大型语言模型 (LLM) 通常是资源密集型的,需要大量的内存、计算和电力才能有效运行。量化通过将权重和激活从 16 位浮点数减少到更低的比特率(例如,8 位、4 位、2 位)提供了一种解决方案,从而显著提高了速度并节省了内存,同时还支持更大的批处理大小。
现有的低精度推理解决方案在小批处理大小下表现良好,但存在以下问题:
- 当我们增加批处理大小时,性能会下降
- 对量化类型的限制,例如,某些内核仅支持对称量化,这可能会影响模型在较低比特下的精度
- 量化、序列化和张量并行 (TP) 之间的相互作用使得加载量化模型变得困难,并且需要更改用户模型
为了应对这些挑战,我们创建了一个端到端、高性能、模块化和可扩展的低精度推理解决方案,集成了以下库:
- GemLite,一个 Triton 内核库,解决了大批处理大小的性能限制以及对量化类型的限制
- TorchAO,一个 PyTorch 原生库,为量化、稀疏性和张量并行(使用 DTensor)提供流线型体验
- SGLang,一个用于大型语言模型 (LLM) 和视觉语言模型 (VLM) 的快速、高效、可定制的服务框架,具有广泛的模型支持
如果您有兴趣在 SGLang 中试用,请按照这些重现说明进行操作。对于本博客的其余部分,我们将详细介绍 GemLite、TorchAO 和 SGLang 的相关细节,包括库本身的设计以及在解决我们前面提到的问题方面的集成。最后,我们将展示 Llama 3.1-8B 模型在不同批处理大小和张量并行大小下的基准测试结果。
1. 结果预告
以下是 Llama 3.1-8B 在 8xH100 机器上解码结果的摘要。对于所有实验,基准是 bfloat16 torch.compiled 模型
| bfloat16 w/ torch.compile | int4 仅权重量化,组大小 64 | float8 每行动态量化 | |
| 批处理大小 1,TP 大小 1 | 131 tokens/秒 | 255 tokens/秒 (1.95 倍加速) | 166 tokens/秒 (1.27 倍加速) |
| 批处理大小 32,TP 大小 1 | 2799 tokens/秒 | 3241 tokens/秒 (1.16 倍加速) | 3586 tokens/秒 (1.28 倍加速) |
| 批处理大小 32,TP 大小 4 | 5575 tokens/秒 | 6334 tokens/秒 (1.14 倍加速) | 6159 tokens/秒 (1.10 倍加速) |
我们的解决方案支持 NVIDIA GPU,包括 H100 和 A100,并且在所有批处理大小和 TP 大小下,对于 int4 仅权重(从 1.14 倍到 1.95 倍)和 float8 动态量化(从 1.10 倍到 1.28 倍),都比编译的 bfloat16 基线实现了加速。请注意,量化可能会对精度产生很小的影响,这不在本博客文章的讨论范围之内。我们的 int4 仅权重量化与 HQQ 等精度保持技术兼容。有关更多信息,请参阅TorchAO 的 README、此基准和此博客。
2. GemLite:内核开发
这些内核是 GemLite 项目的一部分,该项目致力于优化低比特矩阵乘法内核。GemLite 使用 Triton 开发,为各种激活、比特率和硬件提供了高度灵活和高性能的解决方案。简而言之,这些内核提供:
- 支持各种激活数据类型:fp16、int8 和 fp8
- 兼容性:与非打包(例如 int8、fp8)和打包格式(例如 uint4、uint2、uint1)无缝协作
- 性能优化:包括优化内核和自动调优工具,以在不同硬件和批处理大小下实现高性能
- 集成:与 torch.compile 和 CUDA 图兼容,确保支持张量并行等高级功能
内核选择
优化大型语言模型 (LLM) 生成的内核选择需要解决不同批处理大小的独特需求。LLM 工作负载涉及计算密集型和内存密集型迭代的混合:较小的批处理大小是内存密集型的,而较大的批处理大小则成为计算密集型的。GemLite 内核旨在适应这些不同的需求,确保每种场景的最佳执行。
在内存密集型场景中,数据传输是限制因素,处理器通常等待数据获取,导致计算资源未充分利用。对于批处理大小 = 1,GEMV 内核表现最佳,而对于较大的批处理大小,GEMM 内核效率更高。对于介于 2 到 64 之间的批处理大小,当矩阵“瘦”时,使用 GEMM-SPLITK 内核以实现更好的 GPU 利用率 (arXiv)。
GemLite 包含针对这些场景优化的以下内核:
单样本推理
对于单样本推理,我们使用 GEMV 内核。然而,非对称量化方法需要加载额外的元数据,例如每个块的比例和零点。这可能导致内存传输增加,因此仔细处理至关重要。
具体来说,对于打包数据,我们的实验表明,每两个连续块仅加载一次比例和零点可最大程度地减少冗余操作。由于这些块共享相同的元数据,因此这种方法会带来:
- 与默认 GEMV 内核相比,端到端推理速度提升 5-8%
- 比传统 Split-K 方法改进 30-40%
这种新的内核/算法 GEMV_REVSPLITK 可在此处找到:https://github.com/mobiusml/gemlite/blob/master/gemlite/triton_kernels/gemv_revsplitK_A16fWnO16f_int32packing.py。
对于非打包数据,采用 GEMV_SPLITK 算法。该算法迭代 k 维度来计算点积,而不依赖于 Triton 的 tl.dot。
批处理推理
对于中等批处理大小,我们使用基于 GEMM 的 Split-K 方法 (arXiv),该方法将 k 维度(权重行)分成多个作业。通过自动调优 1 到 16 的值来找到最佳拆分 SPLIT_K 参数。设置 SPLIT_K=1 可以启用回退实现到 GEMM 内核,允许相同的内核代码用于从 32 和 64 开始的计算密集型批处理大小,具体取决于矩阵形状和设备。
最大化高性能:关键实现见解
必须仔细处理各种实现细节以实现高性能。以下是我们为确保高性能而关注的一些关键方面:
- 自动调优以获得性能自动调优对于实现最佳内核性能至关重要。由于此过程可能耗时,GemLite 提供了工具来自动保存和加载所有内核的自动调优结果。这确保了自动调优过程每个 GPU 设备只执行一次,从而最大限度地缩短了运行时,减少了重复开销,并保持了运行之间的一致性能。
- 确保内核正确性确保不同量化和配置设置的内核正确性至关重要。Triton 的早期配置剪枝在此过程中起着关键作用。例如,在 Split-K 调优期间,仅当 K 可被 BLOCK_SIZE_K × SPLIT_K 整除时才选择配置,并且根据组大小值进一步剪枝 BLOCKS_SIZE_K。这种方法确保了内核操作的效率和正确性。
- 克服比特解包瓶颈在部署到 NVIDIA A100 和 H100 等数据中心级 GPU 时,观察到与比特解包相关的性能瓶颈。为了缓解这些瓶颈,探索了各种比特打包配置,包括沿列与沿行打包,以及尝试不同的比特打包宽度(例如,8 位与 32 位)。值得注意的是,从 32 位打包过渡到 8 位打包,A100 的性能提高了高达 18%,H100 提高了 6%。
- torch.compile 兼容性为了确保与 PyTorch 的 torch.compile 无缝兼容,内核调用被包装在自定义操作中。这种集成允许预挂钩和早期配置剪枝等高级功能正常运行,在不牺牲性能的情况下提供准确的结果。虽然其中一些功能尚未在 PyTorch 中完全支持,但 custom_op 实现有效地弥合了这一差距,确保了平稳集成和高性能。
3. TorchAO
TorchAO 是一个 PyTorch 原生量化和稀疏库,用于训练和推理,具有简单的用户 API 来训练、量化和部署低精度模型,并与 PyTorch 的其他功能(如分布式推理和 torch.compile)具有可组合性。
PyTorch 默认不支持低精度 dtype 或不同的打包格式。通过 Tensor Subclass,我们扩展了 PyTorch 原生 Tensor 抽象,并将模型量化为 dtype 转换,而自定义内核的不同打包格式通过布局进行处理。例如,我们支持使用 int4 权重(以 Tensor Core 友好布局打包)的量化线性操作,使用 tinygemm 或 GemLite 内核实现。更多详细信息可在此处找到:https://pytorch.ac.cn/ao/stable/contributor_guide.html。
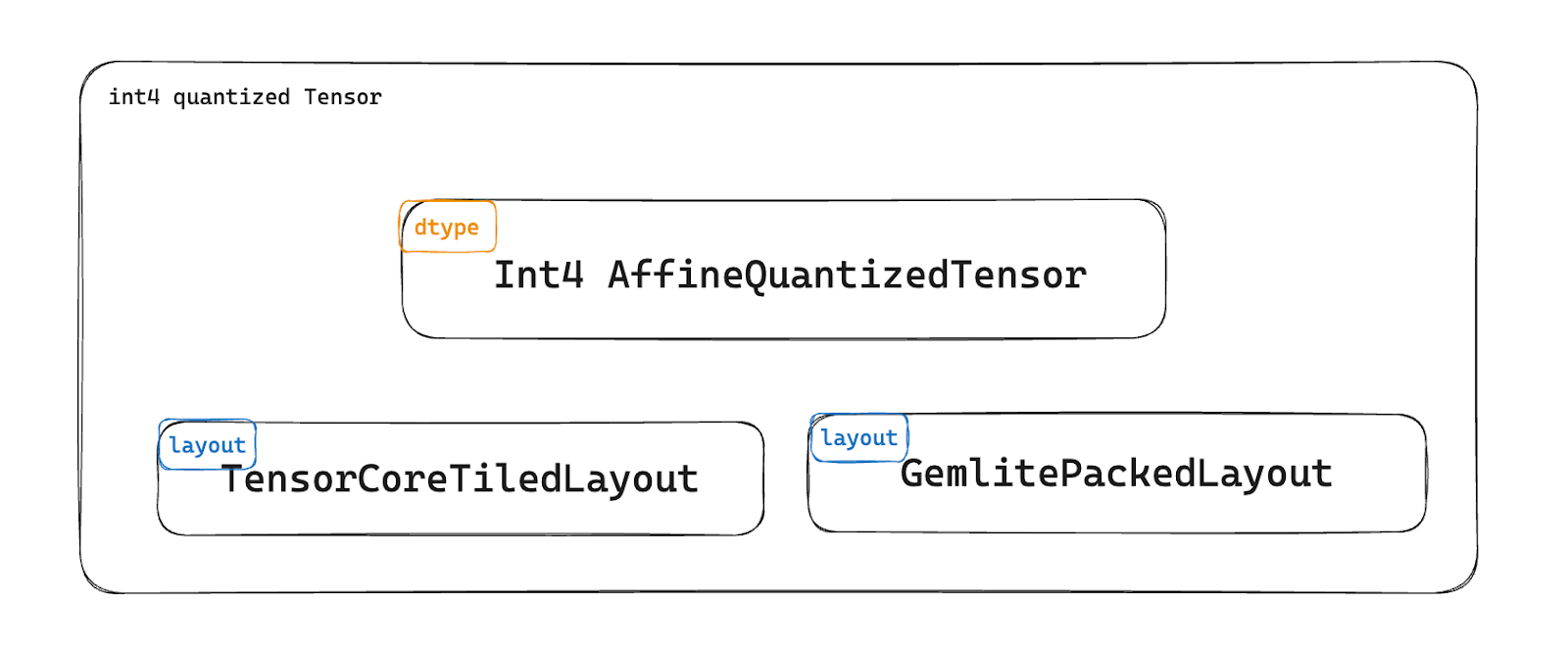
除了为开发人员提供更 PyTorch 原生的抽象之外,我们还想强调这种设计对建模用户的两个好处。
- 序列化:像浮点模型一样将量化权重保存和加载到 state_dict 中,无需在加载量化权重之前将浮点模型转换为量化模型。这减少了分发和部署量化模型的摩擦。
- 可组合性:与张量并行等下游功能无缝集成,允许用户专注于建模,而无需担心与张量并行、torch.compile 和其他 PyTorch 功能的兼容性。由于这些功能是使用 Tensor 级别抽象实现的,因此用户在大多数情况下可以对模型进行量化和分布式推理,而无需更改模型。
GemLite 内核集成
为了实现 GemLite 内核的上述优势,我们将 GemLite 集成到 TorchAO 中。这种集成利用了 GemLite 广泛的支持和灵活性,允许在非对称和对称量化方案下进行 4 位和 8 位仅权重量化,32 位和 8 位打包大小,以及分组和非分组量化。我们通过 `quantize_` API 启用此集成,该 API 可以与 GemLite 构造函数一起使用,如下所示:
quantize_(model, gemlite_uintx_weight_only(group_size, bit_width, packing_bitwidth))
创建此集成的主要困难是确保 GemLite 量化内核选项的全部广度都满足 TorchAO 的可组合性保证。虽然主要集成相对简单,但确保每种不同的量化类型及其相关内核与张量并行良好配合并非易事。
Torch 张量并行
张量并行是加速 LLM 推理的有效方法。TP 将线性或嵌入模块的大型矩阵分片到多个设备上,通常采用列式或行式。随着权重矩阵的分布,计算也随之分解。例如,下面的列式模式可以在四个设备上同时进行矩阵向量乘法。

PyTorch 通过将常规张量(例如矩阵 A)转换为 DTensor 来实现 TP。
dtensor = _shard_tensor(mA, device_mesh, (Shard(0),))
由于 DTensor 存储了关于分片的元信息,因此它知道如何在需要时重建完整结果。以 Transformer 的前馈模块为例,由于下投影和上投影分别使用列式和行式分片,DTensor 将在它们进入下一个操作时自动对等级的结果执行 all-reduce。这种自动化允许模型作者专注于计算,而无需担心分布式执行所需的通信。
张量并行与量化顺序
由于 DTensor 和量化都是张量级转换,因此应用顺序对于确保工作流通常可以在不同设置上运行至关重要。我们有两点观察:(i)检查点通常以量化格式保存,以节省每次运行前的量化开销;(ii)TP 可能会在不同数量的设备上运行,具体取决于资源限制或服务协议。因此,我们首先将量化应用于原始张量,并根据是否需要重用将其保存到磁盘。在服务启动时,我们加载量化检查点,并在加载到模型时动态将张量分片为 DTensor。
TorchAO 中的张量并行支持
由于我们首先量化模型,然后分发 Tensor,因此我们将拥有 `DTensor(QuantizedTensor(weight))`,其中 `DTensor` 表示分布式 Tensor 类,`QuantizedTensor` 表示 TorchAO 中的量化张量类。`QuantizedTensor` 应该支持在构造 `DTensor` 时调用的运算符,包括切片和视图操作。为了确保整体执行效率,在维度 0 和 1 上切片的打包权重应与先切片未打包权重然后打包的结果匹配(打包和切片操作应可交换),否则打包格式与张量并行不兼容。
4. SGLang
SGLang 是一个用于大型语言模型和视觉语言模型的快速服务框架。它以其几乎零开销批处理调度器和快速受限解码而闻名。它主要用 Python 实现,轻量级且易于修改。它也是首批集成 torch.compile 的框架之一。
SGLang 中的 TorchAO 集成
我们将 `quantize_` API(用于将特定类型的量化应用于模型)集成到 SGLang 中,目前支持 int4 仅权重量化(tinygemm 和 GemLite 版本)、float8 动态量化以及其他几种类型的量化。用户可以通过向基准测试脚本添加 `--torchao-config` 参数来启用量化。当前启用的选项还通过与 `DTensor` 的组合支持张量并行,`DTensor` 通过 `--tp-size` 选项启用。
SGLang 中的 Torch 原生张量并行支持
SGLang 中现有的模型定义使用与张量并行样式耦合的特殊线性模块,例如:`MergedColumnParallelLinear`、`QKVParallelLinear` 和 `RowParallelLinear`。为了解耦模型定义和张量并行化样式,我们定义了一个pytorch 原生模型,该模型使用 PyTorch 的普通 `nn.Linear` 模块,并依靠 PyTorch 张量并行 API 进行并行化,依靠 torch.compile 进行加速。在相关的模块层次结构中,我们添加了一个描述子模块应如何并行化的字典。例如,在 `class LlamaAttention` 中,我们定义:
_tp_plan = {
"qkv_proj": "Colwise_Sharded",
"o_proj": "Rowwise",
}
其中 `“qkv_proj”` 和 `“o_proj”` 是 `wqkv` 和 `wo` 投影的 FQN,其值是它们的 TP 样式。
然后我们在 `model_parallel.py` 中定义了一个 TP 引擎。它在模型中递归搜索 `_tp_plan`,并使用 PyTorch 的parallelize_module API 将指定的 TP 样式应用于子模块。
5. 结果
评估侧重于 H100 机器的两种流行量化技术:int4 仅权重(weight-only)量化和 float8 动态量化。选择这些方法是因为它们在优化 H100 机器上的内存效率和计算性能方面广泛使用,使其成为针对各种工作负载进行基准测试的理想候选者。
- int4 仅权重(Weight-Only)量化:该方法显著减少内存占用并加速内存密集型工作负载的解码,对计算密集型场景(如预填充或较大批处理大小)的性能影响最小。下面我们展示了 bf16、GemLite 和 tinygemm 内核在各种批处理大小和张量并行配置下的结果
- float8 动态量化:虽然提供更少的内存节省,但该方法通常为内存密集型和计算密集型任务提供更高的精度和平衡的加速。借助 Hopper 级硬件和原生 fp8 支持,AO 使用的高效 cutlass/cuBLAS 内核有助于显著加速
下面的图表显示了不同 tp 大小的解码 tokens/秒,每个图表显示了不同批处理大小和不同量化类型的结果
- BF16 是我们的 bfloat16,torch.compile 基线
- tinygemm-4-64 使用 TorchAO 中的 `int4_weight_only` 量化,这是一种组大小为 64 的 4 位分组量化,使用 tinygemm 内核
- gemlite-4-64 使用 TorchAO 中的 `gemlite_uintx_weight_only` 量化,4 表示 4 位,64 也是组大小,使用 GemLite 内核
- fp8dq-per_row 使用 TorchAO 中的 `float8_dynamic_activation_float8_weight` 量化,激活和权重都使用每行尺度进行量化
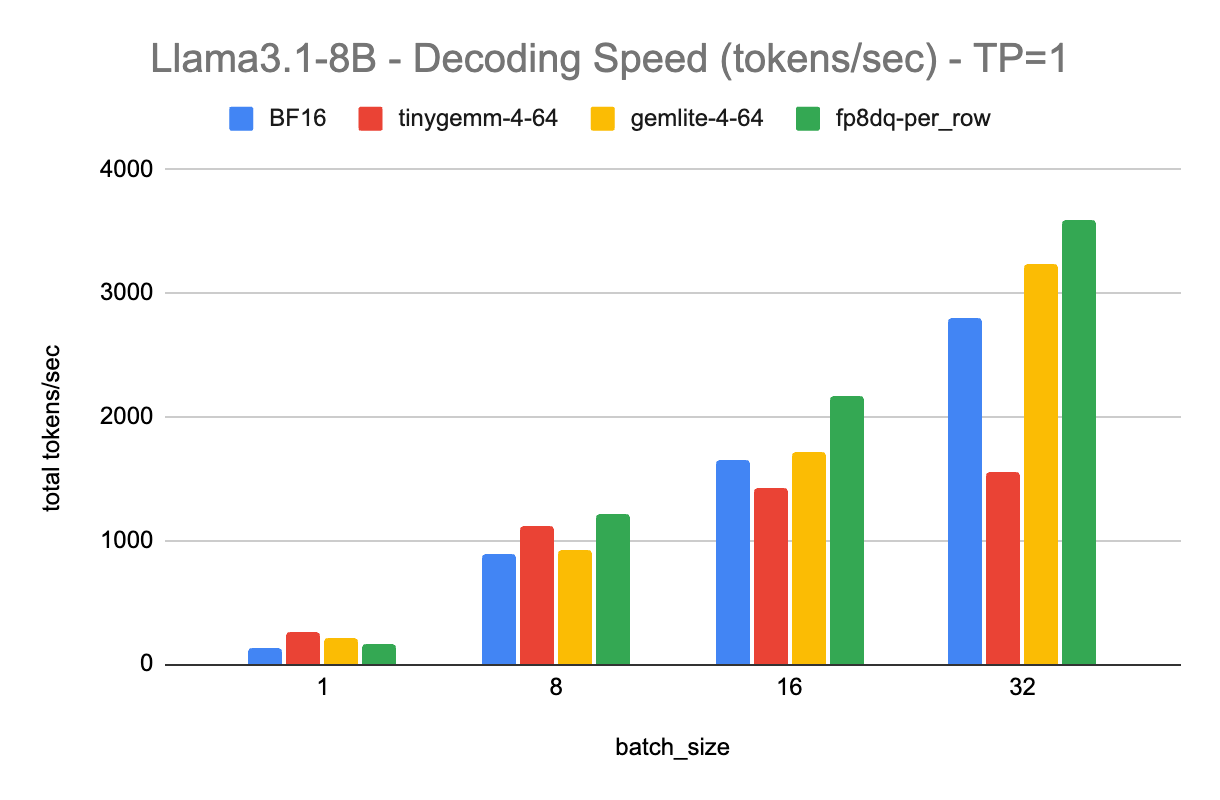
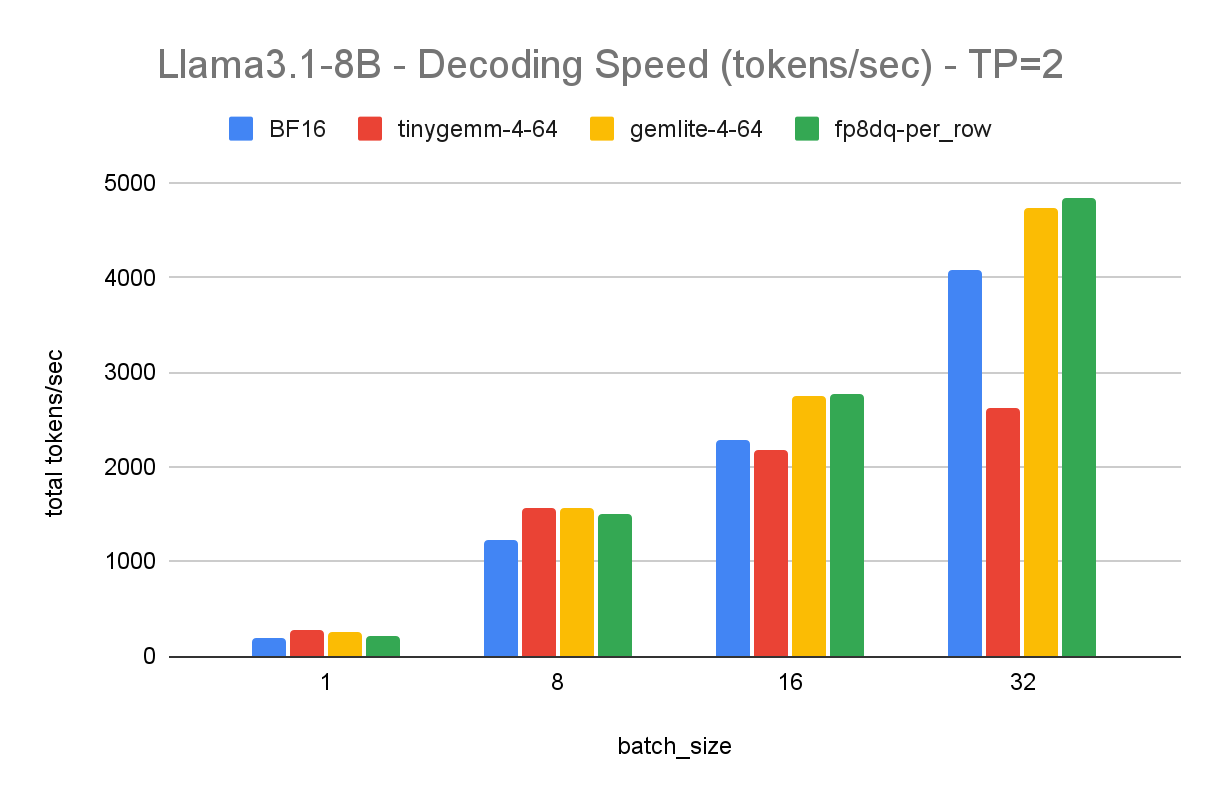
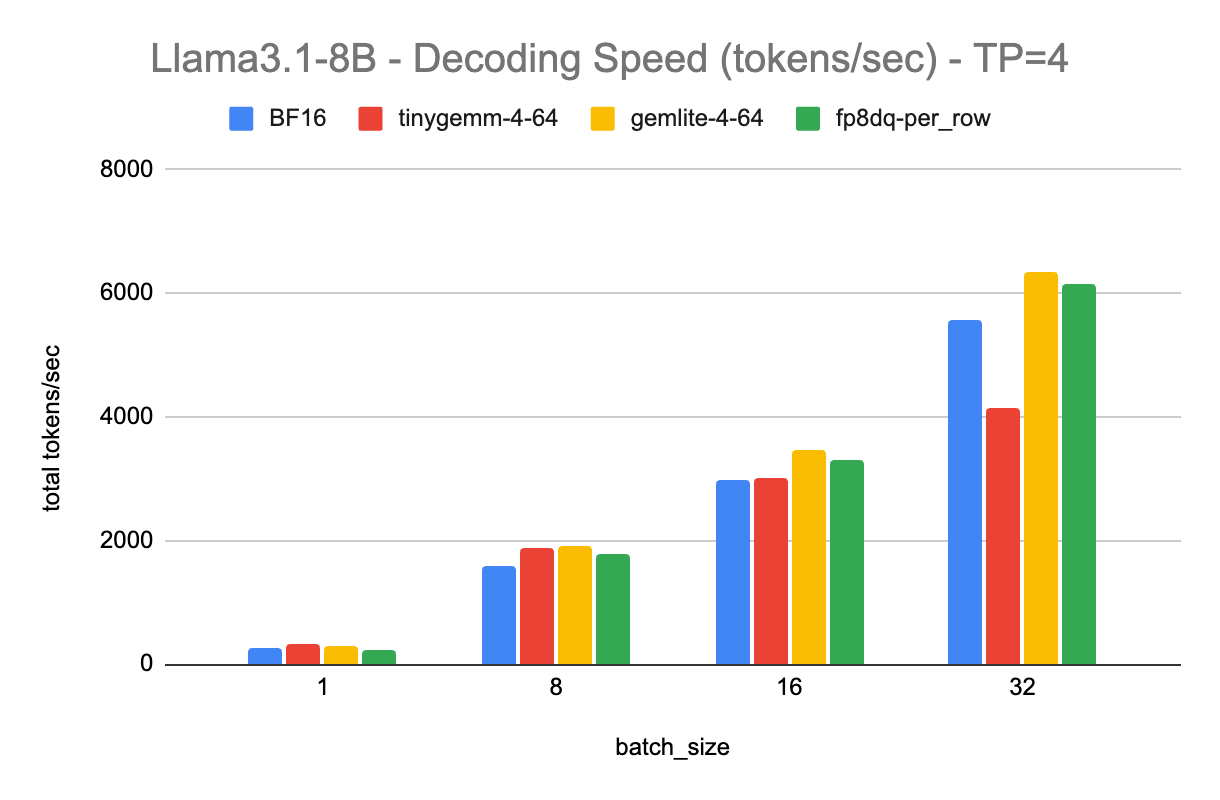
对于 int4 仅权重(weight-only)量化,在批处理大小为 1 时,tinygemm 内核获得了最佳性能。然而,其效率随着批处理大小的增加而下降。相反,GemLite 有效地弥补了这一差距,在更大的批处理大小下提供了卓越的性能。与 tinygemm 相比,GemLite 在预填充阶段也实现了 9-10 倍的加速,尽管 Triton 仍在进行性能优化。
Float8 动态量化在张量并行大小为 1 的情况下,在不同批处理大小下,比 bfloat16 始终快 1.3 倍,在更大的张量并行大小下,快 1.1 倍到 1.2 倍。随着张量并行大小的增加,整体加速会降低,这是由于矩阵乘法大小减小所预期的。请注意,我们确实期望预填充也能获得加速,但由于我们依赖 torch.compile 来加速,并且 SGLang 尚未启用预填充编译,因此我们将此留待未来的工作。
重现说明
我们使用 GemLite 0.4.1、从 commit feb2b76 构建的 SGLang、TorchAO nightly 0.8.0.dev20241223+cu124 和 PyTorch 2.5.1 在 8xH100 机器上进行了基准测试。选择 Llama-3.1 Instruct 模型作为评估架构。
BATCH_SIZE=16
# Note: gemlite is only compatible with float16
# while int4wo-64 (tinygemm-4-64 as shown in the graph) and fp8dq-per_row should use bfloat16
DTYPE=float16
# int4wo-64, fp8dq-per_tensor
TORCHAO_CONFIG=gemlite-4-64
TP_SIZE=2
# Decode performance
python3 -m sglang.bench_offline_throughput --model-path meta-llama/Llama-3.1-8B-Instruct --json-model-override-args '{"architectures": ["TorchNativeLlamaForCausalLM"]}' --dataset-name random --random-input 1024 --random-output 512 --random-range 1 --num-prompts $BATCH_SIZE --enable-torch-compile --dtype $DTYPE --torchao-config $TORCHAO_CONFIG --tp-size $TP_SIZE
# Example output
# Benchmark...
# [2024-12-20 12:42:16 TP0] Prefill batch. #new-seq: 2, #new-token: 2046, #cached-token: 4, cache hit rate: \0.06%, token usage: 0.00, #running-req: 0, #queue-req: 0
# ...
# [2024-12-20 12:45:35 TP0] Decode batch. #running-req: 16, #token: 16763, token usage: 0.01, gen throughput\ (token/s): 2.20, #queue-req: 0
# [2024-12-20 12:45:38 TP0] Decode batch. #running-req: 16, #token: 24443, token usage: 0.02, gen throughput\ (token/s): 2739.89, #queue-req: 0
# We reported the last throughput (token/s) as the performance for decode
结论
通过来自GemLite的高性能可扩展内核,PyTorch 原生架构优化库TorchAO和高性能推理框架SGLang,我们展示了 int4 和 float8 在不同批处理大小和张量并行大小下的快速端到端量化推理,并提供了简单且可组合的用户 API,以减少 LLM 的资源需求。这种集成是我们满足不同模型、工作负载、精度和硬件下快速推理需求的第一步,我们期待继续推进端到端混合和低精度 LLM 推理的最新技术。
我们当前的未来工作重点如下:
- 探索权重和激活量化的多样化组合,以在速度和精度之间取得最佳平衡
- 将支持扩展到其他 GPU 架构以扩大可访问性
- 增强与 MoE 模型的兼容性,以满足对可扩展推理日益增长的需求
- 允许在 TorchAO 中轻松集成快速自定义内核,以便 SGLang 和其他推理框架可以轻松利用它们
- 虽然我们没有在本博客文章中测量精度影响,但我们可以在 TorchAO 中开发自动量化工具,允许用户在性能和精度之间进行权衡
- 更好地集成 SGLang 中的张量并行以支持运行更大的模型
- 在 SGLang 中为预填充阶段启用 torch.compile
我们还邀请社区积极测试、提供反馈并为塑造快速高效 LLM 推理的未来做出贡献。