主要收获
- PyTorch 和 vLLM 已有机集成,以加速尖端生成式 AI 应用,例如推理、训练后和代理系统。
- 预填充/解码解耦是一项关键技术,可在大规模下同时提高生成式 AI 推理的延迟和吞吐量效率。
- 预填充/解码解耦已在 Meta 内部推理堆栈中启用,服务于大规模 Meta 流量。通过 Meta 和 vLLM 团队的协作努力,Meta vLLM 解耦实现已证明其性能优于 Meta 内部 LLM 推理堆栈。
- Meta 的优化和可靠性增强正在向上游 vLLM 社区贡献。
在我们之前的文章《PyTorch + vLLM》中,我们分享了 vLLM 加入 PyTorch 基金会的激动人心的消息,并强调了 PyTorch 和 vLLM 之间的一些集成成就以及计划中的举措。其中一个关键举措是用于推理的大规模预填充-解码 (P/D) 解耦,旨在提高 Meta LLM 产品的吞吐量,同时满足延迟预算。在过去的两个月中,Meta 工程师投入了大量精力来实现与 vLLM 的内部 P/D 解耦集成,从而在 TTFT (首次生成令牌时间) 和 TTIT (迭代生成令牌时间) 指标方面,与 Meta 现有的内部 LLM 推理堆栈相比,性能有所提高。vLLM 与 llm-d 和 dynamo 有原生集成。在 Meta 内部,我们开发了抽象层,可以加速 KV 传输到我们的服务集群拓扑和设置。本文将重点介绍 Meta 对 vLLM 的定制以及与上游 vLLM 的集成。
解耦预填充/解码
在 LLM 推理中,第一个令牌依赖于用户提供的输入提示令牌,所有后续令牌以自回归方式一次生成一个令牌。我们将第一个令牌的生成称为“预填充”,将剩余令牌的生成称为“解码”。
虽然运行的都是基本相同的操作集,但预填充和解码表现出截然不同的特性。一些显著的特性是
- 预填充
- 计算密集型
- 令牌长度和批量大小限制延迟
- 每个请求发生一次
- 解码
- 内存密集型
- 批量大小限制效率
- 在整体延迟中占主导地位
预填充/解码解耦旨在将预填充和解码解耦到单独的主机中,其中解码主机将请求重定向到预填充主机以进行第一个令牌生成,并自行处理剩余部分。我们打算独立扩展预填充和解码推理,从而实现更高效的资源利用,并提高延迟和吞吐量。
vLLM 集成概述
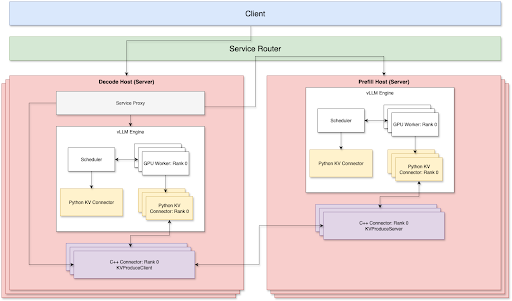
目前,预填充和解码两侧都支持 TP + Disagg。为了通过 TCP 网络实现最佳的 P/D 解耦服务,有 3 个关键组件
- 代理库
- Python KV 连接器
- C++ 解码 KV 连接器和预填充 KV 连接器,通过 TCP 连接
我们通过路由器层处理路由,该层负责负载均衡并通过 P2P 方式连接预填充节点和解码节点,以减少网络开销。预填充节点和解码节点可以根据自己的工作负载独立扩展或缩减。因此,在生产环境中运行时,我们不需要手动维护预填充:解码比率。
组件
服务代理
服务代理连接到解码服务器。它将请求转发到远程预填充主机,并协调解码和预填充 KV 连接器之间的 KV 缓存传输。我们使用 Meta 的内部服务路由器解决方案,根据服务器工作负载和缓存命中率在所有预填充主机之间进行负载均衡。
- 服务代理首先将传入请求转发到选定的预填充主机,同时建立多个流通道,通过底层的 Meta C++ 连接器从同一预填充主机获取 KV 缓存。
- 获取的远程 KV 缓存将首先复制到临时 GPU 缓冲区,等待 vLLM KV 连接器稍后将其注入到适当的 KV 块中。
vLLM Python KV 连接器
我们基于 vLLM v1 KV 连接器接口 实现了一个异步 KV 连接器解决方案。KV 连接器将与主模型执行流并行进行 KV 缓存传输操作,并确保双方的 GPU 操作没有冲突。通过这样做,我们实现了更快的 TTIT/TTFT;优化细节可以在下面部分找到。
- 在预填充端
- Python KV 连接器将在每个层完成注意力计算后,为给定请求将 KV 缓存保存到临时 CPU 缓冲区,并且此类保存操作将通过底层的 Meta C++ 连接器进行。通过这样做,我们确保主流模型执行不会被阻塞。
- KV 缓存保存完成后,它将立即流式传输到远程解码主机。
- 在解码端
- 获取远程 KV 缓存并将其复制到临时 GPU 缓冲区后,Python KV 连接器将开始将远程 KV 缓存注入到 vLLM 分配的本地 KV 缓存块中。这也通过底层的 Meta C++ 连接器在其独立的 C++ 线程和 CUDA 流中进行。
- KV 注入完成后,Python KV 连接器将把请求释放回 vLLM 调度器,并且该请求将在下一次迭代中安排运行。
- 错误处理
- 我们还实现了一个通用的垃圾收集器,用于清理从远程获取的空闲 KV 缓存缓冲区,以避免 CUDA OOM 问题。这涵盖了以下边缘情况:
- 被抢占的请求、取消/中止的请求,这些请求可能已完成远程获取但本地注入已中止。
- 我们还实现了一个通用的垃圾收集器,用于清理从远程获取的空闲 KV 缓存缓冲区,以避免 CUDA OOM 问题。这涵盖了以下边缘情况:
Meta C++ 连接器
由于 KV 传输操作具有繁重的 IO,我们选择使用 C++ 实现它们,这样我们可以更好地并行化数据传输并微调线程模型。所有实际的 KV 传输操作,例如通过网络流式传输、本地 H2D/D2H、KV 注入/提取,都在它们自己的 C++ 线程中进行,并使用单独的 CUDA 流。
预填充 C++ 连接器
在每个层完成模型注意力计算后,KV 缓存被卸载到 DRAM 上的 C++ 连接器。然后,它将 KV 缓存流式传输回解码主机,用于特定的请求和层。
解码 C++ 连接器
它从代理层接收请求及其路由的预填充主机地址,然后建立多个流通道以获取远程 KV 缓存。它将获取的 KV 缓存缓冲在 DRAM 上,并异步将其注入到预分配的 GPU KV 缓存块中。
优化
加速网络传输
- 多网卡支持: 多个前端网卡 (NIC) 连接到最近的 GPU,优化了解码和预填充 KV 连接器之间的连接。
- 多流 KV 缓存传输: 单个 TCP 流无法饱和网络带宽。为了最大限度地提高网络吞吐量,KV 缓存被切片并使用多个流并行传输。
优化服务性能
- 粘性路由: 在预填充转发中,来自同一会话的请求始终定向到同一预填充主机。这显著提高了多轮用例的前缀缓存命中率。
- 负载均衡: 我们利用 Meta 的内部服务路由器根据每个主机的利用率有效地在各种预填充主机之间分配工作负载。这与粘性路由相结合,使得前缀缓存命中率达到 40%-50%,同时将 HBM 利用率保持在 90%。
微调 vLLM
- 更大的块大小: 虽然 vLLM 建议每个 KV 缓存块 16 个令牌,但我们发现,在 CPU 和 GPU 之间传输这些较小的块会由于 KV 缓存注入和提取期间大量的微小内核启动而产生大量的开销。因此,我们采用了更大的块大小(例如,128、256)以提高解耦性能,并进行了必要的内核端调整。
- 禁用解码前缀缓存: 解码主机从 KV 连接器加载 KV 缓存,使得前缀哈希计算成为调度器的不必要开销。在解码端禁用它可以帮助稳定 TTIT(令牌间时间)。
改进 TTFT(首次生成令牌时间)
- 早期首次令牌返回: 代理层从预填充层接收响应,并立即将第一个令牌返回给客户端。同时,引擎解码第二个令牌。我们还重用了预填充的令牌化提示,消除了解码端的额外令牌化步骤。这确保了 P/D 解耦解决方案的 TTFT 尽可能接近预填充主机的 TTFT。
增强 TTIT(迭代生成令牌时间)
- 仅使用基本类型: 我们观察到,在 vLLM 调度器和工作器之间传输数据时,Python 的原生 pickle dump 序列化张量所需的时间是序列化整数列表的三倍。这通常会导致随机调度器进程挂起,对 TTIT 产生负面影响。最好避免在 KVConnectorMetadata 和 SchedulerOutput 中创建张量或复杂对象。
- 异步 KV 加载: 我们将 KV 加载操作与 vLLM 模型解码步骤并行化。这可以防止等待远程 KV 的请求阻塞已经在生成新输出令牌的请求。
- 最大化 GPU 操作重叠: 由于 KV 传输操作主要是复制/IO 操作,而主流模型前向执行是计算密集型的,我们成功地将 KV 传输操作在其自己的 CUDA 流中与主模型前向执行完全重叠。这导致 KV 传输不会产生额外的延迟开销。
- 避免 CPU 调度争用: 我们不是同时调度所有层的 KV 注入(本质上是索引复制操作),这可能在模型前向通过期间导致内核调度争用,而是按顺序调度每层 KV 注入,与模型前向通过同步。
- 非阻塞复制操作: 所有复制(主机到设备/设备到主机)操作都以非阻塞方式运行。我们还解决了一个问题,即在默认 CUDA 流中运行的主模型前向通过意外地阻塞了来自非阻塞 CUDA 流的其他复制操作。
性能结果
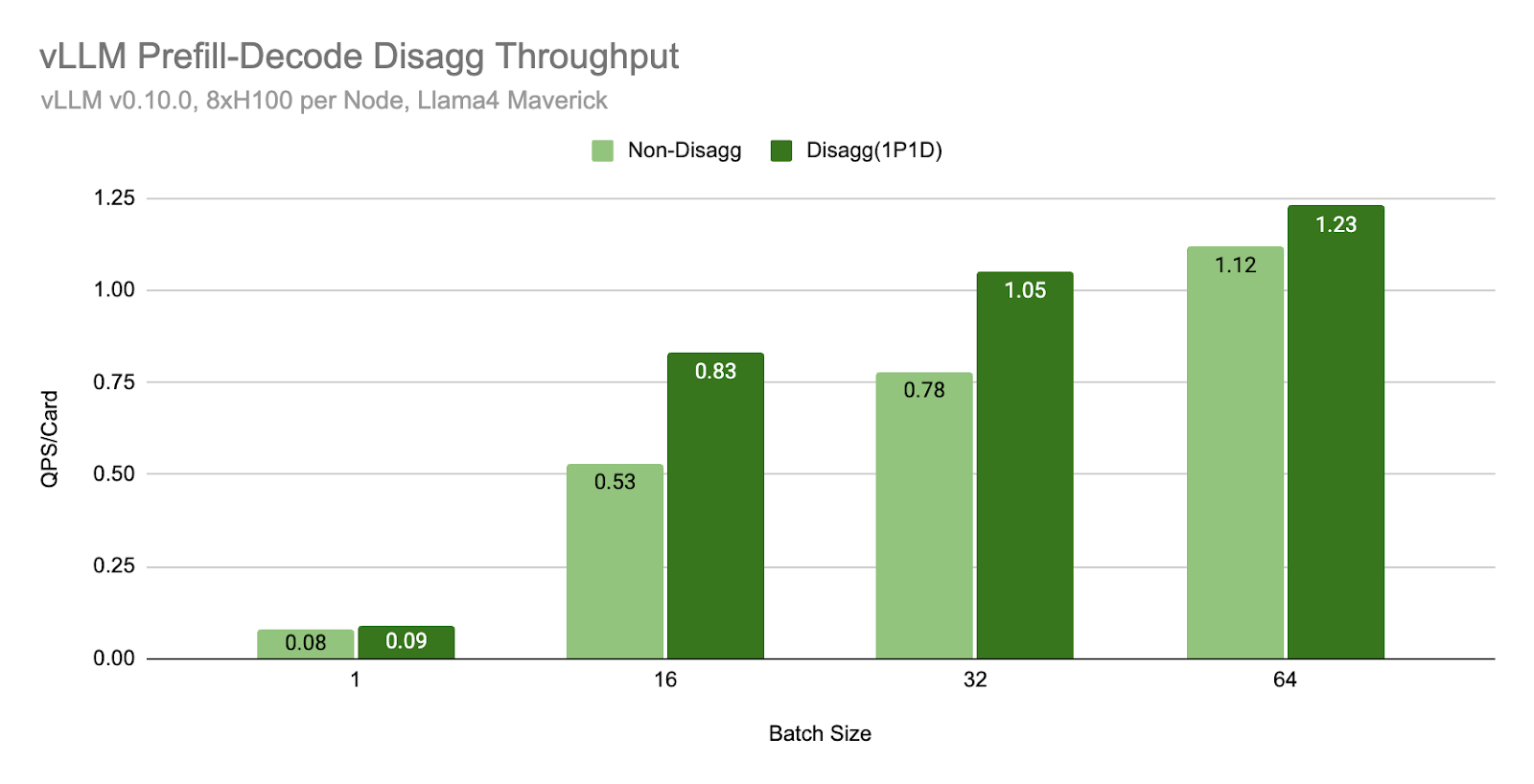
我们使用 Llama4 Maverick 在通过 TCP 网络连接的 H100 主机(每个主机 8xH100 卡)上进行了基准测试。评估使用的输入长度为 2000,输出长度为 150。
在相同的批量大小下,我们发现解耦 (1P1D) 可以提供更高的吞吐量
在相同的 QPS 工作负载下,我们发现解耦 (1P1D) 由于 TTIT 曲线更平滑,可以更好地控制整体延迟。
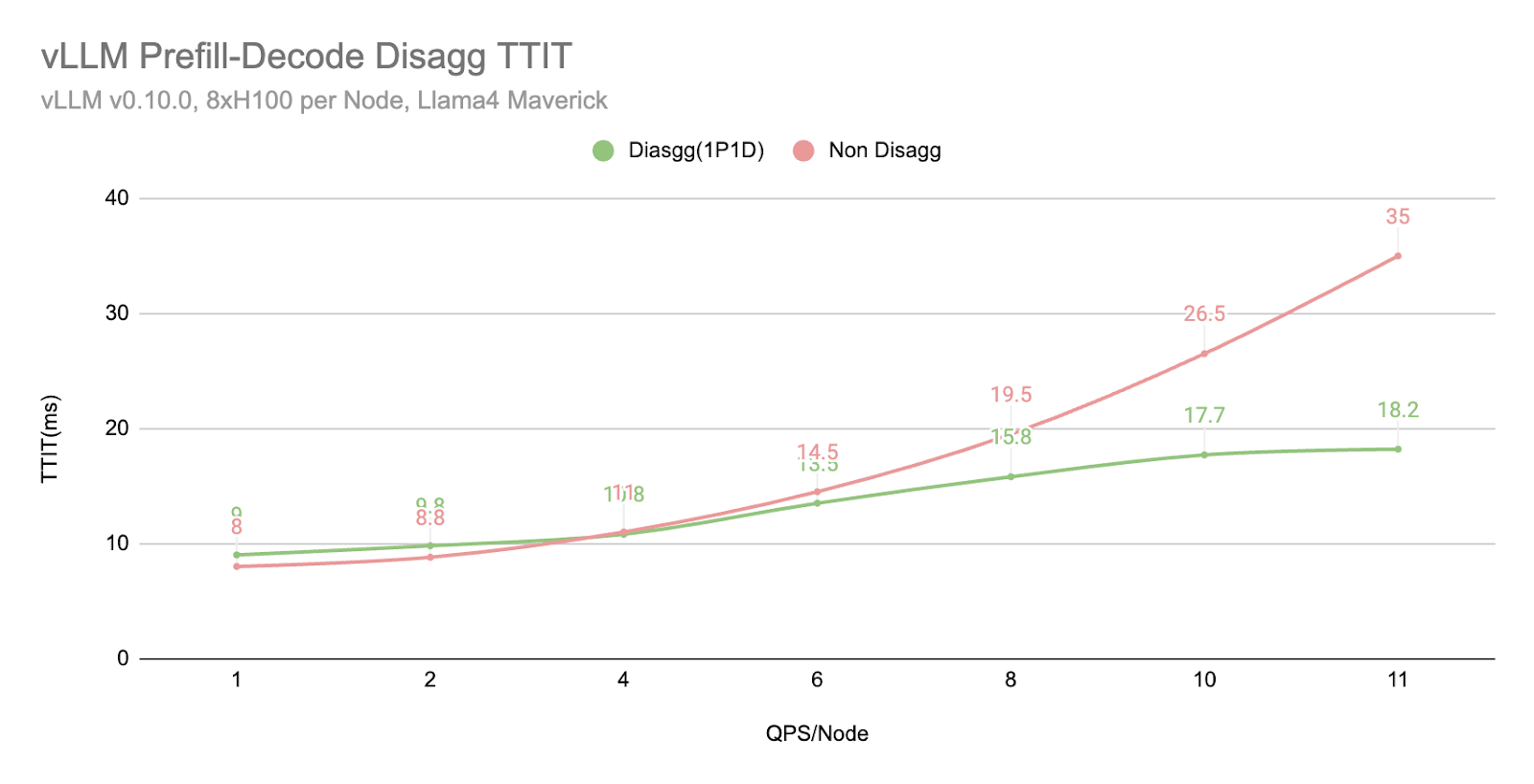
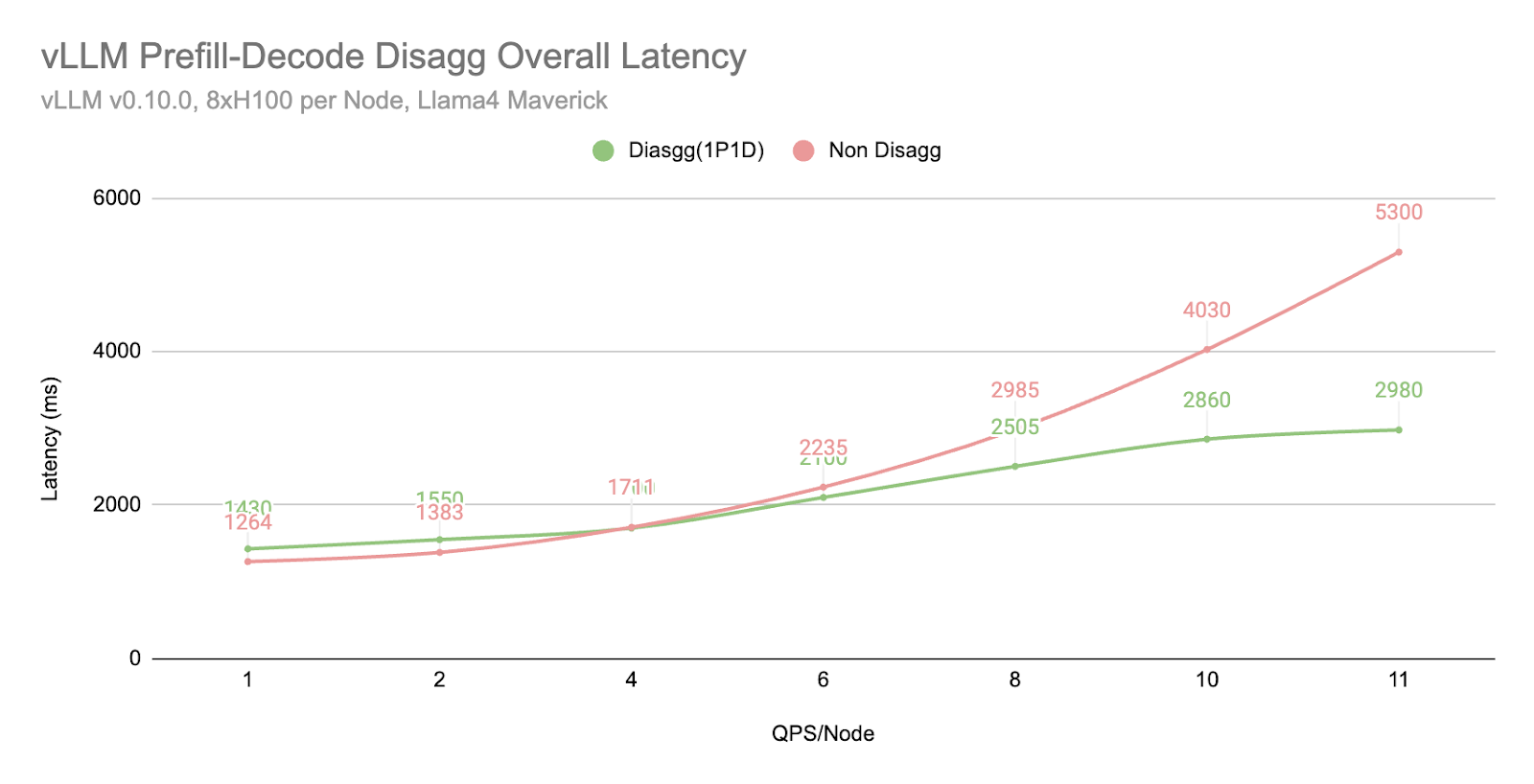
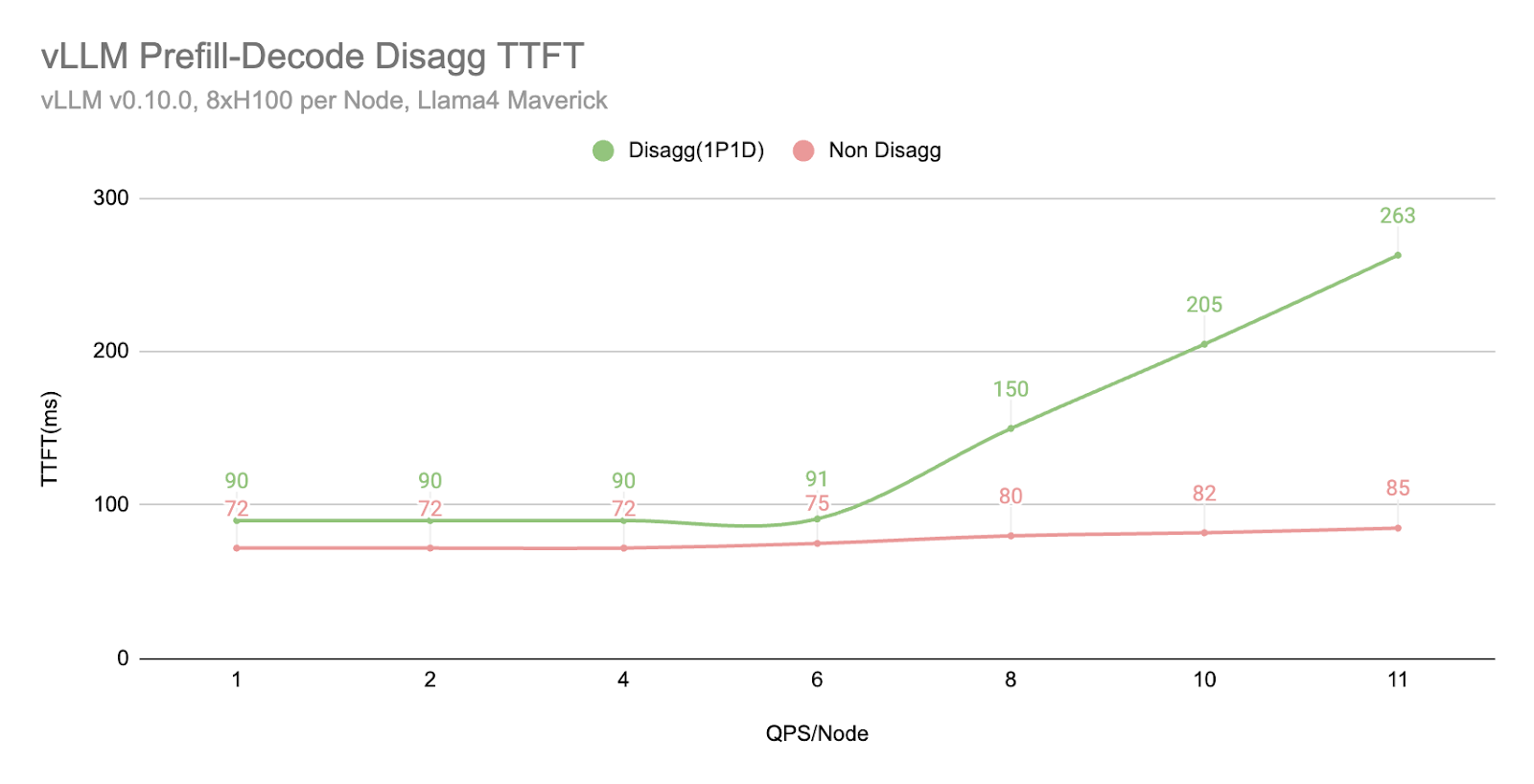
然而,我们也注意到,当工作负载变得非常大时,TTFT 会以更急剧的曲线回退,这可能由于多种原因(正如我们在下一节“更多探索”中提到的)
- 通过 TCP 连接,网络成为瓶颈。
- 1P1D 设置对预填充端施加了更大的工作负载压力,因为我们的评估是在更多预填充密集型工作(2000 个输入 vs 150 个输出)上进行的。理想情况下,需要更高的预填充到解码比率。
更多探索
- 仅缓存未命中 KV 传输
- 我们还原型化了仅缓存未命中 KV 传输机制,在该机制中,我们仅从远程获取解码端缺失的 KV 缓存。例如,如果请求具有 40% 的前缀缓存命中率,我们将仅从预填充端获取其余 60% 的 KV 缓存。根据早期观察,当 QPS 很高时,它会产生更平滑的 TTFT/TTIT 曲线。
- 预填充的计算-通信重叠
- 对于预填充,我们还探索了在自己的 CUDA 流中完成 KV 缓存保存的解决方案,这使其与模型前向通过并行运行。我们计划进一步探索这个方向并调整相关的服务设置,以推动更好的 TTFT 限制。
- 解耦 + DP/EP
- 为了支持 Meta 的大规模 vLLM 服务,我们正在实现 P/D 解耦和大规模 DP/EP 的集成,旨在通过不同程度的负载均衡和网络原语优化来实现整体最佳吞吐量和延迟。
- RDMA 通信支持
- 目前,我们依赖 Thrift 进行通过 TCP 的数据传输,这涉及大量的额外张量移动和网络堆栈开销。通过利用 NVLink 和 RDMA 等先进的通信连接,我们看到了进一步提高 TTFT 和 TTIT 性能的机会。
- 硬件特定优化
- 目前,我们正在将我们的解决方案生产化到 H100 硬件环境,并且我们计划将硬件特定优化扩展到提供 GB200 的其他硬件环境。
当然,我们将继续将所有这些功能贡献到上游,以便社区可以在核心 vLLM 项目和 PyTorch 中利用所有这些功能。如果您希望以任何方式进行协作,请联系我们。
干杯!
Meta & vLLM 团队的 PyTorch 团队