IBM:Tuan Hoang Trong、Alexei Karve、Yan Koyfman、Linsong Chu、Divya Kumari、Shweta Salaria、Robert Walkup、Praneet Adusumilli、Nirmit Desai、Raghu Ganti、Seetharami Seelam
Meta:Less Wright、Wei Feng、Vasiliy Kuznetsov、Driss Guesseous
在这篇博客中,我们将展示如何通过利用 FSDP2、DTensor 和带 torchao float8 的 torch.compile(通过线性层更新(计算)和 float8 all_gathers 进行权重通信),在训练中实现高达 50% 的吞吐量加速,同时在损失和评估基准方面与 FSDP1 bf16 训练持平。我们在各种 Meta LLaMa 模型架构尺寸上展示了这些改进,从小型 1.8B 模型到 405B 模型,使训练比以往任何时候都更快。
我们使用 Meta Llama3 架构演示了这些改进,然后在两个规模上进行了模型质量研究:8B 模型规模下 100B 词元,以及 70B 模型规模下 50B 词元,这提供了 float8 和 bf16 训练损失曲线的精确比较。我们证明,与 bf16 对应的模型训练运行相比,这些损失曲线导致了相同的损失收敛。此外,我们使用 FineWeb-edu 数据集将一个 3B 模型训练到 1T 词元,并运行标准评估基准,以确保模型质量完好无损,并与 bf16 运行相当。
在 IBM Research,我们计划采用这些功能进行数据消融,以在给定的 GPU 预算内增加我们可以执行的实验数量。从长远来看,我们将进行更大规模的模型运行,以演示 float8 训练的端到端可行性。
什么是 Float8?
用于训练模型的 float8 格式由 NVIDIA、ARM 和 Intel 在 2022 年的一篇论文中引入,该论文证明了使用更低精度的 float8 训练的可行性,而不会牺牲模型质量。随着 NVIDIA Hopper 系列等新型 GPU 的引入,FP8 训练变得可行,由于原生 float8 Tensor Core 支持,训练吞吐量有可能提高 2 倍以上。实现这一承诺存在一些挑战:
(i) 在 float8 中启用核心模型操作,如 matmul 和 attention,
(ii) 在分布式框架中启用 float8 训练,以及
(iii) 在 float8 中启用 GPU 之间的权重通信。
虽然 float8 matmul 已由 NVIDIA 库启用,但后两者已在 FSDP2 和 torchao 的最新更新中提供。
在这篇博客中,我们使用 torchtitan 作为训练的入口点,IBM 的确定性数据加载器,来自 torchao 的 float8 线性层实现,以及与 FSDP2 结合的最新 PyTorch nightly 版本中的 float8 all gather。对于此次训练,我们使用 float8 逐张量(tensorwise)缩放粒度,而不是逐行。我们利用 torch.compile 来确保获得最大的性能增益。我们正在使用 SDPA 以 bf16 格式计算 attention,目前也正在努力将其转换为 float8。
实验
我们进行了各种实验来证明 float8 训练的优势。首先是为了确保模型质量不被牺牲。为了验证这一点,我们训练了一个 8B 模型和一个 70B 模型几千步,并比较了 float8 和 bf16 训练运行之间的损失曲线。我们的实验在三个不同的 H100 集群上进行,分别配置了 128、256 和 512 个 H100 GPU,在非常不同的环境中进行,以证明其可复现性。第一个集群是在 Meta 的 Grand Teton 上定制的,采用 400Gbps 定制互连;第二个是 IBM 研究集群,采用 3.2Tbps InfiniBand 互连;第三个是 IBM Cloud 集群,采用 3.2Tbps RoCE 互连用于 GPU 间通信。
首先,我们绘制了这两个模型在下面图表中的损失曲线比较,以演示几千步的损失持平。
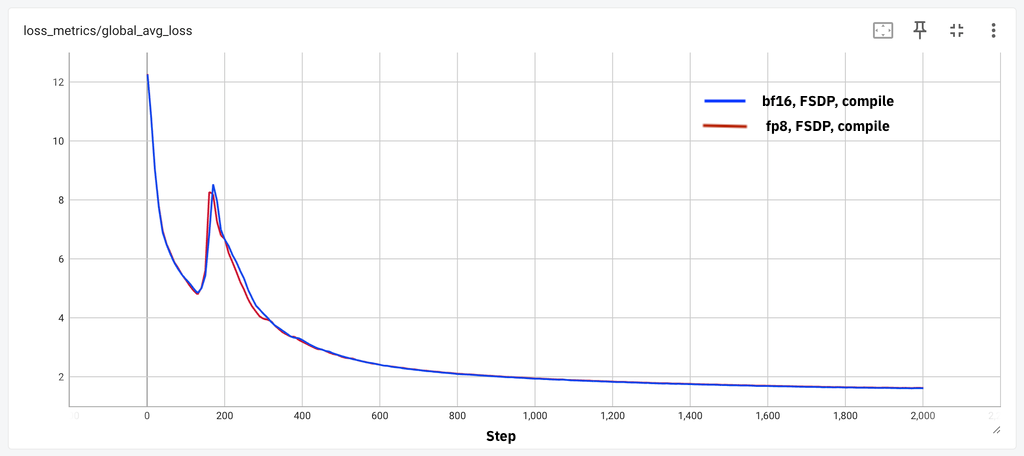
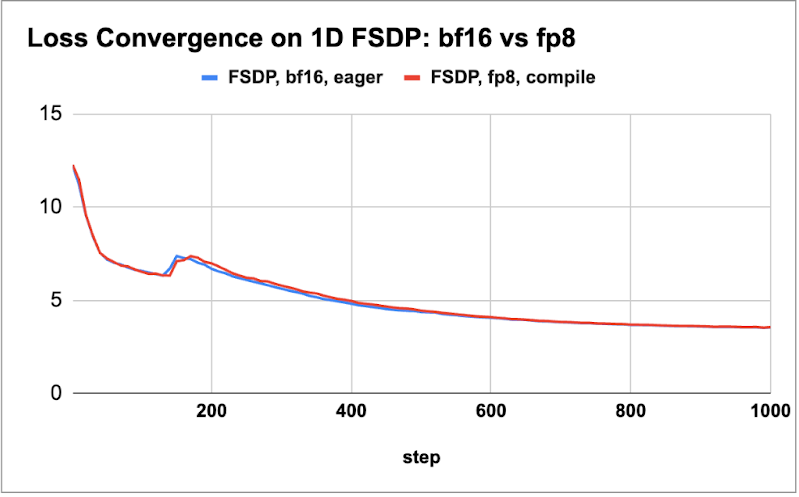
图 1:(a) 8B 模型 2k 步损失持平,(b) 70B 模型 1k 步损失持平
我们观察到,在这些不同的模型和不同环境中,我们获得了小规模词元的损失持平。接下来,我们描述了从 1.8B 到 405B 四种不同模型尺寸的吞吐量增益。我们探索了 float8 和 bf16 训练运行的最佳批量大小和激活检查点方案,以确定 tokens/sec/GPU (wps) 指标并报告性能增益。对于 405B 模型,我们利用 DTensor 进行 FSDP2 的张量并行训练。我们所有测量都使用 8K 的序列长度。
| 模型大小 | wps (bf16) | wps (float8) | 增益百分比 |
| 1.8B | 29K | 35K | 18% |
| 8K | 8K | 10K | 28% |
| 70B | 956 | 1430 | 50% |
| 405B (TP4) | 149 | 227 | 52% |
表 1:相对于 bf16 的性能增益(bf16 和 float8 都使用 torch.compile)
我们从表 1 中观察到,较大模型(70B 和 405B)的增益高达 50%,而较小模型的增益在 20% 到 30% 之间。在进一步的实验中,我们观察到 float8 all_gather 的添加在 float8 计算本身之外还能带来约 5% 的提升,这与 这篇博客中的观察结果一致。
其次,为了证明 FP8 模型的有效性,我们使用 Hugging Face 的 FineWeb-edu 数据集,按照 Llama3 架构训练了一个 3B 模型,共 1T 词元。我们使用 lm-eval-harness 框架进行了评估,并在下表中展示了这些结果的一小部分。我们观察到 bf16 的性能略优于 float8 的分数(大约百分之一)。虽然某些分数在 bf16 下明显更好(例如,MMLU 高出 3 分),但我们预计在选择正确的超参数和更大规模的训练运行中,这些差距会消失(例如,bf16 运行的批量大小减半,众所周知,较小的批量大小运行可以提高评估分数)。
| 基准 | 分数 (float8) | 分数 (bf16) |
| MMLU (5-shot) | 0.26 | 0.29 |
| ARC-e | 0.73 | 0.73 |
| ARC-c | 0.43 | 0.46 |
| Hellaswag | 0.65 | 0.67 |
| sciq | 0.89 | 0.88 |
| OpenBook QA | 0.43 | 0.43 |
| PIQA | 0.76 | 0.76 |
| Winogrande | 0.60 | 0.65 |
| 平均 | 0.59 | 0.60 |
表 2:在 FP16 中进行评估的 float8 训练模型(在 1T 词元的 FineWeb 预训练后)的基准分数。
最后,我们将实验规模扩大到 IBM Cloud 集群上的 512 个 H100 GPU。即使在 512 GPU 规模下,我们也能够重现我们观察到的结果和加速。我们仅在下表中总结了大型模型(70B 和 405B)的这些结果。
| 模型大小 | wps (bf16) | wps (float8) | 增益百分比 |
| 70B | 960 | 1448 | 51% |
| 405B (TP4) | 152 | 217 | 43% |
表 3:在 512 GPU 规模下相对于 bf16 的性能增益(bf16 和 float8 都使用 torch.compile)
未来工作
我们还在评估其他形式的并行性,例如上下文并行性。我们计划评估所有这些功能,以展示大规模模型训练的可组合性和选择能力。
致谢
我们感谢 IBM Research 的 Davis Wertheimer 启用了 torchtitan 运行的数据加载器,使我们能够在多次运行中以相同的顺序重放数据。我们还要感谢 IBM Cloud 为我们提供了 H100 集群的早期测试访问。