简介
易用性、表达性和可调试性是 PyTorch 的核心原则。易用性的关键驱动因素之一是 PyTorch 默认的“即时(eager)”执行方式,即逐操作执行保留了程序的命令式特性。然而,即时执行不提供基于编译器的优化,例如当计算可以表示为图时进行的优化。
LazyTensor [1] 最早随 PyTorch/XLA 引入,它有助于结合这些看似不同的方法。虽然 PyTorch 的即时执行被广泛使用、直观且易于理解,但惰性执行尚未普及。
在这篇文章中,我们将探讨 LazyTensor 系统的一些基本概念,目标是将这些概念应用于理解和调试 PyTorch 中基于 LazyTensor 的实现的性能。尽管我们将使用 PyTorch/XLA 在 Cloud TPU 上作为探索这些概念的载体,但我们希望这些想法对于理解其他基于 LazyTensor 构建的系统也会有所帮助。
LazyTensor
对 PyTorch 张量执行的任何操作默认都会作为内核或内核组合调度到底层硬件。这些内核在底层硬件上异步执行。程序执行不会被阻塞,直到张量的值被获取。这种方法与大规模并行编程硬件(如 GPU)配合得非常好。
LazyTensor 系统的起点是一个自定义张量类型。在 PyTorch/XLA 中,这种类型被称为 XLA 张量。与 PyTorch 的原生张量类型不同,在 XLA 张量上执行的操作会被记录到一个 IR 图中。让我们看一个计算两个张量乘积之和的例子:
import torch
import torch_xla
import torch_xla.core.xla_model as xm
dev = xm.xla_device()
x1 = torch.rand((3, 3)).to(dev)
x2 = torch.rand((3, 8)).to(dev)
y1 = torch.einsum('bs,st->bt', x1, x2)
print(torch_xla._XLAC._get_xla_tensors_text([y1]))
您可以执行 此 colab 笔记本,查看 y1 的结果图。请注意,目前尚未执行任何计算。
y1 = y1 + x2
print(torch_xla._XLAC._get_xla_tensors_text([y1]))
这些操作将继续执行,直到 PyTorch/XLA 遇到一个屏障。这个屏障可以是 mark_step() API 调用,也可以是任何其他强制执行迄今为止记录的图的事件。
xm.mark_step()
print(torch_xla._XLAC._get_xla_tensors_text([y1]))
一旦调用 mark_step(),图就会被编译,然后在 TPU 上执行,即张量已经被实例化。因此,现在图被简化为一行 y1 张量,其中包含计算结果。
一次编译,多次执行
XLA 编译过程提供优化(例如操作融合,通过为多个操作使用暂存内存来减少 HBM 压力,参考),并利用底层的 XLA 基础设施来优化使用底层硬件。然而,有一个注意事项,编译过程开销很大,即可能会增加训练步长。因此,这种方法只有在我们能够 一次编译,多次执行 (编译缓存有助于确保相同的图不会被多次编译)时才能很好地扩展。
在以下示例中,我们创建一个小的计算图并计时执行:
y1 = torch.rand((3, 8)).to(dev)
def dummy_step() :
y1 = torch.einsum('bs,st->bt', y1, x)
xm.mark_step()
return y1
%timeit dummy_step
The slowest run took 29.74 times longer than the fastest. This could mean that an intermediate result is being cached.
10000000 loops, best of 5: 34.2 ns per loop
您会注意到最慢的步骤比最快的步骤要长得多。这是因为图编译开销,对于给定形状的图、输入形状和输出形状,这种开销只发生一次。后续步骤更快,因为无需图编译。
这也意味着,当“一次编译,多次执行”的假设被打破时,我们预期会看到性能陡降。理解何时打破这个假设是理解和优化 LazyTensor 系统性能的关键。让我们来看看是什么触发了编译。
图编译与执行和 LazyTensor 屏障
我们看到,当遇到 LazyTensor 屏障时,计算图会被编译和执行。有三种情况会自动或手动引入 LazyTensor 屏障。第一种是显式调用 mark_step() API,如前一个示例所示。当您使用 MpDeviceLoader 包装您的数据加载器时(强烈建议将计算和数据上传到 TPU 设备重叠),mark_step() 也会在每一步隐式调用。xla_model 的 Optimizer step 方法也允许隐式调用 mark_step(当您设置 barrier=True 时)。
引入屏障的第二种情况是当 PyTorch/XLA 发现一个没有等效 XLA HLO 操作映射(降级)的操作时。PyTorch 有 2000+ 个操作。尽管这些操作中的大多数是复合的(即可以用其他基本操作来表达),但其中一些操作在 XLA 中没有相应的降级。
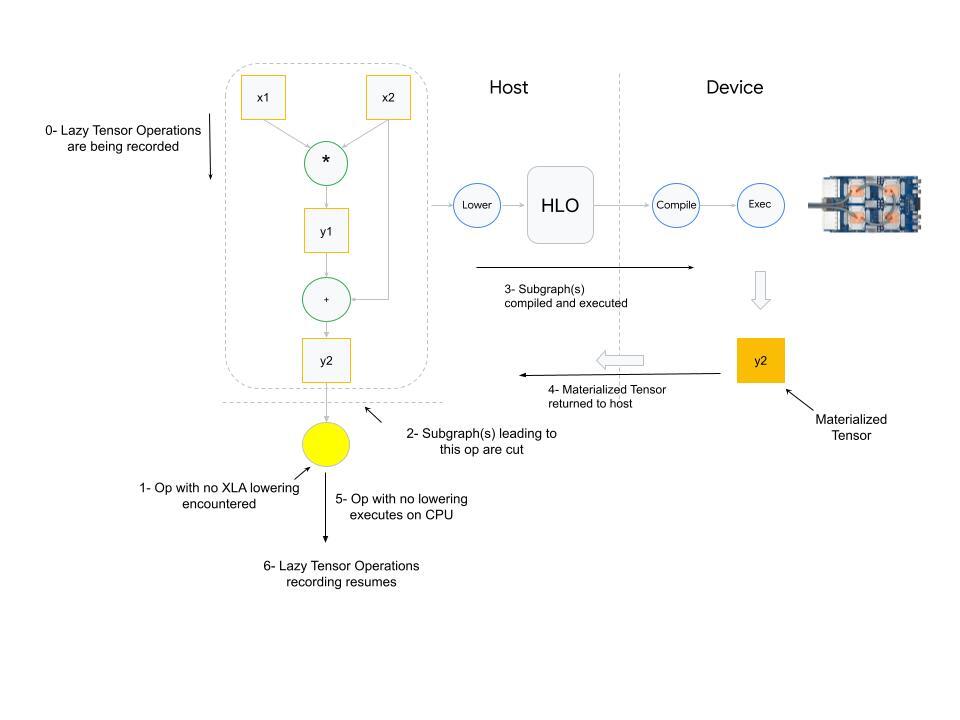
当使用了没有 XLA 降级(lowering)的操作时会发生什么?PyTorch XLA 会停止操作记录,并切断导致未降级操作输入(inputs)的图。然后,这个被切断的图会被编译并调度执行。执行结果(具体化的张量)会从设备发送回主机,然后未降级的操作会在主机(CPU)上执行,接着下游的 LazyTensor 操作会创建新的图,直到再次遇到屏障。
导致 LazyTensor 屏障的第三种也是最后一种情况是存在控制结构/语句或需要张量值的其他方法。这种语句至少会导致导致该张量的计算图的执行(如果该图已被看到),或者导致两者的编译和执行。
这类方法的其他例子包括 .item()、isEqual()。通常,任何将 Tensor 映射到 Scalar 的操作都会导致这种行为。
动态图
如前一节所示,如果相同的图形状被多次执行,图编译成本会得到分摊。这是因为编译后的图会根据图形状、输入形状和输出形状派生的哈希值进行缓存。如果这些形状发生变化,将触发重新编译,而过于频繁的编译会导致训练时间下降。
我们来看下面的例子:
def dummy_step(x, y, loss, acc=False):
z = torch.einsum('bs,st->bt', y, x)
step_loss = z.sum().view(1,)
if acc:
loss = torch.cat((loss, step_loss))
else:
loss = step_loss
xm.mark_step()
return loss
import time
def measure_time(acc=False):
exec_times = []
iter_count = 100
x = torch.rand((512, 8)).to(dev)
y = torch.rand((512, 512)).to(dev)
loss = torch.zeros(1).to(dev)
for i in range(iter_count):
tic = time.time()
loss = dummy_step(x, y, loss, acc=acc)
toc = time.time()
exec_times.append(toc - tic)
return exec_times
dyn = measure_time(acc=True) # acc= True Results in dynamic graph
st = measure_time(acc=False) # Static graph, computation shape, inputs and output shapes don't change
import matplotlib.pyplot as plt
plt.plot(st, label = 'static graph')
plt.plot(dyn, label = 'dynamic graph')
plt.legend()
plt.title('Execution time in seconds')
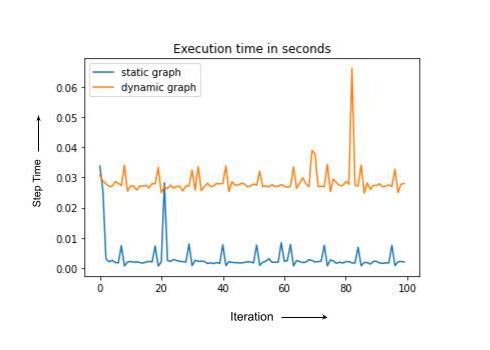
请注意,静态和动态案例具有相同的计算,但动态图每次都会编译,导致整体运行时间更长。在实践中,重新编译的训练步骤有时会慢一个数量级甚至更多。在下一节中,我们将讨论 PyTorch/XLA 的一些工具来调试训练性能下降的问题。
使用 PyTorch/XLA 分析训练性能
PyTorch/XLA 性能分析包含两个主要组件。首先是客户端性能分析。只需将环境变量 PT_XLA_DEBUG 设置为 1 即可启用此功能。客户端性能分析会指向您源代码中未降级(unlowered)的操作或设备到主机的数据传输。客户端性能分析还会报告训练期间是否发生过于频繁的编译。您可以结合性能分析器在 此 笔记本中探索 PyTorch/XLA 提供的一些指标和计数器。
PyTorch/XLA 分析器提供的第二个组件是内联跟踪注释。例如:
import torch_xla.debug.profiler as xp
def train_imagenet():
print('==> Preparing data..')
img_dim = get_model_property('img_dim')
....
server = xp.start_server(3294)
def train_loop_fn(loader, epoch):
....
model.train()
for step, (data, target) in enumerate(loader):
with xp.StepTrace('Train_Step', step_num=step):
....
if FLAGS.amp:
....
else:
with xp.Trace('build_graph'):
output = model(data)
loss = loss_fn(output, target)
loss.backward()
xm.optimizer_step(optimizer)
注意 start_server API 调用。您在此处使用的端口号将与 TensorBoard 分析器使用的端口号相同,以便查看类似于以下内容的 op 跟踪:

操作跟踪与客户端调试功能是调试和优化 PyTorch/XLA 训练性能的强大工具集。有关分析器使用的更详细说明,建议读者探索 PyTorch/XLA 性能调试系列博客的 第1部分、 第2部分和 第3部分。
总结
本文回顾了 LazyTensor 系统的基本原理。我们以 PyTorch/XLA 为基础,深入理解了训练性能下降的潜在原因。我们讨论了为什么“一次编译,多次执行”有助于在 LazyTensor 系统上获得最佳性能,以及当此假设被打破时训练速度会变慢的原因。
我们希望 PyTorch 用户会发现这些见解对他们使用 LazyTensor 系统进行的新颖工作有所帮助。
致谢
衷心感谢我的杰出同事 Jack Cao、Milad Mohammedi、Karl Weinmeister、Rajesh Thallam、Jordan Tottan(Google)和 Geeta Chauhan(Meta)的严谨评审和反馈。同时感谢来自 Google、Meta 和开源社区的 PyTorch/XLA 扩展开发团队,使得 PyTorch 在 TPU 上成为可能。最后,感谢 LazyTensor 论文的作者,他们不仅开发了 LazyTensor,还撰写了如此易懂的论文。
参考文献
[1] LazyTensor: 将即时执行与领域特定编译器结合