引言
在最近的PyTorch大会上,Arm强调了其技术从云端到边缘的广泛影响,并强调了其致力于将先进的AI计算能力无缝地提供给全球数百万开发者的承诺。

在演讲中,Arm强调了其肩负的巨大责任:为2000多万开发者和数十亿用户提供无摩擦的先进AI计算功能。实现这一目标需要跨越庞大的软件和硬件合作伙伴生态系统进行关键的软件协作。
就在几个月前,Arm发布了Arm Kleidi,这是一套开发者赋能技术和资源,旨在推动ML堆栈的技术协作和创新。这包括KleidiAI软件库,它提供了优化的软件例程,当集成到XNNPACK等关键框架中时,可以为Arm Cortex-A CPU上的开发者实现自动AI加速。
今天,我们很高兴地宣布AI开源社区的一个新里程碑,这使Arm离实现这一愿景更近了一步:通过XNNPACK将KleidiAI集成到ExecuTorch中,从而提升Arm移动CPU上的AI工作负载性能!
得益于Arm和Meta工程团队的协作努力,AI开发者现在可以部署量化的Llama模型,这些模型在具有i8mm ISA扩展的Arm Cortex-A v9 CPU上运行速度可提高20%。
还有更多令人兴奋的消息——ExecuTorch团队已正式发布Beta版本!
这标志着我们合作的一个重要里程碑。在这篇博客中,我们渴望分享更多关于ExecuTorch能力、新的Meta Llama 3.2模型、带块级量化的4位整数以及在某些Arm CPU上记录的惊人性能的详细信息。值得注意的是,在Samsung S24+设备上,使用量化的Llama 3.2 1B模型,我们在预填充阶段实现了每秒超过350个token的速度,如以下屏幕截图所示。
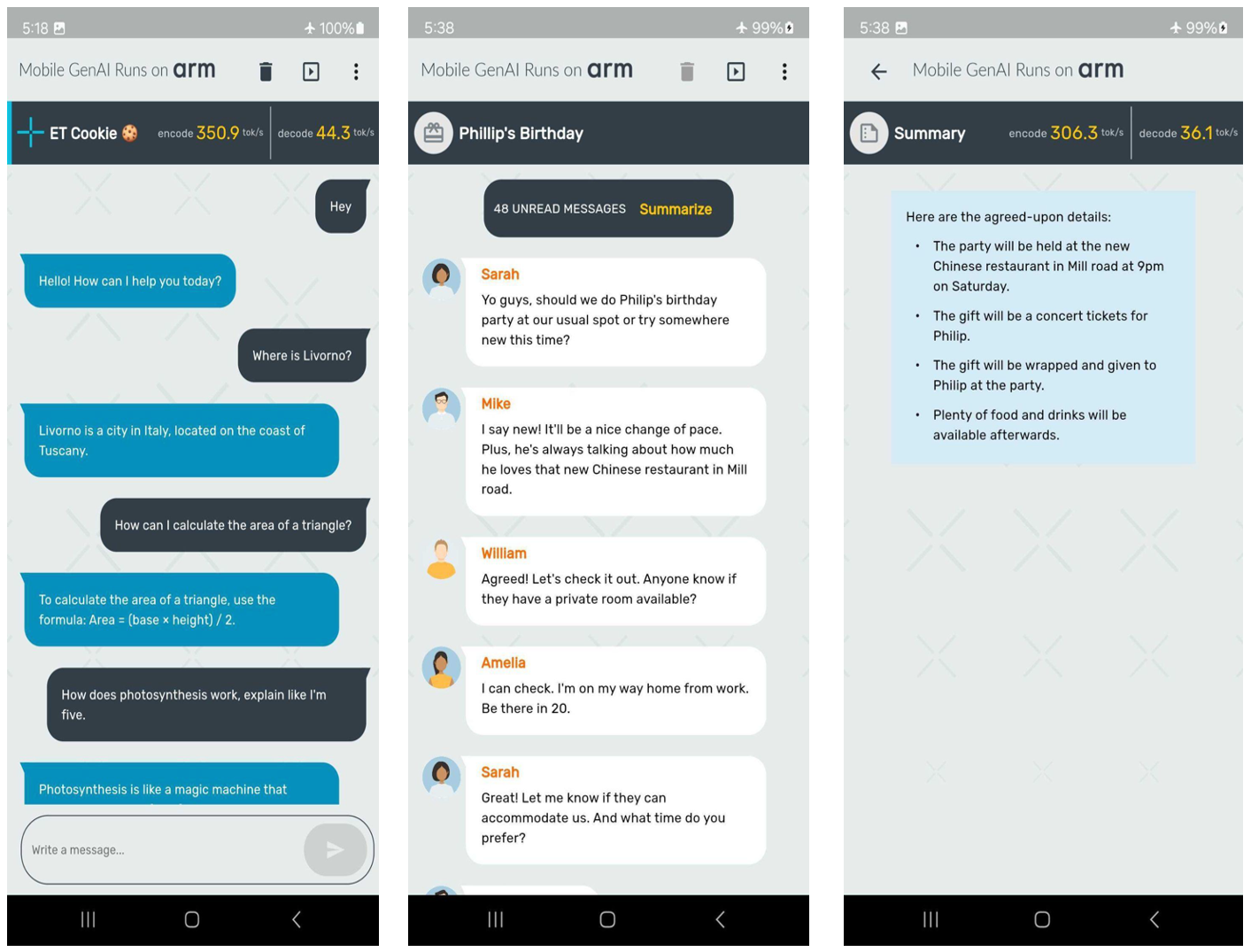
现在,让我们深入探讨实现前述图片中演示的关键组件。首先:新的Llama 3.2模型!
Meta Llama 3.2
Meta最近宣布了首批轻量级量化Llama模型,这些模型旨在在流行的移动设备上运行。Meta使用两种技术对Llama 3.2 1B和3B模型进行量化:带有LoRA适配器(QLoRA)的量化感知训练(QAT),以及最先进的训练后量化方法SpinQuant。量化模型使用PyTorch的ExecuTorch框架作为推理引擎,Arm CPU作为后端进行评估。
这些指令调优模型保留了原始1B和3B模型的质量和安全性,同时实现了2-4倍的加速,并且与原始BF16格式相比,模型大小平均减少了56%,内存占用平均减少了41%。
在这篇博客文章中,我们将展示我们在实验中观察到的性能改进。
ExecuTorch
ExecuTorch是一个PyTorch原生框架,专门设计用于在设备上部署AI模型,增强隐私并减少延迟。它支持部署最先进的开源AI模型,包括Llama系列模型以及视觉和语音模型,如Segment Anything和Seamless。
这为手机、智能眼镜、VR头显和智能家居摄像头等边缘设备开启了新的可能性。传统上,将PyTorch训练的AI模型部署到资源有限的边缘设备既具有挑战性又耗时,通常需要转换为其他格式,这可能导致错误和次优性能。硬件和边缘生态系统中多样化的工具链也降低了开发者体验,使得通用解决方案不切实际。
ExecuTorch通过提供可组合组件来解决这些问题,这些组件包括核心运行时、操作符库和委托接口,从而实现可移植性和可扩展性。模型可以使用torch.export()导出,生成一个与ExecuTorch运行时原生兼容的图,能够在大多数带有CPU的边缘设备上运行,并可扩展到GPU和NPU等专用硬件以提高性能。
与Arm合作,ExecuTorch现在利用Arm KleidiAI库中优化的低位矩阵乘法内核,通过XNNPACK提高设备上的大型语言模型(LLM)推理性能。我们还要感谢Google的XNNPACK团队对这项工作的支持。
在这篇文章中,我们将重点关注ExecuTorch中提供的这种集成
不断发展的AI工作负载架构
在Arm,自深度学习浪潮早期以来,我们一直致力于投资开源项目并在我们的处理器中推进新技术,专注于使AI工作负载高性能且更节能。
例如,Arm引入了SDOT指令,从Armv8.2-A架构开始,以加速8位整数向量之间的点积运算。此功能现已广泛应用于移动设备,显著加快了量化8位模型的计算速度。在SDOT指令之后,Arm引入了BF16数据类型和MMLA指令,以进一步增强CPU上的浮点和整数矩阵乘法性能,最近又宣布了可伸缩矩阵扩展(SME),标志着机器学习能力取得了重大飞跃。
下图展示了Arm CPU在过去十年中在AI领域持续创新的一些示例

鉴于Arm CPU的广泛使用,AI框架需要充分利用这些技术中的关键操作符,以最大限度地提高性能。认识到这一点,我们看到了对一个开源库的需求,以共享这些优化的软件例程。然而,我们注意到了将新库集成到AI框架中的挑战,例如对库大小、依赖项和文档的担忧,以及避免给开发者增加额外负担的必要性。因此,我们采取了额外的步骤,收集了合作伙伴的反馈,并确保了平滑的集成过程,这不需要AI开发者额外的依赖项。这项努力催生了KleidiAI,这是一个开源库,为Arm CPU量身定制,为人工智能(AI)工作负载提供优化的性能关键例程。您可以在此处了解更多关于KleidiAI的信息。
与Meta的ExecuTorch团队合作,Arm为他们新颖的带块级量化的4位量化方案提供了软件优化,该方案用于加速Llama 3.2量化模型的Transformer层中torch.nn.linear操作符的矩阵乘法内核。ExecuTorch的这种灵活的4位量化方案在模型精度和针对设备上LLM的低位矩阵乘法性能之间取得了平衡。
带块级量化的4位整数
在KleidiAI中,我们引入了针对这种新的4位整数量化方案优化的微内核(matmul_clamp_f32_qai8dxp_qsi4c32p)
如下图所示,这种4位量化对权重(RHS矩阵)量化采用块级策略,对激活(LHS矩阵)采用8位每行量化。
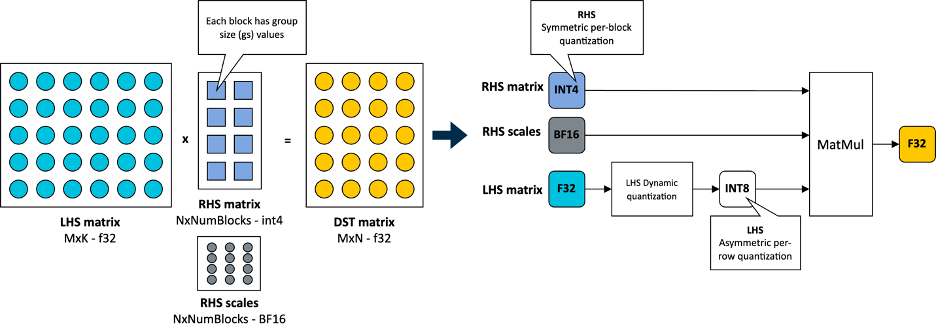
正如您在前面图像中看到的,权重矩阵中的每个输出特征图(OFM)都被分成大小相等的块(组大小),每个块都有一个以BF16格式存储的比例因子。BF16的优点在于它以一半的位大小保持了32位浮点(FP32)格式的动态范围,并且通过简单的移位操作可以轻松地在FP32之间进行转换。这使得BF16成为节省模型空间、保持精度以及确保与缺乏BF16硬件加速的设备向后兼容的理想选择。您可以在这篇Arm社区博客文章中了解更多关于BF16格式的信息。
为了完整起见,这种4位量化方案和我们在KleidiAI中的实现允许用户为线性权重(RHS)配置组大小,从而允许他们在模型大小、模型精度和模型性能之间进行权衡,如果模型由用户量化的话。
此时,我们准备揭示在Arm CPU上运行Llama 3.2 1B和Llama 3.2 3B时,ExecuTorch记录的令人难以置信的性能。让我们首先回顾一下我们将用于评估LLM推理性能的指标。
LLM推理的度量标准
通常,用于评估LLM推理性能的度量标准包括:
- 首个Token生成时间(TTFT):这衡量了用户提供提示后生成第一个输出token所需的时间。这种延迟或响应时间对于良好的用户体验很重要,尤其是在手机上。TTFT也是提示或提示token长度的函数。为了使此指标独立于提示长度,我们在此使用“预填充tokens/秒”作为替代。它们之间的关系是反比的:较低的TTFT对应于较高的预填充tokens/秒。
- 解码性能:这是每秒生成的平均输出token数量,因此以“Tokens/秒”报告。它独立于生成的总token数量。对于设备上推理,将其保持高于用户的平均阅读速度非常重要。
- 峰值运行时内存:此指标反映了运行模型所需的RAM量,通常以兆字节(MiB)报告,其性能使用上述指标衡量。考虑到Android和iOS设备上可用的RAM数量有限,这是设备上LLM部署的关键指标之一。它决定了可以在设备上部署的模型类型。
结果
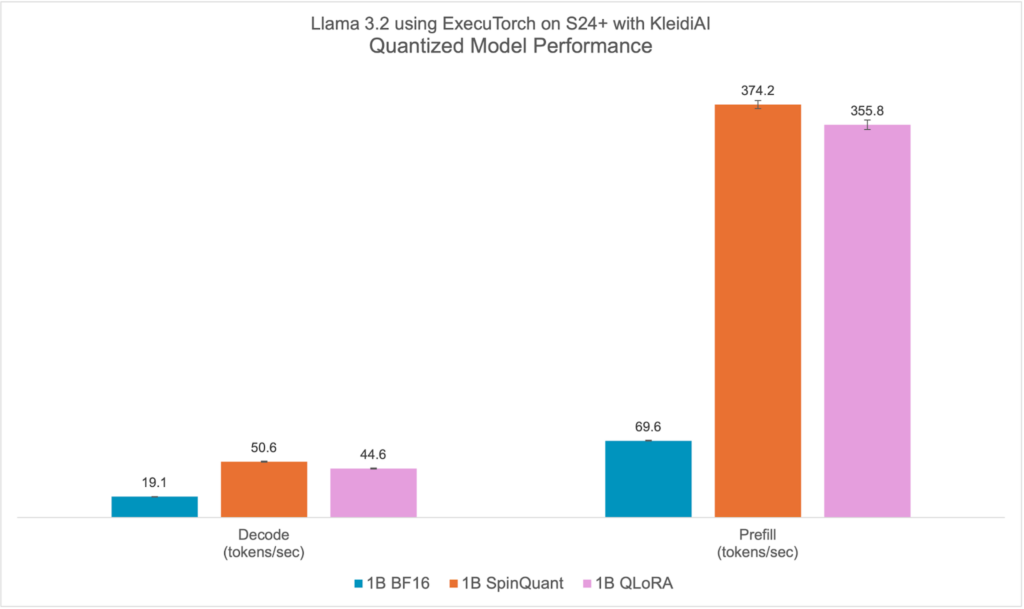
量化的Llama 3.2 1B模型,包括SpinQuant和QLoRA,都设计用于在RAM有限的各种手机上高效运行。在本节中,我们演示了量化的Llama 3.2 1B模型可以在预填充阶段实现每秒超过350个token,在解码阶段实现每秒超过40个token。这种性能水平足以仅使用Arm CPU就能在设备上实现文本摘要,并提供合理的用户体验。从这个角度来看,平均50条未读消息包含大约600个token。凭借这种性能,响应时间(屏幕上出现第一个生成单词所需的时间)约为两秒。
我们展示了在运行原生Android的Samsung S24+上的测量结果。我们使用Llama 3.2 1B参数模型进行这些实验。尽管我们只演示了使用1B模型,但对于3B参数模型也可以预期类似的性能增益。实验设置包括进行一次热身运行,序列长度为128,提示长度为64,使用8个可用CPU中的6个,并测量通过adb获得的结果。
使用GitHub上的ExecuTorch主分支,我们首先为每个模型使用已发布的检查点生成ExecuTorch PTE二进制文件。然后,使用相同的存储库,我们为Armv8生成了ExecuTorch运行时二进制文件。在本节的其余部分,我们将比较不同量化1B模型与BF16模型的性能,使用使用KleidiAI构建的二进制文件。我们还将比较使用KleidiAI的二进制文件和不使用KleidiAI的二进制文件之间量化模型的性能增益,以提取KleidiAI的影响。
量化模型性能
与基线BF16相比,Llama 3.2量化模型(包括SpinQuant和QLoRA)在提示预填充和文本生成(解码)方面表现显著更好。我们观察到解码性能提高了2倍以上,预填充性能提高了5倍以上。
此外,量化模型的大小(PTE文件大小,以字节计)不到BF16模型的一半,即1.1 GiB vs 2.3 GiB。虽然int4的大小是BF16的四分之一,但模型中的某些层用int8量化,使得PTE文件大小比更大。我们观察到运行时峰值内存占用减少了近40%,从BF16模型的3.1 GiB降至SpinQuant模型的1.9 GiB,这是在最大序列长度为2048时,以驻留集大小(RSS)测量的。
通过全面的改进,新的量化Llama 3.2模型是针对Arm CPU的设备上部署的理想选择。有关精度的更多信息,请查阅Meta Llama 3.2博客。
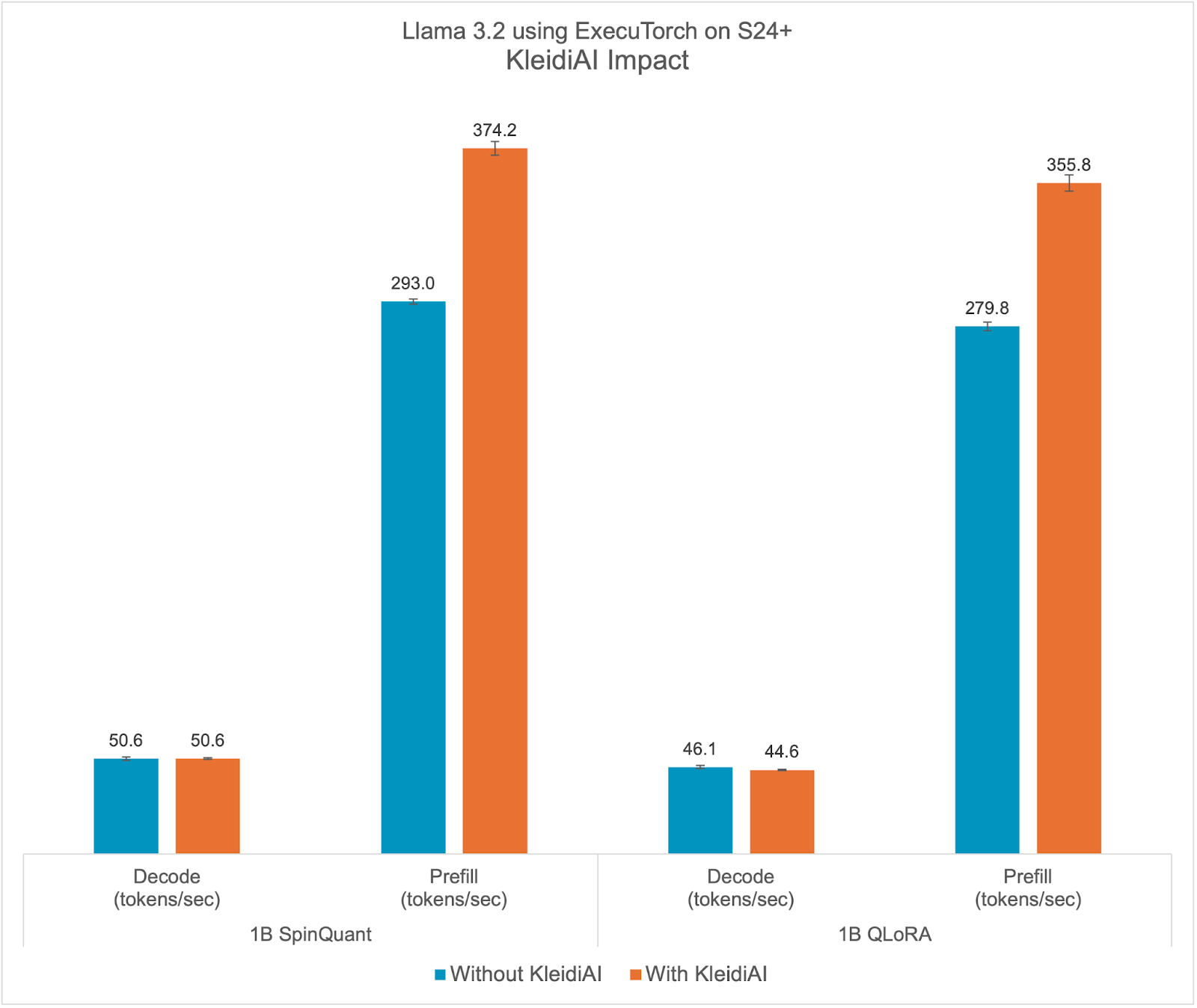
KleidiAI的影响
ExecuTorch依赖Arm KleidiAI库为具有先进Armv8/9 ISA功能的最新Arm CPU提供低位高性能矩阵乘法内核。这些内核用于ExecuTorch中设备上量化Llama 3.2模型的推理。如下图所示,与非KleidiAI内核相比,ExecuTorch在S24+上使用KleidiAI时实现了平均>20%的预填充性能提升,同时保持了相同的精度。这种性能优势不限于特定模型或设备,预计将惠及所有在Arm CPU上使用低位量化矩阵乘法的ExecuTorch模型。
为了评估Kleidi的影响,我们生成了两个针对Arm Cortex-A CPU的ExecuTorch运行时二进制文件,并比较了它们的性能。
- 第一个ExecuTorch运行时二进制文件是通过XNNPACK库与Arm KleidiAI库一起构建的。
- 第二个二进制文件是在没有Arm KleidiAI存储库的情况下构建的,使用XNNPACK库中的原生内核。
亲自尝试!
准备好亲身体验性能提升了吗?以下是您如何在项目中尝试ExecuTorch与KleidiAI提供的优化:这是一个通往学习路径的链接,您可以从Arm开始使用ExecuTorch和KleidiAI开发您自己的基于LLM的应用程序。
我们期待您的反馈!