Silero 语音活动检测器
# this assumes that you have a proper version of PyTorch already installed
pip install -q torchaudio
import torch
torch.set_num_threads(1)
from IPython.display import Audio
from pprint import pprint
# download example
torch.hub.download_url_to_file('https://models.silero.ai/vad_models/en.wav', 'en_example.wav')
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True)
(get_speech_timestamps,
_, read_audio,
*_) = utils
sampling_rate = 16000 # also accepts 8000
wav = read_audio('en_example.wav', sampling_rate=sampling_rate)
# get speech timestamps from full audio file
speech_timestamps = get_speech_timestamps(wav, model, sampling_rate=sampling_rate)
pprint(speech_timestamps)
模型描述
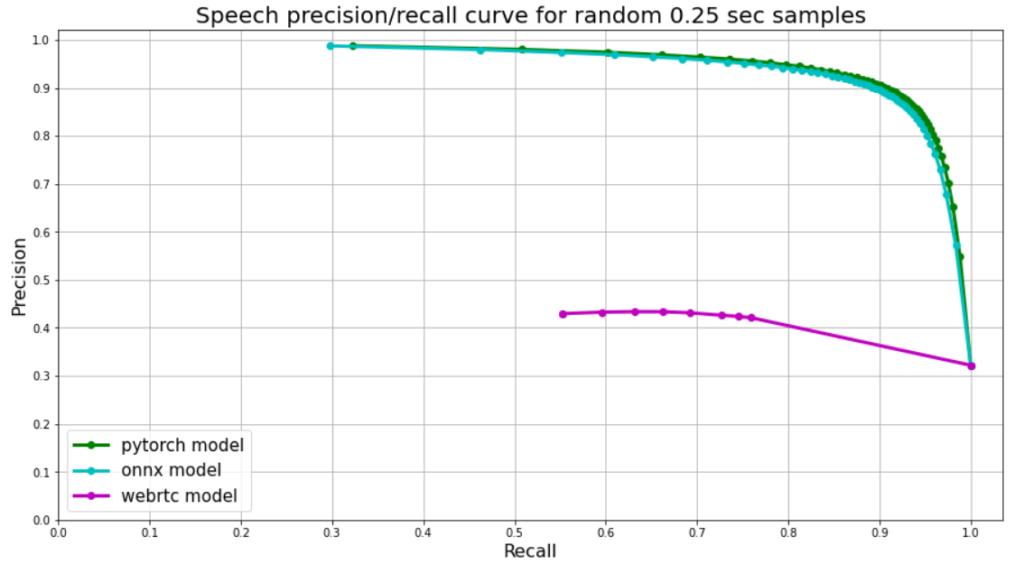
Silero VAD:预训练的企业级语音活动检测器 (VAD)。企业级语音产品,简单易用(参见我们的 STT 模型)。 每个模型单独发布。
目前,除了 WebRTC 语音活动检测器(链接)之外,几乎没有高质量/现代/免费/公共的语音活动检测器。然而,WebRTC 开始显老,并且存在许多误报。
(!!!) 重要通知 (!!!) – 模型仅适用于 CPU 运行,并已针对 1 个 CPU 线程的性能进行了优化。请注意,模型已量化。
其他示例和基准
有关其他示例和其他模型格式,请访问此 链接,并请参阅 Colab 格式的丰富示例(包括流式示例)。
参考文献
VAD 模型架构基于类似的 STT 架构。