在上一篇文章中,我们讨论了 SSD 算法的工作原理,涵盖了其实现细节并介绍了其训练过程。如果您尚未阅读上一篇博客文章,建议您在继续之前先查阅。
在本系列的第二部分中,我们将重点介绍 SSD 的移动友好型变体——SSDlite。我们的计划是:首先,介绍算法的主要组成部分,强调与原始 SSD 不同的部分;其次,讨论已发布的模型的训练方式;最后,提供所有我们探索过的新对象检测模型的详细基准测试。
SSDlite 网络架构
SSDlite 是 SSD 的一种适应版本,最初在MobileNetV2 论文中简要介绍,后来又在MobileNetV3 论文中重新使用。由于这两篇论文的主要重点是引入新颖的 CNN 架构,因此 SSDlite 的大部分实现细节并未阐明。我们的代码遵循两篇论文中提出的所有细节,并在必要时从官方实现中填补了空白。
如前所述,SSD 是一个模型系列,因为可以通过不同的骨干网络(如 VGG、MobileNetV3 等)和不同的头部(如使用常规卷积、可分离卷积等)进行配置。因此,SSDlite 中许多 SSD 组件保持不变。下面我们只讨论那些不同的部分。
分类和回归头部
根据 MobileNetV2 论文的第 6.2 节,SSDlite 将原始头部中使用的常规卷积替换为可分离卷积。因此,我们的实现引入了新的头部,它们使用3x3 深度可分离卷积和 1x1 投影。由于 SSD 方法的所有其他组件保持不变,因此为了创建 SSDlite 模型,我们的实现初始化 SSDlite 头部并将其直接传递给 SSD 构造函数。
骨干特征提取器
我们的实现引入了一个新类来构建 MobileNet特征提取器。根据 MobileNetV3 论文的第 6.3 节,骨干网络返回具有 16 步幅的倒置残差块的扩展层输出,以及具有 32 步幅的池化层之前的输出。此外,骨干网络的所有额外块都替换为轻量级等效块,这些块使用 1x1 压缩、步幅为 2 的可分离 3x3 卷积和 1x1 扩展。最后,为了确保即使在使用小的宽度乘数时,头部也具有足够的预测能力,所有卷积的最小深度尺寸都由min_depth超参数控制。
SSDlite320 MobileNetV3-Large 模型

本节讨论所提供的SSDlite 预训练模型的配置,以及为尽可能接近地复现论文结果而遵循的训练过程。
训练过程
在我们的references文件夹中可以找到用于在 COCO 数据集上训练模型的所有超参数和脚本。这里我们讨论训练过程中最值得注意的细节。
调整的超参数
尽管论文中没有提供用于训练模型的超参数信息(例如正则化、学习率和批量大小),但官方仓库中配置文件中列出的参数是很好的起点,我们通过交叉验证将它们调整到最优值。所有这些都使我们的性能比基线 SSD 配置有了显著提升。
数据增强
SSDlite 与 SSD 的一个关键重要区别在于,前者的骨干网络权重只是后者的一小部分。这就是为什么在 SSDlite 中,数据增强更侧重于使模型对可变大小的对象具有鲁棒性,而不是试图避免过拟合。因此,SSDlite仅使用 SSD 变换的一个子集,从而避免了模型的过度正则化。
学习率方案
由于依赖数据增强使模型对中小尺寸物体具有鲁棒性,我们发现使用大量的 epoch 对于训练方案特别有利。更具体地说,通过使用比 SSD 多大约 3 倍的 epoch,我们能够将精度提高 4.2mAP 点;通过使用 6 倍乘数,我们提高了 4.9mAP。进一步增加 epoch 似乎会带来递减的回报,并使训练过于缓慢和不切实际。然而,根据模型配置,论文作者似乎使用了等效的16 倍乘数。
权重初始化与输入缩放与 ReLU6
最终的一系列优化使我们的实现非常接近官方版本,并帮助我们弥合了精度差距,这些优化包括:从头开始训练骨干网络而不是从 ImageNet 初始化,调整我们的权重初始化方案,改变我们的输入缩放,并将 SSDlite 头部中添加的所有标准 ReLU 替换为 ReLU6。请注意,由于我们从随机权重训练模型,我们还应用了论文中描述的通过使用骨干网络上的缩减尾部来加速的优化。
实现差异
将上述实现与官方仓库中的实现进行比较,我们发现了一些差异。其中大部分是细微的,与我们初始化权重的方式(例如,Normal 初始化与截断 Normal)、我们参数化学习率调度的方式(例如,较小的与较大的预热速率、较短的与较长的训练)等有关。已知最大的差异在于我们计算分类损失的方式。更具体地说,官方仓库中 SSDlite 结合 MobileNetV3 骨干网络的实现没有使用 SSD 的 Multibox 损失,而是使用了 RetinaNet 的焦点损失。这与论文的偏差相当大,由于 TorchVision 已经提供了 RetinaNet 的完整实现,我们决定使用正常的 Multi-box SSD 损失来实现 SSDlite。
关键精度提升细分
如前文所述,重现研究论文并将其转化为代码并非一个单调递增精度的过程,尤其是在不完全了解训练和实现细节的情况下。通常,这个过程涉及大量的回溯,因为需要识别对精度有显著影响的实现细节和参数,并将其与那些没有显著影响的区分开来。下面我们尝试可视化那些将我们的精度从基线提升的最重要的迭代。
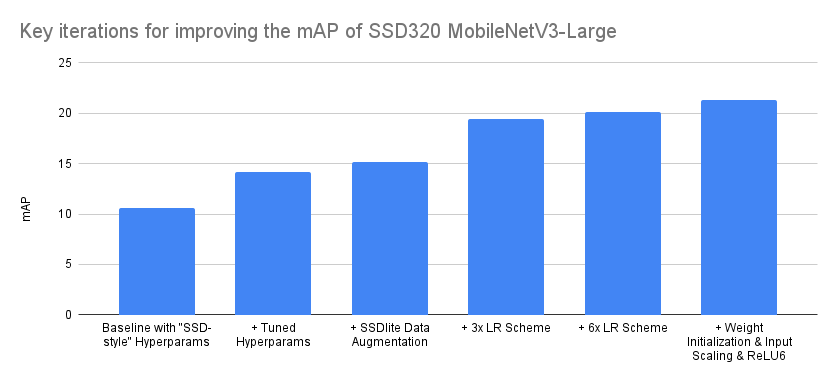
| 迭代 | mAP |
|---|---|
| 基线,使用“SSD风格”超参数 | 10.6 |
| + 调整的超参数 | 14.2 |
| + SSDlite 数据增强 | 15.2 |
| + 3x 学习率方案 | 19.4 |
| + 6x 学习率方案 | 20.1 |
| + 权重初始化 & 输入缩放 & ReLU6 | 21.3 |
上面呈现的优化顺序是准确的,尽管在某些情况下有些理想化。例如,尽管在超参数调整阶段测试了不同的调度器,但它们都没有提供显著的改进,因此我们保留了基线中使用的 MultiStepLR。然而,在后来尝试不同的学习率方案时,我们发现切换到 CosineAnnealingLR 有益,因为它需要较少的配置。因此,我们认为上述总结的主要启示是,即使从同一家族模型的正确实现和一组最优超参数开始,也总能通过优化训练方案和调整实现来发现精度提升点。诚然,上述是一个精度翻倍的极端情况,但在许多情况下,仍有大量的优化可以帮助我们显著提高精度。
基准测试
下面是如何初始化这两个预训练模型的方法
ssdlite = torchvision.models.detection.ssdlite320_mobilenet_v3_large(pretrained=True)
ssd = torchvision.models.detection.ssd300_vgg16(pretrained=True)
以下是新检测模型和选定旧检测模型之间的基准测试
| 模型 | mAP | CPU 推理时间 (秒) | 参数数量 (M) |
|---|---|---|---|
| SSDLite320 MobileNetV3-Large | 21.3 | 0.0911 | 3.44 |
| SSD300 VGG16 | 25.1 | 0.8303 | 35.64 |
| SSD512 VGG16 (未发布) | 28.8 | 2.2494 | 37.08 |
| SSD512 ResNet50 (未发布) | 30.2 | 1.1137 | 42.70 |
| Faster R-CNN MobileNetV3-Large 320 FPN (低分辨率) | 22.8 | 0.1679 | 19.39 |
| Faster R-CNN MobileNetV3-Large FPN (高分辨率) | 32.8 | 0.8409 | 19.39 |
正如我们所见,SSDlite320 MobileNetV3-Large 模型是迄今为止最快、最小的模型,因此它是实际移动应用的绝佳选择。尽管其精度低于预训练的低分辨率 Faster R-CNN 等效模型,但 SSDlite 框架具有适应性,可以通过引入更多卷积的更重头部来提高其精度。
另一方面,SSD300 VGG16 模型相当慢且精度较低。这主要是由于其 VGG16 骨干网络。尽管 VGG 架构极其重要且具有影响力,但如今已相当过时。因此,尽管该特定模型具有历史和研究价值,并因此被纳入 TorchVision,但我们建议需要高分辨率检测器的实际应用用户,要么将 SSD 与其他骨干网络结合使用(参见此示例,了解如何创建一个),要么使用 Faster R-CNN 预训练模型之一。
希望您喜欢 SSD 系列的第二部分也是最后一部分。我们期待您的反馈。