PyTorch* 2.6 刚刚发布了一系列令人兴奋的新功能,包括 torch.compile 与 Python 3.13 的兼容性、新的安全性和性能增强,以及 torch.load 默认参数的更改。PyTorch 还宣布弃用其官方 Anaconda 频道。
在众多性能功能中,有三项功能增强了开发人员在英特尔平台上的生产力:
- 改进了英特尔 GPU 的可用性
- 适用于 LLM 的 x86 CPU 上的 FlexAttention 优化
- Eager 和 Inductor 模式下的 x86 CPU 支持 FP16
改进了英特尔 GPU 可用性
为了向从事人工智能 (AI) 工作的开发人员提供更好的英特尔 GPU 支持,PyTorch 在这些 GPU 上的用户体验得到了增强。此改进包括简化的安装步骤、Windows* 发布二进制分发,以及扩大了支持的 GPU 型号范围,包括最新的英特尔® Arc™ B 系列独立显卡。
这些新功能有助于在 PyTorch 生态系统中促进加速机器学习工作流程,提供一致的开发人员体验和支持。寻求在 英特尔® 酷睿™ Ultra AI PC 和 英特尔® Arc™ 独立显卡 上微调、执行推理和开发 PyTorch 模型的应用程序开发人员和研究人员,现在可以直接通过 Windows、Linux* 和适用于 Linux 2 的 Windows 子系统 的二进制版本安装 PyTorch。
新功能包括:
- 简化的英特尔 GPU 软件堆栈设置,支持一键式安装 torch-xpu PIP wheel,以即用型方式运行深度学习工作负载,从而消除了安装和激活英特尔 GPU 开发软件包的复杂性。
- 适用于英特尔 GPU 的 torch core、torchvision 和 torchaudio 的 Windows 二进制版本已推出,支持范围从 英特尔® 酷睿™ Ultra 第二代(含英特尔® Arc™ 显卡)和 英特尔® Arc™ A 系列显卡 扩展到最新的 GPU 硬件 英特尔® Arc™ B 系列显卡 支持。
- 通过 SYCL* 内核进一步增强了英特尔 GPU 上 Aten 算子的覆盖范围,以实现流畅的 Eager 模式执行,并修复了英特尔 GPU 上 torch.compile 的错误并进行了性能优化。
请参阅 入门指南,了解英特尔® 客户端 GPU 和英特尔® 数据中心 GPU Max 系列上的新环境设置、PIP wheels 安装和示例。
适用于 LLM 的 X86 CPU 上的 FlexAttention 优化
FlexAttention 最初在 PyTorch 2.5 中引入,旨在解决支持各种 Attention 甚至 Attention 组合的需求。此 PyTorch API 利用 torch.compile 生成融合的 FlashAttention 内核,消除了额外的内存分配,并实现了与手写实现相当的性能。
以前,FlexAttention 是针对基于 Triton 后端的 CUDA* 设备实现的。自 PyTorch 2.6 起,通过 TorchInductor CPP 后端添加了 FlexAttention 的 X86 CPU 支持。此新功能利用并扩展了当前的 CPP 模板能力,以支持基于现有 FlexAttention API 的各种 Attention 变体(例如,对 LLM 推理至关重要的 PageAttention),并在 x86 CPU 上带来了优化的性能。借助此功能,用户可以轻松使用 FlexAttention API 在 CPU 平台上构建其 Attention 解决方案,并获得良好的性能。
通常,FlexAttention 被流行的 LLM 生态系统项目(例如 Hugging Face transformers 和 vLLM)在其 LLM 相关建模(例如 PagedAttention)中利用,以实现更好的开箱即用性能。在正式采用之前,Hugging Face 中的 此启用 PR 可以帮助我们了解 FlexAttention 在 x86 CPU 平台上可以带来的性能优势。
下图显示了 PyTorch 2.6(具有此功能)和 PyTorch 2.5(不具有此功能)在典型 Llama 模型上的性能比较。对于实时模式(批量大小 = 1),不同输入令牌长度的下一个令牌性能约有 1.13x-1.42x 的改进。对于典型 SLA(P99 令牌延迟 <= 50 毫秒)下的最佳吞吐量,PyTorch 2.6 的性能是 PyTorch 2.5 的 7.83 倍以上,因为 PyTorch 2.6 可以同时运行 8 个输入(批量大小 = 8)并仍然保持 SLA,而 PyTorch 2.5 只能运行 1 个输入,因为 PyTorch 2.6 中基于 FlexAttention 的 PagedAttention 在多个批量大小场景中提供了更高的效率。
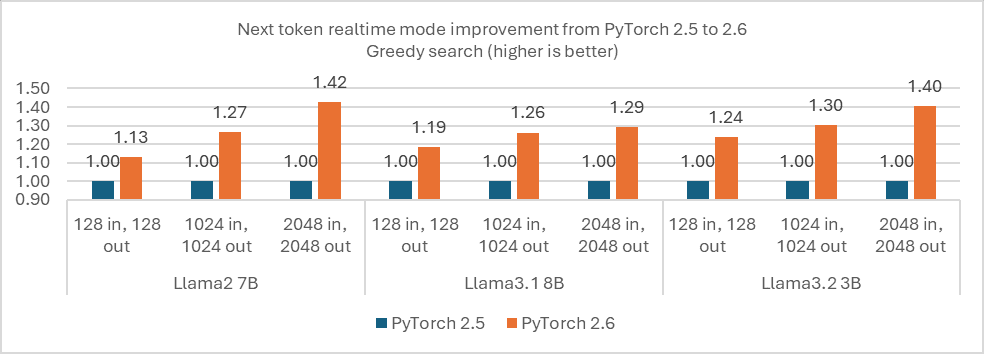
图 1. PyTorch 2.6 和 PyTorch 2.5 在典型 Llama 模型上的性能比较
Eager 和 Inductor 模式下的 X86 CPU 支持 FP16
Float16 是一种常用的精简浮点类型,可提高神经网络推理和训练的性能。像最近推出的 英特尔® 至强® 6 配备 P 核 等 CPU 支持带原生加速器 AMX 的 Float16 数据类型,这极大地提高了 Float16 性能。x86 CPU 上的 Float16 支持最初在 PyTorch 2.5 中作为原型功能引入。现在它已针对 Eager 模式和 Torch.compile + Inductor 模式进行了进一步改进,并已推送到 Beta 级别以实现更广泛的采用。当模型预训练为 Float16/Float32 混合精度时,这有助于在 CPU 端进行部署,而无需修改模型权重。在支持 AMX Float16 的平台(即配备 P 核的英特尔® 至强® 6 处理器)上,Float16 在典型的 PyTorch 基准测试套件(TorchBench、Hugging Face 和 Timms)中具有与 Bfloat16 相同的通过率。它还显示出与 16 位数据类型 Bfloat16 相当的良好性能。
总结
在本博客中,我们讨论了 PyTorch 2.6 中旨在增强英特尔平台开发人员生产力的三项功能。这三项功能旨在提高英特尔 GPU 的可用性,优化适用于大型语言模型 (LLM) 的 x86 CPU 上的 FlexAttention,并在 Eager 和 Inductor 模式下支持 x86 CPU 上的 FP16。获取 PyTorch 2.6 并亲自尝试,或者您可以在 英特尔® Tiber™ AI 云 上访问 PyTorch 2.6,以利用针对英特尔硬件和软件优化的托管笔记本。
致谢
PyTorch 2.6 的发布是英特尔平台的一个激动人心的里程碑,如果没有社区的深入协作和贡献,这一切都将无法实现。我们衷心感谢 Alban、Andrey、Bin、Jason、Jerry 和 Nikita 分享他们宝贵的想法,仔细审查 PR 并就 RFC 提供富有洞察力的反馈。他们的奉献推动了持续改进并推动了英特尔平台的生态系统发展。
参考文献
产品和性能信息
在 AWS EC2 m7i.metal-48xl 上使用以下配置进行测量:2x 英特尔® 至强® 铂金 8488C,超线程开启,睿频加速开启,NUMA 2,集成加速器可用 [已使用]:DLB [8]、DSA [8]、IAA [8]、QAT [CPU 上,8],总内存 512GB (16x32GB DDR5 4800 MT/s [4400 MT/s]),BIOS Amazon EC2 1.0,微码 0x2b000603,1x 弹性网络适配器 (ENA) 1x Amazon 弹性块存储 800G,Ubuntu 24.04.1 LTS 6.8.0-1018-aws。由英特尔于 2025 年 1 月 15 日测试。
注意事项和免责声明
性能因使用、配置和其他因素而异。请访问性能指数网站了解更多信息。性能结果基于所示配置下的测试日期,可能无法反映所有公开发布的更新。 请参阅备份以获取配置详情。 没有任何产品或组件是绝对安全的。您的成本和结果可能有所不同。英特尔技术可能需要启用硬件、软件或服务激活。
英特尔公司。英特尔、英特尔徽标和其他英特尔标志是英特尔公司或其子公司的商标。其他名称和品牌可能属于他人所有。
AI 免责声明
AI 功能可能需要软件购买、订阅或由软件或平台提供商启用,或者可能具有特定的配置或兼容性要求。详情请访问 www.intel.com/AIPC。结果可能有所不同。