我们很高兴正式宣布 torchcodec,这是一个用于将视频解码为 PyTorch 张量的库。它快速、准确且易于使用。在视频上运行 PyTorch 模型时,torchcodec 是我们将这些视频转换为模型可用数据的推荐方式。
torchcodec 的亮点包括
- 直观的解码 API,将视频文件视为帧的 Python 序列。我们支持基于索引和基于显示时间的帧检索。
- 强调准确性:我们确保您获得请求的帧,即使您的视频具有可变帧率。
- 丰富的采样 API,使检索帧批次变得简单高效。
- 一流的 CPU 解码性能。
- CUDA 加速解码,可在同时解码大量视频时实现高吞吐量。
- 支持您已安装的 FFmpeg 版本中所有可用的编解码器。
- 适用于 Linux 和 Mac 的简单二进制安装。
易于使用
简单直观的 API 是我们主要的设计原则之一。我们从简单的解码和提取视频特定帧开始
from torchcodec.decoders import VideoDecoder
from torch import Tensor
decoder = VideoDecoder("my_video.mp4")
# Index based frame retrieval.
first_ten_frames: Tensor = decoder[10:]
last_ten_frames: Tensor = decoder[-10:]
# Multi-frame retrieval, index and time based.
frames = decoder.get_frames_at(indices=[10, 0, 15])
frames = decoder.get_frames_played_at(seconds=[0.2, 3, 4.5])
所有解码的帧都是 PyTorch 张量,可以直接输入模型进行训练。
当然,在 ML 训练管道中更常见的是从视频中采样多个片段。片段只是按显示顺序排列的帧序列——但这些帧通常并*不*是连续的。我们的采样 API 使这变得简单
from torchcodec.samplers import clips_at_regular_timestamps
clips = clips_at_regular_timestamps(
decoder,
seconds_between_clip_starts=10,
num_frames_per_clip=5,
seconds_between_frames=0.2,
)
上述调用生成一批片段,其中每个片段相隔 10 秒开始,每个片段包含 5 帧,这些帧相隔 0.2 秒。有关更多信息,请参阅我们的 解码 和 采样 教程!
快速性能
性能是我们的另一个主要设计原则。用于 ML 训练的视频解码与用于播放的视频解码具有不同的性能要求。典型的 ML 视频训练管道将处理许多不同的视频(有时高达数百万!),但每个视频只采样少量帧(几十到几百)。
因此,我们特别关注解码器在视频中多次查找、每次查找后解码少量帧时的性能。我们提供了以下四种场景的实验
- 同时解码和转换来自多个视频的帧,灵感来自我们在大规模训练管道数据加载中看到的情况:a. 十个线程并行解码 50 个视频批次。
b. 对于每个视频,在均匀间隔的时间解码 10 帧。
c. 对于每个帧,将其大小调整为 256×256 分辨率。 - 在单个视频中随机位置解码 10 帧。
- 在单个视频的均匀间隔时间解码 10 帧。
- 解码单个视频的前 100 帧。
我们比较了以下视频解码器
- Torchaudio,仅限 CPU 解码。
- Torchvision,使用 video_reader 后端,仅限 CPU 解码。
- Torchcodec,使用 CUDA 进行 GPU 解码。
- Torchcodec,仅限 CPU 解码。
使用以下三个视频
- 使用 FFmpeg 的 mandelbrot 生成模式合成生成的视频。视频长 10 秒,每秒 60 帧,分辨率为 1920×1080。
- 与上面相同,但视频长 120 秒。
- NASA 的宣传视频,长 206 秒,每秒 29.7 帧,分辨率为 960×540。
实验脚本 在我们的仓库中。我们的实验在具有 22 个可用核心的 Intel 处理器和 NVIDIA GPU 的 Linux 系统上运行。对于 CPU 解码,所有库都指示自动确定要使用的最佳线程数。
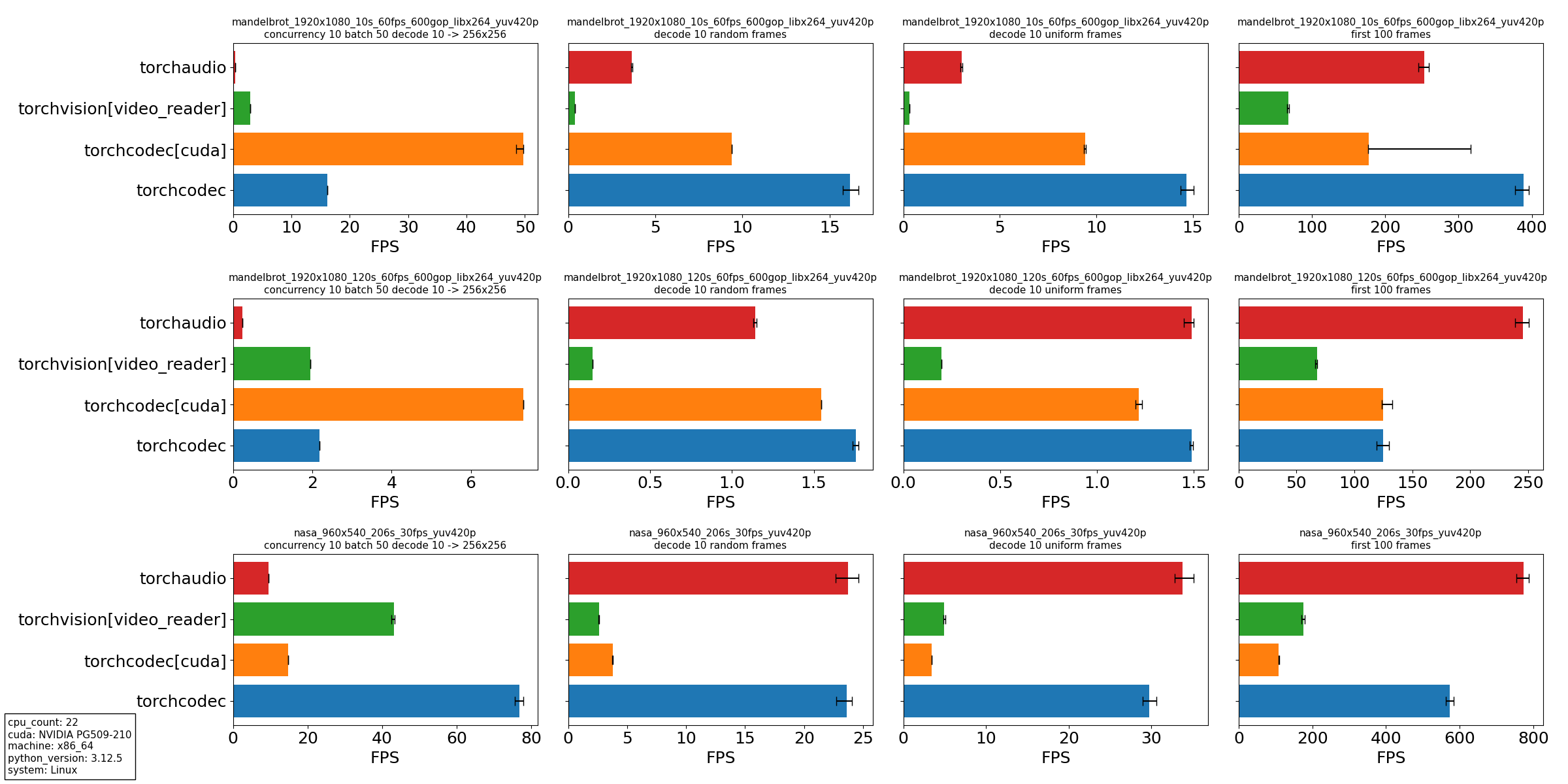
从我们的实验中,我们得出几个结论
- 对于我们设计它的主要用例,torchcodec 始终是表现最佳的库:作为训练数据加载管道的一部分,一次解码多个视频。特别是,高分辨率视频在 CUDA 中获得了巨大的收益,解码和转换都在 GPU 上进行。
- torchcodec 在 CPU 上具有查找密集型用例(如随机和均匀采样)的竞争力。目前,torchcodec 的性能在文件大小较短的视频上更好。这种性能是由于 torchcodec 强调查找准确性,这涉及到初始的线性扫描。
- 在没有查找的情况下,即打开视频文件并从头开始解码时,torchcodec 的竞争力不如其他库。这再次归因于我们对查找准确性和初始线性扫描的强调。
在 torchcodec 中实现 近似查找模式 应该可以解决这些性能差距,这是我们视频解码的最高优先级功能。
下一步是什么?
顾名思义,torchcodec 的长期未来不仅仅是视频解码。我们的下一个重要功能是音频支持——从视频中解码音频流,以及从纯音频媒体中解码音频流。从长远来看,我们希望 torchcodec 成为 PyTorch 的媒体解码库。这意味着随着我们在 torchcodec 中实现功能,我们将弃用并最终移除 torchaudio 和 torchvision 中互补的功能。
我们还计划了视频解码改进,例如前面提到的近似查找模式,适用于那些愿意牺牲准确性以获得性能的用户。
最重要的是,我们正在寻求社区的反馈!我们最感兴趣的是开发社区认为有价值的功能。欢迎 分享您的需求 并影响我们未来的方向!