们关于 Transformer 封装的深度视频此处,其中我们演示了如何找到许多 Transformer 模型中的层类。
混合精度——如果您有 Ampere 架构 GPU,请使用 BF16
FSDP 支持灵活的混合精度策略,让您可以精细控制参数、梯度和缓冲区数据类型。这使您可以轻松利用 BFloat16 或 FP16 将训练速度提高高达 70%。
*请注意,BFloat 16 仅适用于 Ampere 型 GPU。在 AWS 上,p4dn 和 g5 实例提供此功能。
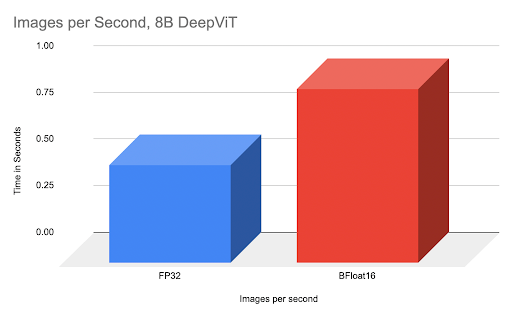
通过比较,我们可以看到在 8B DeepVit 模型上,完全调优的 BFloat16 与 FP32 相比,速度提高了 77%。
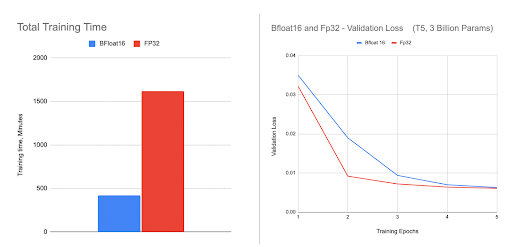
如图所示,在对 3B HuggingFace T5 模型进行微调时,使用 BFloat16 取得了更大的加速。我们观察到,由于精度较低,BFloat16 的验证损失在前几个 epoch 略微落后,但它能够追赶上来,并最终达到与 FP32 相同的准确率。
要使用混合精度,我们创建一个包含所需数据类型的策略,并在 FSDP 初始化期间将其传入。
为了创建我们的策略,我们需要导入 MixedPrecision 类,然后使用我们的定制类定义我们的自定义策略。
from torch.distributed.fsdp import MixedPrecision
bfSixteen = MixedPrecision(
param_dtype=torch.bfloat16,
# Gradient communication precision.
reduce_dtype=torch.bfloat16,
# Buffer precision.
buffer_dtype=torch.bfloat16,
)
model = FSDP(
model,
auto_wrap_policy=transformer_auto_wrapper_policy,
mixed_precision=bfloatPolicy)
您可以根据自己的喜好混合搭配参数、梯度和缓冲区的精度。
comboPolicy = MixedPrecision(
# Param precision
param_dtype=torch.bfloat16,
# Gradient communication precision.
reduce_dtype=torch.float32,
# Buffer precision.
buffer_dtype=torch.float32,
)
对于 FP16 训练,您还需要使用 ShardedGradScaler,我们将在后续文章中介绍。对于 BFloat16,它是即插即用的替代方案。
AnyPrecision 优化器——超越混合精度,实现纯 BF16 训练
混合精度训练,无论是在 FSDP 还是其他地方,都会将工作权重保持在缩小的日期类型(BF16 或 FP16)中,同时将主权重保持在完整的 FP32 中。主权重使用 FP32 的原因是,纯 BF16 运行会导致“权重停滞”,即由于精度较低,非常小的权重更新会丢失,并且精度会随着时间推移而趋于平稳,而 FP32 权重可以继续通过这些小的更新而改进。
为了解决这个难题,我们可以使用 TorchDistX (Torch Distributed Experimental) 中提供的新的 AnyPrecision 优化器,它允许您成功训练并将主权重保持在纯 BF16 而不是 FP32 中。此外,与典型的 FP32 优化器状态存储不同,AnyPrecision 还可以将状态保持在纯 BF16 中。
AnyPrecision 通过维护一个额外的缓冲区来实现纯 BF16 训练,该缓冲区跟踪权重更新过程中丢失的精度,并在下一次更新时重新应用,从而有效地解决了权重停滞问题,而无需 FP32。
为了比较使用 AnyPrecision 进行纯 BF16 训练可获得的吞吐量增益,我们使用 FSDP 和 T5 11B 模型进行了实验,其中包括常规 FP32 训练、BF16 混合精度训练以及使用 AnyPrecision 优化器在 3 个节点上使用 A100 GPU 进行的纯 BF16 训练,如前所述。
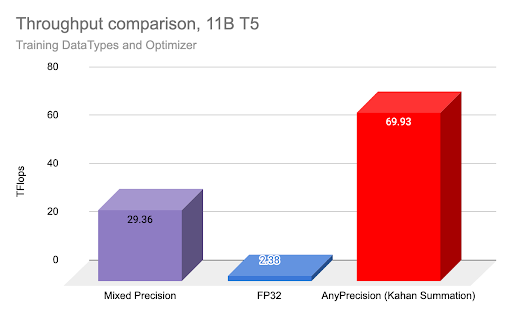
如上所示,使用 AnyPrecision 和纯 BF16 进行训练的吞吐量是混合精度的 2 倍,是 FP32 的 20 倍以上。
潜在的权衡是对最终准确性的影响——在我们测试的案例中,由于精度略微降低带来的正则化效应,准确性与 FP32 相同或更好,但您的结果可能会有所不同。
AnyPrecision 优化器可在此处测试,并且是 AdamW 优化器的即插即用替代品。
激活检查点——通过计算换取内存来提高吞吐量
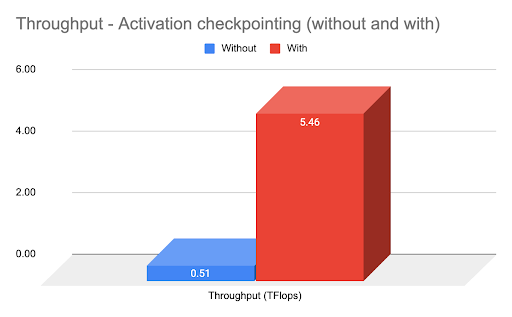
FSDP 在模型分片后支持激活检查点,并且易于实现。上图显示使用激活检查点可将吞吐量提高约 4 倍。
激活检查点是在前向传播期间释放中间激活,并留下一个检查点作为占位符。这通常会使可用 GPU 内存增加 30% 以上。
缺点是,在反向传播期间,这些先前删除的中间激活必须使用检查点中的信息重新计算(重复计算),但是通过利用增加的 GPU 内存,可以增加批量大小,从而使净吞吐量显着增加。
# verify we have FSDP activation support ready by importing:
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import (
checkpoint_wrapper,
CheckpointImpl,
apply_activation_checkpointing_wrapper,
)
实现激活检查点所需的步骤是首先导入 FSDP 检查点函数。我们需要声明我们的检查点封装器类型(它是不可重入的),并创建一个检查函数来识别要封装的层,如下所示:
non_reentrant_wrapper = partial(
checkpoint_wrapper,
offload_to_cpu=False,
checkpoint_impl=CheckpointImpl.NO_REENTRANT,
)
check_fn = lambda submodule: isinstance(submodule, T5Block)
apply_activation_checkpointing_wrapper(
model, checkpoint_wrapper_fn=non_reentrant_wrapper, check_fn=check_fn
)
重要提示——这必须在模型通过 FSDP 初始化后运行。
然而,希望您已经看到,FSDP 选项的一些初始调整如何对您的训练性能产生巨大影响。
接下来,我们将把注意力从 FSDP 内部的扩展转向如何使用 AWS 为 FSDP 扩展服务器硬件。
使用 AWS 进行 FSDP 大规模训练——多节点优先考虑高速网络
AWS 提供了多种服务可用于运行 FSDP 分布式训练:Amazon EC2 加速计算实例、AWS ParallelCluster 和 Amazon Sagemaker。
在本系列博客文章中,我们使用了Amazon EC2 p4d实例,采用单实例多 GPU 配置和多实例配置,使用 AWS ParallelCluster 和 SageMaker 来运行我们的训练作业。
在这里,我们将重点介绍 AWS ParallelCluster,并概述如何将其用于训练目的。
AWS ParallelCluster 设置
AWS ParallelCluster 是一个开源集群管理工具,可让您轻松地在 AWS 上部署和管理高性能计算 (HPC) 集群。AWS ParallelCluster 使用 yaml 配置文件来预置所有必要的资源。它还支持多种实例类型、作业提交队列、共享文件系统(如Amazon EFS (NFS) 或Amazon FSx for Lustre)以及作业调度程序(如 AWS Batch 和 Slurm)。

集群工作流程
其核心思想是拥有一个包含头节点(控制计算节点)的集群。实际的训练作业在计算节点上运行。在集群上运行训练作业的总体步骤如下:
- 设置 AWS ParallelCluster(我们将在下面讨论)
- 连接到头节点,并导入训练代码/设置环境。
- 拉取数据并将其放置在计算节点可以访问的共享文件夹中(FSx Lustre 驱动器)。
- 使用作业调度程序(本例中为 Slurm)运行训练作业。
设置 AWS ParallelCluster
要设置 AWS ParallelCluster,
- 部署网络栈。此步骤是可选的,因为您可以使用您的账户默认 VPC,让 AWS ParallelCluster 创建您的子网和安全组。但是,我们更喜欢将我们所需的网络基础设施进行分区,并通过 CloudFormation 栈进行部署。由于我们部署了一个公共子网和一个私有子网,我们希望将它们创建到包含我们目标实例(本例中为 p4d)的可用区中。我们通过以下 AWS CLI 命令查询它们在我们使用的区域(us-east-1)中的可用性:
aws ec2 describe-instance-type-offerings --location-type availability-zone \ --filters Name=instance-type,Values=p4d.24xlarge --region us-east-1 --output table我们看到三个包含 p4d 实例的可用区,我们选择其中一个(us-east-1c,您的可能不同)来部署我们的网络栈。这可以通过 AWS 控制台或 AWS CLI 完成。在我们的案例中,我们使用后者,如下所示:aws cloudformation create-stack --stack-name VPC-Large-Scale --capabilities CAPABILITY_IAM --template-body file://VPC-Large-Scale.yaml --parameters ParameterKey=SubnetsAZ,ParameterValue=us-east-1cCloudFormation 将代表我们部署新的 VPC、子网、安全组和端点。完成后,您可以通过查询栈输出以及值PublicSubnet和PrivateSubnet来检索公共子网和私有子网的 ID。例如,使用 AWS CLI 查询私有子网:aws cloudformation describe-stacks --stack-name VPC-Large-Scale --query "Stacks[0].Outputs[?OutputKey=='PrivateSubnet'].OutputValue" --output text - 创建 ParallelCluster,集群配置文件指定了我们集群的资源。这些资源包括头节点、计算节点的实例类型、对 S3 桶的访问权限、以及我们将数据存储的共享存储。我们将使用 Amazon FSx for Lustre,它提供了一个完全托管的基于 Lustre 的共享存储服务。此处是一个集群配置文件的示例。我们可以使用 AWS ParallelCluster CLI 来创建集群。请注意,私有和公共子网 ID 需要替换为您之前检索到的 ID。您将能够使用 AWS ParallelCluster CLI 控制集群,以启动、停止、暂停等操作。
pcluster create-cluster --cluster-name my-hpc-cluster --cluster-configuration cluster.yaml - SSH 到头节点 – 一旦集群准备就绪,我们就可以使用 SSH 协议连接到头节点,拉取我们的训练代码,并将数据放置在集群配置文件中指定的共享存储中。
pcluster ssh --cluster-name cluster -i your-key_pair - 启动训练作业 – 既然我们有了数据和训练代码,我们就可以启动用于训练的 slurm 作业了。这是一个使用 torchrun 启动作业的 slurm 脚本示例。
有关如何设置集群的更多详细信息超出了本文的范围,但是我们将在单独的文章中讨论它。
下一步是什么?
通过本文,我们提供了 FSDP 的高级概述以及它如何高效地扩展分布式 AI 训练。所附的流程图将提供一个核对清单,帮助您回顾讨论的调优选项,例如 Transformer 封装器和激活检查点。
在接下来的文章中,我们将继续使用 T5 模型,并深入探讨上述每个主题,特别是分片策略和其他优化,以提供更多见解和细节。目前,分片策略的一个很好的参考是我们的视频教程此处。
如果您有问题或发现问题,请联系作者Less、Hamid 和 Geeta,或在PyTorch github 上提交问题。
特别感谢
PyTorch 分布式团队、沈黎、Rohan Varma、闫立钊、Andrew Gu、Anjali Sridhar、Ana Simoes、Pierre-Yves Aquilanti、Sundar Ranganathan,以及更广泛的 AWS 团队,感谢他们为我们提供基础设施和技术支持,以运行大规模实验。
资源