引言
ZenFlow是2025年夏季引入的DeepSpeed新扩展,旨在作为大型语言模型(LLM)训练的无停滞卸载引擎。卸载是一种广泛使用的技术,用于缓解LLM模型规模不断增长所导致的GPU内存压力。然而,近年来CPU-GPU性能差距已扩大数个数量级。传统的卸载框架(如DeepSpeed ZeRO-Offload)通常由于在较慢的CPU上卸载计算而导致严重的GPU停滞。
我们很高兴发布ZenFlow,它通过重要性感知流水线解耦了GPU和CPU更新。通过将CPU工作和PCIe传输与GPU计算完全重叠,我们看到了超过85%的停滞减少,以及高达5倍的加速!这确保了我们可以在享受卸载带来的内存优势的同时,不会因为较慢的硬件而牺牲训练速度。
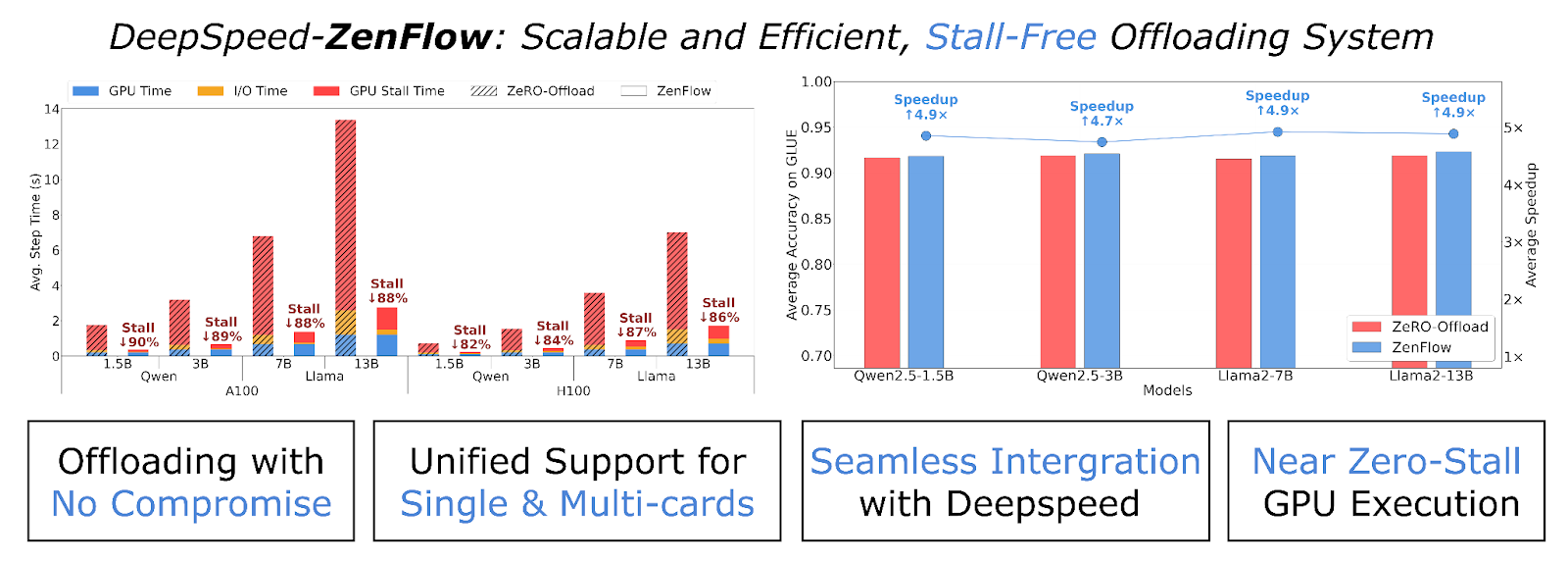
图1:ZenFlow是DeepSpeed用于LLM训练的无停滞卸载引擎。它通过优先处理重要梯度以进行即时GPU更新,并将其余梯度推迟到异步CPU侧累积,从而解耦了GPU和CPU的更新。通过将CPU工作和PCIe传输与GPU计算完全重叠,ZenFlow消除了停滞,并在单GPU和多GPU设置中实现了高硬件利用率。
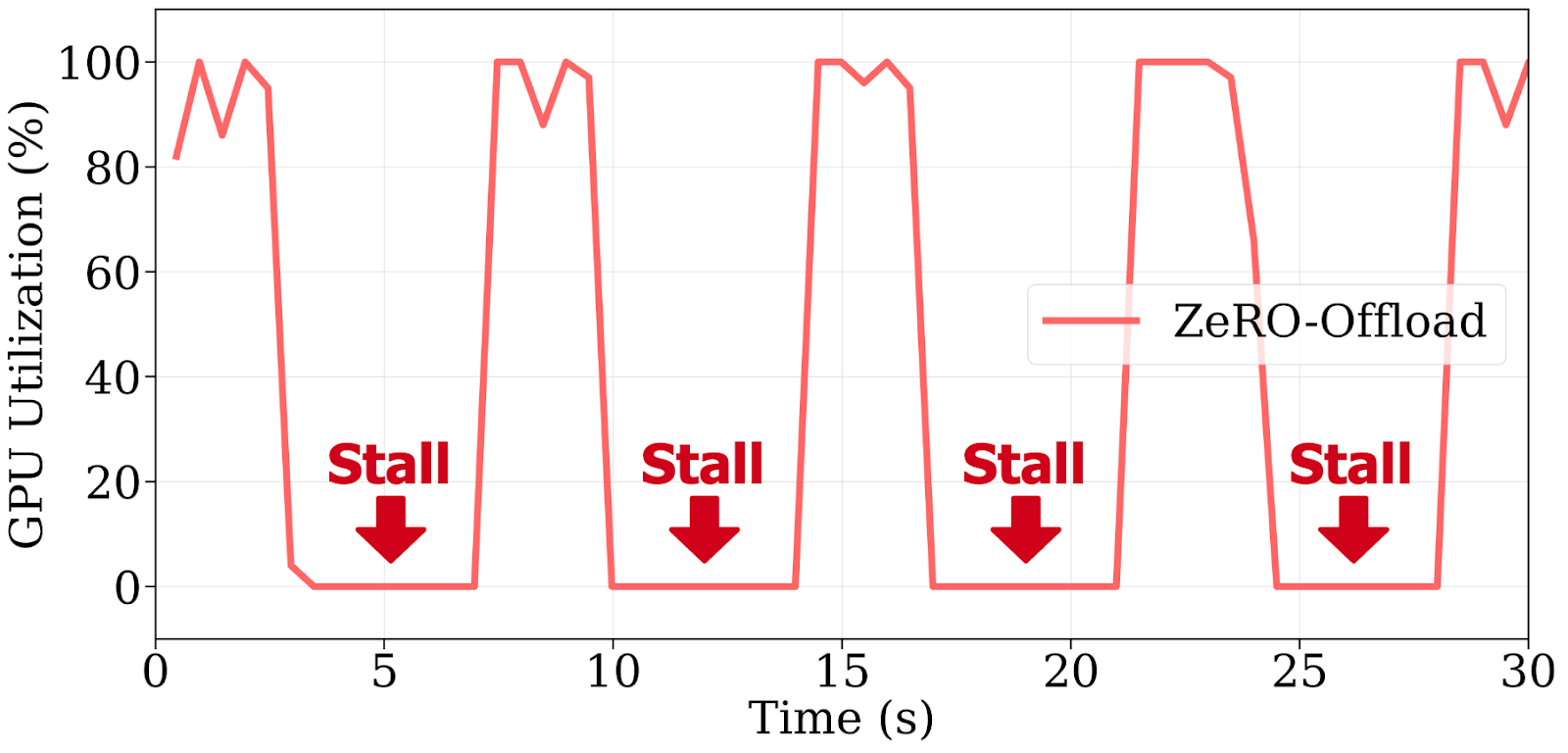
图2:ZeRO-Offload由于阻塞CPU更新和PCIe传输,导致重复的GPU停滞,在4块A100上训练Llama 2-7B时,每步闲置时间超过60%。
卸载已成为一种标准方法,用于将大型语言模型(LLM)的微调扩展到超出GPU内存限制。ZeRO-Offload等框架通过将梯度和优化器状态推送到CPU来减少GPU内存使用。然而,它们也创建了一个新的瓶颈:昂贵的GPU经常闲置,等待缓慢的CPU更新和PCIe数据传输。实际上,在4块A100 GPU上训练Llama 2-7B时启用卸载,可以将每步时间从0.5秒增加到7秒以上,这是一个14倍的减速。
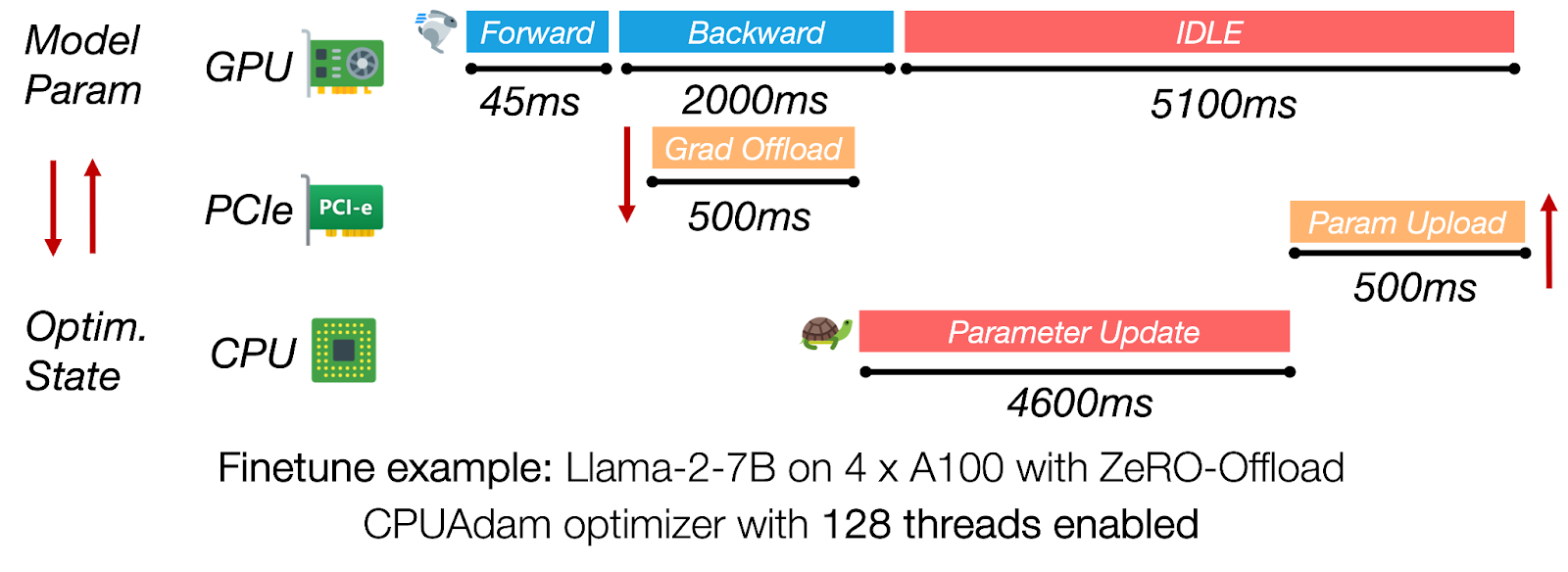
图3:在ZeRO-Offload中,CPU侧优化器更新和PCIe传输占据了迭代时间的主导地位,使GPU闲置超过5秒。
ZenFlow 通过无停滞训练流水线解决了这一瓶颈。它优先处理高影响力的梯度以进行即时GPU更新,同时将其余梯度卸载到CPU并异步应用它们。这些延迟的CPU更新与GPU计算完全重叠,消除了停滞并显著提高了吞吐量。最重要的是,ZenFlow保持了相同的模型精度,并与DeepSpeed无缝集成。
ZenFlow 概览
- 零GPU停滞: 最重要的k个梯度立即在GPU上更新;低优先级梯度在CPU上异步处理——没有GPU等待时间。
- 异步且有界: ZenFlow通过有界陈旧性策略解耦了CPU和GPU的执行,从而保持了收敛性。
- 自动调优: ZenFlow根据梯度动态在运行时调整更新间隔——无需手动调优。
ZenFlow 亮点
ZenFlow 是第一个提供有界异步更新方案的卸载框架,该方案在保持收敛性的同时,实现了相对于ZeRO-Offload高达5倍的端到端加速。
性能
| 特性 | 优势 |
|---|---|
| 相对于ZeRO-Offload高达5倍的端到端加速,相对于ZeRO-Infinity高达6.3倍的加速 | 更快的收敛时间 |
| 在A100/H100节点上GPU停滞减少> 85% | 保持GPU繁忙,更高的利用率 |
| PCIe流量降低约2倍(每步1.13倍模型大小,而ZeRO中为2倍) | 减少集群带宽压力 |
| 在GLUE上保持或提高了精度(OPT-350M → Llama-13B) | 无精度损失 |
| 轻量级梯度选择(比完全AllGather便宜6000倍) | 扩展到多GPU设置而不会出现内存占用飙升 |
| 自动调优(Zen-auto)在运行时自动调整更新间隔 | 无需手动调整参数 |
有关更详细的性能结果,请参阅我们的arXiv论文。
设计动机
使用卸载训练大型模型可以节省GPU内存,但通常以牺牲性能为代价。在本节中,我们将简要讨论三个主题。首先,我们解释为什么将CPU侧优化器更新与GPU计算耦合会导致LLM微调期间严重的GPU停滞。其次,我们量化了全梯度卸载如何饱和A100/H100服务器有限的PCIe带宽,从而增加了迭代时间。最后,我们揭示了梯度高度倾斜的重要性分布,表明同时统一更新GPU中所有参数是浪费且不必要的。
卸载导致的GPU停滞
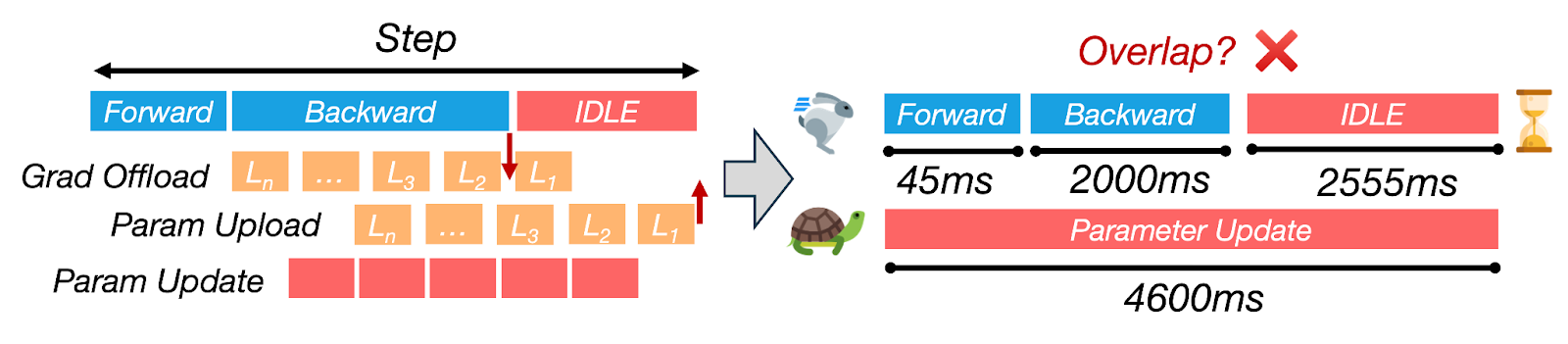
图4:CPU更新主导了步长时间,由于与计算的重叠不足,导致GPU闲置超过60%。
同步卸载框架(例如,ZeRO-Offload)在CPU执行完整优化器步骤并将更新的参数传输回GPU时,使GPU处于空闲状态。对于Llama-2-7B在4块A100上的训练,CPU路径可能需要超过4秒,而反向传播则需要大约2秒,因此每次迭代超过60%的时间是纯粹的GPU等待时间。消除这种序列化对于实现高GPU利用率至关重要。
带宽瓶颈
单个训练步骤将完整的模型梯度副本从GPU传输到CPU,并将完整的模型参数副本传回,即每步PCIe流量为模型大小的2倍。即使在PCIe 4.0(约32 GB/s)上,Llama-2-13B每次迭代也要传输约40 GB,增加了超过1秒的传输延迟。
梯度重要性不均
并非所有梯度都同等重要。我们的分析表明,在微调过程中,前1%的梯度通道贡献了超过90%的L²范数能量。换句话说,大多数更新对模型学习的影响很小,但在传统卸载流水线中仍会产生不成比例的高计算和I/O成本。
梯度重要性的这种倾斜为更好的设计打开了大门:立即在GPU上更新关键梯度,并将其余梯度推迟到CPU上进行异步批量、低优先级的更新。ZenFlow将这一想法转化为一个原则性的、高效的训练引擎。
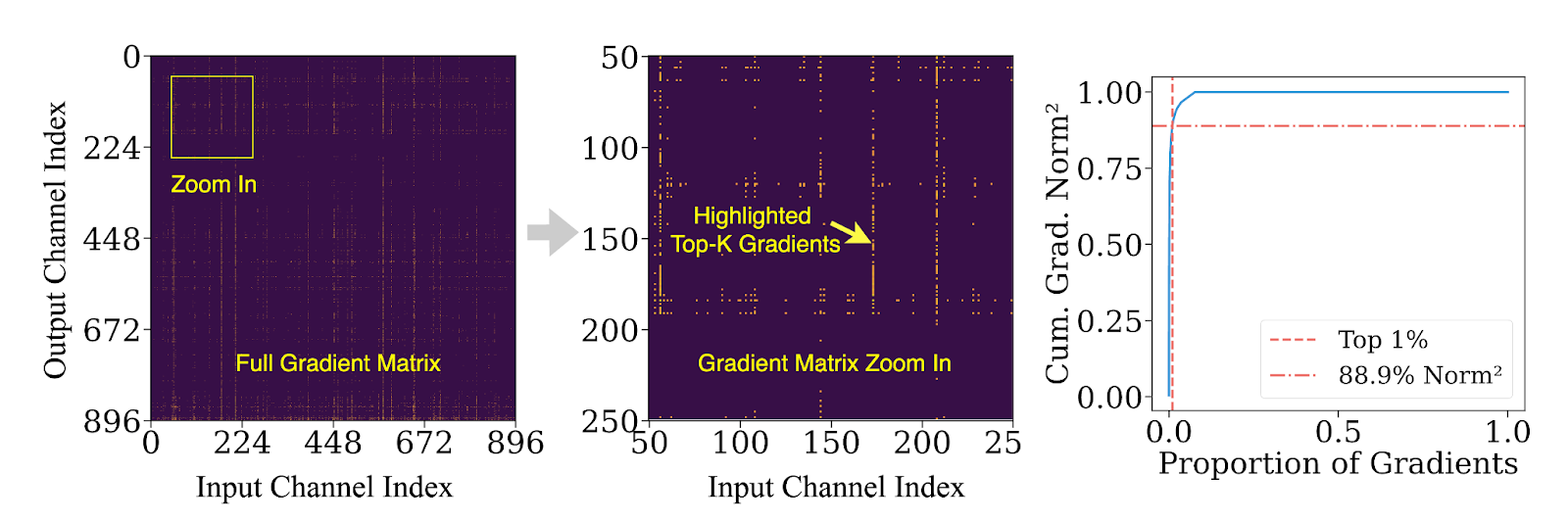
图5:前1%的梯度可能贡献超过85%的梯度范数。
ZenFlow设计
ZenFlow围绕三个关键思想进行设计,这些思想将关键和非关键梯度更新分开,同时最大限度地减少通信瓶颈。以下是我们如何打破GPU和CPU计算之间的紧密耦合,以创建无停滞流水线的方法。
思路1:重要性感知Top-k梯度更新
并非所有梯度对训练的影响都相同。ZenFlow引入了重要性感知设计,优先更新前k个最重要的梯度。这些梯度直接在GPU上更新,利用其高计算带宽。这种方法使我们能够将每步梯度更新的大小减少近50%,从而将通信负载减少约2倍。
对于其余对模型学习贡献较小的梯度,ZenFlow将它们批量处理并在CPU上执行异步更新。这些更新会延迟,直到它们充分累积,从而减少对训练速度的影响。
思路2:有界异步CPU累积
ZenFlow的异步累积允许CPU在GPU执行其他计算时保持忙碌。我们对非关键梯度应用了累积窗口,允许它们在多次迭代中累积,然后再进行更新。这使得ZenFlow能够同时处理多轮梯度更新,消除了通常花费在等待CPU优化器上的空闲时间。
通过仔细协调CPU更新与GPU执行,ZenFlow完全隐藏了CPU执行在GPU计算之后——确保GPU保持活跃利用,避免停滞,并最大化硬件效率。
思路3:轻量级梯度选择
分布式训练中的一个主要挑战是选择重要的梯度,同时不引入过高的通信和GPU内存成本。传统系统依赖全局同步(通过AllGather)来收集完整梯度,这在多GPU设置中可能成为主要瓶颈。
ZenFlow通过轻量级梯度代理解决了这个问题:ZenFlow不是传输完整的梯度,而是使用每列梯度范数来近似每个梯度的重要性。通过计算每列梯度的紧凑摘要(例如,平方范数),ZenFlow将通信量减少了超过4,000倍——几乎没有精度损失。
这种方法使ZenFlow能够高效地跨GPU扩展,而不会产生高内存或通信开销,并且它支持动态梯度选择,因为模型会演变。
整合所有:ZenFlow的零停滞流水线
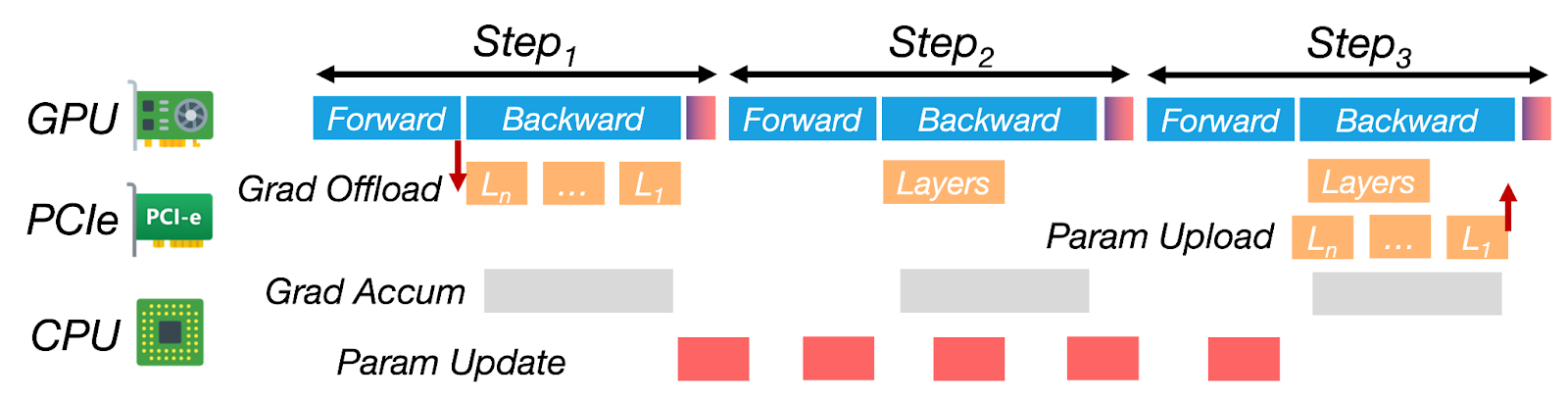
图6:ZenFlow的无停滞流水线将CPU更新和传输与多步GPU计算重叠。
- GPU上的前向/后向传播: ZenFlow在GPU上处理前向和后向传播,立即在GPU上更新top-k梯度,而无需等待CPU。
- 梯度传输到CPU: 当GPU忙碌时,来自当前迭代(或先前迭代)的梯度通过专用PCIe流传输到CPU。这与GPU计算并行进行,不会导致任何GPU等待时间。
- CPU更新: 一旦累积了一批非关键梯度,CPU就会异步执行更新。此更新通常跨越多个GPU迭代,但隐藏在GPU工作之后,使其在整个流水线中几乎不可见。
- 双缓冲: ZenFlow使用双缓冲来管理新更新的梯度。当CPU更新完成后,新参数会传回GPU。交换速度和指针翻转一样快——无需重新加载整个模型或重新启动内核。
通过不断将GPU计算与CPU侧工作重叠,ZenFlow将传统的计算→等待→更新循环转变为连续的无停滞流水线。
入门:试用DeepSpeed-ZenFlow
要试用DeepSpeed-ZenFlow,请参阅我们DeepSpeedExamples仓库中的ZenFlow示例以及DeepSpeed中的ZenFlow教程。
引用
@article{lan2025zenflow,
title = {ZenFlow: 通过异步更新实现无停滞卸载训练},
author = {Tingfeng Lan and Yusen Wu and Bin Ma and Zhaoyuan Su and Rui Yang and Tekin Bicer and Masahiro Tanaka and Olatunji Ruwase and Dong Li and Yue Cheng},
journal = {arXiv 预印本 arXiv:2505.12242},
year = {2025}
}
致谢
这项工作是弗吉尼亚大学 (UVA)、加利福尼亚大学默塞德分校 (UC Merced)、阿贡国家实验室 (ANL) 和 DeepSpeed 团队密切合作的成果。
贡献者包括来自UVA的Tingfeng Lan、Yusen Wu、Zhaoyuan Su、Rui Yang和Yue Cheng;来自UC Merced的Bin Ma和Dong Li;来自ANL的Tekin Bicer;以及来自DeepSpeed团队的Olatunji Ruwase和Masahiro Tanaka。我们特别感谢Olatunji Ruwase和Masahiro Tanaka的早期反馈和富有洞察力的讨论,以及对开源社区的支持。