在使用 PyTorch 进行 GPU 编程时,您可能熟悉这个常见的错误消息
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 512.00 MiB. GPU 0 has a total capacity of 79.32 GiB of which 401.56 MiB is free.
在本系列中,我们将展示如何使用内存工具,包括内存快照 (Memory Snapshot)、内存分析器 (Memory Profiler) 和引用循环检测器 (Reference Cycle Detector) 来调试内存不足错误并改进内存使用情况。
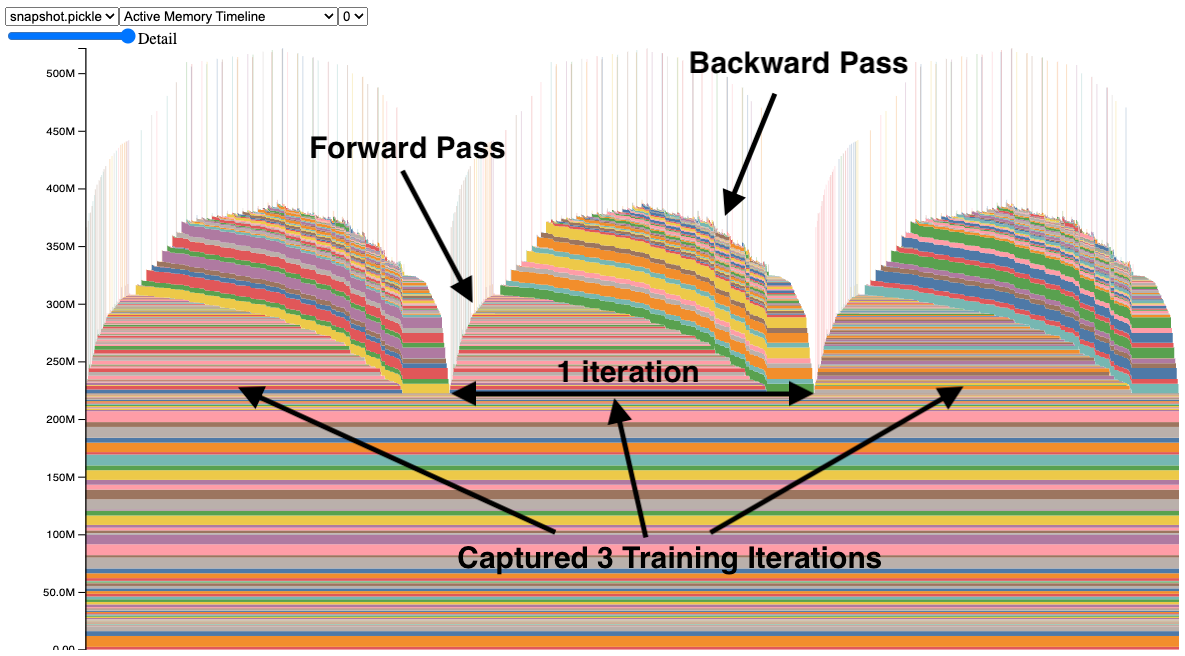
内存快照工具提供细粒度的 GPU 内存可视化,用于调试 GPU OOM(内存不足)问题。捕获的内存快照将显示内存事件,包括分配、释放和 OOM,以及它们的堆栈跟踪。
在快照中,每个张量的内存分配都用不同的颜色编码。x 轴表示时间,y 轴表示 GPU 内存量(以 MB 为单位)。快照是交互式的,因此我们可以通过鼠标悬停来观察任何分配的堆栈跟踪。您可以在 https://github.com/pytorch/pytorch.github.io/blob/site/assets/images/understanding-gpu-memory-1/snapshot.html 亲自尝试。
在此快照中,有 3 个峰值显示了 3 个训练迭代期间的内存分配(这是可配置的)。观察这些峰值时,可以很容易地看到正向传播中内存的上升以及在反向传播中梯度计算时内存的下降。还可以看到程序在每次迭代中具有相同的内存使用模式。其中一个突出之处是许多微小的内存尖峰,通过鼠标悬停在它们上面,我们发现它们是卷积操作临时使用的缓冲区。
捕获内存快照
捕获内存快照的 API 相当简单,可在 torch.cuda.memory 中找到
- 开始:
torch.cuda.memory._record_memory_history(max_entries=100000) - 保存:
torch.cuda.memory._dump_snapshot(file_name) - 停止:
torch.cuda.memory._record_memory_history(enabled=None)
代码片段(完整代码示例请参阅附录 A)
# Start recording memory snapshot history, initialized with a buffer
# capacity of 100,000 memory events, via the `max_entries` field.
torch.cuda.memory._record_memory_history(
max_entries=MAX_NUM_OF_MEM_EVENTS_PER_SNAPSHOT
)
# Run your PyTorch Model.
# At any point in time, save a snapshot to file for later.
for _ in range(5):
pred = model(inputs)
loss_fn(pred, labels).backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
# In this sample, we save the snapshot after running 5 iterations.
# - Save as many snapshots as you'd like.
# - Snapshots will save last `max_entries` number of memory events
# (100,000 in this example).
try:
torch.cuda.memory._dump_snapshot(f"{file_prefix}.pickle")
except Exception as e:
logger.error(f"Failed to capture memory snapshot {e}")
# Stop recording memory snapshot history.
torch.cuda.memory._record_memory_history(enabled=None)
为了可视化快照文件,我们提供了一个工具,托管在 https://pytorch.ac.cn/memory_viz。在那里,您可以拖放保存的快照文件,它将随时间绘制每个分配。隐私注意事项:该工具不会保存您的快照。

或者,您可以使用 pytorch/torch/cuda/_memory_viz.py 中的脚本从 .pickle 文件生成 HTML,示例如下:
python torch/cuda/_memory_viz.py trace_plot snapshot.pickle -o snapshot.html
调试 CUDA OOM
让我们看看如何使用内存快照工具来回答以下问题:
- 为什么会发生 CUDA OOM?
- GPU 内存用在哪里?
带有 bug 的 ResNet50
我们在第一个快照中查看了一个正常工作的模型。现在,让我们看看一个带有 bug 的训练示例,请参见快照。
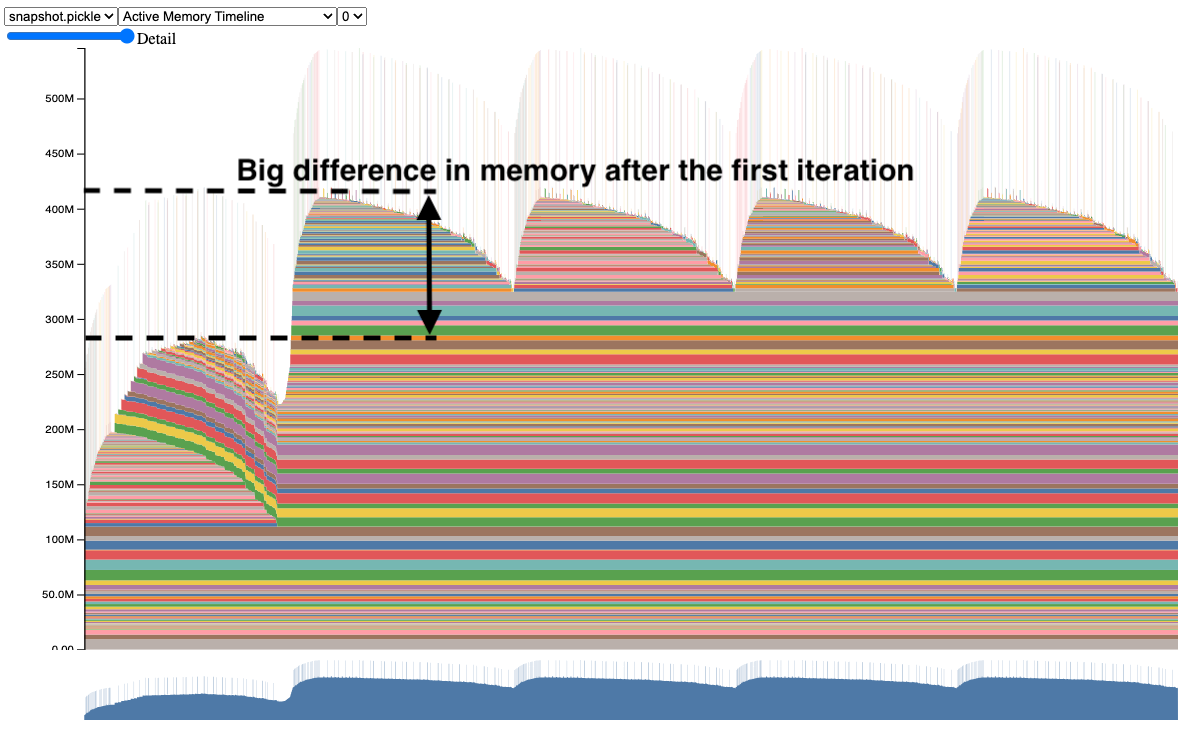
注意第二次迭代使用的内存比第一次迭代多得多。如果这个模型更大,它可能会在第二次迭代中发生 CUDA OOM,而没有太多其他信息来解释原因。
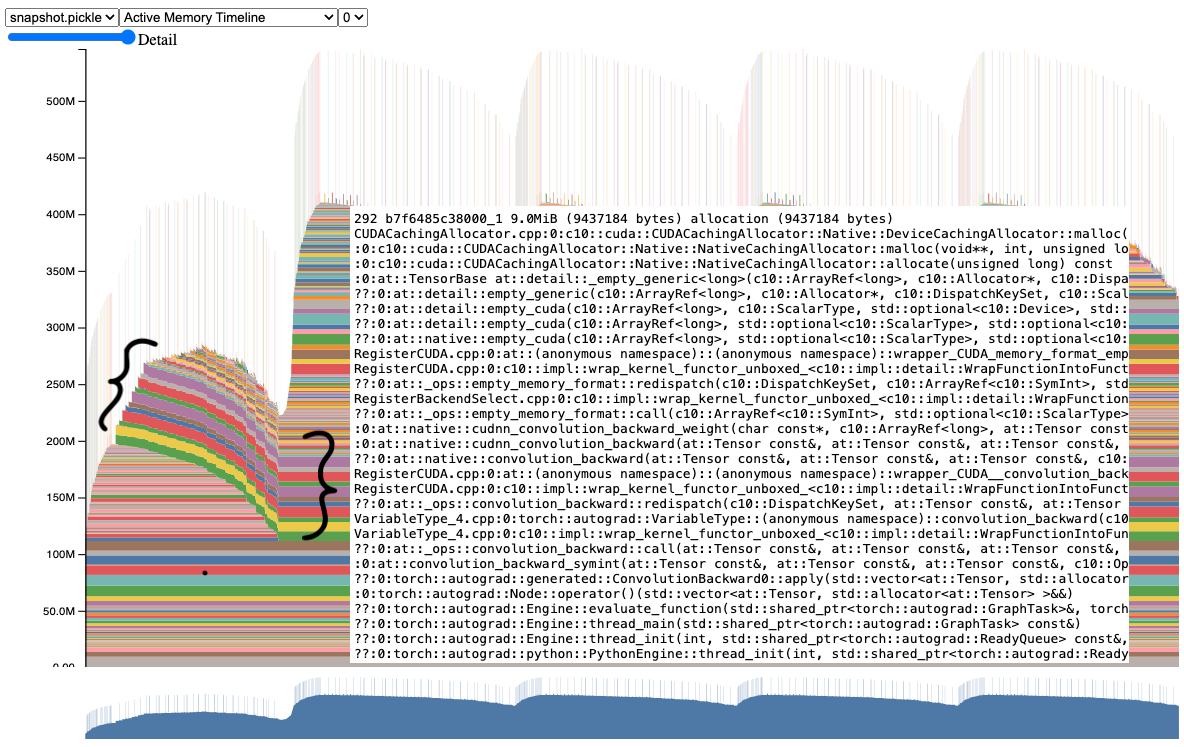
进一步检查此快照时,我们可以清楚地看到,从第一次迭代到第二次以及后续迭代,有几个张量仍然存在。如果我们将鼠标悬停在其中一个张量上,它将显示一个堆栈跟踪,表明这些是梯度张量。
确实,如果我们查看代码,可以看到它没有清除梯度张量,而它本可以在正向传播之前清除它们。
之前
for _ in range(num_iters):
pred = model(inputs)
loss_fn(pred, labels).backward()
optimizer.step()
之后
for _ in range(num_iters):
pred = model(inputs)
loss_fn(pred, labels).backward()
optimizer.step()
# Add this line to clear grad tensors
optimizer.zero_grad(set_to_none=True)
我们可以简单地添加一个 `optimizer.zero_grad(set_to_none=True)` 指令来清除每次迭代之间的梯度张量(关于为什么需要将梯度归零的更多详细信息,请参见此处:https://pytorch.ac.cn/tutorials/recipes/recipes/zeroing_out_gradients.html)。
这是我们使用此工具在更复杂的程序中发现的一个 bug 的简化。我们鼓励您在您的 GPU 内存问题上尝试使用内存快照,并告诉我们结果如何。
ResNet50 修复 bug 后
应用修复后,快照似乎正在清除梯度了。
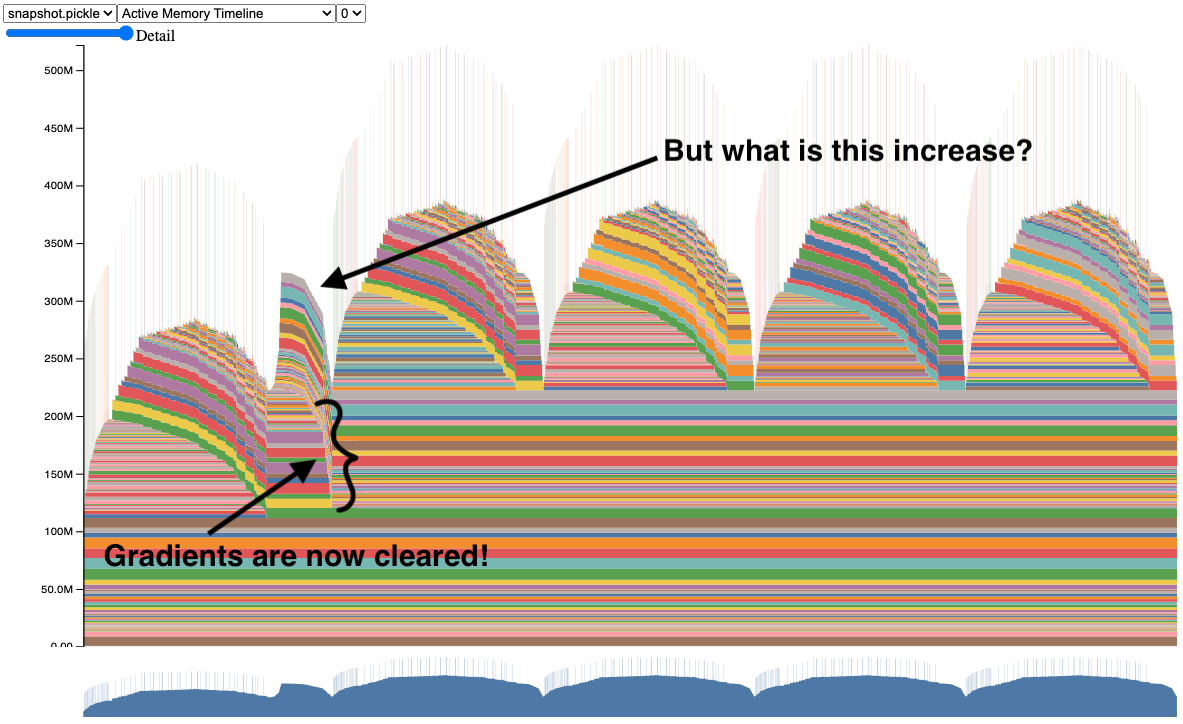
我们现在有一个正常工作的 ResNet50 模型的快照。请亲自尝试代码(请参阅附录 A 中的代码示例)。
但您可能想知道,为什么在第一次迭代之后内存仍然会增加?为了回答这个问题,让我们在下一节中探讨内存分析器。
分类内存使用情况
内存分析器是 PyTorch 分析器的一个附加功能,它能分类随时间变化的内存使用情况。我们仍然依赖内存快照来获取堆栈跟踪,以便深入研究内存分配。
为了生成内存时间线,这里有一个代码片段(完整代码示例请参见附录 B)
# Initialize the profiler context with record_shapes, profile_memory,
# and with_stack set to True.
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
],
schedule=torch.profiler.schedule(wait=0, warmup=0, active=6, repeat=1),
record_shapes=True,
profile_memory=True,
with_stack=True,
on_trace_ready=trace_handler,
) as prof:
# Run the PyTorch Model inside the profile context.
for _ in range(5):
prof.step()
with record_function("## forward ##"):
pred = model(inputs)
with record_function("## backward ##"):
loss_fn(pred, labels).backward()
with record_function("## optimizer ##"):
optimizer.step()
optimizer.zero_grad(set_to_none=True)
# Construct the memory timeline HTML plot.
prof.export_memory_timeline(f"{file_prefix}.html", device="cuda:0")
欲了解更多信息,请参阅 https://pytorch.ac.cn/docs/main/profiler.html。
内存分析器会根据分析期间记录的张量操作图自动生成类别。
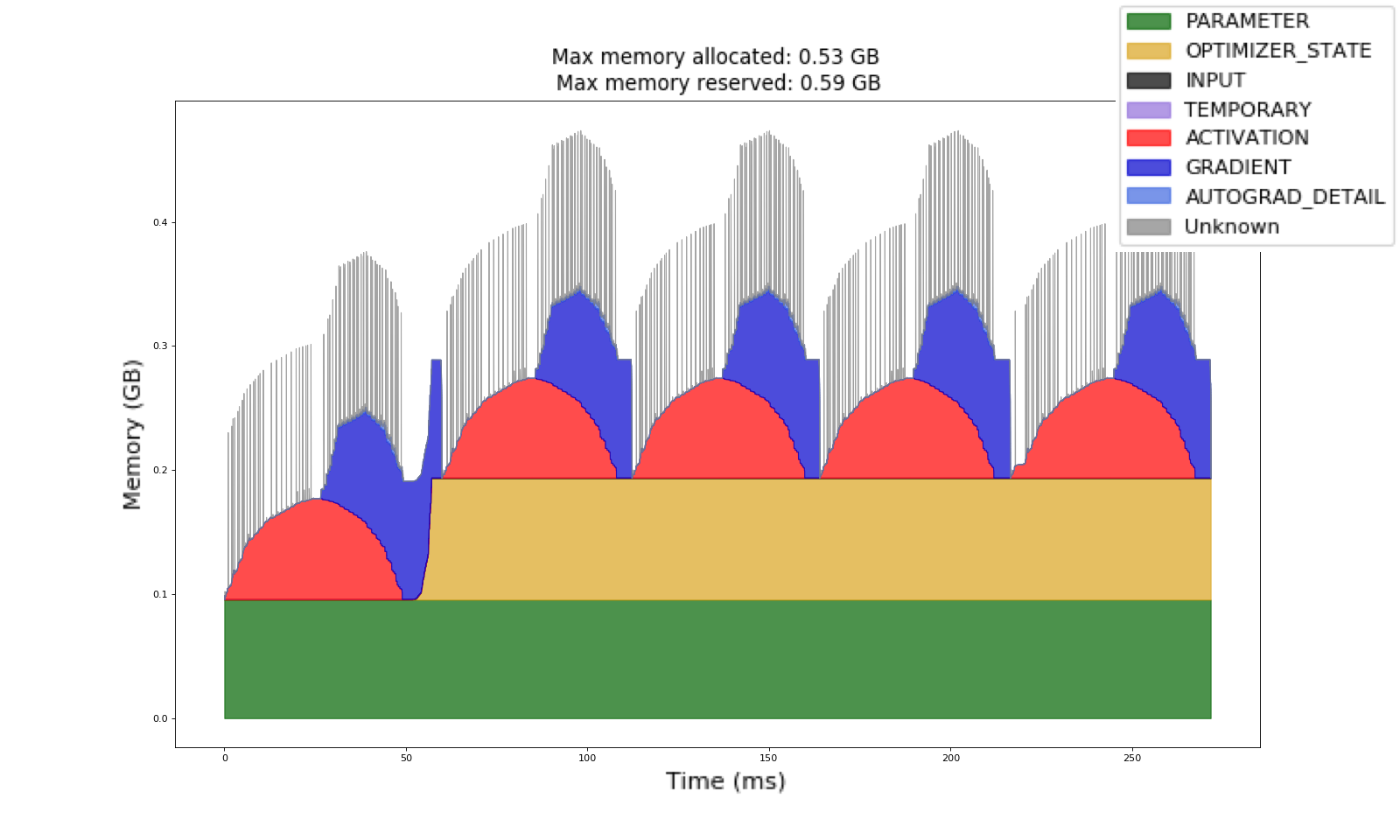
在此使用内存分析器收集的内存时间线中,我们有与之前相同的训练示例。我们可以观察到蓝色表示的梯度现在在每次迭代后都被清除了。我们还可以注意到,黄色表示的优化器状态在第一次迭代后被分配,并在接下来的工作中保持不变。
这种优化器状态是导致 GPU 内存从第一次迭代到第二次增加的原因。您可以自己尝试代码(请参阅附录 B 中的代码示例)。内存分析器有助于提高训练的内存理解,以便模型作者可以找出哪些类别正在使用最多的 GPU 内存。
我在哪里可以找到这些工具?
我们希望这些工具能大大提高您调试 CUDA OOMs 并按类别理解内存使用情况的能力。
内存快照和内存分析器作为实验性功能已在 PyTorch v2.1 版本中提供。
- 有关内存快照的更多信息,请参见此处 PyTorch 内存文档。
- 有关内存分析器的更多详细信息,请参见此处 PyTorch 分析器文档。
反馈
我们期待听到您关于我们的工具帮助解决了哪些增强功能、错误或内存故事的反馈!一如既往,请随时在 PyTorch 的 Github 页面上开新问题。
我们也欢迎开源社区的贡献,欢迎在任何 Github PR 中 @Aaron Shi 和 Zachary DeVito 进行代码审查。
致谢
非常感谢内容审阅者 Mark Saroufim 和 Gregory Chanan 审阅此帖子并提高其可读性。
非常感谢 Adnan Aziz 和 Lei Tian 的代码审查和反馈。
附录
附录 A – ResNet50 内存快照代码示例
# (c) Meta Platforms, Inc. and affiliates.
import logging
import socket
from datetime import datetime, timedelta
import torch
from torchvision import models
logging.basicConfig(
format="%(levelname)s:%(asctime)s %(message)s",
level=logging.INFO,
datefmt="%Y-%m-%d %H:%M:%S",
)
logger: logging.Logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
TIME_FORMAT_STR: str = "%b_%d_%H_%M_%S"
# Keep a max of 100,000 alloc/free events in the recorded history
# leading up to the snapshot.
MAX_NUM_OF_MEM_EVENTS_PER_SNAPSHOT: int = 100000
def start_record_memory_history() -> None:
if not torch.cuda.is_available():
logger.info("CUDA unavailable. Not recording memory history")
return
logger.info("Starting snapshot record_memory_history")
torch.cuda.memory._record_memory_history(
max_entries=MAX_NUM_OF_MEM_EVENTS_PER_SNAPSHOT
)
def stop_record_memory_history() -> None:
if not torch.cuda.is_available():
logger.info("CUDA unavailable. Not recording memory history")
return
logger.info("Stopping snapshot record_memory_history")
torch.cuda.memory._record_memory_history(enabled=None)
def export_memory_snapshot() -> None:
if not torch.cuda.is_available():
logger.info("CUDA unavailable. Not exporting memory snapshot")
return
# Prefix for file names.
host_name = socket.gethostname()
timestamp = datetime.now().strftime(TIME_FORMAT_STR)
file_prefix = f"{host_name}_{timestamp}"
try:
logger.info(f"Saving snapshot to local file: {file_prefix}.pickle")
torch.cuda.memory._dump_snapshot(f"{file_prefix}.pickle")
except Exception as e:
logger.error(f"Failed to capture memory snapshot {e}")
return
# Simple Resnet50 example to demonstrate how to capture memory visuals.
def run_resnet50(num_iters=5, device="cuda:0"):
model = models.resnet50().to(device=device)
inputs = torch.randn(1, 3, 224, 224, device=device)
labels = torch.rand_like(model(inputs))
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9)
loss_fn = torch.nn.CrossEntropyLoss()
# Start recording memory snapshot history
start_record_memory_history()
for _ in range(num_iters):
pred = model(inputs)
loss_fn(pred, labels).backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
# Create the memory snapshot file
export_memory_snapshot()
# Stop recording memory snapshot history
stop_record_memory_history()
if __name__ == "__main__":
# Run the resnet50 model
run_resnet50()
附录 B – ResNet50 内存分析器代码示例
# (c) Meta Platforms, Inc. and affiliates.
import logging
import socket
from datetime import datetime, timedelta
import torch
from torch.autograd.profiler import record_function
from torchvision import models
logging.basicConfig(
format="%(levelname)s:%(asctime)s %(message)s",
level=logging.INFO,
datefmt="%Y-%m-%d %H:%M:%S",
)
logger: logging.Logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
TIME_FORMAT_STR: str = "%b_%d_%H_%M_%S"
def trace_handler(prof: torch.profiler.profile):
# Prefix for file names.
host_name = socket.gethostname()
timestamp = datetime.now().strftime(TIME_FORMAT_STR)
file_prefix = f"{host_name}_{timestamp}"
# Construct the trace file.
prof.export_chrome_trace(f"{file_prefix}.json.gz")
# Construct the memory timeline file.
prof.export_memory_timeline(f"{file_prefix}.html", device="cuda:0")
def run_resnet50(num_iters=5, device="cuda:0"):
model = models.resnet50().to(device=device)
inputs = torch.randn(1, 3, 224, 224, device=device)
labels = torch.rand_like(model(inputs))
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9)
loss_fn = torch.nn.CrossEntropyLoss()
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
],
schedule=torch.profiler.schedule(wait=0, warmup=0, active=6, repeat=1),
record_shapes=True,
profile_memory=True,
with_stack=True,
on_trace_ready=trace_handler,
) as prof:
for _ in range(num_iters):
prof.step()
with record_function("## forward ##"):
pred = model(inputs)
with record_function("## backward ##"):
loss_fn(pred, labels).backward()
with record_function("## optimizer ##"):
optimizer.step()
optimizer.zero_grad(set_to_none=True)
if __name__ == "__main__":
# Warm up
run_resnet50()
# Run the resnet50 model
run_resnet50()