在这篇博客中,我们分享了如何在**无需任何用户端代码插桩**的情况下,为训练工作负载启用 PyTorch Profiler 痕迹的收集和分析。我们利用 Dynolog(一个用于 CPU 和 GPU 遥测的开源守护程序)来收集 PyTorch Profiler 痕迹,并使用 Holistic Trace Analysis(一个用于分析 PyTorch Profiler 痕迹的开源库)来分析收集到的痕迹。这套工具链使得 Meta 的工程师能够加速他们的性能优化工作流程。我们解决方案的关键是在 PyTorch 的基础 Optimizer 类中实现了前置和后置钩子。我们通过一个短视频演示了如何使用 Dynolog 收集 PyTorch 痕迹。
问题
Meta 的软件开发人员每天运行大量的分布式训练。为了确保 GPU 得到有效利用,有必要测量和分析所有作业的 GPU 性能。此外,开发人员需要能够内省模型并了解 CPU 和 GPU 如何交互以调试性能问题。开发人员最初使用少量 GPU 构建原型,生产版本则扩展到数百甚至数千个 GPU,服务于生成式 AI、推荐系统、广告排名等众多业务用例。
鉴于 Meta 的规模,有必要拥有低开销且相互无缝协作的性能测量和监控工具链,以保持开发人员的高效率。
在这篇博客中,我们将描述如何使用 PyTorch Profiler、Dynolog(一个遥测守护程序)和 Holistic Trace Analysis(一个性能调试库)来在无需任何用户端代码插桩的情况下收集痕迹,并分析它们以识别 GPU 利用率低的作业。
解决方案
下图展示了工具链如何协同工作。
- 用户启动 PyTorch 应用程序。
- 训练服务或用户使用 Dynolog CLI 触发分析会话,Dynolog CLI 通过网络向 Dynolog 守护程序发送请求。
- Dynolog 守护程序将分析配置中继到 PyTorch 应用程序,将其暂时设置为分析模式。
- PyTorch Profiler 收集痕迹并将其存储到数据库(例如,网络文件系统或 S3 存储桶)。
- 然后使用 Holistic Trace Analysis (HTA) 分析收集到的痕迹。
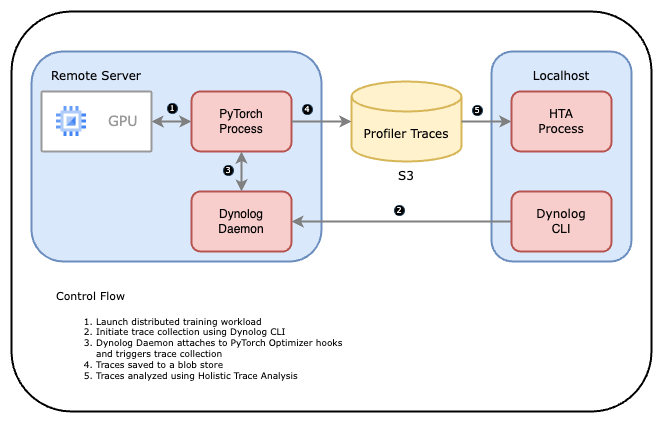
图 1:Dynolog、PyTorch Profiler 和 HTA 工具链工作流程
让我们深入了解每个组件。
Dynolog
Dynolog 是一个用于异构 CPU-GPU 系统的轻量级监控守护程序。它支持对 CPU(利用率、网络带宽、每秒指令数)和 GPU(SM 占用率、DRAM 带宽、GPU 功耗)的性能指标进行持续监控。此外,Dynolog 还导出 API 以收集可通过 dyno CLI 访问的深入分析数据。
Dynolog 提供的主要集成之一是与 PyTorch Profiler 的接口。这使得按需远程追踪成为可能,只需一个命令即可追踪数千台服务器。这可以通过使用 dyno gputrace 命令来实现。
PyTorch Profiler
GPU 内核异步执行,需要 GPU 侧支持来创建痕迹。NVIDIA 通过 CUPTI 库提供这种可见性。Kineto 是 Profiler 中与 CUPTI 接口的子系统。PyTorch Profiler 利用 Kineto 库来收集 GPU 痕迹。为了**无需任何用户端代码插桩**即可大规模实现训练工作负载的自动化分析,我们对 PyTorch 进行了一些根本性的修改。这些修改使得无需用户干预即可收集痕迹。
- 注册:首先,我们修改了 PyTorch,使其在启动时注册到 Dynolog 守护程序。通过设置环境变量 KINETO_USE_DAEMON=True 来启用此功能。设置此环境变量为 True 后,PyTorch Profiler 会定期轮询 Dynolog 以检查按需追踪请求。
- 迭代钩子:然后,我们为基础 Optimizer 类实现了前置和后置钩子。这使得我们能够标注训练迭代的开始/结束。Profiler 随后会知道迭代计数,并可以安全地在痕迹中捕获固定数量的迭代。
Holistic Trace Analysis (HTA)
机器学习研究人员和工程师常常因为不了解其工作负载中的性能瓶颈而难以在计算上扩展其模型。大型分布式训练作业可能会生成数千条痕迹,其中包含的数据量对于人工检查来说太多了。这就是 Holistic Trace Analysis 的用武之地。HTA 是一个用于性能分析的开源库——它以 PyTorch Profiler 痕迹为输入,并提升其中包含的性能信息。其目标是帮助研究人员和工程师从硬件堆栈中获得最佳性能。为了帮助性能调试,HTA 提供了以下功能(部分列表):
- 时间分解:根据计算、通信、内存事件和单个节点以及所有等级上的空闲时间来分解 GPU 时间。
- 空闲时间分解:将 GPU 空闲时间分解为等待主机、等待另一个内核或归因于未知原因。
- 内核分解:查找每个等级上持续时间最长的内核。
- 内核持续时间分布:最长内核在不同等级上的平均时间分布。
- 通信计算重叠:计算通信与计算重叠的时间百分比。
我们邀请您查看这些 Jupyter 笔记本,了解 HTA 能为您做些什么。如果您是初次使用,我们建议从 trace_analysis_demo 笔记本开始。
总而言之,Dynolog 让我们能够以可扩展的方式动态收集 PyTorch Profiler 痕迹。此外,通过利用 HTA,我们可以自动化性能分析并识别瓶颈。在 Meta,我们使用 Dynolog、PyTorch Profiler 和 HTA 工具链来加速我们的性能优化工作流程。
演示
我们分享了一个截屏视频,展示了如何在没有任何用户端代码插桩的情况下,为一个简单的 PyTorch 程序收集痕迹。演示在 Docker 容器中运行,痕迹收集通过 Dynolog 触发。HTA 可用于后续分析收集到的痕迹。
常见问题
问:dyno gputrace 还能为我做些什么?
dyno gputrace 命令支持多种自定义 PyTorch Profiler 选项:
- 捕获 Python 堆栈
- 内存分析
- 记录输入形状
请运行 dyno gputrace --help 查看所有选项。
问:Dynolog 是否收集硬件性能指标?
Dynolog 也可用于始终在线监控:
- 它使用 DCGM 为 NVIDIA GPU 提供开箱即用的 GPU 性能监控。
- Dynolog 提供基本的 Linux 内核 性能指标,包括 CPU、网络和 IO 资源使用情况。
- Dynolog 管理 Intel 和 AMD CPU 上与 CPU 缓存、TLB 等微架构特定事件相关的硬件性能计数器。
问:如何构建演示中使用的 Docker 镜像?
Dockerfile 可在此处 获取。使用以下命令构建 Docker 镜像。
docker build -f /path/to/dynolog_repo/dynolog_hta.dockerfile -t <image_name:tag> .
问:如何运行 Docker 镜像?
您可以参考此 备忘单 来运行 Docker 镜像。