在 TorchVision v0.10 中,我们发布了两个基于 SSD 架构的新的目标检测模型。我们的计划是分两篇文章介绍算法的关键实现细节以及它们的训练方式。
在本系列文章的第1部分中,我们将重点介绍 Single Shot MultiBox Detector 论文中描述的 SSD 算法的原始实现。我们将简要地从高层次描述算法的工作原理,然后介绍其主要组成部分,突出其代码的关键部分,最后讨论我们如何训练发布的模型。我们的目标是涵盖重现模型所需的所有细节,包括论文中未涵盖但属于 原始实现 的那些优化。
SSD 如何工作?
强烈建议阅读上述论文,但这里是一个快速简化的回顾。我们的目标是检测图像中物体的位置及其类别。这是 SSD 论文 中的图5,其中包含模型的预测示例。

SSD 算法使用一个 CNN 主干网络,将输入图像通过它,并从网络的不同层获取卷积输出。这些输出列表称为特征图。然后这些特征图通过分类和回归头,这些头负责预测框的类别和位置。
由于每个图像的特征图包含来自网络不同级别的输出,它们的尺寸不同,因此它们可以捕获不同尺寸的物体。在每个特征图上,我们平铺了几个默认框,这些框可以被认为是我们的粗略先验猜测。对于每个默认框,我们预测是否存在一个物体(及其类别)及其偏移量(对原始位置的修正)。在训练时,我们需要首先将真实标注与默认框匹配,然后我们使用这些匹配来估计我们的损失。在推理时,类似的预测框被组合以估计最终预测。
SSD 网络架构
在本节中,我们将讨论 SSD 的关键组成部分。我们的代码密切遵循 论文,并使用了 官方实现 中包含的许多未记录的优化。
DefaultBoxGenerator
DefaultBoxGenerator 类 负责生成 SSD 的默认框,其操作方式类似于 FasterRCNN 的 AnchorGenerator(有关它们的区别,请参见论文第4-6页)。它生成一组具有特定宽度和高度的预定义框,这些框平铺在图像上,作为物体可能位于何处的第一个粗略先验猜测。这是 SSD 论文中的图1,其中包含真实标注和默认框的可视化。
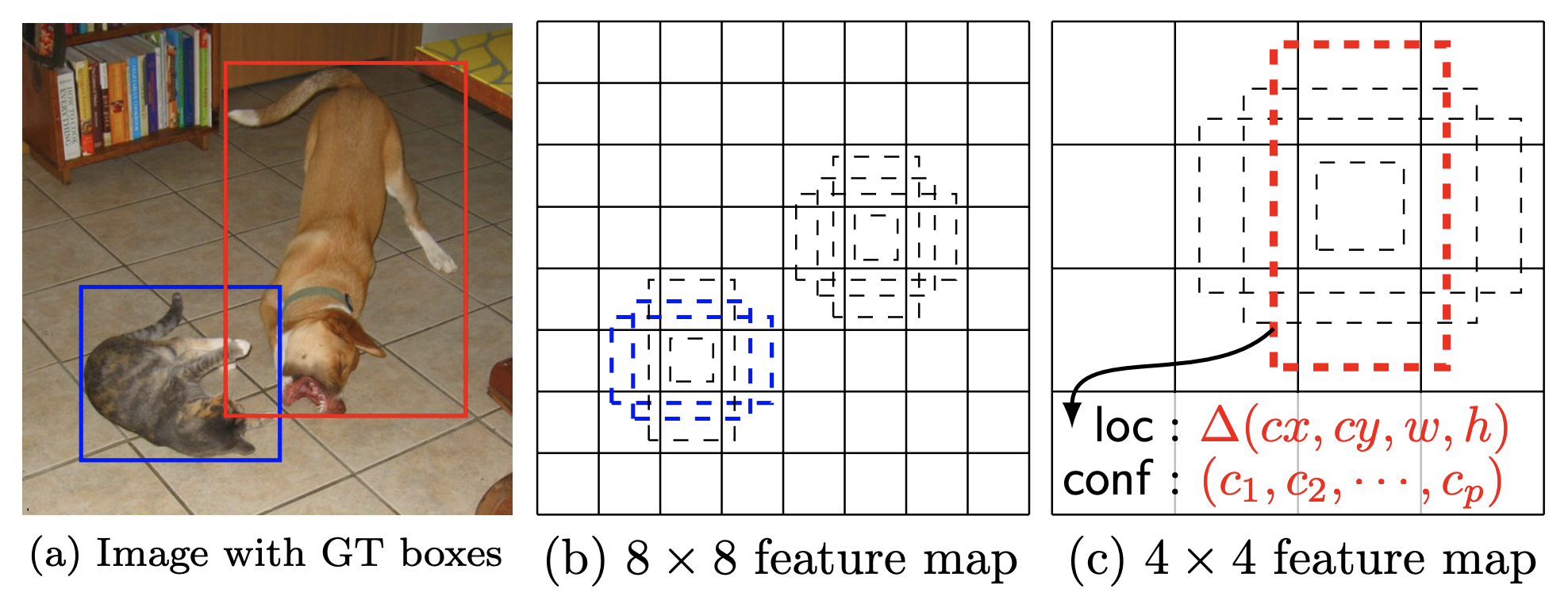
该类由一组超参数参数化,这些超参数控制其 形状 和 平铺方式。该实现将为那些希望尝试新主干网络/数据集的人 自动提供良好的猜测,但也可以传递 优化的自定义值。
SSDMatcher
SSDMatcher 类 扩展了 FasterRCNN 使用的标准 Matcher,它负责将默认框与真实标注匹配。在估计所有组合的 IoU 后,我们使用匹配器为每个默认框找到最佳的 候选 真实标注,其重叠度高于 IoU 阈值。匹配器的 SSD 版本有一个额外的步骤,以确保每个真实标注都与具有 最高重叠度 的默认框匹配。匹配器的结果用于模型训练过程中的损失估计。
分类和回归头
SSDHead 类 负责初始化网络的分类和回归部分。以下是其代码的一些值得注意的细节:
- 分类 头和 回归 头都继承自 同一个类,该类负责为每个特征图进行预测。
- 特征图的每个级别都使用单独的 3x3 卷积来估计 类别 logits 和 框位置。
- 每个头在每个级别上进行的 预测数量 取决于默认框的数量和特征图的大小。
主干特征提取器
特征提取器 重新配置并使用额外的层增强了标准 VGG 主干网络,如 SSD 论文图2所示。
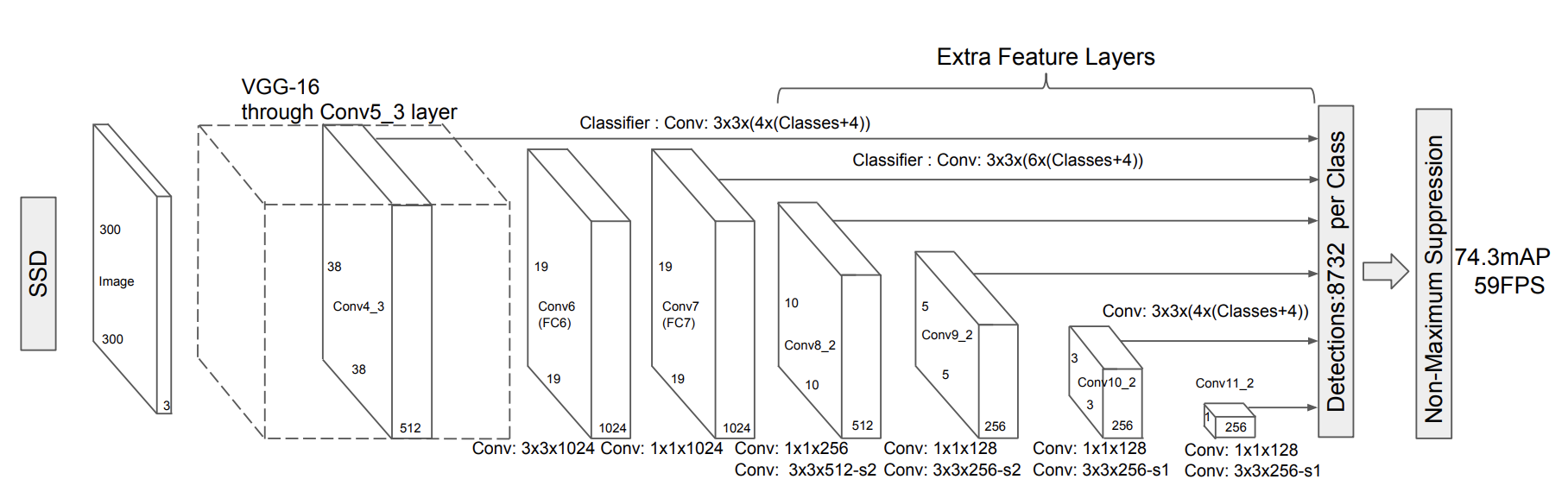
该类支持 TorchVision 的所有 VGG 模型,并且可以为其他类型的 CNN 创建类似的提取器类(参见 ResNet 的这个例子)。以下是该类的一些实现细节:
- 修补 第3个 Maxpool 层的
ceil_mode 参数对于获得与论文相同的特征图大小是必要的。这是由于 PyTorch 和模型的原始 Caffe 实现之间存在细微差异。 - 它在 VGG 上添加了一系列 额外的特征层。如果在其构建过程中
highres 参数为True,它将附加一个 额外的卷积。这对于模型的 SSD512 版本很有用。 - 如论文第3节所述,原始 VGG 的全连接层通过 第一个使用 Atrous 的 卷积转换为卷积层。此外,maxpool5 的步长和核大小也 被修改。
- 如第3.1节所述,对 conv4_3 的输出 使用了 L2 归一化,并引入了一组 可学习权重 来控制其缩放。
SSD 算法
实现中最后一个关键部分是 SSD 类。以下是一些值得注意的细节:
- 该算法通过一系列与其它检测模型相似的参数 参数化。强制参数包括:负责 估计特征图 的主干网络,应该是
DefaultBoxGenerator类的 已配置实例 的anchor_generator,输入图像 将被调整到的尺寸,以及分类的num_classes,不包括 背景。 - 如果未提供 head,构造函数将 初始化 默认的
SSDHead。为此,我们需要知道主干网络生成的每个特征图的输出通道数。最初,我们尝试从主干网络 检索此信息,如果不可用,我们将 动态估计它。 - 该算法 重用了 其他检测模型使用的标准 BoxCoder 类。该类负责 编码和解码 边界框,并配置为使用与 原始实现 相同的先验方差。
- 尽管我们重用了标准的 GeneralizedRCNNTransform 类 来调整和归一化输入图像,但 SSD 算法 对其进行了配置,以确保图像尺寸保持固定。
以下是实现的两个核心方法:
compute_loss方法估计 SSD 论文第5页描述的标准 Multi-box 损失。它使用 平滑 L1 损失 进行回归,并使用标准的 交叉熵损失 以及 难例挖掘(hard-negative sampling) 进行分类。- 与所有检测模型一样,
forward方法当前的行为取决于模型处于训练模式还是评估模式。它首先 调整和归一化输入图像,然后 通过主干网络 获取特征图。然后特征图 通过头 获取预测,然后该方法 生成默认框。
SSD300 VGG16 模型
SSD 是一个模型家族,因为它可以配置不同的主干网络和不同的头部配置。在本节中,我们将重点介绍提供的 SSD 预训练模型。我们将讨论其配置细节和用于重现报告结果的训练过程。
训练过程
该模型使用 COCO 数据集进行训练,其所有超参数和脚本都可以在我们的 references 文件夹中找到。下面我们提供训练过程中最值得注意的方面的详细信息。
论文超参数
为了在 COCO 上取得最佳结果,我们采用了论文第3节中描述的关于优化器配置、权重正则化等超参数。此外,我们发现采用 官方实现 中关于 DefaultBox 生成器 平铺配置 的优化很有用。这项优化在论文中没有描述,但对于提高小物体检测精度至关重要。
数据增强
实现论文第6页和第12页描述的 SSD 数据增强策略 对于重现结果至关重要。更具体地说,使用随机的“放大”和“缩小”变换使模型对各种输入尺寸具有鲁棒性,并提高了其在小中型物体上的精度。最后,由于 VGG16 有相当多的参数,包含在增强中 的光度失真具有正则化作用,并有助于避免过拟合。
权重初始化和输入缩放
我们发现另一个有益的方面是遵循论文提出的 权重初始化方案。为此,我们必须通过 撤销 ToTensor() 执行的 0-1 缩放,并使用与此缩放匹配的 预训练 ImageNet 权重 来调整我们的输入缩放方法(特别感谢 Max deGroot 在他的仓库中提供它们)。所有新卷积的权重都 使用 Xavier 初始化,其偏置设置为零。初始化后,网络 进行了端到端训练。
学习率方案
如论文所述,在应用激进的数据增强后,模型需要训练更长时间。我们的实验证实了这一点,我们必须调整学习率、批量大小和总步数才能获得最佳结果。我们 提出的学习方案 配置得相当保守,在步数之间显示出平台期迹象,因此您很可能只需训练我们 epoch 数的 66% 就能训练出类似的模型。
关键精度改进分解
需要注意的是,直接根据论文实现模型是一个迭代过程,它在编码、训练、bug 修复和调整配置之间循环,直到我们匹配论文中报告的精度。这通常还涉及简化训练方法或用更近期的技术进行增强。这绝不是一个线性过程,即通过一次改进一个方向来逐步提高精度,而是涉及探索不同的假设,在不同方面进行增量改进,并进行大量回溯。
考虑到这一点,下面我们尝试总结对我们精度影响最大的优化。我们通过将各种实验分组为4个主要组,并将实验改进归因于最接近的匹配。请注意,图表的 Y 轴从18而不是0开始,以使优化之间的差异更明显。
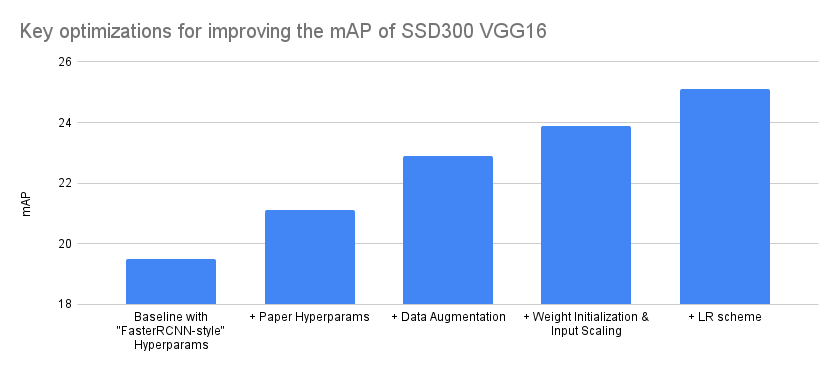
| 模型配置 | mAP 增量 | mAP |
|---|---|---|
| 带有“FasterRCNN 风格”超参数的基线 | – | 19.5 |
| + 论文超参数 | 1.6 | 21.1 |
| + 数据增强 | 1.8 | 22.9 |
| + 权重初始化和输入缩放 | 1 | 23.9 |
| + 学习率方案 | 1.2 | 25.1 |
我们的最终模型实现了 25.1 的 mAP,并完全重现了论文中报告的 COCO 结果。这是精度指标的 详细分解。
希望您对本系列文章的第1部分感兴趣。在第2部分中,我们将重点介绍 SSDlite 的实现,并讨论它与 SSD 的区别。在此之前,我们期待您的反馈。