YOLOP
开始之前
安装 YOLOP 依赖项
pip install -qr https://github.com/hustvl/YOLOP/blob/main/requirements.txt # install dependencies
YOLOP:You Only Look Once for Panoptic driving Perception(仅一次全景驾驶感知)
模型描述
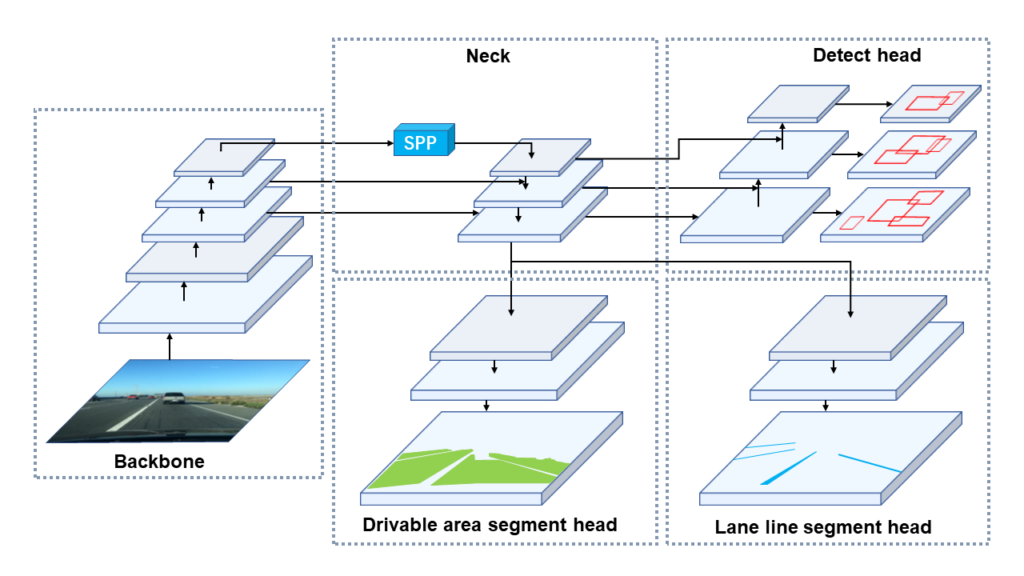
- YOLOP 是一个高效的多任务网络,可以联合处理自动驾驶中的三个关键任务:物体检测、可行驶区域分割和车道线检测。它也是第一个在嵌入式设备上达到实时性能,同时在 BDD100K 数据集上保持最先进水平性能的模型。
结果
交通物体检测结果
| 模型 | 召回率 (%) | mAP50 (%) | 速度 (fps) |
|---|---|---|---|
Multinet | 81.3 | 60.2 | 8.6 |
DLT-Net | 89.4 | 68.4 | 9.3 |
Faster R-CNN | 77.2 | 55.6 | 5.3 |
YOLOv5s | 86.8 | 77.2 | 82 |
YOLOP (我们的) | 89.2 | 76.5 | 41 |
可行驶区域分割结果
| 模型 | mIOU (%) | 速度 (fps) |
|---|---|---|
Multinet | 71.6 | 8.6 |
DLT-Net | 71.3 | 9.3 |
PSPNet | 89.6 | 11.1 |
YOLOP (我们的) | 91.5 | 41 |
车道线检测结果
| 模型 | mIOU (%) | IOU (%) |
|---|---|---|
ENet | 34.12 | 14.64 |
SCNN | 35.79 | 15.84 |
ENet-SAD | 36.56 | 16.02 |
YOLOP (我们的) | 70.50 | 26.20 |
消融研究 1:端到端对比分步
| 训练方法 | 召回率 (%) | AP (%) | mIoU (%) | 准确率 (%) | IoU (%) |
|---|---|---|---|---|---|
ES-W | 87.0 | 75.3 | 90.4 | 66.8 | 26.2 |
ED-W | 87.3 | 76.0 | 91.6 | 71.2 | 26.1 |
ES-D-W | 87.0 | 75.1 | 91.7 | 68.6 | 27.0 |
ED-S-W | 87.5 | 76.1 | 91.6 | 68.0 | 26.8 |
端到端 | 89.2 | 76.5 | 91.5 | 70.5 | 26.2 |
消融研究 2:多任务对比单任务
| 训练方法 | 召回率 (%) | AP (%) | mIoU (%) | 准确率 (%) | IoU (%) | 速度 (ms/帧) |
|---|---|---|---|---|---|---|
检测 (仅) | 88.2 | 76.9 | – | – | – | 15.7 |
可行驶区域分割 (仅) | – | – | 92.0 | – | – | 14.8 |
车道线分割 (仅) | – | – | – | 79.6 | 27.9 | 14.8 |
多任务 | 89.2 | 76.5 | 91.5 | 70.5 | 26.2 | 24.4 |
注意事项:
- 在表 4 中,E、D、S 和 W 分别指代编码器、检测头、两个分割头和整个网络。因此,该算法(首先,我们只训练编码器和检测头。然后我们冻结编码器和检测头,并训练两个分割头。最后,整个网络联合训练所有三个任务。)可以标记为 ED-S-W,其他以此类推。
可视化
交通物体检测结果

可行驶区域分割结果

车道线检测结果

注意事项:
- 车道线检测结果的可视化已通过二次拟合进行后处理。
部署
我们的模型可以在 Jetson Tx2 上实时推理,并使用 Zed Camera 捕获图像。我们使用 TensorRT 工具进行加速。我们在 github 代码中提供了模型部署和推理的代码。
从 PyTorch Hub 加载
此示例加载预训练的 YOLOP 模型并传入图像进行推理。
import torch
# load model
model = torch.hub.load('hustvl/yolop', 'yolop', pretrained=True)
#inference
img = torch.randn(1,3,640,640)
det_out, da_seg_out,ll_seg_out = model(img)
引用
更多详细信息请参阅 github 代码 和 arxiv 论文。
如果您发现我们的论文和代码对您的研究有用,请考虑点赞和引用。