PyTorch DDP 已在业界广泛用于分布式训练,它默认运行同步 SGD,在每一步同步模型副本间的梯度。这种技术的性能对于模型探索期间的快速迭代以及资源和成本节约至关重要。其性能对于模型开发和探索的快速迭代和成本节约至关重要。为解决大规模训练中由慢速节点引起的普遍性能瓶颈,Cruise 和 Meta 共同开发了一种基于 分层式 SGD 算法的解决方案,以显著加速存在这些掉队者时的训练。
缓解掉队者问题的必要性
在 DDP 设置中,当一个或多个进程运行速度远慢于其他进程(“掉队者”)时,可能会出现掉队者问题。发生这种情况时,所有进程都必须等待掉队者完成梯度同步和通信,这实质上会将分布式性能限制在最慢的工作节点上。因此,即使对于训练相对较小的模型,通信成本仍然可能是一个主要的性能瓶颈。
掉队者问题的潜在原因
严重的掉队者问题通常是由同步前的工作负载不平衡引起的,许多因素都可能导致这种不平衡。例如,分布式环境中的某些数据加载器工作节点可能成为掉队者,因为某些输入示例的数据大小可能是异常值,或者某些示例的数据传输可能因网络 I/O 不稳定而急剧减慢,或者即时数据转换成本可能具有较高的方差。
除了数据加载之外,梯度同步之前的其他阶段也可能导致掉队者,例如在推荐系统中前向传播期间嵌入表查找的工作负载不平衡。
掉队者的出现
如果我们对存在掉队者的 DDP 训练任务进行分析,我们会发现某些进程在某个步骤中可能比其他进程具有更高的梯度同步成本(又称梯度 allreduce)。因此,即使模型大小非常小,分布式性能也可能由通信成本主导。在这种情况下,某些进程在某个步骤中比掉队者运行得更快,因此它们必须等待掉队者,并在 allreduce 上花费更长的时间。
以下显示了 PyTorch 分析器在某个用例中输出的两个跟踪文件的屏幕截图。每个屏幕截图分析了 3 个步骤。
- 第一个屏幕截图显示,一个进程在第一步和第三步的 allreduce 成本都非常高,因为该进程比掉队者更早到达同步阶段,并花费了更多时间等待。另一方面,第二步的 allreduce 成本相对较小,这表明 1) 在此步骤中没有掉队者;或 2) 此进程是所有进程中的掉队者,因此它无需等待任何其他进程。
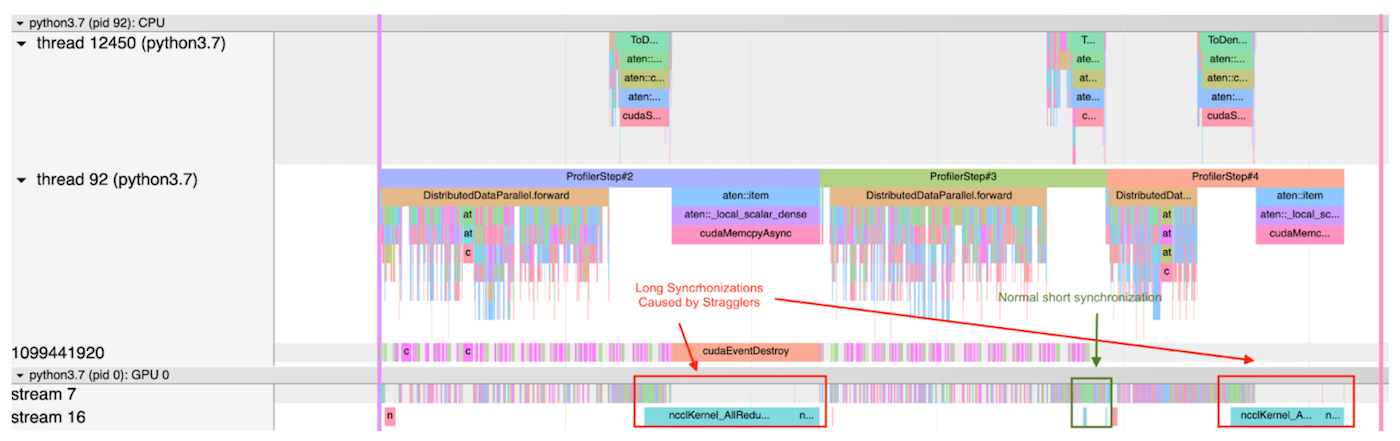
第一步和第三步均被掉队者拖慢
- 第二个屏幕截图显示了没有掉队者的正常情况。在这种情况下,所有梯度同步都相对较短。
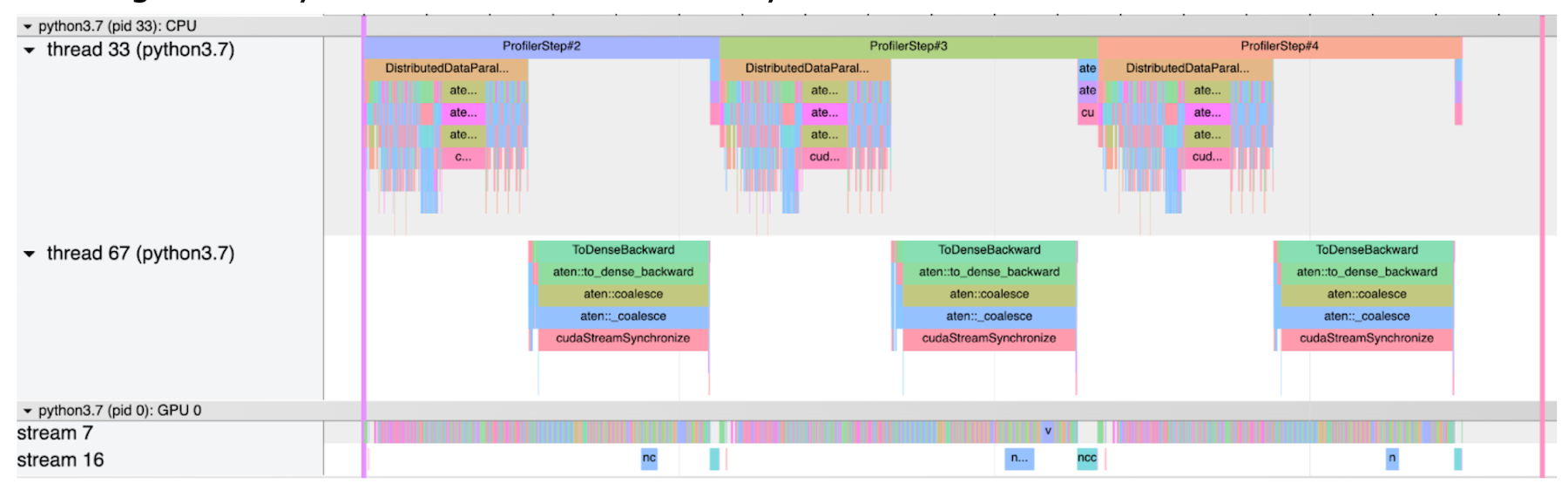
无掉队者的正常情况
PyTorch 中的分层式 SGD
最近提出了分层式 SGD,主要通过减少大规模分布式训练中的数据传输总量来优化通信成本,并提供了多个收敛性分析(示例)。作为本文的主要创新,在 Cruise,我们能够利用分层式 SGD 来缓解掉队者问题,这在训练相对较小的模型时也可能发生。我们的实现在 2022 年初已由 Cruise 上游到 PyTorch。
分层式 SGD 如何工作?
顾名思义,分层式 SGD 将所有进程按不同级别组织成一个层次结构中的组,并遵循以下规则运行同步:
- 同一级别的所有组具有相同数量的进程,这些组中的进程以相同的频率并发同步,同步周期由用户预定义。
- 组的级别越高,使用的同步周期越长,因为同步变得越昂贵。
- 当多个重叠组根据其周期进行同步时,为了减少冗余同步并避免组间数据竞争,只有最高级别的组运行同步。
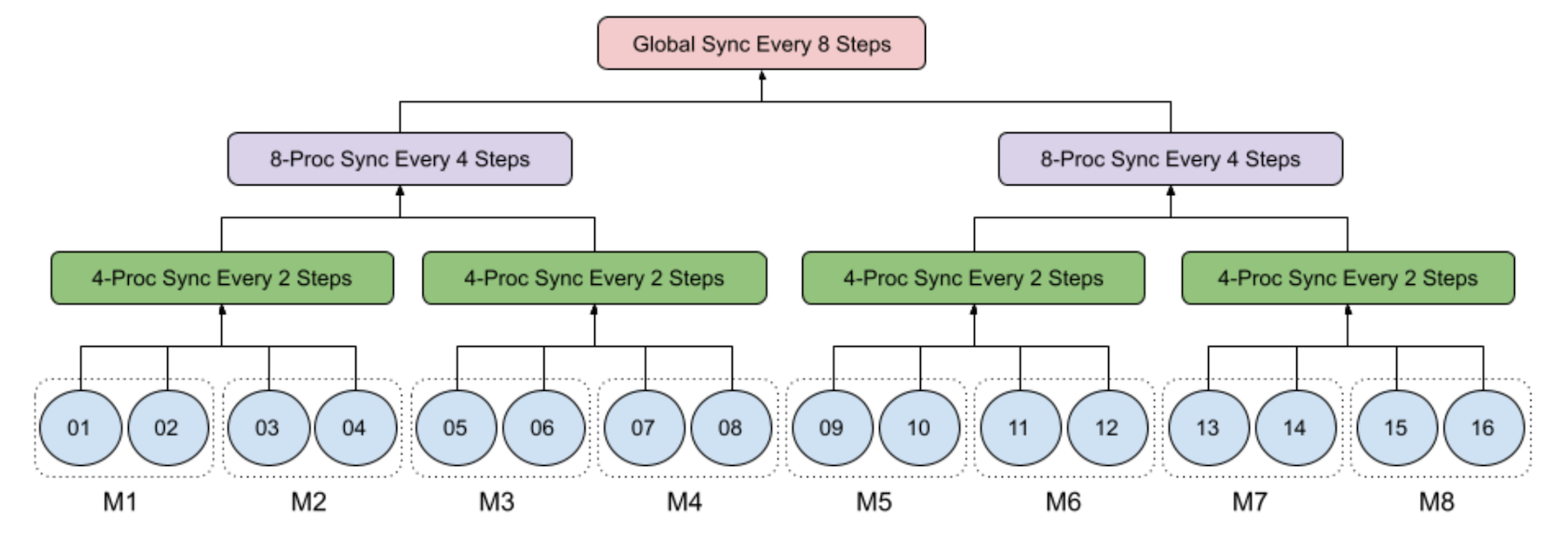
下图展示了 16 个进程在 8 台机器(每台机器有 2 个 GPU)上进行 4 级分层式 SGD 的示例:
- 第一层: 每个进程在本地运行迷你批次 SGD;
- 第二层: 跨 2 台机器的每个 4 进程组每 2 步运行一次同步;
- 第三层: 跨 4 台机器的每个 8 进程组每 4 步运行一次同步;
- 第四层: 跨 8 台机器的所有 16 个进程的全局进程组每 8 步运行一次同步。
特别是,当步数可以被 8 整除时,只执行 3) 处的同步;当步数可以被 4 整除但不能被 8 整除时,只执行 2) 处的同步。
直观地说,分层式 SGD 可以被视为本地 SGD的扩展,本地 SGD 只有两级层次结构——每个进程在本地运行迷你批次 SGD,然后以一定频率全局同步。这也有助于解释,就像本地 SGD 一样,分层式 SGD 同步模型参数而不是梯度。否则,当频率大于 1 时,梯度下降将在数学上不正确。
为什么分层式 SGD 可以缓解掉队者问题?
这里的关键在于,当存在随机掉队者时,它只会直接减慢相对较小的一组进程,而不是所有进程。下次另一个随机掉队者很可能会减慢不同的一个小进程组,因此层次结构可以帮助平滑掉队者效应。
下面的例子假设在总共 8 个进程中,每一步都有一个随机掉队者。经过 4 步后,运行同步 SGD 的香草 DDP 将被掉队者减慢 4 次,因为它在每一步都运行全局同步。相比之下,分层式 SGD 在前两步后与 4 个进程的组运行同步,然后在再两步后进行全局同步。我们可以看到前两个掉队者和后两个掉队者有很大的重叠,因此可以缓解性能损失。
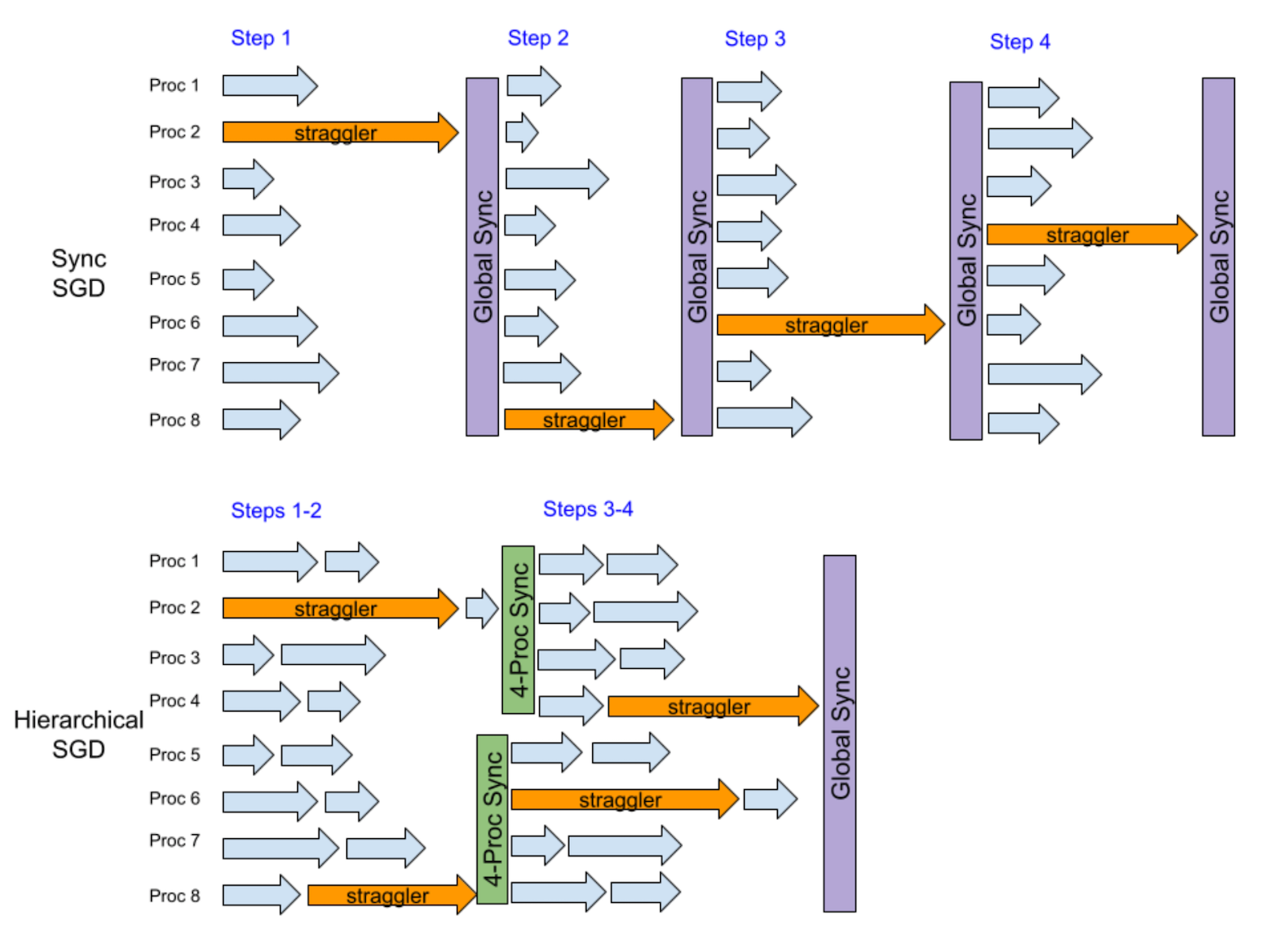
本质上,此分层式 SGD 示例的缓解效果实际上介于每 2 步和每 4 步频率的本地 SGD 之间。分层式 SGD 相对于本地 SGD 的主要优势在于相同全局同步频率下更好的收敛效率,因为分层式 SGD 允许更多的低级同步。此外,分层式 SGD 有可能在模型一致性下提供低于本地 SGD 的全局同步频率,从而带来更高的训练性能,尤其是在大规模分布式训练中。
易用性
掉队者缓解在分布式训练中并非一项新研究。已经提出了多种方法,例如gossip SGD、数据编码、梯度编码,以及一些专为参数服务器架构设计的,包括备份工作节点和陈旧同步并行。然而,据我们所知,在此项工作之前,我们尚未找到一个能在 Cruise 训练系统中像插件一样工作的、良好的开源 PyTorch 掉队者缓解实现。相比之下,我们的实现只需要最少的更改——无需修改现有代码或调整任何现有超参数。这对于行业用户来说是一个非常有吸引力的优势。
如以下代码示例所示,只需在 DDP 模型的设置中添加几行代码,训练循环代码即可保持不变。如前所述,分层式 SGD 是本地 SGD 的扩展形式,因此启用方式与本地 SGD 非常相似(请参阅 PyTorch 文档中的PostLocalSGDOptimizer)
- 注册一个后局部 SGD 通信钩子,以运行完全同步 SGD 的热身阶段并推迟分层式 SGD。
- 创建一个后局部 SGD 优化器,它封装了一个现有的局部优化器和一个分层式 SGD 配置。
import torch.distributed.algorithms.model_averaging.hierarchical_model_averager as hierarchicalSGD
from torch.distributed.algorithms.ddp_comm_hooks.post_localSGD_hook import (
PostLocalSGDState,
post_localSGD_hook,
)
from torch.distributed.optim import PostLocalSGDOptimizer
ddp_model = nn.parallel.DistributedDataParallel(
module=model,
device_ids=[rank],
)
# Register a post-local SGD communication hook for the warmup.
subgroup, _ = torch.distributed.new_subgroups()
state = PostLocalSGDState(subgroup=subgroup, start_localSGD_iter=1_000)
ddp_model.register_comm_hook(state, post_localSGD_hook)
# Wraps the existing (local) optimizer to run hierarchical model averaging.
optim = PostLocalSGDOptimizer(
optim=optim,
averager=hierarchicalSGD.HierarchicalModelAverager(
# The config runs a 4-level hierarchy SGD among 128 processes:
# 1) Each process runs mini-batch SGD locally;
# 2) Each 8-process group synchronize every 2 steps;
# 3) Each 32-process group synchronize every 4 steps;
# 4) All 128 processes synchronize every 8 steps.
period_group_size_dict=OrderedDict([(2, 8), (4, 32), (8, 128)]),
# Do not run hierarchical SGD until 1K steps for model parity.
warmup_steps=1_000)
)
算法超参数
分层式 SGD 有两个主要超参数:period_group_size_dict 和 warmup_steps。
- period_group_size_dict 是一个有序字典,将同步周期映射到进程组大小,用于初始化层次结构中不同大小的进程组,以并发同步参数。较大的组预计使用较大的同步周期。
- warmup_steps 指定了在分层式 SGD 之前运行同步 SGD 的热身阶段的步数。类似于后局部 SGD 算法,通常建议使用热身阶段以获得更高的准确性。该值应与注册 post_localSGD_hook 时在 PostLocalSGDState 中使用的 start_localSGD_iter 参数相同。通常,热身阶段应至少覆盖训练开始时损失急剧下降的时期。
PyTorch 实现与相关论文中提出的初始设计之间的一个细微区别是,在热身阶段之后,默认情况下,每个主机内的进程仍每一步运行主机内梯度同步。这是因为:
- 主机内通信相对便宜,通常可以显著加速收敛;
- 主机内组(对于大多数行业用户来说,大小为 4 或 8)通常可以作为分层式 SGD 中同步最频繁的最小进程组的良好选择。如果同步周期为 1,则梯度同步比模型参数同步(又称模型平均)更快,因为 DDP 会自动重叠梯度同步和反向传播。
可以通过在 PostLocalSGDState 中取消设置 post_local_gradient_allreduce 参数来禁用此类主机内梯度同步。
演示
现在我们演示分层式 SGD 如何通过缓解掉队者问题来加速分布式训练。
实验设置
我们比较了分层式 SGD、局部 SGD 和同步 SGD 在 ResNet18 (模型大小:45MB)上的性能。由于模型非常小,训练不会因同步期间的数据传输成本而受限。为了避免远程存储数据加载引起的噪声,输入数据是从内存中随机模拟的。我们改变了训练使用的 GPU 数量,从 64 到 256。每个工作节点的批次大小为 32,训练迭代次数为 1,000。由于在此组实验中我们不评估收敛效率,因此未启用热身。
我们还在 128 和 256 个 GPU 上模拟了 1% 的掉队者率,在 64 个 GPU 上模拟了 2% 的掉队者率,以确保平均每一步至少有一个掉队者。这些掉队者随机出现在不同的 CUDA 设备上。每个掉队者除了正常的每步训练时间(在我们的设置中约为 55 毫秒)外,还会停顿 1 秒。这可以被视为一种实际场景,其中 1% 或 2% 的输入数据在训练期间的数据预处理成本(I/O 和/或即时数据转换)方面是异常值,并且此成本比平均值大 20 倍以上。
下面的代码片段展示了如何在训练循环中模拟掉队者。我们将其应用于 ResNet 模型,它也可以很容易地应用于其他模型。
loss = loss_fn(y_pred, y)
# Emulate a straggler that lags for 1 second at a rate of 1%.
if random.randint(1, 100) == 1:
time.sleep(1)
loss.backward()
optimizer.step()
实验在 us-central1 GCP 集群上进行。每台机器有 4 个 NVIDIA Tesla T4 GPU,每个 GPU 有 16 GB 内存,通过 32 Gbit/s 以太网连接。每个实例还配备 96 个 vCPU 和 360 GB RAM。
| 架构 | ResNet18 (45MB) |
| 工作节点 | 64, 128, 256 |
| 后端 | NCCL |
| GPU | Tesla T4, 16 GB 内存 |
| 批次大小 | 32 x ## 工作节点数 |
| 掉队者持续时间 | 1 秒 |
| 掉队者率 | 128 和 256 个 GPU 上为 1%,64 个 GPU 上为 2% |
我们为局部 SGD 和分层式 SGD 使用了多种配置。局部 SGD 分别每 2、4 和 8 步运行一次全局同步。
我们使用以下配置运行分层式 SGD:
- 在 64 个 GPU 上
- 每个 8 进程组、32 进程组和全局 64 进程组分别每 2、4 和 8 步同步一次。表示为“HSGD 2-8,4-32,8-64”。
- 每个 32 进程组和全局 64 进程组分别每 4 和 8 步同步一次。表示为“HSGD 4-32,8-64”。
- 在 128 个 GPU 上
- 每个 8 进程组、32 进程组和全局 128 进程组分别每 2、4 和 8 步同步一次。表示为“HSGD 2-8,4-32,8-128”。
- 每个 32 进程组和全局 128 进程组分别每 4 和 8 步同步一次。表示为“HSGD 4-32,8-128”。
- 在 256 个 GPU 上
- 每个 4 进程组、16 进程组、64 进程组和全局 256 进程组分别每 1、2、4 和 8 步同步一次。表示为“HSGD 1-4,2-16,4-64,8-256”。
- 每个 8 进程组、64 进程组和全局 256 进程组分别每 2、4 和 8 步同步一次。表示为“HSGD 2-8,4-64,8-256”。
- 每个 16 进程组和全局 256 进程组分别每 4 和 8 步同步一次。表示为“HSGD 4-16,8-256”。
实验结果
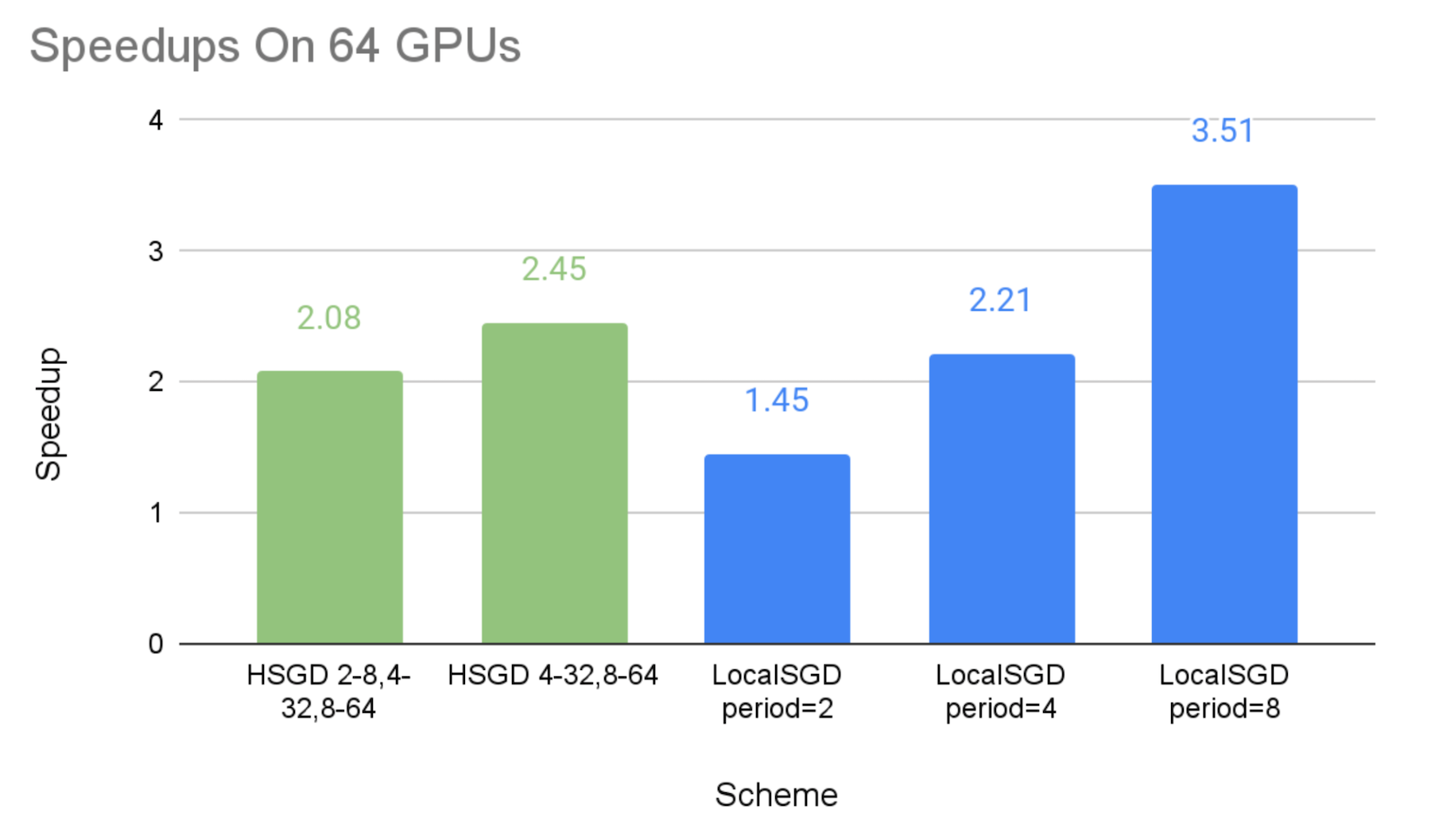
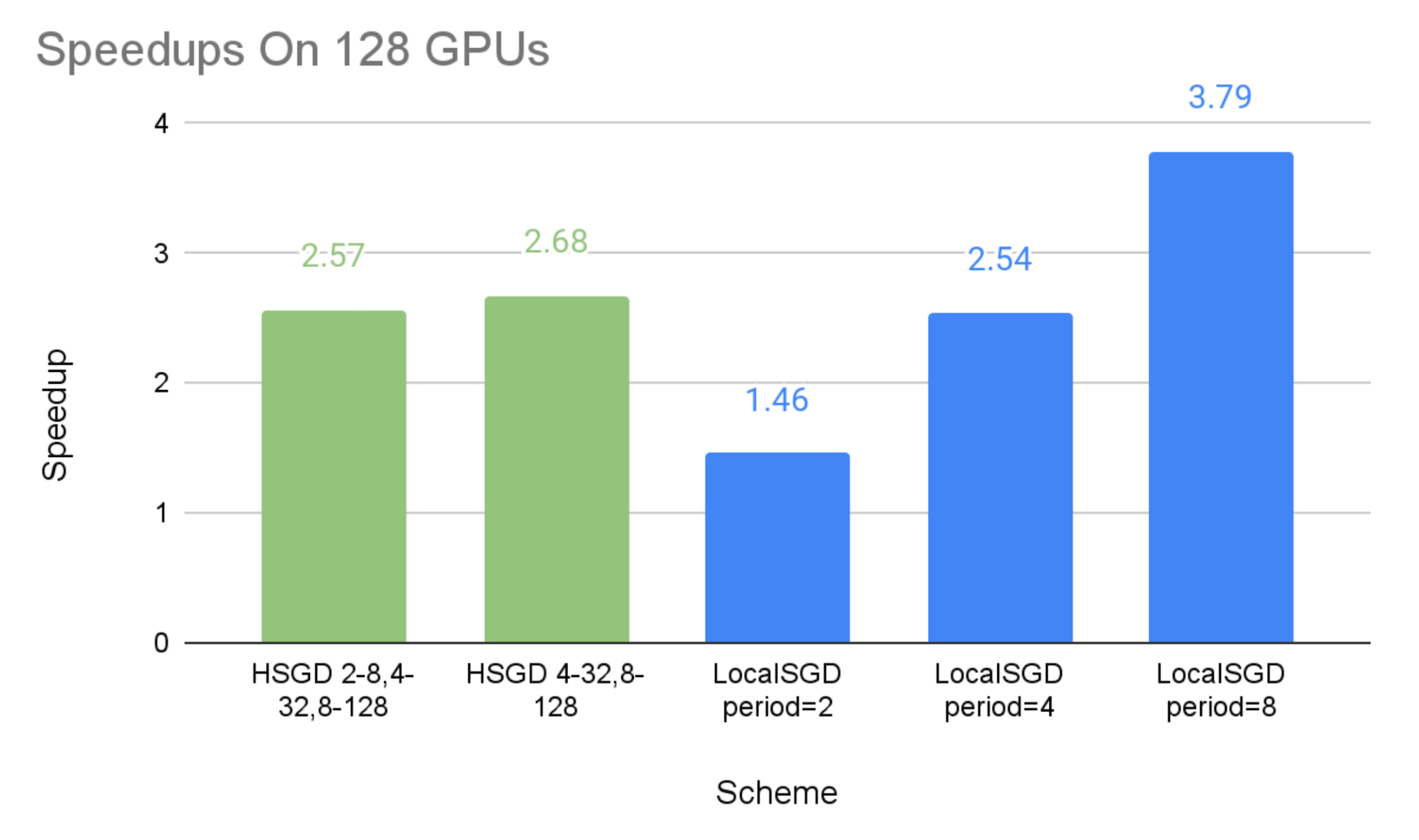
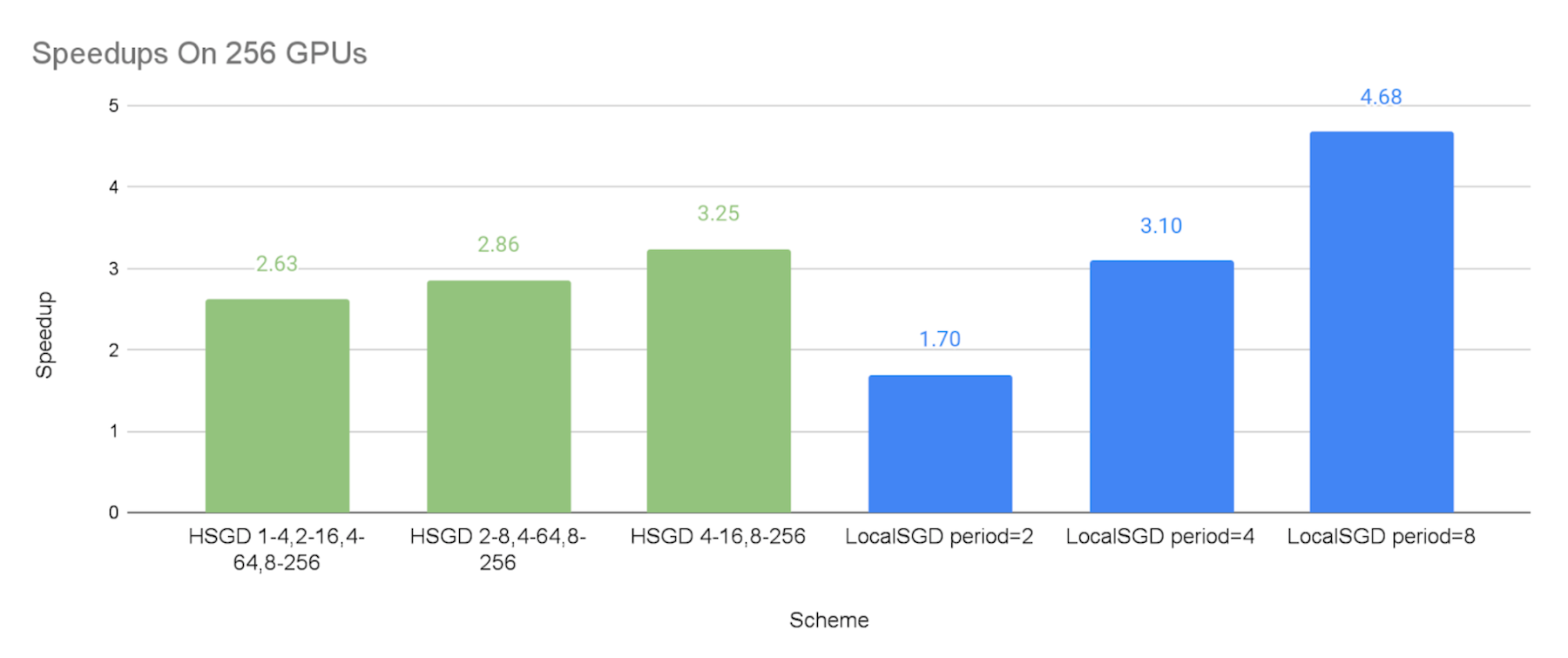
下图显示了不同通信方案相对于同步 SGD 基线的加速比,其中包含模拟的掉队者。我们可以得出以下观察结果:
- 正如预期的那样,我们可以看到分层式 SGD 和局部 SGD 都可以通过较低的同步频率实现更高的加速比。
- 分层式 SGD 方案的加速比在 64 个 GPU 上分别为 2.08X-2.45X,在 128 个 GPU 上为 2.57X-2.68X,在 256 个 GPU 上为 2.63X-3.25X。这表明分层式 SGD 可以显著缓解掉队者问题,并且这种缓解在更大规模下可能更有效。
- 同步周期为 2 步和 8 步的局部 SGD 性能可以分别视为实验分层式 SGD 方案的下限和上限。这是因为分层式 SGD 方案的全局同步频率低于每 2 步,但与每 8 步的全局同步相比,它们在小规模组中的低级同步是额外的开销。
总的来说,分层式 SGD 比局部 SGD 提供了通信成本和模型质量之间更细粒度的权衡。因此,当同步周期较长(例如 8 或 4)的局部 SGD 无法提供令人满意的收敛效率时,分层式 SGD 更有可能同时实现良好的加速比和模型一致性。
由于实验中仅使用模拟数据,我们在此未演示模型一致性,这在实践中可以通过两种方式实现:
- 调整超参数,包括层次结构和热身步数;
- 在某些情况下,分层式 SGD 可能会导致相同训练步数下模型质量略低于原始模型(即收敛速度较慢),但由于每训练步有 2 倍以上的加速比,因此仍有可能通过更多步数实现模型一致性,同时总训练时间更短。
局限性
在将分层式 SGD 应用于掉队者缓解之前,用户应该了解这种方法的一些局限性:
- 这种方法只能缓解非持久性掉队者,即在不同时间发生在不同工作节点上的掉队者。然而,对于持久性掉队者(可能由硬件降级或特定主机上的网络问题引起),这些掉队者每次都会减慢相同的低级子组,导致几乎没有掉队者缓解效果。
- 这种方法只能缓解低频率的掉队者。例如,如果 30% 的工作节点在每一步都可能随机成为掉队者,那么大多数低级同步仍将被掉队者拖慢。因此,分层式 SGD 可能不会显示出比同步 SGD 明显的性能优势。
- 由于分层式 SGD 应用的模型平均与香草 DDP 使用的梯度平均(与反向传播重叠)不同,它不会与反向传播重叠,因此其掉队者缓解带来的性能增益必须大于通信与反向传播之间没有重叠造成的性能损失。因此,如果掉队者只使训练减慢不到 10%,分层式 SGD 可能无法带来太多加速。这个限制可以通过在未来重叠优化器步骤和反向传播来解决。
- 由于分层式 SGD 的研究不如局部 SGD 深入,因此无法保证具有更细粒度同步粒度的分层式 SGD 能够比某些高级形式的局部 SGD(例如,SlowMo,它可以通过慢速动量提高收敛效率)更快地收敛。然而,据我们所知,这些高级算法目前还不能作为 PyTorch DDP 插件像分层式 SGD 那样得到原生支持。
致谢
我们感谢 Cruise 团队成员 Bo Tian, Sergei Vorobev, Eugene Selivonchyk, Tsugn-Hsien Lee, Dan Ring, Ian Ackerman, Lei Chen, Maegan Chew, Viet Anh To, Xiaohui Long, Zeyu Chen, Alexander Sidorov, Igor Tsvetkov, Xin Hu, Manav Kataria, Marina Rubtsova, 和 Mohamed Fawzy, 以及 Meta 团队成员 Shen Li, Yanli Zhao, Suraj Subramanian, Hamid Shojanzeri, Anjali Sridhar 和 Bernard Nguyen 的支持。