
此博文作者是Jae-Won Chung,密歇根大学的博士生,也是ML.ENERGY Initiative的负责人。
深度学习消耗相当大的能量。例如,在AWS p4d实例上训练一个200B的LLM消耗了大约11.9 GWh(来源:CIDR 2024主题演讲),这足以单独为一个家庭提供一年的电力,而这个量能供超过一千个普通美国家庭使用一年。
Zeus是一个开源工具箱,用于测量和优化深度学习工作负载的能耗。我们的目标是,通过提供可组合且假设最少的工具,使基于精确测量的能耗优化尽可能简单,适用于各种深度学习工作负载和设置。
Zeus主要提供两类工具:
- 用于GPU能耗测量的编程和命令行工具
- 多种能耗优化工具,用于寻找最佳的ML和/或GPU配置
Zeus可以惠及以下人群:
- 测量和优化其电力成本
- 减少GPU散热(通过降低功耗)
- 报告研发过程中的能耗
- 减少电力使用造成的碳足迹
第一部分:测量能耗
就像性能优化一样,精确测量是有效能耗优化的基础。流行的功耗估算代理,如硬件的最大功耗有时与实际测量值大相径庭。
为了使能耗测量尽可能简单透明,Zeus提供的核心工具是ZeusMonitor类。我们来看一下实际的代码片段。
from zeus.monitor import ZeusMonitor
# All four GPUs are measured simultaneously.
monitor = ZeusMonitor(gpu_indices=[0,1,2,3])
# Measure total time and energy within the window.
monitor.begin_window("training")
for e in range(100):
# Measurement windows can arbitrarily be overlapped.
monitor.begin_window("epoch")
for x, y in train_dataloader:
y_hat = model(x)
loss = criterion(y, y_hat)
loss.backward()
optim.step()
measurement = monitor.end_window("epoch")
print(f"Epoch {e}: {measurement.time} s, {measurement.total_energy} J")
measurement = monitor.end_window("training")
print(f"Entire training: {measurement.time} s, {measurement.total_energy} J")
您上面看到的是一个典型的PyTorch训练循环,它使用四个GPU进行数据并行训练。在其中,我们创建了一个ZeusMonitor实例,并传入一个要监控的GPU索引列表。然后,使用该监视器,我们可以通过配对调用begin_window和end_window来测量训练脚本中任意执行窗口的时间和能耗。多个窗口可以以任意方式重叠和嵌套,只要它们的名称不同,就不会影响彼此的测量。
ZeusMonitor带来的开销非常小——通常是个位数毫秒。这使得ZeusMonitor可以用于各种应用。例如:
- ML.ENERGY排行榜:首个关于LLM文本生成消耗多少能量的开源基准。
- ML.ENERGY竞技场:一个在线服务,允许用户根据响应质量和能耗并排比较LLM响应。
请参阅我们的博客文章,了解更深入的GPU能耗测量技术细节。
第二部分:优化能耗
让我向您介绍Zeus提供的两个能耗优化器。
GlobalPowerLimitOptimizer
GPU允许用户配置其最大功耗,称为功率限制。通常,当您将GPU的功率限制从默认最大值降低时,计算速度可能会稍微变慢,但您将节省不成比例的更多能量。Zeus中的GlobalPowerLimitOptimizer会自动全局查找所有GPU的最佳功率限制。
from zeus.monitor import ZeusMonitor
from zeus.optimizer.power_limit import GlobalPowerLimitOptimizer
# The optimizer measures time and energy through the ZeusMonitor.
monitor = ZeusMonitor(gpu_indices=[0,1,2,3])
plo = GlobalPowerLimitOptimizer(monitor)
for e in range(100):
plo.on_epoch_begin()
for x, y in train_dataloader:
plo.on_step_begin()
y_hat = model(x)
loss = criterion(y, y_hat)
loss.backward()
optim.step()
plo.on_step_end()
plo.on_epoch_end()
在我们熟悉的PyTorch训练循环中,我们实例化了GlobalPowerLimitOptimizer,并向其传递了一个ZeusMonitor实例,通过该实例,优化器可以感知到GPU。然后,我们只需要让优化器知道训练进度(步数和epoch边界),优化器就会透明地完成所有必要的分析并收敛到最佳功率限制。
如果您正在使用HuggingFace的Trainer或SFTTrainer,集成会更加简单:
from zeus.monitor import ZeusMonitor
from zeus.optimizer.power_limit import HFGlobalPowerLimitOptimizer
# ZeusMonitor actually auto-detects CUDA_VISIBLE_DEVICES.
monitor = ZeusMonitor()
pl_optimizer = HFGlobalPowerLimitOptimizer(monitor)
# Pass in the optimizer as a Trainer callback. Also works for SFTTrainer.
trainer = Trainer(
model=model,
train_dataset=train_dataset,
...,
callbacks=[pl_optimizer],
)
HFGlobalPowerLimitOptimizer封装了GlobalPowerLimitOptimizer,使其能够自动检测步数和epoch边界。我们在此处提供了集成示例这里,包括运行Gemma 7B使用QLoRA进行监督微调。
现在我们知道了如何集成优化器,但什么是最优功率限制呢?我们知道不同的用户在权衡时间与能量方面可能有不同的偏好,因此我们允许用户指定一个OptimumSelector(基本上是策略模式)来表达他们的需求。
# Built-in strategies for selecting the optimal power limit.
from zeus.optimizer.power_limit import (
GlobalPowerLimitOptimizer,
Time,
Energy,
MaxSlowdownConstraint,
)
# Minimize energy while tolerating at most 10% slowdown.
plo = GlobalPowerLimitOptimizer(
monitor,
MaxSlowdownConstraint(factor=1.1),
)
一些内置策略包括“最小化时间”(Time,这可能仍然会降低默认的功率限制,因为一些工作负载即使在较低的功率限制下也几乎没有减速),“最小化能量”(Energy),“两者之间”(ZeusCost),以及“在最大减速限制下最小化能量”(MaxSlowdownConstraint)。用户也可以根据需要创建自己的最佳选择器。
PipelineFrequencyOptimizer
基于我们的研究论文Perseus,管道频率优化器是我们针对大型模型训练(如GPT-3)能耗优化的最新工作。Perseus可以减少大型模型训练的能耗,而训练吞吐量几乎没有或可以忽略不计的退化。我们将简要介绍其原理。
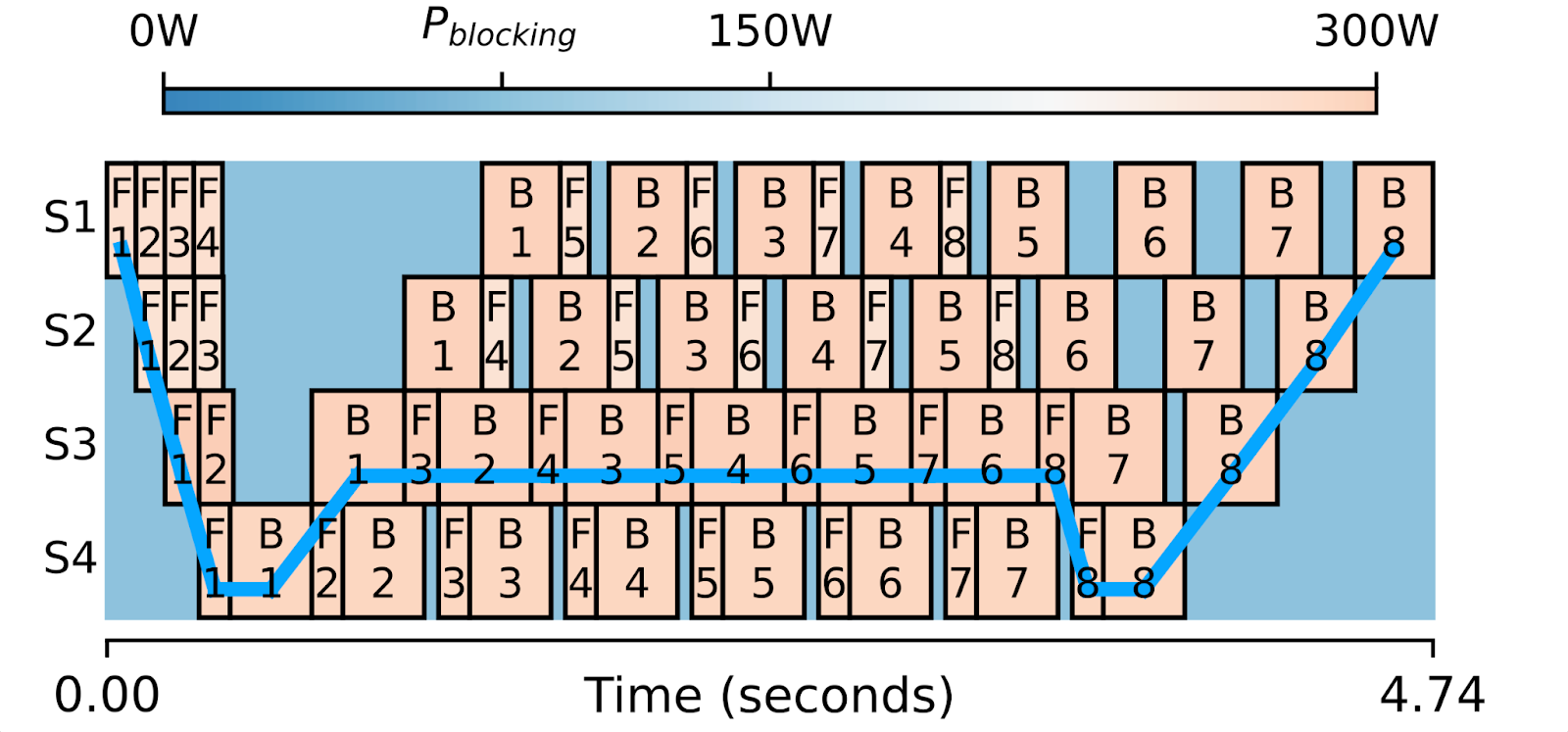
上图是采用1F1B调度运行的四阶段管道并行训练的一次迭代的可视化。每个方框代表一个前向或后向计算,并以其功耗着色。
这里的关键观察是,当模型被分割成管道阶段时,很难将它们精确地分割成相等的大小。这导致前向/后向方框宽度不同,从而在方框之间产生计算空闲时间。您会注意到那些较小的方框可以比更宽的方框运行得稍慢,并且整体关键路径(蓝线)根本不会改变。
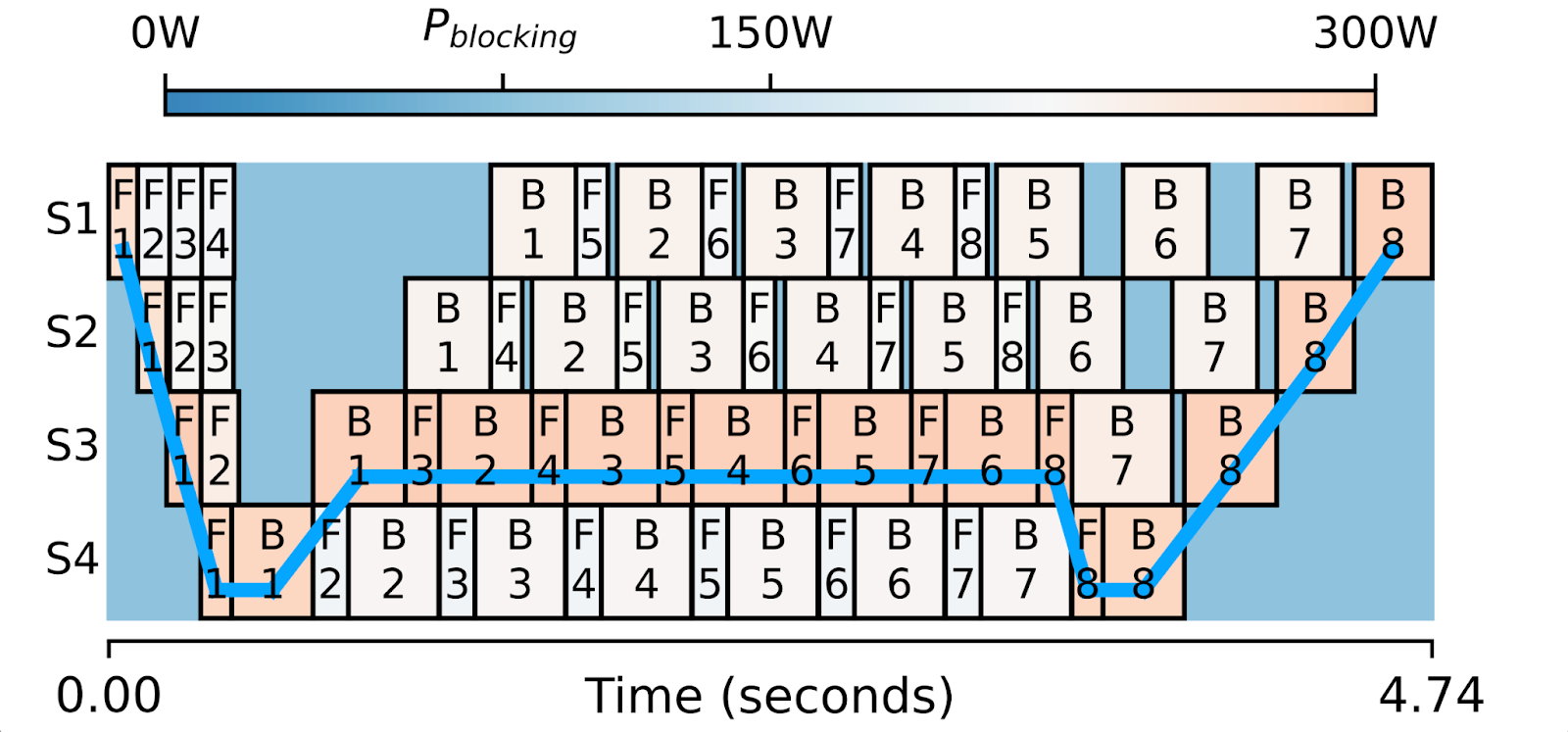
这就是Perseus自动完成的事情。它基于剖析,识别出不在关键路径上的计算方框,并找出每个方框精确的减速量,以最小化能耗。如果操作正确,我们减速的计算将消耗更少的功率和能量,但管道的整体迭代时间不会改变。
请参阅我们的指南,开始使用Perseus!
最后的话
对于使用自己的本地计算的用户来说,能耗和由此产生的电费是不容忽视的。从更大的范围来看,能耗不仅仅是电费的问题,还涉及到数据中心的电力供应。随着数千个GPU在集群中运行,寻找稳定、经济且可持续的电力来源来为数据中心供电正变得越来越具挑战性。寻找能比减速不成比例地更多地减少能耗的方法,可以降低平均功耗,这有助于解决电力供应的挑战。
通过Zeus,我们希望迈出深度学习能耗测量和优化的第一步。
想知道接下来要去哪里?这里有一些有用的链接:
- ML.ENERGY Initiative(即构建Zeus的人员)
- Zeus主页/文档
- Zeus GitHub仓库
- Zeus使用和集成示例