通过 TorchAO 团队、ExecuTorch 团队和 Unsloth 之间的合作,PyTorch 现在提供 Phi4-mini-instruct、Qwen3、SmolLM3-3B 和 gemma-3-270m-it 的原生量化变体!这些模型利用 int4 和 float8 量化,在 A100、H100 和移动设备上提供高效推理,同时与 bfloat16 模型相比,模型质量几乎没有或没有下降。亮点:
- 我们发布了针对服务器和移动平台优化的预量化模型:供希望在生产中部署更快模型的用户使用
- 我们发布了全面、可复现的量化方案和指南,涵盖模型质量评估和性能基准测试:供将 PyTorch 原生量化应用于自己的模型和数据集的用户使用
- 您还可以使用 unsloth 进行微调,并使用 TorchAO 量化微调后的模型
训练后量化模型和可复现方案
到目前为止,我们已经发布了以下 Phi4-mini-instruct、Qwen3、SmolLM3-3B 和 gemma-3-270m-it 的量化变体:
| 量化方法 | 结果 | 模型 |
| 使用 hqq 算法和 AWQ 的 Int4 仅权重(weight only)量化(适用于服务器 H100 和 A100 GPU) |
|
Phi-4-mini-instruct-INT4 Phi-4-mini-instruct-AWQ-INT4 Qwen3-8B-INT4 Qwen3-8B-AWQ-INT4 |
| Float8 动态激活和 float8 权重量化(适用于服务器 H100 GPU) |
|
gemma-3-270m-it-torchao-FP8 Phi-4-mini-instruct-FP8 Qwen3-32B-FP8 |
| Int8 动态激活和 int4 权重量化(适用于移动 CPU) |
|
Phi-4-mini-instruct-INT8-INT4 Qwen3-4B-INT8-INT4 SmolLM3-3B-INT8-INT4 |
上述每个模型在其模型卡中都包含使用 TorchAO 库的可复现量化方案。这意味着您也可以使用 TorchAO 量化其他模型。
集成
PyTorch 原生量化模型受益于 PyTorch 生态系统中的强大集成,可提供满足不同部署需求的稳健、高性能量化解决方案。
以下是我们在整个技术栈中用于量化、微调、评估模型质量、延迟和部署模型的工具。已发布的量化模型和量化方案在模型准备和部署的整个生命周期中无缝协作。
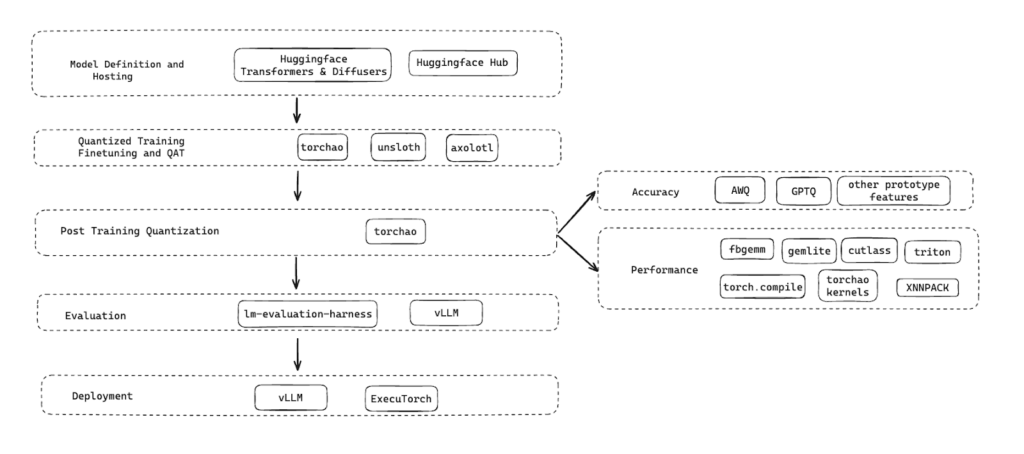
下一步
- 新功能
- 推理和训练的 MoE 量化
- 新的数据类型支持:NVFP4
- 更多保持准确性的训练后量化技术,例如 SmoothQuant、GPTQ、SpinQuant
- 合作
- 继续与 unsloth 合作,向其用户提供 TorchAO,用于微调、QAT、训练后量化,并发布 TorchAO 量化模型
- 我们正在与 vLLM 合作,利用 FBGEMM 的快速内核,实现优化的端到端服务器推理性能
行动号召
请尝试我们的模型和量化方案,并通过在 TorchAO 中提出 问题 或在 已发布模型页面 开始讨论,让我们知道您的想法。您也可以在我们的 Discord 频道 与我们联系。我们也很想了解社区目前如何量化模型,并希望未来在 HuggingFace 上合作发布量化模型。