1. 简介
PyTorch 2.0(简称 PT2)可以使用名为 torch.compile 的编译器显著提高 AI 模型的训练和推理性能,同时与 PyTorch 1.x 100% 向后兼容。已有报告指出 PT2 如何改善常见 基准(例如,HuggingFace 的 diffusers)的性能。在本博客中,我们将讨论我们在 Meta 将 PT2 应用于 生产级 AI 模型的经验。
2. 背景
2.1 为什么自动性能优化对生产至关重要?
性能对于生产尤其重要——例如,即使是重度使用模型的训练时间减少 5%,也能为 GPU 成本和数据中心 功耗 带来可观的节省。另一个重要指标是 开发效率,它衡量将模型投入生产所需的工程师月数。通常,这项投入生产的工作中有很大一部分用于 手动 性能调优,例如重写 GPU 内核以提高训练速度。通过提供 自动 性能优化,PT2 可以同时提高 成本 和开发效率。
2.2 PT2 如何提高性能
作为编译器,PT2 可以查看从模型捕获的训练图中的 多个 操作(与 PT1.x 不同,PT1.x 一次只执行一个操作)。因此,PT2 可以利用多种性能优化机会,包括:
- 将多个操作融合到一个 GPU 内核中
- 运行 GPU 程序时典型的性能开销类型是启动小型 GPU 内核的 CPU 开销。通过将多个操作融合到一个 GPU 内核中,PT2 可以显著减少 CPU 上内核启动的开销。例如,考虑图 1(a) 中的 PyTorch 程序。当它在 PT1 下在 GPU 上执行时,它有三个 GPU 内核(两个用于两个 sin() 操作,一个用于加法操作)。使用 PT2,只生成一个内核,它将所有三个操作融合在一起。
- 融合一些操作后,图中的某些操作可能会变得无用,因此可以被优化掉。这可以节省 GPU 上的计算和内存带宽。例如,在图 1(b) 中,其中一个重复的 sin() 操作可以被优化掉。
- 此外,融合还可以减少 GPU 设备内存读写(通过组合逐点内核)并有助于提高硬件利用率。

图 1:PT2 如何通过融合和死代码消除来提高性能。
- 减少使用低精度数据类型的类型转换开销
- PyTorch 1.x 支持自动混合精度 (AMP)。虽然 AMP 可以减少操作的计算时间,但它在操作之前和之后引入了类型转换开销。PT2 可以通过优化掉不必要的类型转换代码来提高 AMP 性能,从而显著减少其开销。例如,图 2(a) 在进行矩阵乘法之前将三个 32 位输入张量 (a32, b32, c32) 转换为 bf16。然而,在这个例子中,a32 和 c32 实际上是同一个张量 (a_float32)。因此,不需要将 a_float32 转换两次,如 torch.compile 在图 2(b) 中生成的代码所示。请注意,虽然此示例和上一个示例都优化掉了冗余计算,但它们的不同之处在于此示例中的类型转换代码是通过 torch.autocast 隐式 进行的,而上一个示例中的 torch.sin(x).cuda() 在用户代码中是 显式 的。

图 2:PT2 如何在使用 AMP 时减少类型转换开销。
- 在 GPU 上重用缓冲区
- 借助全局视图,torch.compile 中的调度器可以在 GPU 上重用缓冲区,从而减少内存分配时间和内存消耗。图 3 显示了调用图 2(a) 程序生成的 Triton 内核的驱动程序。我们可以看到 `buf1` 被重用为 `buf4`。

图 3:缓冲区的重用。
- 自动调优
- PT2 有选项可以对矩阵乘法操作、逐点操作和归约操作启用自动调优(通过 Triton)。可调参数包括块大小、阶段数和 warp 数。通过自动调优,可以通过经验找到操作性能最佳的实现。
3. 生产环境考量
在本节中,我们将描述将 PT2 应用于生产环境的一些重要考量。
3.1 确保 torch.compile 不会导致模型质量下降
将 torch.compile 应用于模型会导致数值变化,原因在于 (1) 浮点运算在各种优化(如融合)期间的重新排序,以及 (2) 如果启用了 AMP,则使用 bf16 等较低精度数据类型。因此,不期望与 PT 1.x 实现 100% 的位级兼容性。尽管如此,我们仍然需要确保在应用 torch.compile 后模型质量(以某种数值分数衡量)得以保留。通常,每个生产模型都会有自己的可接受分数范围(例如,百分比变化必须在 0.01% 以内)。
如果 torch.compile 导致模型质量下降,我们需要进行深入调试。
调试与 torch.compile 相关的数值问题的一个有用技术是使用不同的后端应用 torch.compile,特别是“eager”和“aot_eager”,以及“inductor”。
- 如果数值问题发生在“eager”后端,则 torch.compile 构建的前向图可能不正确;
- 如果数值问题不发生在“eager”后端,但发生在“aot_eager”后端,则 torch.compile 构建的后向图可能不正确;
- 如果数值问题不发生在“eager”或“aot_eager”后端,但发生在“inductor”后端,则 inductor 内部的代码生成可能不正确。
3.2 生产环境中的自动调优
默认情况下,torch.inductor 中的自动调优是在模型执行时 在线 完成的。对于某些生产模型,我们发现自动调优时间可能需要数小时,这对于生产环境来说是不可接受的。因此,我们添加了 离线自动调优,其工作方式如图 4 所示。模型第一次运行时,所有需要调优的操作的详细信息(例如,输入张量形状、数据类型等)将被记录到数据库中。然后,这些操作的调优过程在夜间运行,以搜索每个操作性能最佳的实现;搜索结果会更新到持久缓存中(实现为 torch.inductor 的源文件)。下次模型再次运行时,每个操作的调优实现将在缓存中找到并选择执行。
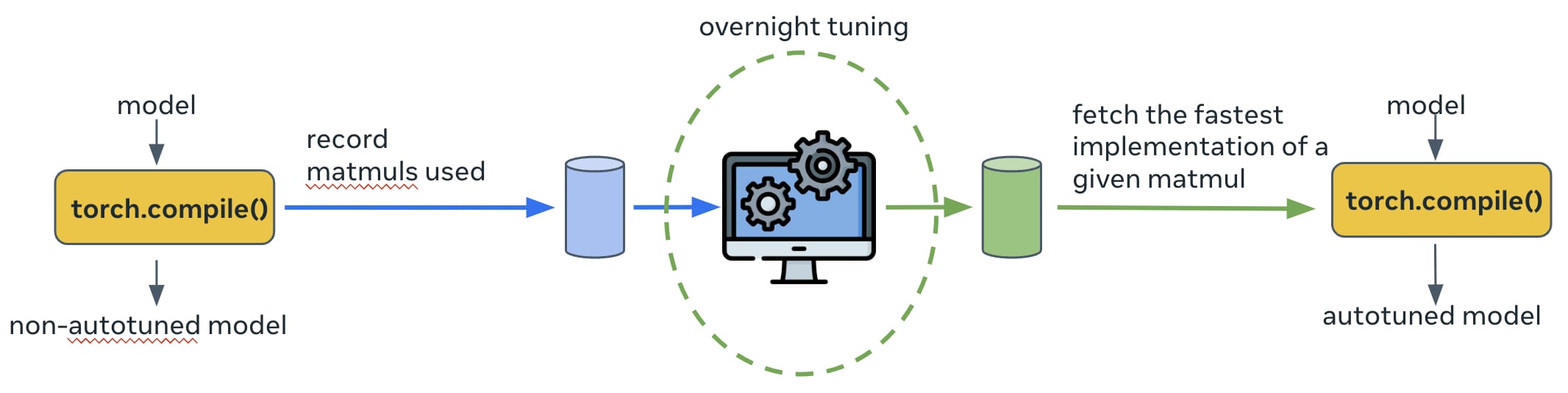
图 4:生产环境中使用的离线自动调优。
3.3 torch.compile 的性能分析支持
正如我们之前在这篇博客中讨论的,性能分析器对于调试生产模型的性能至关重要。我们已经增强了性能分析器,以便在时间轴上显示与 torch.compile 相关的事件。最有用的是标记模型中哪些部分正在运行编译代码,这样我们就可以快速验证模型中应该编译的部分是否真的被 torch.compile 编译了。例如,图 5 中的跟踪有两个编译区域(带有“CompiledFunction”标签)。其他有用的事件是编译所花费的时间以及访问编译器代码缓存所花费的时间。
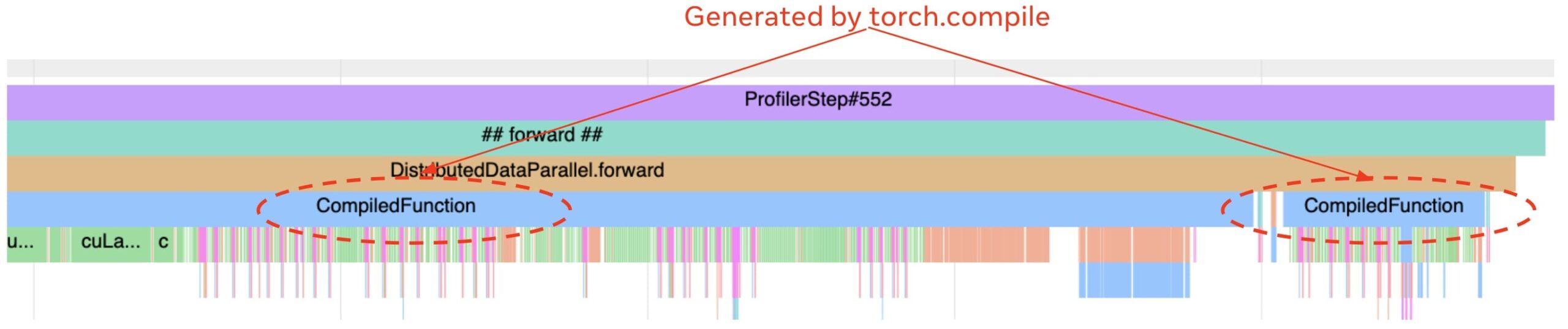
图 5:一个包含两个编译区域的跟踪。
3.4 控制即时编译时间
torch.compile 使用即时编译。编译发生在训练第一批数据时。在我们的生产环境中,对训练作业达到第一批数据所需的时间有一个上限,即 首次批处理时间 (TTFB)。我们需要确保启用 torch.compile 不会使 TTFB 超过限制。这可能具有挑战性,因为生产模型很大,并且 torch.compile 可能需要大量的编译时间。我们启用了 并行编译 以控制编译时间(这由 `torch/_inductor/config.py` 中的全局变量 `compile_threads` 控制,在 OSS Linux 上已设置为 CPU 数量)。模型被分解为一个或多个计算图;每个图被分解为多个 Triton 内核。如果启用并行编译,同一图中的所有 Triton 内核可以同时编译(然而,来自不同图的内核仍然串行编译)。图 6 说明了并行编译如何提供帮助。
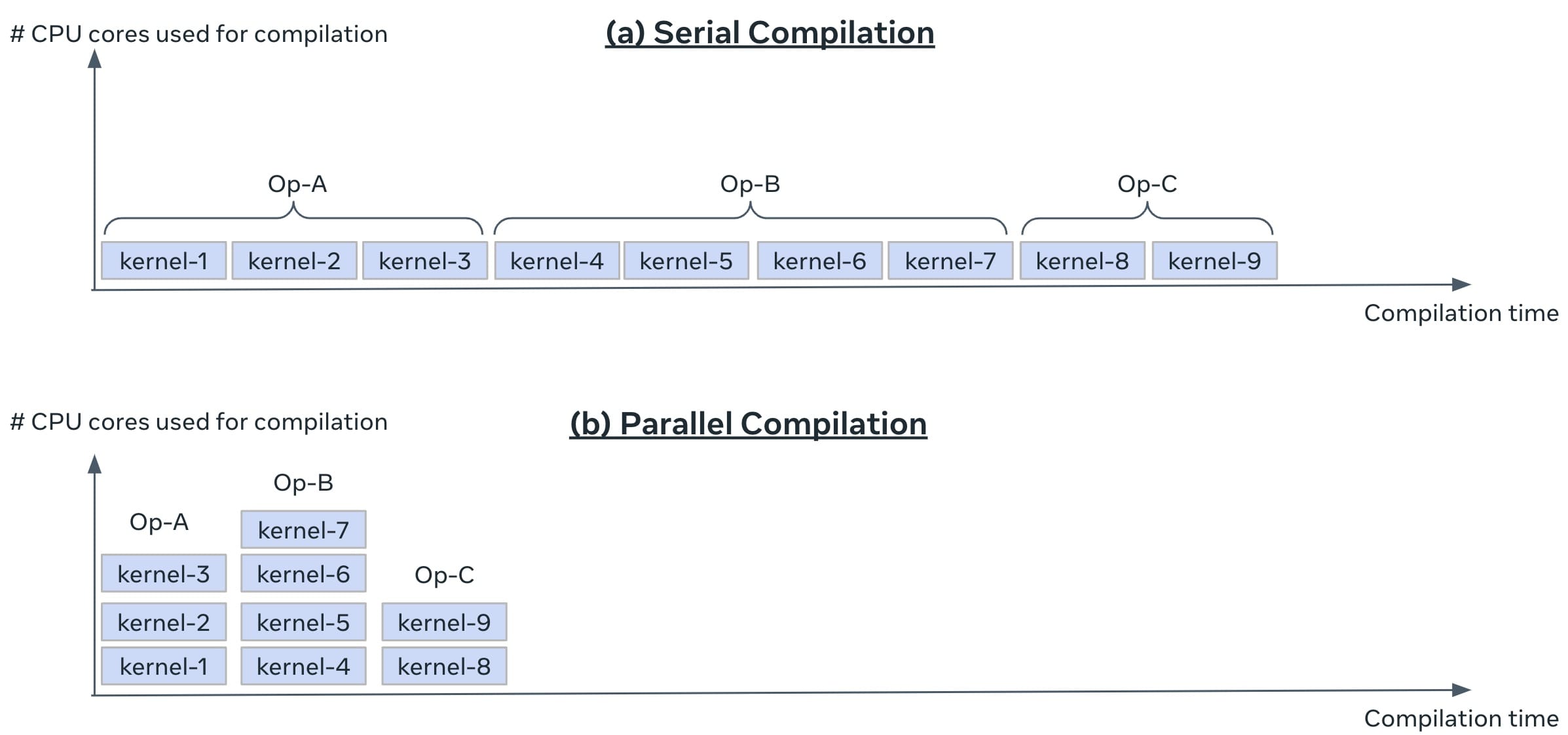
图 6:在生产中使用并行编译。
4. 结果
在本节中,我们使用三个生产模型来评估 PT2。首先,我们展示了使用不同优化配置的 PT2 训练时间加速。其次,我们展示了并行编译对编译时间的重要性。
4.1 使用 torch.compile 进行训练时间加速
图 7 报告了使用 PT2 的训练时间加速。对于每个模型,我们展示了四种情况:(i) 不编译且使用 bf16,(ii) 编译且使用 fp32,(iii) 编译且使用 bf16,(iv) 编译且使用 bf16 和自动调优。y 轴是相对于基线(不编译且使用 fp32)的加速比。请注意,由于类型转换开销,不编译且使用 bf16 实际上比不编译且使用 fp32 慢。相比之下,编译且使用 bf16 通过大大减少此开销实现了更大的加速。总的来说,考虑到这些模型已经经过大量手动优化,我们很高兴看到 torch.compile 仍然可以提供 1.14-1.24 倍的加速。
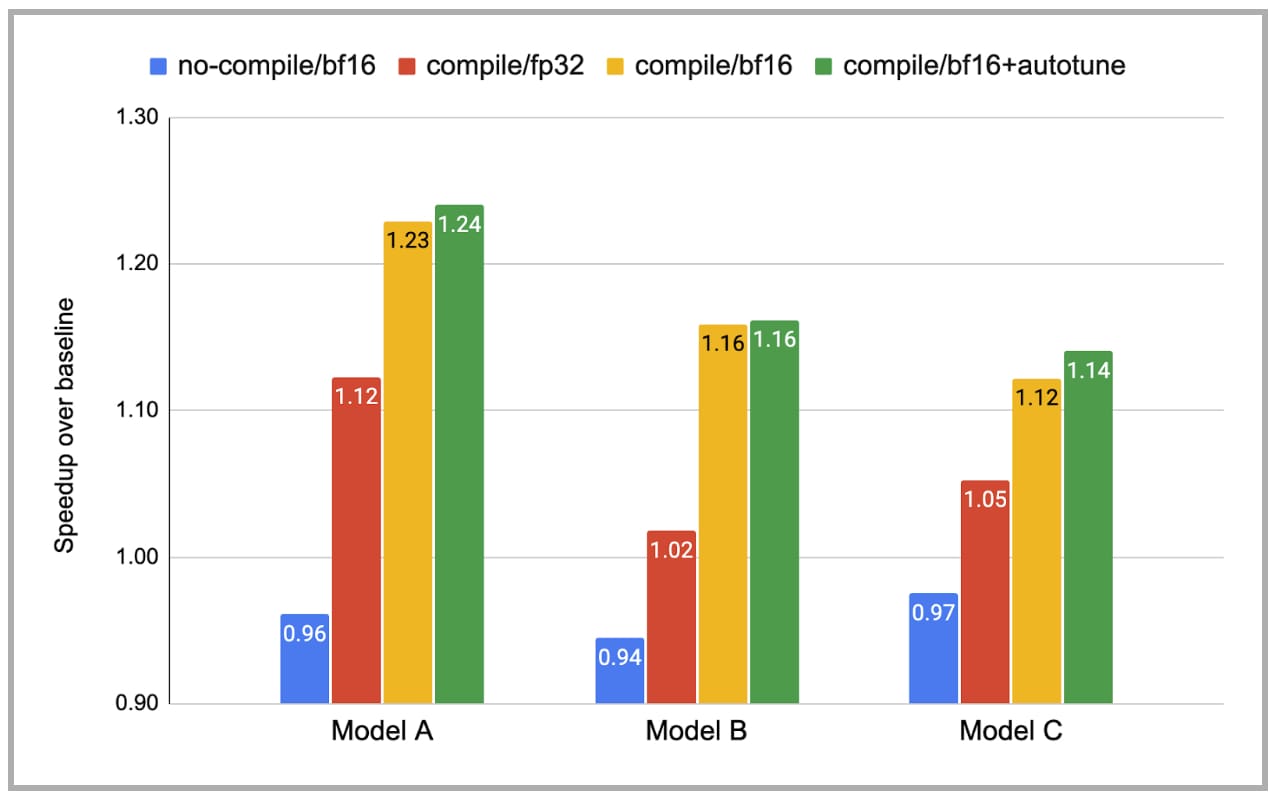
图 7:使用 torch.compile 的训练时间加速(注意:图中省略了基线,即不编译/fp32)。
4.2 使用并行编译减少编译时间
图 8 显示了有无并行编译的编译时间。虽然串行编译时间仍有改进空间,但并行编译已将 TTFB 上的编译开销降低到可接受的水平。模型 B 和 C 从并行编译中受益比模型 A 更大,因为它们每个图中有更多不同的 Triton 内核。
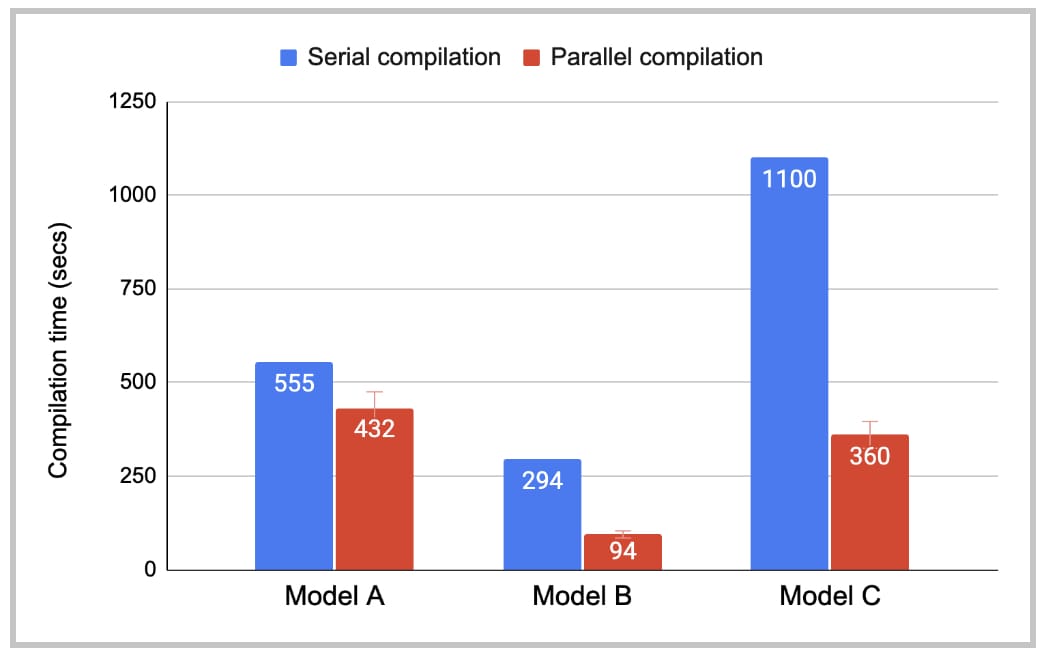
图 8:PT2 编译时间。
5. 总结
在这篇博客中,我们展示了 PT2 可以显著加速大型复杂生产级 AI 模型的训练,并且编译时间合理。在我们的下一篇博客中,我们将讨论 PT2 如何进行通用图转换。
6. 致谢
非常感谢Mark Saroufim、Adnan Aziz 和Gregory Chanan 的详细而富有洞察力的评论。