我们很高兴地宣布发布 Holistic Trace Analysis (HTA),这是一个面向 PyTorch 用户的开源性能分析和可视化 Python 库。HTA 接受 PyTorch profiler 收集的 Kineto 跟踪作为输入,这些跟踪复杂且难以解释,HTA 提升了这些跟踪中包含的性能信息。它最初是在 Meta 内部开发的,用于理解和调试 GPU 上大规模分布式训练作业的性能问题。这个多学科团队对 HTA 的功能进行了多项增强,并将其扩展以支持最先进的 ML 工作负载。
ML 研究人员和系统工程师经常因为不了解其工作负载中的性能瓶颈而难以在计算上扩展其模型。由于缺乏“幕后”可见性,作业请求的资源(例如 GPU、内存)往往与实际所需的资源不匹配。为了从硬件堆栈中获得最佳性能,了解分布式训练工作负载的资源利用率和瓶颈至关重要。
HTA 的初始实现专门针对基于深度学习的推荐模型 (DLRM)。为了使 HTA 中的功能通用并适用于分析 Vision 和 NLP 模型等用例,我们决定重构 HTA 代码库并使该库可供更广泛的社区使用。这个新的代码库实现了一些重要的想法,从而显著提高了效率和性能。
在这篇博客中,我们介绍了 HTA 开源版本中实现的几个功能,这些功能既可以作为 Python 脚本使用,也可以在 Jupyter notebook 中交互式使用。HTA 提供以下功能:
- 按维度分解
- 时间:按计算、通信、内存事件和空闲时间在单个节点和所有等级上花费的时间对 GPU 时间进行分解。
- 空闲时间:将 GPU 空闲时间分解为等待主机、等待另一个内核或归因于未知原因。
- 内核:查找每个等级上持续时间最长的内核。
- 通信计算重叠:计算通信与计算重叠的时间百分比。
- 统计分析
- 内核持续时间分布:不同等级上最长内核的平均时间分布。
- CUDA 内核启动:持续时间非常短、持续时间长和启动时间过长的 GPU 内核分布。
- 增强计数器(内存带宽、队列长度):增强的跟踪文件,提供内存复制带宽和每个 CUDA 流上的未完成操作数量的见解。
- 模式
- 频繁的 CUDA 内核:查找任何给定 PyTorch 或用户定义操作符最频繁启动的 CUDA 内核。
- 跟踪比较
- 跟踪差异:一个跟踪比较工具,用于识别和可视化跟踪之间的差异。
HTA 源代码通过 Github 向用户提供。除了上述功能外,用户还可以使用代码库中提供的核心库和数据结构请求新功能或构建自己的分析。
GPU 训练性能调试 101
为了理解分布式训练作业中的 GPU 性能,我们考虑模型操作符如何与 GPU 设备交互以及此类交互如何反映在某些可测量指标中。
在高层次上,我们可以将模型执行中的 GPU 操作分解为三大类,以下简称内核类型:
- 计算 (COMP) – 计算内核执行编译的例程,用于矩阵乘法和类似的数值计算。它们负责模型执行所需的所有数值运算。
- 通信 (COMM) – 通信内核负责在分布式训练作业中不同 GPU 设备之间交换和同步数据。NVIDIA Collective Communication Library (NCCL) 是一个广泛使用的通信库,其所有内核都带有前缀“nccl”。NCCL 内核示例包括 NCCL_AllGather、NCCL_ReduceScatter、NCCL_AllReduce 等。
- 内存 (MEM) – 内存内核管理 GPU 设备上的内存分配/解除分配以及主机和 GPU 之间内存空间的数据移动。内存内核包括 Memcpy_H2D、Memcpy_D2H、Memcpy_D2D、Memset 等。这里,H 表示主机,D 表示 GPU 设备。因此,H2D、D2H、D2D 分别代表主机到设备、设备到主机和设备到设备。
由于像 NVIDIA A100 GPU 这样的现代 GPU 设备是能够同时运行多个内核的大规模并行设备,因此可以重叠计算、通信和内存内核以减少模型执行时间。实现重叠的一种常见技术是利用多个 CUDA 流。CUDA 流是在 GPU 设备上按主机代码发出的顺序执行的操作序列。不同的 CUDA 流可以交错甚至并发运行,从而实现内核重叠的效果。
为了帮助理解上述概念,图 1 提供了 8 个 GPU 上的示例分布式训练作业一次迭代的 GPU 内核时间线。在下图中,每个等级代表一个 GPU,每个 GPU 上的内核在 6 个 CUDA 流上运行。在图的右栏中,您可以看到所使用的 GPU 内核的名称。在图的中间,您可以看到计算和通信内核之间的重叠。此图是使用 HTA 中提供的 plot_timeline 示例 notebook 创建的。
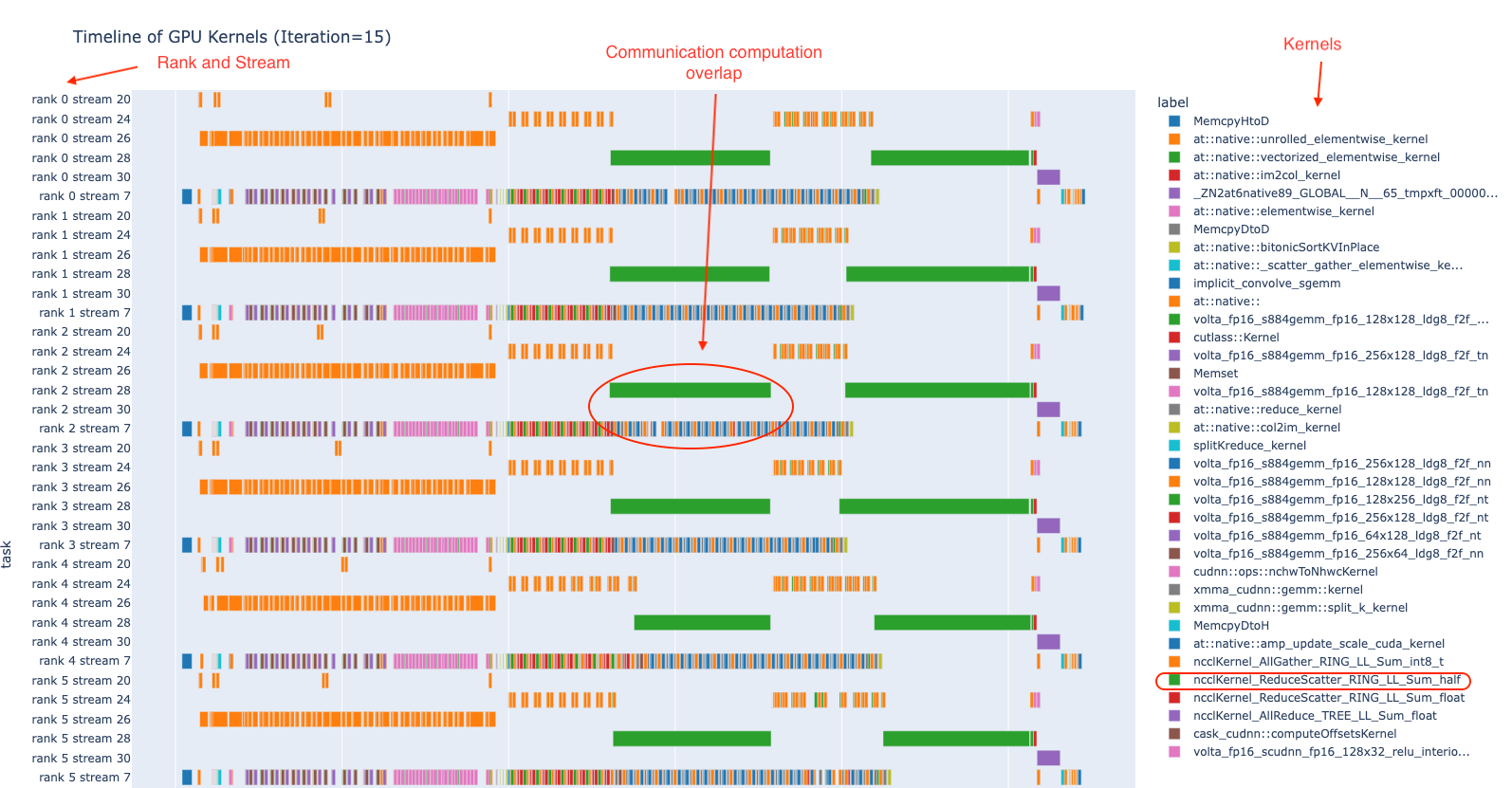
图 1. 多个等级上 GPU 内核执行时间线的示例
多个 GPU 训练作业的性能受多种因素影响。在这些因素中,模型执行如何创建和协调 GPU 内核起着关键作用。HTA 提供模型执行如何与 GPU 设备交互的见解,并突出性能改进的机会。
凭借我们在 HTA 中构建的功能,我们旨在为用户提供对“分布式 GPU 训练中幕后发生了什么?”的见解。我们将在接下来的几段中简要介绍这些功能。
整体跟踪分析中的功能
对于大多数用户来说,理解 GPU 训练作业的性能并非易事。因此,我们构建了这个库来简化跟踪分析任务,并通过检查模型执行跟踪为用户提供有用的见解。作为第一步,我们开发了足够重要和通用的功能,以便大多数用户可以从该库中受益。
时间分解:我们首先要问的是,GPU 是将时间花在计算、通信、内存事件上,还是处于空闲状态?为了回答这个问题,时间分解功能提供了按这些类别进行的分解。为了实现高训练效率,代码应最大化计算内核使用的时间,并最小化空闲时间和非计算时间(通信或内存内核使用的时间)。这通过实现计算内核与通信或内存内核的并发执行来完成。请注意,在计算内核与通信/内存内核并发执行期间,通信/内存内核花费的时间计入计算时间。
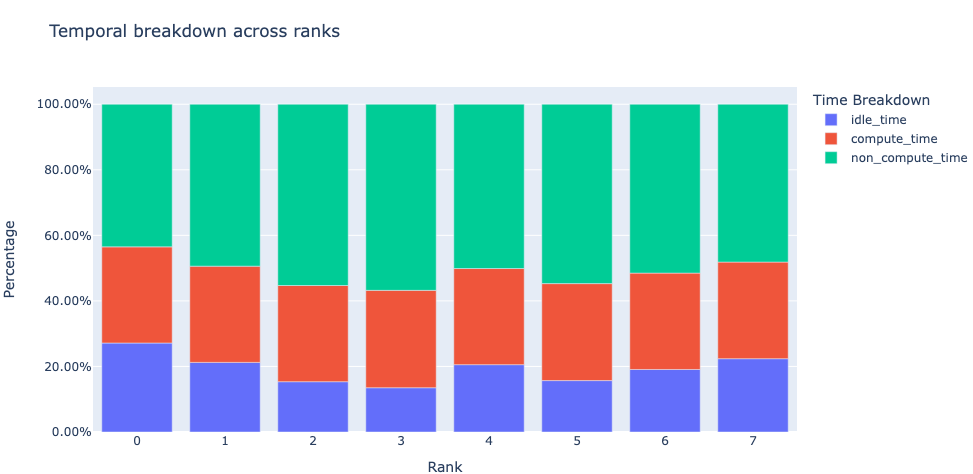
图 2:8 个 GPU 的时间分解
内核分解:很自然地会问哪些内核花费的时间最多。下一个功能按每个内核类型(COMM、COMP、MEM)分解所花费的时间,并按持续时间对其进行排序。我们将此信息以饼图形式呈现给每个内核类型和每个等级。参见下面的图 3。
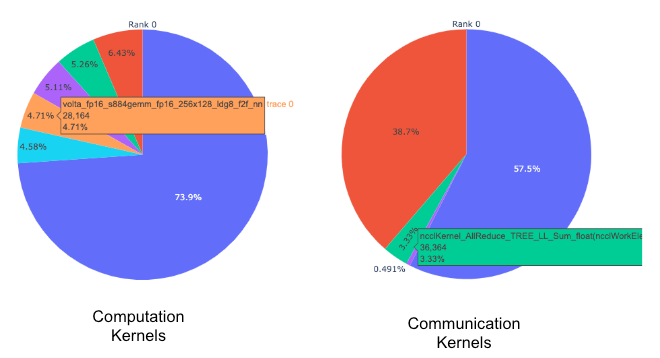
图 3:顶级计算和通信内核的饼图
内核持续时间分布:随后,人们还可以问——对于任何给定的内核,其在所有等级上的时间分布是怎样的?为了回答这个问题,HTA 为所有等级上给定内核的平均持续时间生成条形图。此外,条形图中的误差线显示了给定内核在给定等级上花费的最短和最长时间。下面的图 4 显示了等级 0 上的平均持续时间与其他等级相比存在差异。等级 0 上的这种异常行为指导用户查找可能的错误。
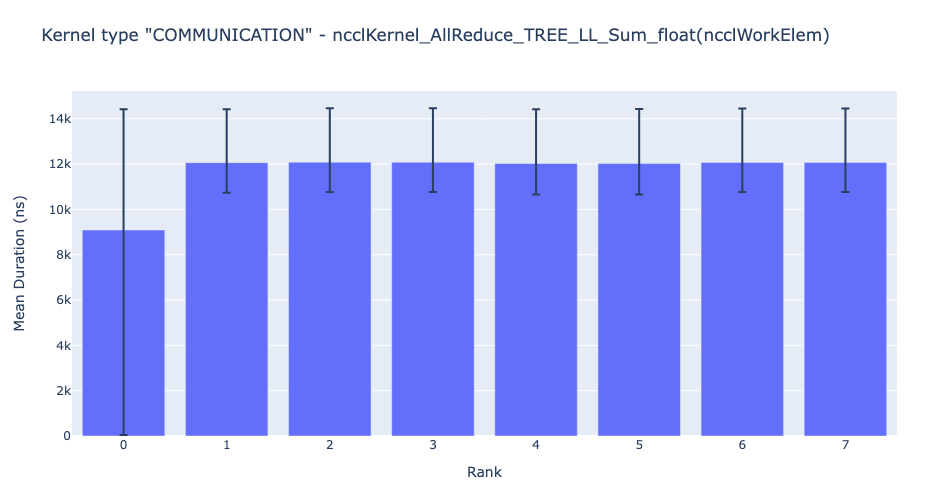
图 4:8 个等级上 NCCL AllReduce 内核的平均持续时间
通信计算重叠:在分布式训练中,大量时间花在多个 GPU 设备之间的通信和同步事件上。为了实现高 GPU 效率(即 TFLOPS/GPU),保持 GPU 进行实际计算工作至关重要。换句话说,GPU 不应因等待来自其他 GPU 的数据而被阻塞。衡量计算因数据依赖性而被阻塞的程度的一种方法是计算计算-通信重叠。如果通信事件与计算事件重叠,则会观察到更高的 GPU 效率。缺乏通信和计算重叠将导致 GPU 空闲,从而导致效率低下。因此,通信计算重叠功能计算作业中每个等级的通信和计算重叠时间的百分比,并生成条形图表示。见下图。更准确地说,我们测量以下比率:
(通信期间用于计算的时间)/(用于通信的时间)
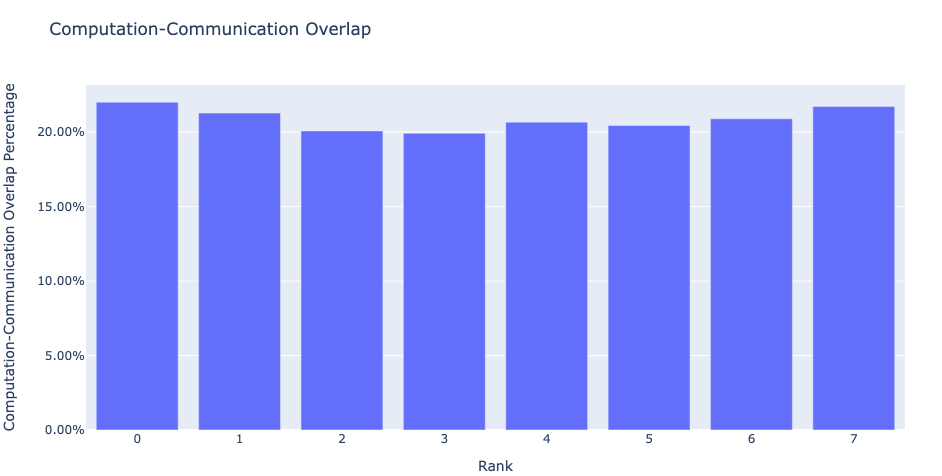
图 5:通信计算重叠
增强计数器(队列长度、内存带宽):为了帮助调试,HTA 计算 D2H、H2D 和 D2D 内存复制 (memcpy) 以及内存设置 (memset) 事件的内存带宽统计信息。此外,HTA 还计算每个 CUDA 流上未完成的 CUDA 操作数。我们将其称为队列长度。当流上的队列长度达到 1024 或更大时,新事件无法在该流上调度,CPU 将停滞,直到 GPU 事件处理完毕。此外,HTA 生成一个包含内存带宽和队列长度时间序列的新跟踪文件。参见下面的图 6。
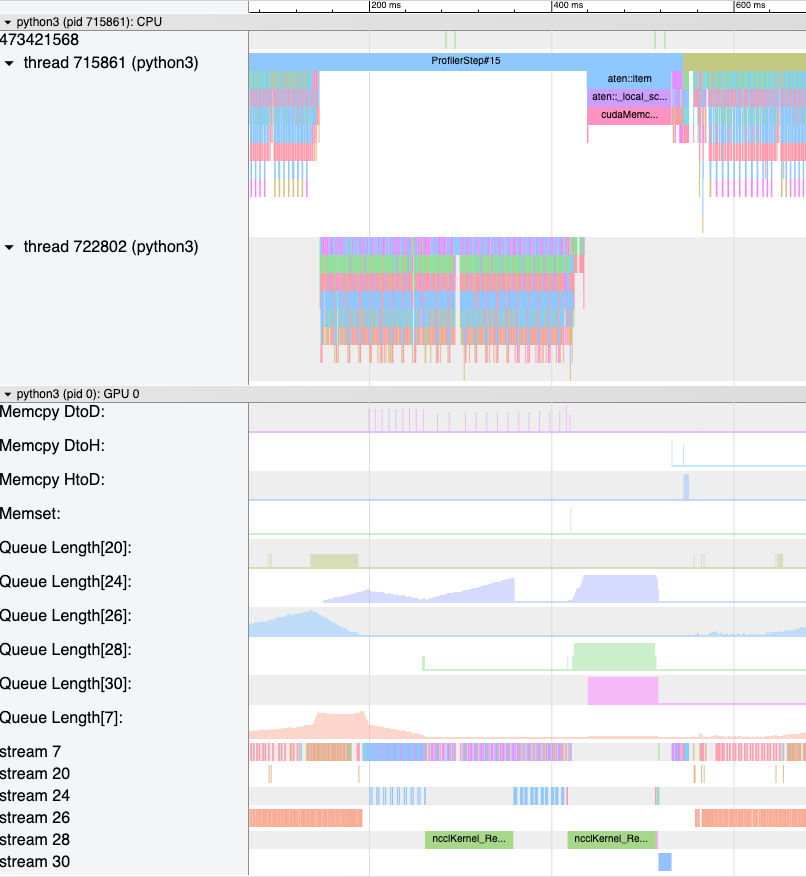
图 6:内存带宽和队列长度
这些主要功能使我们能够一窥系统性能,并帮助回答“系统发生了什么?”。随着 HTA 的发展,我们希望解决“为什么会发生 X?”并提出克服瓶颈的可能解决方案。
安装和使用
安装
有关安装 HTA 的信息,请参阅 README。简而言之,用户需要克隆 repo 并通过 pip 安装必要的 Python 包。
使用
此版本的 Holistic Trace Analysis 目前处于测试阶段,我们建议在 Jupyter notebook 中使用 HTA。为了您的方便,提供了 演示 notebook。要开始使用,请在 Jupyter notebook 中导入 hta 包,创建一个 TraceAnalysis 对象,然后只需两行代码即可开始。
from hta.trace_analysis import TraceAnalysis
analyzer = TraceAnalysis(trace_dir = “/trace/folder/path”)
要求
- 训练或推理作业的所有跟踪文件必须存储在唯一的文件夹中。
- 跟踪文件为 json 或 gzipped json 格式。
常见问题解答
问:如何安装 HTA?
请参阅存储库根目录中的 README。
问:HTA 中的功能和 API 是否有任何文档?
文档和详细 API 可在此处获取:此处。
问:您能实现功能 X 吗?
根据该功能的需求广泛程度以及实现所需的精力,我们将考虑开发该功能。请打开一个 Github Issue 并将其标记为 feature-request 标签。
问:我可以修改代码吗?
如果您认为这对其他人有用,请修改并 发送 PR。
问:如何在 PyTorch 中收集跟踪?
请参阅此教程:此处。
问:HTA 可以在生产规模中使用吗?
是的,请参阅此处的使用案例研究:此处。