FastPitch 2
模型描述
本笔记本演示了 FastPitch 模型的 PyTorch 实现,该模型在 FastPitch 论文中有所描述。FastPitch 模型从原始输入文本生成梅尔谱图并预测音高轮廓。在 1.1 版本中,它不需要任何预训练的对齐模型来引导。为了获得音频波形,我们需要第二个模型从生成的梅尔谱图生成它。在本笔记本中,我们使用 HiFi-GAN 模型进行第二步。
FastPitch 模型基于 FastSpeech 模型。FastPitch 与 FastSpeech 之间的主要区别如下:
- 不依赖外部对齐器(Transformer TTS、Tacotron 2);在 1.1 版本中,FastPitch 像 One TTS Alignment To Rule Them All 中一样,自行将音频与转录文本对齐。
- FastPitch 明确学习预测音高轮廓,
- 音高条件消除了刺耳的伪影并提供了更快的收敛速度,
- 无需使用教师模型蒸馏梅尔谱图,
- 具备训练多说话人模型的能力。
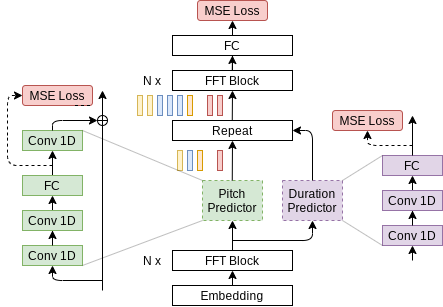
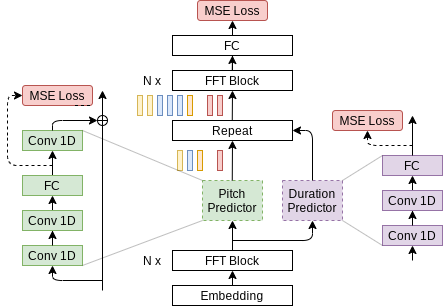
模型架构
示例
在下面的示例中
- 预训练的 FastPitch 和 HiFiGAN 模型从 torch.hub 加载
- 给定输入文本的张量表示(“Say this smoothly to prove you are not a robot.”),FastPitch 生成梅尔谱图
- HiFiGAN 根据梅尔谱图生成声音
- 输出声音保存为“audio.wav”文件
要运行该示例,您需要安装一些额外的 Python 包。这些包用于文本和音频的预处理,以及显示和输入/输出处理。最后,为了提高 FastPitch 模型的性能,我们下载了 CMU 发音词典。
apt-get update
apt-get install -y libsndfile1 wget
pip install numpy scipy librosa unidecode inflect librosa matplotlib==3.6.3
wget https://raw.githubusercontent.com/NVIDIA/NeMo/263a30be71e859cee330e5925332009da3e5efbc/scripts/tts_dataset_files/heteronyms-052722 -qO heteronyms
wget https://raw.githubusercontent.com/NVIDIA/NeMo/263a30be71e859cee330e5925332009da3e5efbc/scripts/tts_dataset_files/cmudict-0.7b_nv22.08 -qO cmudict-0.7b
import torch
import matplotlib.pyplot as plt
from IPython.display import Audio
import warnings
warnings.filterwarnings('ignore')
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
print(f'Using {device} for inference')
下载并设置 FastPitch 生成器模型。
fastpitch, generator_train_setup = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_fastpitch')
下载并设置声码器和去噪器模型。
hifigan, vocoder_train_setup, denoiser = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_hifigan')
验证生成器和声码器模型在输入参数上是否一致。
CHECKPOINT_SPECIFIC_ARGS = [
'sampling_rate', 'hop_length', 'win_length', 'p_arpabet', 'text_cleaners',
'symbol_set', 'max_wav_value', 'prepend_space_to_text',
'append_space_to_text']
for k in CHECKPOINT_SPECIFIC_ARGS:
v1 = generator_train_setup.get(k, None)
v2 = vocoder_train_setup.get(k, None)
assert v1 is None or v2 is None or v1 == v2, \
f'{k} mismatch in spectrogram generator and vocoder'
将所有模型放在可用设备上。
fastpitch.to(device)
hifigan.to(device)
denoiser.to(device)
加载文本处理器。
tp = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_textprocessing_utils', cmudict_path="cmudict-0.7b", heteronyms_path="heteronyms")
设置要合成的文本,准备输入并设置附加的生成参数。
text = "Say this smoothly, to prove you are not a robot."
batches = tp.prepare_input_sequence([text], batch_size=1)
gen_kw = {'pace': 1.0,
'speaker': 0,
'pitch_tgt': None,
'pitch_transform': None}
denoising_strength = 0.005
for batch in batches:
with torch.no_grad():
mel, mel_lens, *_ = fastpitch(batch['text'].to(device), **gen_kw)
audios = hifigan(mel).float()
audios = denoiser(audios.squeeze(1), denoising_strength)
audios = audios.squeeze(1) * vocoder_train_setup['max_wav_value']
绘制中间频谱图。
plt.figure(figsize=(10,12))
res_mel = mel[0].detach().cpu().numpy()
plt.imshow(res_mel, origin='lower')
plt.xlabel('time')
plt.ylabel('frequency')
_=plt.title('Spectrogram')
合成音频。
audio_numpy = audios[0].cpu().numpy()
Audio(audio_numpy, rate=22050)
将音频写入 wav 文件。
from scipy.io.wavfile import write
write("audio.wav", vocoder_train_setup['sampling_rate'], audio_numpy)
详情
有关模型输入和输出、训练方法、推理和性能的详细信息,请访问: github 和/或 NGC