Open-Unmix
# assuming you have a PyTorch >=1.6.0 installed
pip install -q torchaudio
import torch
# loading umxhq four target separator
separator = torch.hub.load('sigsep/open-unmix-pytorch', 'umxhq')
# generate random audio
# ... with shape (nb_samples, nb_channels, nb_timesteps)
# ... and with the same sample rate as that of the separator
audio = torch.rand((1, 2, 100000))
original_sample_rate = separator.sample_rate
# make sure to resample the audio to models' sample rate, separator.sample_rate, if the two are different
# resampler = torchaudio.transforms.Resample(original_sample_rate, separator.sample_rate)
# audio = resampler(audio)
estimates = separator(audio)
# estimates.shape = (1, 4, 2, 100000)
模型描述
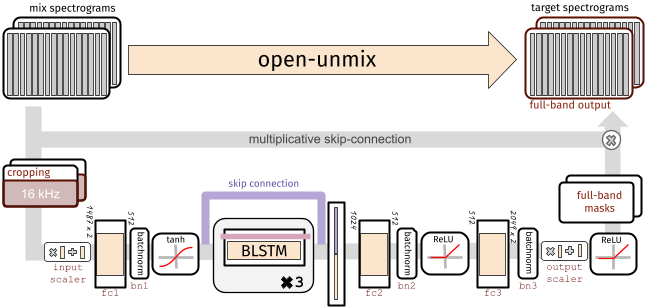
Open-Unmix 提供了即用型模型,让用户能将流行音乐分离成四个音轨: 人声、 鼓点、 贝斯 以及其余的 其他 乐器。这些模型已在免费提供的 MUSDB18 数据集上进行了预训练。
每个目标模型都基于一个三层双向深度 LSTM。该模型学习从混合输入的幅度谱图中预测目标源(如人声)的幅度谱图。在内部,通过在输入上应用掩码来获得预测。该模型在幅度域使用均方误差进行优化。
Separator 元模型(如上面的代码示例所示)将多个 Open-unmix 谱图模型组合在一起,用于每个所需的目标,并通过多通道广义维纳滤波器组合它们的输出,然后使用 torchaudio 应用逆 STFT。该滤波是 norbert 的可微分(但无参数)版本。
预训练的 Separator 模型
umxhq(默认) 在 MUSDB18-HQ 上训练,该数据集包含与 MUSDB18 相同的音轨,但未压缩,从而产生 22050 Hz 的全带宽。umx在常规的 MUSDB18 上训练,由于 AAC 压缩,其带宽限制在 16 kHz。该模型应用于与 SiSEC18 中评估的其他(较旧的)方法进行比较。
此外,我们还提供了由 Sony Corporation 训练的语音增强模型
umxse语音增强模型在 Voicebank+DEMAND corpus 的 28 说话人版本上训练。
所有这三个模型也可用作谱图(核心)模型,它们接受幅度谱图输入并输出分离的谱图。这些模型可以使用 umxhq_spec、 umx_spec 和 umxse_spec 加载。
详情
如需更多示例、文档和使用示例,请访问此 GitHub 仓库。
此外,模型和所有用于预处理、读取和保存音频音轨的实用功能都可以在一个 Python 包中获得,可以通过以下方式安装
pip install openunmix