我们很高兴地宣布 TorchRec 和 FBGEMM 的 1.0 稳定版发布。TorchRec 是 PyTorch 原生的推荐系统库,由 FBGEMM(Facebook GEneral Matrix Multiplication)高效的低级内核提供支持。
TorchRec
最初于 2022 年开源,TorchRec 提供了用于创建最先进个性化模型的常用原语
- 用于在数百个 GPU 上进行分布式训练的简单、优化的 API
- 用于嵌入的高级分片技术
- 推荐系统编写中常用的模块
- 通过 TorchRec 模型的量化和分片 API,实现分布式推理的无缝路径
自那时起,TorchRec 取得了显著的成熟,在 Meta 的许多生产推荐模型中被广泛采用,用于训练和推理,并新增了诸如:可变批次嵌入、嵌入卸载、零冲突哈希等功能。此外,TorchRec 在 Meta 之外也占有一席之地,例如 Databricks 的推荐模型和 Twitter 算法。因此,标准的 TorchRec 功能已被标记为 stable,并具有 PyTorch 风格的 BC 保证,可在改版后的 TorchRec 文档中查看。
FBGEMM
FBGEMM 是一个为 CPU 和 GPU 提供高性能内核的库。自 2018 年以来,FBGEMM 通过将其范围从 CPU 推理的性能关键内核扩展到 CPU 和 GPU 上训练和推理的更复杂稀疏算子——以及最近用于生成式 AI——来支持 Meta 内部和外部 AI/ML 工作负载的高效执行。
FBGEMM 通过其后端高性能内核实现为 TorchRec 提供支持,适用于推荐工作负载,从嵌入袋内核到锯齿状张量操作。我们与 TorchRec 一同发布了 FBGEMM 1.0,它保证了为其核心功能服务的多个稳定 API 的功能性和向后兼容性,并提供了 增强的文档。
性能
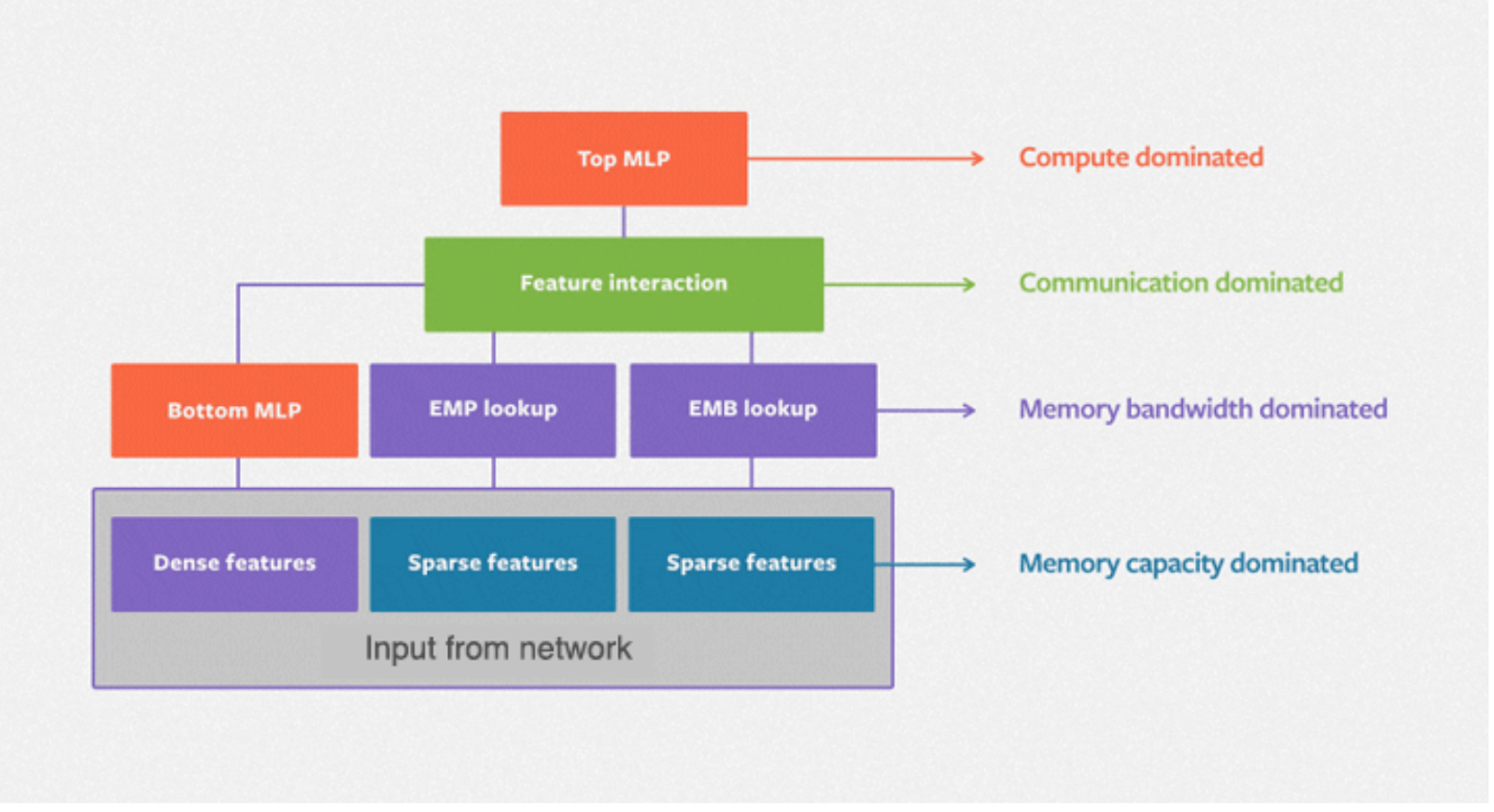
DLRM(深度学习推荐模型)是为 Meta 提供推荐功能的标准神经网络架构,其中分类特征通过嵌入处理,而连续(密集)特征则通过底部多层感知器处理。下图描绘了 DLRM 的基本架构,其中在密集和稀疏特征之间有一个二阶交互层,以及一个用于生成预测的顶部 MLP。
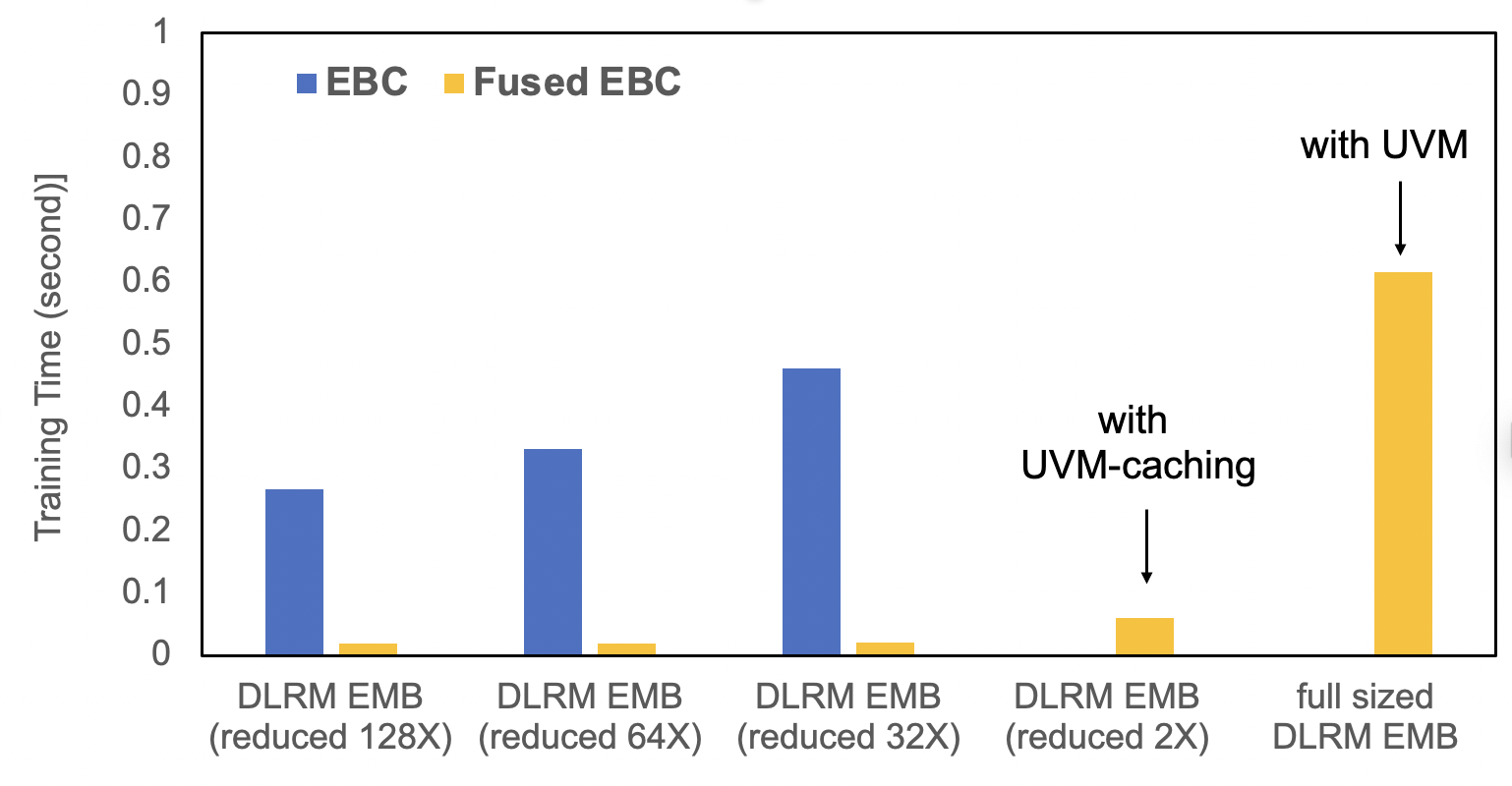
TorchRec 提供了标准化模块,并在融合嵌入查找方面进行了显著优化。EBC 是一种传统的 PyTorch 嵌入模块实现,包含一组 torch.nn.EmbeddingBags。FusedEBC 由 FBGEMM 提供支持,用于在嵌入表上执行高性能操作,具有融合优化器和 UVM 缓存/管理以缓解内存限制,是分片 TorchRec 模块中用于分布式训练和推理的优化版本。下面的基准测试展示了 FusedEBC 相较于传统 PyTorch 嵌入模块实现 (EBC) 的巨大性能提升,以及 FusedEBC 能够通过 UVM 缓存处理比 GPU 内存可用嵌入大得多的嵌入的能力。
TorchRec 数据类型
TorchRec 提供了标准的数据类型和模块,以便轻松处理分布式嵌入。这是一个通过 TorchRec 设置嵌入表集合的简单示例
from torchrec import EmbeddingBagCollection
from torchrec import KeyedJaggedTensor
from torchrec import JaggedTensor
ebc = torchrec.EmbeddingBagCollection(
device="cpu",
tables=[
torchrec.EmbeddingBagConfig(
name="product_table",
embedding_dim=64,
num_embeddings=4096,
feature_names=["product"],
pooling=torchrec.PoolingType.SUM,
),
torchrec.EmbeddingBagConfig(
name="user_table",
embedding_dim=64,
num_embeddings=4096,
feature_names=["user"],
pooling=torchrec.PoolingType.SUM,
)
]
)
product_jt = JaggedTensor(
values=torch.tensor([1, 2, 1, 5]), lengths=torch.tensor([3, 1])
)
user_jt = JaggedTensor(values=torch.tensor([2, 3, 4, 1]), lengths=torch.tensor([2, 2]))
kjt = KeyedJaggedTensor.from_jt_dict({"product": product_jt, "user": user_jt})
print("Call EmbeddingBagCollection Forward: ", ebc(kjt))
分片
TorchRec 提供了一个规划器类,可以自动生成跨多个 GPU 的优化分片计划。这里我们演示了如何在两个 GPU 上生成分片计划
from torchrec.distributed.planner import EmbeddingShardingPlanner, Topology
planner = EmbeddingShardingPlanner(
topology=Topology(
world_size=2,
compute_device="cuda",
)
)
plan = planner.collective_plan(ebc, [sharder], pg)
print(f"Sharding Plan generated: {plan}")
模型并行
TorchRec 的主要分布式训练 API 是 DistributedModelParallel,它调用规划器生成分片计划(如上所示),并根据该计划对 TorchRec 模块进行分片。我们演示了如何使用 DistributedModelParallel 对我们的 EmbeddingBagCollection 进行分片嵌入分布式训练
model = torchrec.distributed.DistributedModelParallel(ebc, device=torch.device("cuda"))
推理
TorchRec 为模型的量化和嵌入分片提供了简单的 API,用于分布式推理。用法如下所示
from torchrec.inference.modules import (
quantize_inference_model,
shard_quant_model,
)
quant_model = quantize_inference_model(ebc)
sharded_model, _ = shard_quant_model(
quant_model, compute_device=device, sharding_device=device
)
结论
TorchRec 和 FBGEMM 现已稳定,并为大规模推荐系统优化了功能。
有关 TorchRec 和 FBGEMM 的设置,请查看入门指南。
我们还推荐阅读这篇全面的端到端介绍 TorchRec 和 FBGEMM 功能的教程。